自动视频概括的制作方法
技术特征:
1.一种用于自动视频概括的设备,所述方法包括:
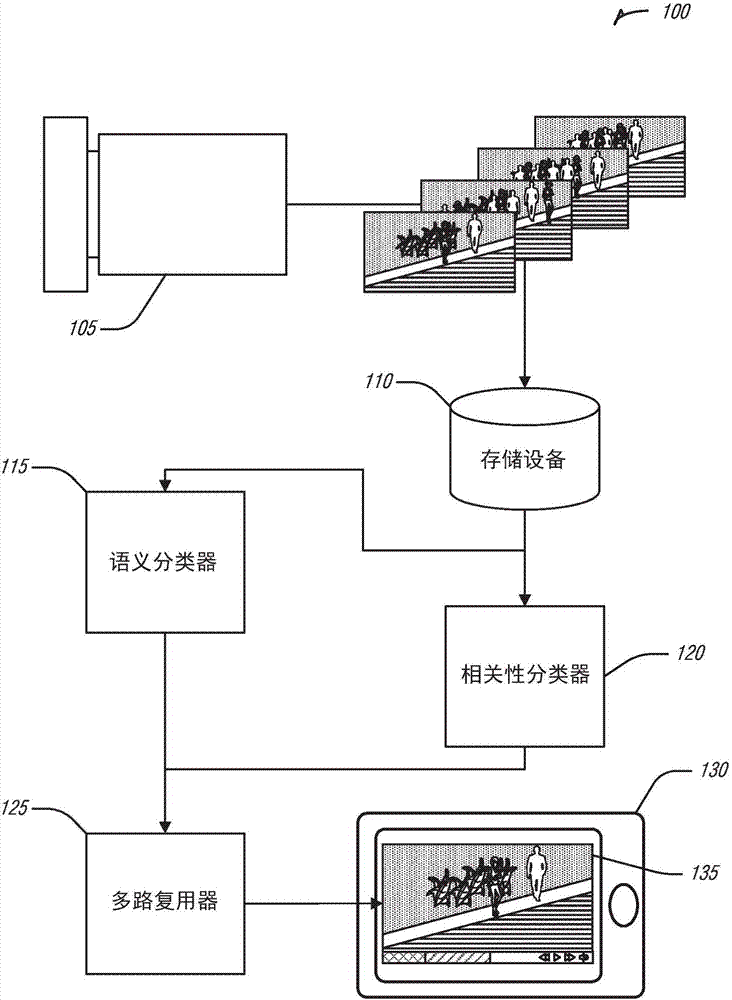
存储设备,用于保存视频;
语义分类器,用于从所述视频的帧生成所述视频的语义模型;
相关性分类器,用于向所述帧指派相应的相关性得分;
多路复用器,用于:
使用所述相应的相关性得分初始化所述语义模型;以及
迭代地处理所述语义模型以产生子场景集合,每次迭代包括所述多路复用器,用于:
在初始化之后收敛所述语义模型;
在收敛之后选择具有最高相关性得分的帧序列;以及
通过固定所选帧序列的所述相关性得分来重新初始化所述语义模型。
2.如权利要求1所述的设备,其特征在于,生成所述语义模型包括提取所述帧的诸特征。
3.如权利要求2所述的设备,其特征在于,生成所述语义模型包括从所提取的诸特征生成伪语义域,其中所述伪语义域是从所述诸特征导出的n维空间。
4.如权利要求3所述的设备,其特征在于,生成所述语义模型包括通过为每个帧导出所述伪语义域中的坐标来将所述帧映射到所述伪语义域,所述坐标的每个元素与所述伪语义域的维度相对应并且是从所提取的诸特征中为所述帧所特有的特征的存在性导出的。
5.如权利要求4所述的设备,其特征在于,生成所述语义模型包括从映射到所述伪语义域的所述帧创建生成模型。
6.如权利要求5所述的设备,其特征在于,创建所述生成模型包括通过将具有最高得分的帧添加到所述帧集合来递归地标识所述帧中的关键帧集合,帧的所述得分是针对所述关键帧集合的所有成员就所述帧的坐标的平方范数乘以常数然后除以所述帧与所述关键帧集合中的帧之间的距离的范数的平方进行的求和的倒数。
7.如权利要求1所述的设备,其特征在于,向所述帧指派相应的相关性得分包括从所述视频提取拍摄所述视频的人的行为指示符。
8.如权利要求1所述的设备,其特征在于,使用所述相应的相关性得分来初始化所述语义模型包括构建一图形,在所述图形中,节点对应于所述帧,节点值对应于所述帧的相应的相关性得分,而边缘按所述语义模型中确定的帧之间的距离倒数来加权。
9.如权利要求1所述的设备,其特征在于,包括控制器,用于:
以产生所述子场景的次序呈现包括所述子场景的用户界面;
从用户接收对子场景的丢弃选择;以及
从视频概括中丢弃所述子场景。
10.一种用于自动视频概括的机器实现方法,所述方法包括:
获得视频;
从所述视频的帧生成所述视频的语义模型;
向所述帧指派相应的相关性得分;
使用所述相应的相关性得分初始化所述语义模型;以及
迭代地处理所述语义模型以产生子场景集合,每次迭代包括:
在初始化之后收敛所述语义模型;
在收敛之后选择具有最高相关性得分的帧序列;以及
通过固定所选帧序列的所述相关性得分来重新初始化所述语义模型。
11.如权利要求10所述的方法,其特征在于,生成所述语义模型包括提取所述帧的诸特征。
12.如权利要求11所述的方法,其特征在于,生成所述语义模型包括从所提取的诸特征生成伪语义域,其中所述伪语义域是从所述诸特征导出的n维空间。
