一种基于用户画像的意图场景识别方法及系统与流程
本发明涉及数据处理技术领域,并且特别涉及一种基于用户画像的意图场景识别方法及系统。
背景技术:
用户画像,又称为用户角色(Persona),是一种勾画目标用户、联系用户诉求与设计方向的有效工具。例如在产品开发时,可用于对产品进行定位与规划;在具体实现时,可以将用户画像作为刻画用户特征的标签(tag)集合,例如:年龄、性别、学历等基础属性,或者用户的兴趣特征等;在产品推广时,可根据用户画像挖掘潜在客户群体,进行有针对性的产品推荐。随着信息技术的不断发展,用户画像也逐渐应用于更多领域中。
随着人们对快速、准确地获取信息的需求不断增加,意图识别技术逐渐兴起,其能分析用户的意图并为用户返回一个简洁、准确的答案。但现有的意图识别都是通过本次交互所输入的信息来进行判断,对于用户没有个性化,同时容易出错,用户体验不够好。
技术实现要素:
针对现有技术的不足,本发明提供一种基于用户画像的意图场景识别方法及系统,采用将用户画像向量与传统意图识别的向量相结合的方式,得到具有个性化的回答生成,实现问答的个性化体验,并大大提高准确率。
为解决上述技术问题,本发明提供一种基于用户画像的意图场景识别方法,包括:步骤1:用户输入多模态输入,并对所述多模态输入进行多模态输入转化,将其转化为文本;步骤2:根据转化的文本进行意图识别,并对得出的每一个意图进行打分。在本发明实施例中,可使用传统的方式进行意图识别;步骤3:将用户画像生成的向量和每一个候选意图的向量进行相似度计算;步骤4:将上述步骤3计算的相似度作为另一个分数,与传统方式得出的分数进行加权相加、重排,并将得分最高的候选意图作为最终输出的意图。
优选地,所述步骤2-4是在服务器上执行。
本发明还提供一种基于用户画像的意图场景识别方法,其特征在于,包括:步骤1:用户输入文本;步骤2:根据所述文本进行意图识别,并对得出的每一个候选意图进行打分;步骤3:将用户画像生成的向量和每一个候选意图的向量进行相似度计算;步骤4:将上述步骤3计算的相似度作为另一个分数,与传统方式得出的分数进行加权相加、重排,并将得分最高的候选意图作为最终输出的意图。
优选地,所述步骤2-4是在服务器上执行。
为解决上述技术问题,本发明还提供一种基于用户画像的意图场景识别系统,包括:多模态输入转化模块,用于将用户输入的多模态输入进行多模态输入转化,将其转化为文本;意图识别模块,用于根据所述转化的文本进行意图识别,并对得出的每一个候选意图进行打分;用户画像相似度计算模块,用于将用户画像生成的向量和每一个候选意图的向量进行相似度计算;以及意图输出模块,用于将计算的相似度作为另一个分数,与传统方式得出的分数进行加权相加、重排,并将得分最高的候选意图作为最终意图输出。
优选地,所述意图识别模块、用户画像相似度计算模块、和意图输出模块是在服务器上。
为解决上述技术问题,本发明还提供一种基于用户画像的意图场景识别系统,包括:文本输入模块,用于接收用户输入的文本;意图识别模块,用于根据接收的所述文本进行意图识别,并对得出的每一个候选意图进行打分;用户画像相似度计算模块,用于将用户画像生成的向量和每一个候选意图的向量进行相似度计算;以及意图输出模块,用于将计算的相似度作为另一个分数,与传统方式得出的分数进行加权相加、重排,并将得分最高的候选意图作为最终意图输出。
优选地,所述意图识别模块、用户画像相似度计算模块、和意图输出模块是在服务器上。
