一种数据挖掘装置、应用服务器及服务器集群的制作方法
本申请涉及数据挖掘技术领域,特别涉及一种数据挖掘装置、应用服务器及服务器集群。
背景技术:
随着科学技术的发展,商业智能的快速发展以及大数据技术日新月异,大数据的价值越来越受到重视,特别是银行系统在其日常业务办理过程中能够积累海量的业务数据,利用这些大数据进行数据挖掘,能够将挖掘结果广泛的应用在客户营销、产品优化、风险管控等诸多领域,对于提升核心竞争力具有重要的意义。
由此,亟需一种能够实时有效的对数据进行挖掘的实现方案。
技术实现要素:
有鉴于此,本申请的目的是提供一种数据挖掘装置、应用服务器及服务器集群,用以解决现有技术中无法实时有效的对数据进行挖掘的技术问题。
本申请提供了一种数据挖掘装置,与数据挖掘系统相连接,所述数据挖掘系统包括第一集群及第二集群,所述第一集群中包括多个第一服务器,所述第二集群中包括多个第二服务器,所述第一服务器基于ILog规则引擎配置有第一挖掘模型,所述第二服务器基于SAS(STATISTICAL ANALYSIS SYSTEM,统计分析系统)配置有第二挖掘模型,所述装置包括:
请求接收接口,用于接收至少一个数据挖掘请求,所述数据挖掘请求中至少包括请求类型;
请求分类器,用于对所述数据挖掘请求基于其请求类型进行分类;
第一传输接口,用于将请求类型为快速响应类型的数据挖掘请求传输给所述第一集群,由所述第一集群中的第一服务器基于所述数据挖掘请求利用所述第一挖掘模型对数据源中的数据进行数据挖掘,得到第一挖掘结果;
第二传输接口,用于将数据类型不是快速响应类型的数据挖掘请求传输给所述第二集群,由所述第二集群中的第二服务器基于所述数据挖掘请求利用所述第二挖掘模型对数据源中的数据进行数据挖掘处理,得到第二挖掘结果。
上述装置,优选的,还包括:
结果返回接口,用于在得到所述第一挖掘结果和所述第二挖掘结果之后,将所述第一挖掘结果和所述第二挖掘结果进行返回。
上述装置,优选的,还包括:
结果存储接口,用于将所述第一挖掘结果及所述第二挖掘结果进行存储。
上述装置,优选的,还包括:
第三传输接口,用于在得到所述第一挖掘结果和所述第二挖掘结果之后,将所述第一挖掘结果和所述第二挖掘结果传输给所述第二集群,由所述第二集群中的第二服务器利用所述第二挖掘模型对所述第一挖掘结果及所述第二挖掘结果进行交叉验证。
上述装置,优选的,还包括:
第四传输接口,用于将所述第一挖掘模型传输到所述第二集群,由所述第二集群中的第二服务器利用所述第二挖掘模型进行模型训练和验证。
本申请还提供了一种应用服务器,所述应用服务器与数据挖掘系统相连接,所述数据挖掘系统包括第一集群及第二集群,所述第一集群中包括多个第一服务器,所述第二集群中包括多个第二服务器,所述第一服务器基于ILog规则引擎配置有第一挖掘模型,所述第二服务器基于SAS配置有第二挖掘模型;
其中,所述应用服务器中设置有如权利要求1~5中任意一项所述的数据挖掘装置,所述数据挖掘装置集群用于接收至少一个数据挖掘请求,所述数据挖掘请求中至少包括请求类型,对所述数据挖掘请求基于其请求类型进行分类,将请求类型为快速响应类型的数据挖掘请求传输给所述第一集群,由所述第一集群中的第一服务器基于所述数据挖掘请求利用所述第一挖掘模型对数据源中的数据进行数据挖掘,得到第一挖掘结果,并将数据类型不是快速响应类型的数据挖掘请求传输给所述第二集群,由所述第二集群中的第二服务器基于所述数据挖掘请求利用所述第二挖掘模型对数据源中的数据进行数据挖掘处理,得到第二挖掘结果。