13.如权利要求12所述的方法,其特征在于,生成所述语义模型包括通过为每个帧导出所述伪语义域中的坐标来将所述帧映射到所述伪语义域,所述坐标的每个元素与所述伪语义域的维度相对应并且是从所提取的诸特征中为所述帧所特有的特征的存在性导出的。
14.如权利要求10所述的方法,其特征在于,向所述帧指派相应的相关性得分包括从所述视频提取拍摄所述视频的人的行为指示符。
15.如权利要求10所述的方法,其特征在于,使用所述相应的相关性得分来初始化所述语义模型包括构建一图形,在所述图形中,节点对应于所述帧,节点值对应于所述帧的相应的相关性得分,而边缘按所述语义模型中确定的帧之间的距离倒数来加权。
16.如权利要求10所述的方法,其特征在于,包括:
以产生所述子场景的次序呈现包括所述子场景的用户界面;
从用户接收对子场景的丢弃选择;以及
从视频概括中丢弃所述子场景。
17.至少一种机器可读介质,所述至少一种机器可读介质包括指令,所述指令在被机器执行时,使所述机器执行用于自动视频概括的操作,所述操作包括:
获得视频;
从所述视频的帧生成所述视频的语义模型;
向所述帧指派相应的相关性得分;
使用所述相应的相关性得分初始化所述语义模型;以及
迭代地处理所述语义模型以产生子场景集合,每次迭代包括:
在初始化之后收敛所述语义模型;
在收敛之后选择具有最高相关性得分的帧序列;以及
通过固定所选帧序列的所述相关性得分来重新初始化所述语义模型。
18.如权利要求17所述的至少一种机器可读介质,其特征在于,生成所述语义模型包括提取所述帧的诸特征。
19.如权利要求18所述的至少一种机器可读介质,其特征在于,生成所述语义模型包括从所提取的诸特征生成伪语义域,其中所述伪语义域是从所述诸特征导出的n维空间。
20.如权利要求19所述的至少一种机器可读介质,其特征在于,生成所述语义模型包括通过为每个帧导出所述伪语义域中的坐标来将所述帧映射到所述伪语义域,所述坐标的每个元素与所述伪语义域的维度相对应并且是从所提取的诸特征中为所述帧所特有的特征的存在性导出的。
21.如权利要求20所述的至少一种机器可读介质,其特征在于,生成所述语义模型包括从映射到所述伪语义域的所述帧创建生成模型。
22.如权利要求21所述的至少一种机器可读介质,其特征在于,创建所述生成模型包括通过将具有最高得分的帧添加到所述帧集合来递归地标识所述帧中的关键帧集合,所述帧的得分是针对所述关键帧集合的所有成员就所述帧的坐标的平方范数乘以常数然后除以所述帧与所述关键帧集合中的帧之间的距离的范数的平方进行的求和的倒数。
23.如权利要求17所述的至少一种机器可读介质,其特征在于,向所述帧指派相应的相关性得分包括从所述视频提取拍摄所述视频的人的行为指示符。
24.如权利要求17所述的至少一种机器可读介质,其特征在于,使用所述相应的相关性得分来初始化所述语义模型包括构建一图形,在所述图形中,节点对应于所述帧,节点值对应于所述帧的相应的相关性得分,而边缘按所述语义模型中确定的帧之间的距离倒数来加权。
25.如权利要求17所述的至少一种机器可读介质,其特征在于,所述指令包括:
以产生子场景的次序呈现包括所述子场景的用户界面;
从用户接收对子场景的丢弃选择;以及
从视频概括中丢弃所述子场景。
- 还没有人留言评论。精彩留言会获得点赞!