总体而言,相较于现有技术,本发明的技术方案具有以下有益效果:
1、通过用户画像进行意图识别能满足个性化的特点;
2、将用户画像向量与意图识别向量进行相似度计算,并将计算的相似度与传统方式得到的意图识别分数进行加权计算,得到的结果更准确。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明一实施例提供的基于用户画像的意图场景识别方法的流程图;
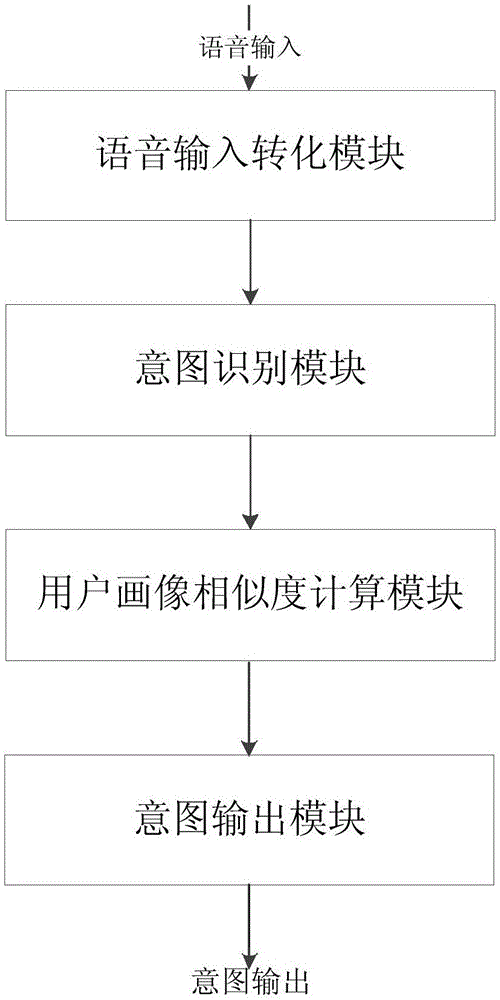
图2是本发明一实施例提供的基于用户画像的意图场景识别系统的结构示意图;
图3是本发明另一实施例提供的基于用户画像的意图场景识别系统的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
图1所示为本发明一实施例提供的基于用户画像的意图场景识别方法的流程图,包括以下步骤:
步骤1:用户输入多模态输入,并对输入的多模态输入进行多模态输入转化,将其转化为文本。例如,用户输入语音,并对输入的语音进行语音转化,将其转化为文本问题。请注意,本文所指的“多模态输入”包括但不限于,视频、人脸、表情、场景、声纹、指纹、虹膜瞳孔、光感、等信息。
步骤2:根据转化的文本进行意图识别,并对得出的每一个意图进行打分。在本发明实施例中,可使用传统的方式进行意图识别;
步骤3:将用户画像生成的向量和每一个候选意图的向量进行相似度计算;
步骤4:将上述步骤3计算的相似度作为另一个分数,与传统方式得出的分数进行加权相加、重排,并将得分最高的候选意图作为最终输出的意图。
其中,所述步骤1中,用户也可以直接输入文本问题,并且所述步骤2-4是在服务器上执行。也就是说,输入语音以及语音转化的步骤并非是必要的。
图2所示为本发明一实施例提供的基于用户画像的意图场景识别系统的结构示意图,包括多模态输入转化模块(例如,语音输入转化模块)、意图识别模块、用户画像相似度计算模块以及意图输出模块。其中,语音输入转化模块,用于将用户输入的语音进行语音转化,将其转化为文本;意图识别模块,用于根据转化的文本进行意图识别,并对得出的每一个候选意图进行打分;用户画像相似度计算模块,用于将用户画像生成的向量和每一个候选意图的向量进行相似度计算;以及意图输出模块,用于将计算的相似度作为另一个分数,与传统方式得出的分数进行加权相加、重排,并将得分最高的候选意图作为最终意图输出。
图3所示为本发明另一实施例提供的基于用户画像的意图场景识别系统的结构示意图,包括文本输入模块、意图识别模块、用户画像相似度计算模块以及意图输出模块。其中,文本输入模块,用于接收用户输入的文本并发送至意图识别模块;意图识别模块,用于根据接收的文本进行意图识别,并对得出的每一个候选意图进行打分;用户画像相似度计算模块,用于将用户画像生成的向量和每一个候选意图的向量进行相似度计算;以及意图输出模块,用于将计算的相似度作为另一个分数,与传统方式得出的分数进行加权相加、重排,并将得分最高的候选意图作为最终意图输出。
在一个实施例中,所述意图识别模块、用户画像相似度计算模块、和意图输出模块是在服务器上。
本发明提供的基于用户画像的意图场景识别方法及系统,通过用户画像的方式来实现意图识别,能满足个性化的功能,并提高了准确率。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!