一种基于深度学习与局部特征融合的哈希图像检索方法与流程
本发明涉及基于内容的图像检索领域,特别是一种基于深度学习与局部特征融合的哈希图像检索方法。
背景技术:
如何将大规模图像数据进行高效检索以满足用户需求是一个亟待解决的问题,传统的方式是视觉词袋模型的图像检索,就是先使用尺度不变特征变换描述子对图像进行特征提取,然后使用硬聚类算法(K-Means)进行局部特征聚类得到视觉词典,最后统计每个视觉词出现的频率生成视觉单词直方图,进而匹配计算图像相似度,由于视觉词袋模型最初提取的特征是传统手工描述子,所以抽取的特征比较低级,无法很好的描述图像的高层语义信息,导致返回的图像可能完全不是用户所需要的,造成很差的用户体验。
近些年,深度学习在各种计算机视觉任务中都取得了重大的突破,其中包括基于内容的图像检索任务,其目的是直接通过分析图像内容来检索图像,在检索任务中图像的特征表达与相似性的度量成为了图像检索中的关键任务。随着基于内容的图像检索的发展,一个具有挑战性的问题是从相关联的像素级信息去抽象出便于人类感知的语义信息。尽管已经有很多手工描述子被研究出来用于提取图像特征,如尺度不变特征变换描述子,曾经在人脸识别广泛应用的局部二值模式高效算子,还有行人检测中的方向梯度直方图特征描述子等,由于它们是浅层特征,所以视觉特征的描述能力非常有限。随着深度学习的发展,卷积神经网络可以提取含有高层语义信息级别的特征,并渐渐应用到图像检索领域,如直接用训练好的AlexNet网络的最后一个全连接层特征进行图像检索,可获得不错的精度。然而,卷积神经网络提取的特征虽然语义丰富,但对于大规模图像集而言所需要的匹配计算量,内存占用以及时间开销显然是用户不可接受的。而图像特征经过哈希编码后,相似度的度量从高维浮点型的欧式距离计算转化为低维哈希码的汉明距离计算,极大的减少了计算成本和时间开销。另外,基于深度学习的图像检索一般是提取最后一个卷积层或全连接层的特征直接进行相似度计算,导致最后检索出的结果虽然是语义同类的图像,但是图像间的局部细节并不相似,因为高层的特征已经损失了很多细节信息,例如在电商中进行纹饰服装箱包搜索、工业精密器件搜索以及植物叶片搜索时,图像在整体轮廓上相似而细节差距却很大,导致检索结果可能与用户所期望的结果不一致。
技术实现要素:
本发明的主要目的在于克服现有技术中的上述缺陷,提出一种基于深度学习与局部特征融合的哈希图像检索方法,通过使用局部特征融合的方法将网络中不同层的特征图谱进行融合,使得到的特征同时含有高层的抽象语义信息和低层的局部细节信息;同时,为了加快图像检索速度,使用了近似最近邻搜索策略,相较于目前主流方法,这种基于深度学习与局部特征融合的哈希图像检索方法具有精确度高、检索速度快的特点。
本发明采用如下技术方案:
一种基于深度学习与局部特征融合的哈希图像检索方法,包括如下步骤:
1)将输入的图像进行预处理,依次对每张图像进行去均值化、裁剪和镜像;
2)将预处理后的图像构建成三元组的形式输入到深度卷积网络进行训练;
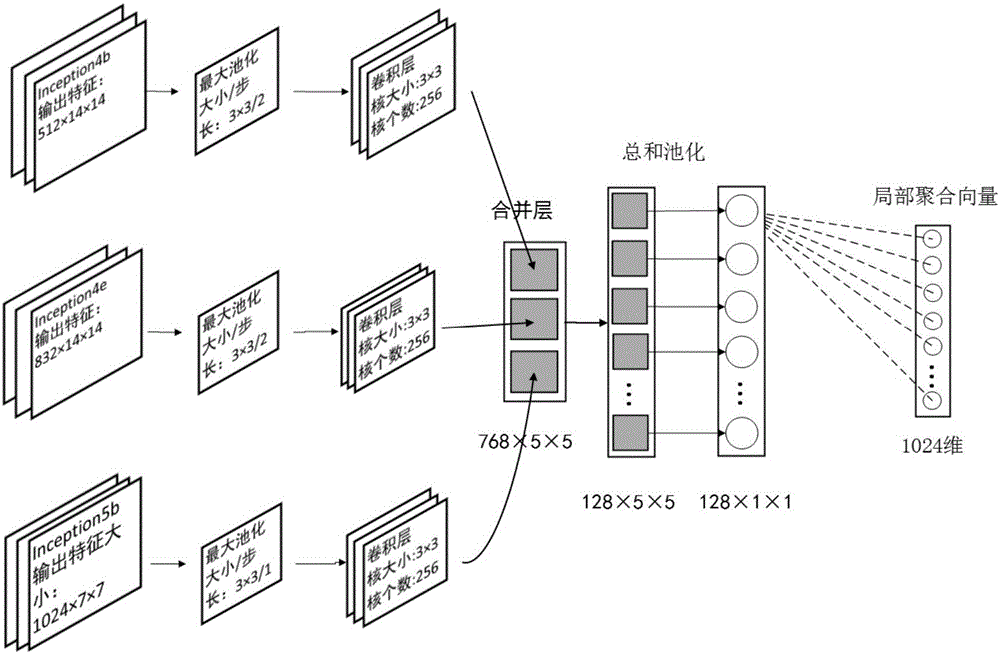
3)将GoogLeNet模型中inception 4b层、inception 4e层和inception 5b层输出的特征图分别进行最大值池化和卷积处理,然后使用合并层将处理后的特征图进行拼接;
4)将合并层输出的特征图进行卷积核大小为1×1的卷积操作,得到大小为128×5×5的特征图;
5)将1×1卷积操作后的特征图进行总和池化处理,即对每一个特征图的所有元素值进行累加,并将128个特征图连接成一个128维的向量,向量每个维度上的值对应单个特征图的所有元素总和值;
6)将输出的大小为128×1×1的特征图经过一个结点个数为1024的全连接层映射,得到1个1024维的局部聚合向量;
7)将得到的局部聚合向量输入到哈希映射层,并利用感知哈希算法计算得到哈希码;
8)将得到的局部聚合向量进行L2范数归一化,归一化后的向量使用三元组损失形成约束优化,并与交叉熵损失函数同时进行训练。
