互联网信息收集及关联方法与流程
本发明涉及一种互联网信息处理方法,尤其涉及一种互联网信息收集及关联方法。
背景技术:
随着互联网的快速发展以及数据收集技术的不断发展,大数据时代早已到来。但随着网络的迅速发展而带来的网上信息量的大幅增长,使得用户在面对大量信息时无法从中获得对自己真正有用的那部分信息,对信息的使用效率反而降低了,这就是所谓的“信息超载”(informationoverload)问题。如何帮助用户在海量的数据中快速找到对其有价值的信息,并让网络中的暗信息能够被用户获得成为急需解决的问题。
目前,推荐系统是主动地从大量信息中找到用户可能感兴趣的信息的工具,是构建支持用户在线决策的系统。在信息爆炸时代,推荐系统是解决用户“信息过载”的一种有效手段。随着互联网移动技术的发展,推荐系统已经渗透到人们的衣食住行中。为用户提供快捷访问的优质推荐,正是推荐系统研究领域的主要目标。近年来,推荐系统被广泛应用到很多领域,如电子商务、音频视频网站、音乐电台、社交网络、个性化阅读、个性化广告、基于位置的服务和移动推荐等,并催生了很多新兴的推荐技术,涌现出一些著名的推荐系统,如Amazon的个性化产品推荐、Netflix的视频推荐、Pandora的音乐推荐、Facebook的好友推荐和Google Reader的个性化阅读等。推荐系统广泛应用在电子商务、大规模零售业和各种知识管理应用中,不仅给运营商带来了利益,也给用户带来了诸多便利。推荐个性化、匹配度高的产品或项目是推荐系统领域的核心问题,它最早可追溯到认知科学、近似理论、信息检索、预测理论、管理科学和市场中的客户选择模型等。鉴于推荐系统的理论和实际应用价值。近年来国际学术界与其相关的研究极为活跃。推荐系统研究的顶级会议是美国计算机学会(ACM)每年举办的RecSys年会,该会议自2007年以来已在世界各地举办了8届,并成为全球关于推荐系统研究最重要的交流渠道和把脉其最新进展的重要窗口。最近一次ACM RecSys年会于2014年10月6~10日于美国硅谷(第8届)举办,共收录各国学者研究论文55篇,内容基本涵盖了当前RS研究的主流领域,既有对传统领域的深入探讨,也有对新领域的探索;既有对实践和技术的应用研究,也有推荐基本理论和方法的探析。
传统推荐系统的用户画像是通过网络爬虫收集数据,先通过数据预处理,再通过权重,衰减因子的方式筛选出消费者,其权重因子的分配模糊,具有主观性,导致筛选出的结果不尽人意;当属性值很多时,权重的赋值变的更为困难,导致通过算法筛选出的结果不符合精准营销的目的,即找不到潜在的消费者或者潜在的消费者在结果中所占比例很低。
技术实现要素:
本发明的目的就在于为了解决上述问题而提供一种精准度高的互联网信息收集及关联方法。
本发明通过以下技术方案来实现上述目的:
一种互联网信息收集及关联方法,包括以下步骤:
(1)构建指标体系:先根据某个个体的互联网信息确定各种分类指标信息并分别设定为x0*、x1*、x2*…xn*,这里的个体的互联网信息包括基本信息、行为信息和偏好信息;
(2)根据漏斗模型求目标集:设h(x)是顾客的样本空间(x0、x1、x2…xn),g(x)是假设空间(x0*、x1*、x2*…xn*),对于该个体的互联网信息,可以根据如下公式求出总得分值:
其中,ll(·)是指示函数,若·为真则取值1,否则取值0,
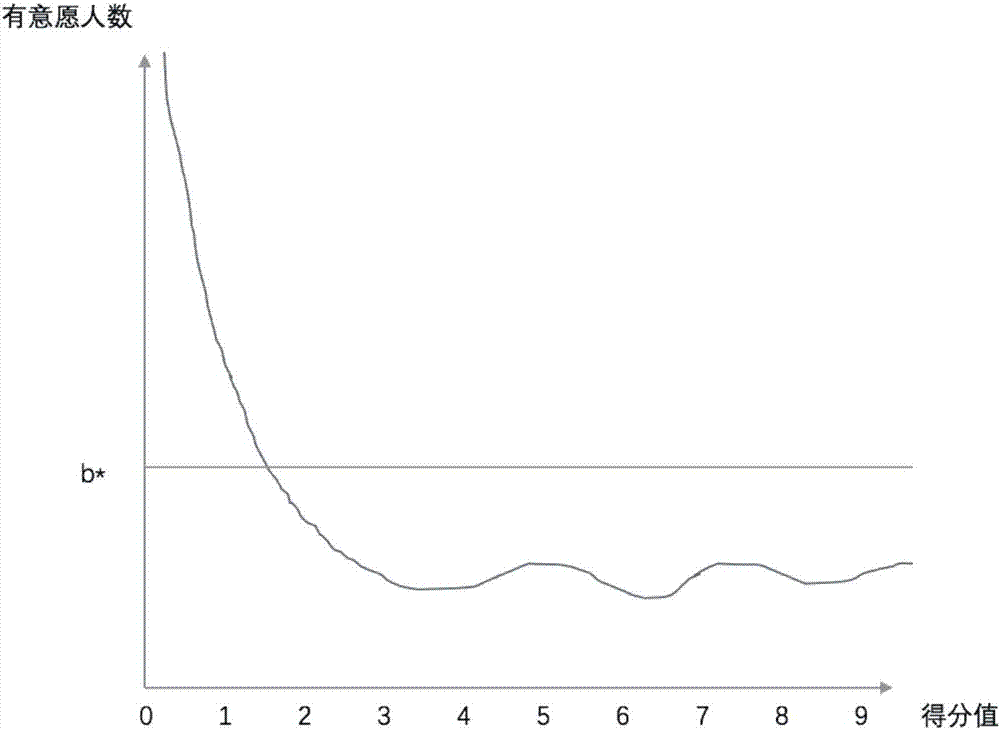