本申请还提供了一种服务器集群,包括多个上述的应用服务器,还包括:
数据挖掘系统,所述数据挖掘系统包括:第一集群及第二集群,所述第一集群中包括多个第一服务器,所述第二集群中包括多个第二服务器,所述第一服务器基于ILog规则引擎配置有第一挖掘模型,所述第二服务器基于SAS配置有第二挖掘模型;
其中,所述第一服务器用于基于数据挖掘请求利用所述第一挖掘模型对数据源中的数据进行数据挖掘,得到第一挖掘结果;
所述第二服务器用于基于数据挖掘请求利用所述第二挖掘模型对数据源中的数据进行数据挖掘处理,得到第二挖掘结果。
上述服务器集群,优选的,还包括:负载均衡服务器,其中:
所述负载均衡服务器,用于根据所述服务器集群中应用服务器当前的负载状态,将所述数据挖掘请求发送到所述服务器集群中满足预设的负载均衡条件的应用服务器上。
由上述方案可知,本申请提供的一种数据挖掘装置、应用服务器及服务器集群,通过将ILog集群与SAS集群配置到同一个系统中,从而在接收到数据挖掘请求时,可以根据数据挖掘请求的请求类型来决定采用Ilog的挖掘方式还是SAS的挖掘方式,使得本申请能够同时具备Ilog的能够对数据挖掘进行快速响应的基于专家模型的数据挖掘特性以及SAS的对数据模型的挖掘及验证等挖掘功能的特性,从而在相同数据来源的基础上汇集Ilog及SAS两种数据挖掘特性,在不影响原有数据挖掘任务处理能力的情况下,大幅度提升对不同响应时间、不同挖掘复杂度任务的响应效率。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例六提供的一种数据挖掘装置的结构示意图;
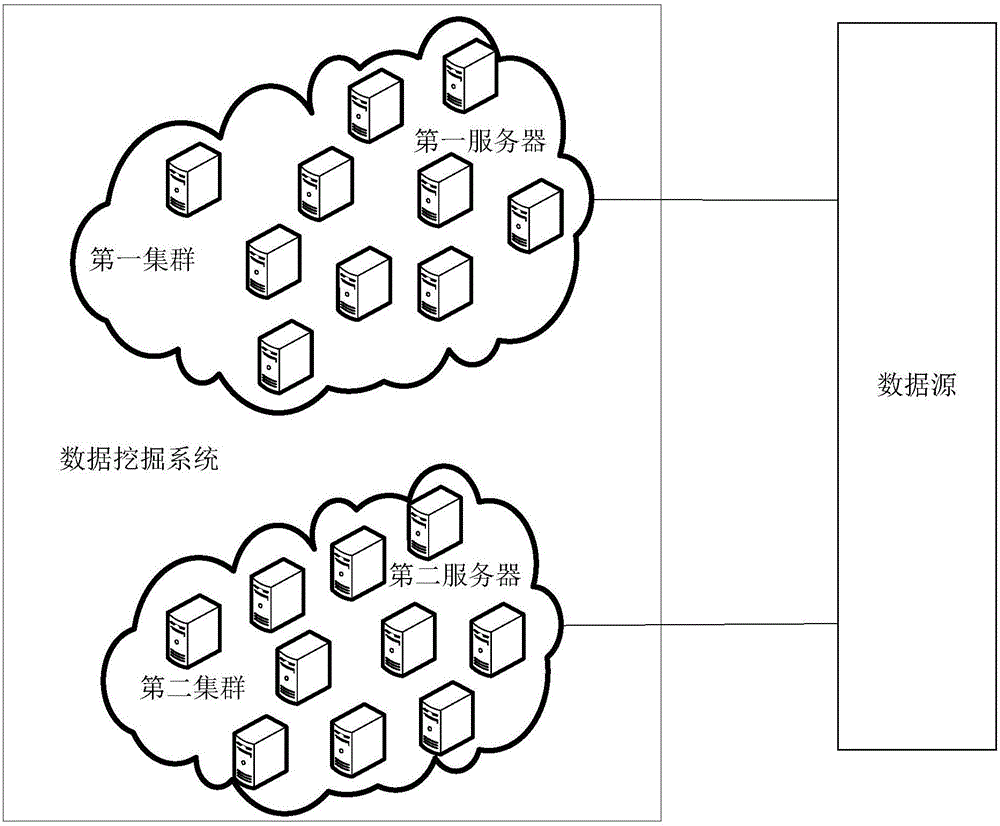
图2为本申请实施例的应用示例图;
图3为本申请实施例二提供的一种数据挖掘装置的结构示意图;
图4为本申请实施例三提供的一种数据挖掘装置的结构示意图;
图5为本申请实施例四提供的一种数据挖掘装置的结构示意图;
图6为本申请实施例五提供的一种数据挖掘装置的结构示意图;
图7为本申请实施例六提供的一种应用服务器的结构示意图;
图8为本申请实施例七提供的一种服务器集群的结构示意图;
图9为本申请实施例八提供的一种服务器集群的结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
参考图1,为本申请实施例六提供的一种数据挖掘装置的结构示意图,所述装置与图2所示的数据挖掘系统相连接,数据挖掘装置与访问终端相连接,数据挖掘系统与数据源相连接。
其中,数据挖掘系统中可以包括有:第一集群及第二集群,两个集群与数据源相连接,第一集群中可以包括多个第一服务器,第二集群中可以包括多个第二服务器,第一服务器基于ILog规则引擎配置有第一挖掘模型,第一挖掘模型即为能够快速对数据进行挖掘响应的专家模型,由此,第一服务器中基于ILog规则引擎能够快速响应和部署用户的基于专家模型的数据挖掘需求,第二服务器基于SAS(STATISTICAL ANALYSIS SYSTEM,统计分析系统)配置有第二挖掘模型,第二挖掘模型即为数据模型,第二服务器基于SAS能够对复杂度较高的数据挖掘任务进行响应。
在本实施例中,所述装置可以包括以下结构,实现数据挖掘:
请求接收接口101,用于接收至少一个数据挖掘请求,所述数据挖掘请求中至少包括请求类型。