然后把不同得分值的个体分到不同的类别中去,把E=a,a[0,n],aI N*归为一个集合,记为Ea,然后画出得分值与有意愿个体数比例的x-y图;
设定有意愿个体数阀值为b*,大于b*的Ea留下,小于的b*的Ea剔除,得到关于E的集合O1,设定有意愿个体数比例阀值为c*,大于c*的Ea留下,小于的c*的Ea剔除,得到关于E的集合O2;令Oa=O1I O2,求得Oa;
(3)关联规则求目标集:包括以下步骤:
(3.1)找出所有频繁项集:频繁项集定义:项的集合称为项集,包含k个项的项集称为k-项集,项集的出现频率是包含项集的事务数,简称为项集的频率、支持计数或计数,如果项集满足最小支持度阀值,即项集的出现频率大于或等于支持度与数据库事务集合中的事务总数的乘积,则称它为频繁项集,频繁k-项集的集合记作Lk;利用Apriori算法找出所有频繁项集;
(3.2)由频繁项集产生关联规则,具体方法如下:
(3.2.1)对于每个频繁项集L,产生L的所有非空子集S;
(3.2.2)对于L的每个非空子集S,如果
P(L)/P(S)≧min_conf,
其中,P(L)是包含频繁项集L的事务数,P(S)是包含非空子集S的事务数,min_conf是最小置信度阈值,
则输出关联规则
其中,L-S表示在频繁项集L中除去非空子集S后的项集;
(3.2.3)找到与关联规则对应的个体集合Ob;
(4)获取最终目标集:O=OaUOb;
(5)输出目标集O=OaUOb。
具体地,所述步骤(3.1)中,利用Apriori算法找出所有频繁项集的具体方法为:
(3.1.1)连接步:为找Lk,通过Lk-1与自己连接产生候选k-项集的集合,该候选项集的集合记作Ck,设l1和l2是Lk-1中的项集,记号li[j]表示li的第j项,假定事务或项集中的项按字典次序排序,执行连接Lk-1I Lk-1,其中,Lk-1的元素是可连接的,如果它们前(k-2)个项相同,即,Lk-1的元素l1和l2是可连接的,如果(l1[1]=l2[1])∧(l1[2]=l2[2])∧...∧(l1[k-2]=l2[k-2])∧(l1[k-1]<l2[k-1]),条件(l1[k-1]<l2[k-1])是简单地保证不产生重复,连接l1和l2产生的结果项集是l1[1]l1[2]...l1[k-1]l2[k-1];
(3.1.2)剪枝步:Ck是Lk的超集,即它的成员可以是也可以不是频繁的,但所有的频繁k-项集都包含在Ck中,扫描数据库,确定Ck中每个候选的计数,从而确定Lk,为压缩Ck,用以下方法使用Apriori性质:任何非频繁的(k-1)-项集都不可能是频繁k-项集的子集,因此,如果一个候选k-项集的(k-1)-子集不在Lk-1中,则该候选也不可能是频繁的,从而可以由Ck中删除。
本发明的有益效果在于:
本发明采用漏斗模型并排除了传统主观赋值权重的影响,使得目标集最逼近客观事实,使得本系统能很好抓取我们所需的目标集;本发明还采用关联规则apriori算法,保证模型的支持度和置信度的情况下,逻辑严密,排出无关集合,保留全部目标集,从而找到符合我们意愿的目标集;漏斗模型和apriori算法两种方法筛选数据具有单一规则无法比拟的优势,目标集更好地接近预期,显著提高了互联网信息收集及关联的精准度。
附图说明
图1是本发明所述互联网信息收集及关联方法的流程图;
图2是实施例中得分值与有意愿人数的x-y图;
图3是实施例中得分值与有意愿人数比例的x-y图。
具体实施方式
下面结合实施例和附图对本发明作进一步说明:
为了便于理解,下面以“从顾客在购买汽车方面留下的互联网信息中收集和关联有用信息”为例,对本发明进行具体阐述。
如图1所示,具体的互联网信息收集及关联方法包括以下步骤:
(1)构建指标体系:先根据某个顾客的互联网信息确定各种分类指标信息并分别设定为x0*、x1*、x2*…xn*,这里的个体的互联网信息包括基本信息、行为信息和偏好信息;更具体地,指标体系构建如下:
x0*=年龄:25《=年龄《=50,
x1*=收入:15《=收入,
x2*=“汽车”搜索行为,
x3*=“具体品牌”搜索行为,
x4*=“具体车系”搜索行为,
x5*=“具体车系询价”行为,
x6*=“具体车型”搜索行为,
x7*=“具体车型”询价行为,
x8*=“具体车型”参与pk行为,
x9*=网页停留时间》=60s行为。
(2)根据漏斗模型求目标集:设h(x)是顾客的样本空间(x0、x1、x2…x9),g(x)是假设空间(x0*、x1*、x2*…x9*),对于该个体的互联网信息,可以根据如下公式求出总得分值:
其中,n取9,ll(·)是指示函数,若·为真则取值1,否则取值0,
然后把不同得分值的个体分到不同的类别中去,把E=a,a[0,9],aI N*归为一个集合,记为Ea,然后画出得分值与有意愿人数的x-y图,如图2所示,以及得分值与有意愿人数比例的x-y图,如图3所示;
设定有意愿个体数阀值为b*,大于b*的Ea留下,小于的b*的Ea剔除,得到关于E的集合O1,设定有意愿个体数比例阀值为c*,大于c*的Ea留下,小于的c*的Ea剔除,得到关于E的集合O2;令Oa=O1I O2,求得Oa。
(3)关联规则求目标集:包括以下步骤:
(3.1)找出所有频繁项集:频繁项集定义:项的集合称为项集,包含k个项的项集称为k-项集,项集的出现频率是包含项集的事务数,简称为项集的频率、支持计数或计数,如果项集满足最小支持度阀值,即项集的出现频率大于或等于支持度与数据库事务集合D中的事务总数的乘积,则称它为频繁项集,频繁k-项集的集合记作Lk;利用Apriori算法找出所有频繁项集,其具体方法为:
(3.1.1)连接步:为找Lk,通过Lk-1与自己连接产生候选k-项集的集合,该候选项集的集合记作Ck,设l1和l2是Lk-1中的项集,记号li[j]表示li的第j项,假定事务或项集中的项按字典次序排序,执行连接Lk-1I Lk-1,其中,Lk-1的元素是可连接的,如果它们前(k-2)个项相同,即,Lk-1的元素l1和l2是可连接的,如果(l1[1]=l2[1])∧(l1[2]=l2[2])∧...∧(l1[k-2]=l2[k-2])∧(l1[k-1]<l2[k-1]),条件(l1[k-1]<l2[k-1])是简单地保证不产生重复,连接l1和l2产生的结果项集是l1[1]l1[2]...l1[k-1]l2[k-1];
(3.1.2)剪枝步:Ck是Lk的超集,即它的成员可以是也可以不是频繁的,但所有的频繁k-项集都包含在Ck中,扫描数据库,确定Ck中每个候选的计数,从而确定Lk,为压缩Ck,用以下方法使用Apriori性质:任何非频繁的(k-1)-项集都不可能是频繁k-项集的子集,因此,如果一个候选k-项集的(k-1)-子集不在Lk-1中,则该候选也不可能是频繁的,从而可以由Ck中删除;
(3.2)由频繁项集产生关联规则:
一旦由数据库事务集合D中的事务找出频繁项集,由它们产生强关联规则是直接了当的,强关联规则满足最小支持度和最小置信度,对于置信度Confidence,可以用下获取,其中条件概率用项集支持度计数表示:
其中,P(AB)是包含项集A和B的事务数,P(A)是包含项集A的事务数;根据该式,由频繁项集产生关联规则的具体方法如下:
(3.2.1)对于每个频繁项集L,产生L的所有非空子集S;
(3.2.2)对于L的每个非空子集S,如果
P(L)/P(S)≧min_conf,
其中,P(L)是包含频繁项集L的事务数,P(S)是包含非空子集S的事务数,min_conf是最小置信度阈值,
则输出关联规则本例中即为S(购买汽车),
其中,L-S表示在频繁项集L中除去非空子集S后的项集;
(3.2.3)找到与关联规则对应的顾客集合Ob。
(4)获取最终目标集:O=OaUOb;
(5)输出目标集O=OaUOb。
为了便于理解Apriori算法的相关技术,下面作进一步介绍:
基本概念:
设I={i1,i2,...,im}是项的集合,设任务相关的数据D是数据库事务集合,其中每个事务T是项的集合,使得每一个事务有一个标识符,称作TID。设A是一个项集,事务T包含A当且仅当关联规则是形如的蕴涵式,其中并且规则在事务集D中成立,具有支持度s,其中s是D中事务包A∩B(即A和B二者)的百分比,它是概率P(AB)。规则在事务集D中具有置信度c,如果D中包含A的事务同时也包含B的百分比是c,这是条件概率P(B|A),即:
support(支持度)
cinfidence(置信度)
同时满足最小支持度阈值即min_sup和最小置信度阈值即min_conf的规则称作强规则。为方便计,用0%和100%之间的值,而不是用0到1之间的值表示支持度和置信度。
项的集合称为项集,包含k个项的项集称为k-项集,项集的出现频率是包含项集的事务数,简称为项集的频率、支持计数或计数。如果项集满足最小支持度阀值min_sup,即项集的出现频率大于或等于support(支持度)与D中事务总数的乘积,则称它为频繁项集;频繁k-项集的集合通常记作Lk。
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法;该算法的名字基于这样的事实:算法使用频繁项集性质的先验知识,正如我们将看到的。Apriori使用一种称作逐层搜索的迭代方法,k-项集用于探索(k+1)-项集。首先,找出频繁1-项集的集合,该集合记作L1;L1用于找频繁2-项集的集合L2,而L2用于找L3,如此下去,直到不能找到频繁k-项集。找每个Lk需要一次数据库扫描。
为提高频繁项集逐层产生的效率,一种称作Apriori性质的重要性质用于压缩搜索空间,介绍该性质如下:
Apriori性质:频繁项集的所有非空子集都必须也是频繁的;Apriori性质基于如下观察:根据定义,如果项集I不满足最小支持度阈值s,则I不是频繁的,即P(I)<s;如果项A添加到I,则结果项集即I∪A不可能比I更频繁出现。因此,I∪A也不是频繁的,即P(I∪A)<s。
该性质属于一种特殊的分类,称作反单调,意指如果一个集合不能通过测试,则它的所有超集也都不能通过相同的测试。称它为反单调的,因为在通不过测试的意义下,该性质是单调的。
上述实施例只是本发明的较佳实施例,并不是对本发明技术方案的限制,只要是不经过创造性劳动即可在上述实施例的基础上实现的技术方案,均应视为落入本发明专利的权利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!