其中,数据挖掘请求由访问终端中生成并发送,表征用户所需要进行挖掘的需求,在每个数据挖掘请求中至少包括有表征用户需求的请求类型,如需要快速响应的类型或者大数据统计或复杂度较高的请求类型等。
需要说明的是,请求接收接口101可以采用能够进行数据传输的接口实现,用以接收访问终端发送的数据挖掘请求。
请求分类器102,用于对所述数据挖掘请求基于其请求类型进行分类。
在本实施例中,对数据挖掘请求的分类是指,对解析数据挖掘请求中用户的需求进行切分,也就是说,用户通过访问终端生成数据挖掘请求,此时生成的数据挖掘请求中能够表征用户需要采用哪种方式对数据源中的数据进行挖掘。
需要说明的是,请求分类器102可以采用分类器实现,基于请求类型将数据挖掘请求进行分类。
第一传输接口103,用于将请求类型为快速响应类型的数据挖掘请求传输给所述第一集群,由所述第一集群中的第一服务器基于所述数据挖掘请求利用所述第一挖掘模型对数据源中的数据进行数据挖掘,得到第一挖掘结果。
其中,在数据挖掘请求传输给第一集群之后,第一集群可以根据各个第一服务器的当前负载,确定一个或多个第一服务器进行数据挖掘,实现数据挖掘的负载均衡调度。
需要说明的是,第一传输接口103可以采用能够进行数据传输的接口实现,用以将数据挖掘请求传输给第一集群。
第二传输接口104,用于将数据类型不是快速响应类型的数据挖掘请求传输给所述第二集群,由所述第二集群中的第二服务器基于所述数据挖掘请求利用所述第二挖掘模型对数据源中的数据进行数据挖掘处理,得到第二挖掘结果。
其中,在数据挖掘请求传输给第二集群之后,第二集群可以根据各个第二服务器的当前负载,确定一个或多个第二服务器进行数据挖掘,实现数据挖掘的负载均衡调度。
需要说明的是,第二传输接口104可以采用能够进行数据传输的接口实现,用以将数据挖掘请求传输给第二集群。
也就是说,本实施例中在对数据挖掘请求根据其请求类型进行切分之后,将不同类型的数据挖掘请求采用不同的处理方式,例如:将需要快速响应的数据挖掘请求传输给第一集群,进行时效性较高的数据挖掘,将需要数据量大或复杂度需求较高的数据挖掘请求传输给第二集群进行更加完善或深度更高的数据挖掘。
需要说明的是,这里的数据源可以为各种类型的数据源,如关系型数据库、Hadoop数据库或数据文件的数据集合等。
由上述方案可知,本申请实施例一提供的一种数据挖掘装置,通过将ILog集群与SAS集群配置到同一个系统中,从而在接收到数据挖掘请求时,可以根据数据挖掘请求的请求类型来决定采用Ilog的挖掘方式还是SAS的挖掘方式,使得本申请能够同时具备Ilog的能够对数据挖掘进行快速响应的基于专家模型的数据挖掘特性以及SAS的对数据模型的挖掘及验证等挖掘功能的特性,从而在相同数据来源的基础上汇集Ilog及SAS两种数据挖掘特性,在不影响原有数据挖掘任务处理能力的情况下,大幅度提升对不同响应时间、不同挖掘复杂度任务的响应效率。
参考图3,为本申请实施例二提供的一种数据挖掘装置的结构示意图,所述装置还可以包括以下结构:
结果返回接口105,与第一集群以及第二集群相连接,用于在第一集群得到所述第一挖掘结果和第二集群得到所述第二挖掘结果之后,将所述第一挖掘结果和所述第二挖掘结果进行返回。
具体的,所述结果返回接口105可以采用与所述第一传输接口103与所述第二传输接口104相同的传输接口,用以将第一挖掘结果及第二挖掘结果返回给访问终端。
参考图4,为本申请实施例三提供的一种数据挖掘装置的结构示意图,其中,所述装置还可以包括以下结构:
结果存储接口106,与第一集群及第二集群相连接,第一集群与第二集群与数据存储系统相连接,所述结果存储接口106用于将第一集群得到的所述第一挖掘结果及第二集群得到的所述第二挖掘结果进行存储。
具体的,本实施例中,结果存储接口106可以将所述第一挖掘结果及所述第二挖掘结果存储到与第一集群及第二集群连接的数据库等存储系统中。
其中,所述结果存储接口106可以为向数据存储系统如各种类型的数据库传输第一挖掘结果和第二挖掘结果的数据接口。
参考图5,为本申请实施例四提供的一种数据挖掘装置的结构示意图,其中,所述装置还可以包括以下结构:
第三传输接口107,与第二集群相连接,用于在得到所述第一挖掘结果和所述第二挖掘结果之后,将所述第一挖掘结果和所述第二挖掘结果传输给所述第二集群,由所述第二集群中的第二服务器利用所述第二挖掘模型对所述第一挖掘结果及所述第二挖掘结果进行交叉验证。
需要说明的是,第三传输接口107可以采用能够进行数据传输的接口实现,用以将第一挖掘结果与第二挖掘结果传输给第二集群,由第二集群中的第二服务器进行交叉验证。例如,第一挖掘结果代表专家模型的建模结果,第二挖掘结果代表数据魔心的建模结果,第二服务器对两个模型的结果使用实际数据进行互相交叉验证,用以相互验证发现两类模型存在的问题和缺陷,以此作为两类模型的优化依据,提升模型的准确性。
也就是说,第二集群中的第二服务器基于SAS构建有第二挖掘模型,使得第二服务器能够进行数据模型的挖掘和训练验证,由此,在本实施例中,可以在得到第一挖掘结果及第二挖掘结果之后对第一挖掘结果如专家模型结果及第二挖掘结果如数据模型的结果进行交叉验证。
参考图6,为本申请实施例五提供的一种数据挖掘装置的结构示意图,其中,所述装置还可以包括以下结构:
第四传输接口108,连接于第一集群与第二集群之间,用于将所述第一挖掘模型传输到所述第二集群,由所述第二集群中的第二服务器利用所述第二挖掘模型进行模型训练和验证。
需要说明的是,第四传输接口108可以采用能够进行数据传输的接口实现,将第一集群中的第一挖掘模型如专家模型传输给第二集群,由第二集群中的第二服务器进行模型训练和验证。例如,第一挖掘模型(Ilog)只能快速开发专家模型,本身不带有模型的训练和验证功能,而第二挖掘模型(SAS)是具有这样的功能的,因此,可以将第一挖掘模型放到第二挖掘模型进行模型训练和验证。
也就是说,第二集群中的第二服务器基于SAS构建有第二挖掘模型,使得第二服务器能够进行数据模型的挖掘和训练验证,由此,在本实施例中,可以将第一集群中第一服务器的第一挖掘模型如专家模型放到第二集群中进行模型的训练和验证,之后,第二集群可以将模型训练结果反馈给第一集群,进行模型完善等处理。
参考图7,为本申请实施例六提供的一种应用服务器的结构示意图,其中,所述应用服务器与数据挖掘系统及访问终端相连接,所述数据挖掘系统如图2中所示,包括第一集群及第二集群,两个集群与数据源相连接,所述第一集群中包括多个第一服务器,所述第二集群中包括多个第二服务器,所述第一服务器基于ILog规则引擎配置有第一挖掘模型,所述第二服务器基于SAS配置有第二挖掘模型;
其中,所述应用服务器中设置有如上述任意一项实施例所述的数据挖掘装置,所述数据挖掘装置的结构如图1中所示,用以:接收至少一个数据挖掘请求,所述数据挖掘请求中至少包括请求类型,对所述数据挖掘请求基于其请求类型进行分类,将请求类型为快速响应类型的数据挖掘请求传输给所述第一集群,由所述第一集群中的第一服务器基于所述数据挖掘请求利用所述第一挖掘模型对数据源中的数据进行数据挖掘,得到第一挖掘结果,并将数据类型不是快速响应类型的数据挖掘请求传输给所述第二集群,由所述第二集群中的第二服务器基于所述数据挖掘请求利用所述第二挖掘模型对数据源中的数据进行数据挖掘处理,得到第二挖掘结果。
参考图8,为本申请实施例七提供的一种服务器集群的结构示意图,其中,所述服务器集群中包括多个如上一实施例中所述的应用服务器801,所述应用服务器801中设置有数据挖掘装置811,所述服务器集群中还包括有数据挖掘系统802,所述数据挖掘系统802包括有:第一集群821及第二集群822,两个集群与数据源相连接,所述第一集群821中包括多个第一服务器823,所述第二集群822中包括多个第二服务器824,所述第一服务器823基于ILog规则引擎配置有第一挖掘模型,所述第二服务器824基于SAS配置有第二挖掘模型。
其中,所述服务器集群中的应用服务器801通过数据挖掘装置811在接收至少一个数据挖掘请求之后,所述数据挖掘请求由访问终端803生成并发送,数据挖掘请求中至少包括请求类型,对所述数据挖掘请求基于其请求类型进行分类,将请求类型为快速响应类型的数据挖掘请求传输给所述数据挖掘系统802中第一集群821,由所述第一集群821中的第一服务器823基于所述数据挖掘请求利用所述第一挖掘模型对数据源中的数据进行数据挖掘,得到第一挖掘结果,并将数据类型不是快速响应类型的数据挖掘请求传输给所述数据挖掘系统802中的第二集群822,由所述第二集群822中的第二服务器824基于所述数据挖掘请求利用所述第二挖掘模型对数据源中的数据进行数据挖掘处理,得到第二挖掘结果。
参考图9,为本申请实施例八提供的一种服务器集群的结构示意图,其中,所述服务器集群中还包括有:负载均衡服务器804,连接在访问终端803与每个应用服务器801之间,其中:
所述负载均衡服务器804,用于根据所述服务器集群中应用服务器801当前的负载状态,将所述数据挖掘请求发送到所述应用服务器集群中满足预设的负载均衡条件的应用服务器801上。
其中,所述负载均衡条件可以为当前负载量在服务器集群中从小到大排序在前N个应用服务器,N为大于或等于1的正整数,也就是说,将当前负载量最小或前N小的应用服务器作为处理当前数据挖掘请求的应用服务器,负载均衡服务器804将数据挖掘请求发送到这些当前负载量最小或前N小的应用服务器上,进行请求的处理,实现负载均衡。
也就是说,在实际应用中,本实施例中的数据挖掘装置可运行在服务器集群的应用服务器中,服务器集群中可以含有多个应用服务器,能够对数据挖掘请求进行响应,将数据挖掘请求进行处理转发到相应的第一集群或第二集群中。
而为了实现负载均衡,用户的访问终端所产生的数据挖掘请求可以首先发送到与应用服务器相连接的负载均衡服务器中,由负载均衡服务器进行均衡调度指挥再转发到合适的服务器集群的应用服务器中,进而实现数据挖掘。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体与另一个实体区分开来,而不一定要求或者暗示这些实体之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的物品或者设备中还存在另外的相同要素。
以上对本申请所提供的一种数据挖掘装置、应用服务器及集群进行了详细介绍,对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!