步骤1)中所述预处理,包括:将输入的图像重置大小为256×256,对每一个图像进行裁剪,裁剪的是图片中央、4个角以及镜像共10张图片并去均值化,依次处理所有输入的训练图像,从而得到的每一个图像大小为224×224。
步骤2)中所述构建三元组的形式,包括:首先从训练数据集中随机选一个样本锚点,然后再随机选取一个和锚点属于同一类的正样本和不同类的负样本,由此构成三元组(锚点,正样本,负样本),则对应的损失函数L可表示为:
其中与分别表示锚点、正样本与负样本的特征向量;N表示网络训练的批大小;+表示括号内式子的值大于零的时候取该值为损失,反之则损失为零;α表示为可接受的不同类样本间的距离间隔。
步骤3)中,将GoogLeNet网络中的inception 4b、inception 4e和inception 5b输出的特征图进行最大值池化和卷积处理,分别得到3个尺度为256×5×5的特征图,采用合并层对这些特征图进行合并,生成大小为768×5×5的特征图。
步骤5)中,所述将1×1卷积操作后的特征图进行总和池化处理,其表达式如下:
其中H、W分别为特征图的高度与宽度,x、y为特征图的空间坐标,I是输入的特征图,则f(x,y)表示特征图I上对应点(x,y)的值,总和池化实际上是对得到的每一个特征图I进行累加求和,如果有n个特征图,最终会生成一个n×1×1的特征向量。
步骤7)中,所述利用感知哈希算法计算得到哈希码,包括:定义哈希映射层的输出特征向量V(v1,v2,...,vm),通过均值感知哈希算法计算阈值得到二进制哈希码特征向量H(h1,h2,...,hm),表示式如下:
其中,1≤j≤m。
步骤8)中,所述将得到的局部聚合向量进行L2范数归一化,包括:定义局部聚合向量Y(y1,y2,...,yp),将归一化后的向量表示为Y'(y1',y'2,...,y'p),归一化操作的表达式如下:
其中,1≤k≤p。
本发明具有如下有益效果:
本发明使用深度学习模型训练并进行特征提取,将不同层的局部特征进行融合,使提取的特征不仅含有高层语义信息还具有局部细节信息,并用近似最近邻搜索策略进行图像检索,实现快速高效的图像检索任务。
以下结合附图及实施例对本发明作进一步详细说明,但本发明的一种基于深度学习与局部特征融合的哈希图像检索方法不局限于实施例。
附图说明
图1是本发明的深度学习网络结构示意图;
图2是局部特征融合操作示意图;
图3是图像检索框架流程图;
图4是基于深度学习的两步快速分层图像检索示意图;
图5是在CIFAR-10数据集上48位哈希码图像检索精度图;
图6是在CIFAR-10数据集上Top10的图像检索结果图;
图7是在LEAVESDATA-85数据集上植物叶片图像检索结果图。
具体实施方式
以下通过具体实施方式对本发明作进一步的描述。
图1是本发明的深度学习网络结构示意图。本发明的网络模型框架是基于GoogLeNet网络结构改进而来的深度卷积网络,深度卷积网络结构如图1所示,网络包含五个部分:输入部分、卷积子网络部分、局部特征融合部分、哈希层编码部分以及损失函数部分。输入部分包含图像和对应的标签,且图像以三元组的形式输入;卷积子网络部分使用GoogLeNet网络的卷积部分,同时包含原有的3个损失层;局部特征融合模块主要由卷积层和池化层以及一个合并层与全连接层组成;哈希层编码部分由一个全连接层和阈值分割模块组成,全连接层个数为哈希码位数;损失函数部分主要由一个三元组损失函数与交叉熵函数组成并一起训练。
其中,哈希层中全连接层采用随机初始化,此时哈希层类似于局部敏感哈希思想,使用随机映射来构建哈希码,全连接层的节点个数代表哈希码的位数,每个节点可以类似看做一个超平面。经过哈希映射层的输出特征向量V(v1,v2,...,vm),通过均值感知哈希算法计算阈值得到二进制哈希码特征向量H(h1,h2,...,hm),表示式如下:
其中,1≤j≤m。
损失层通过同时优化三元组损失函数和交叉熵损失函数来端到端的学习局部融合特征与哈希层的特征。三元组损失度量方法可在训练过程中尽可能缩小两个相同类物体之间的距离,并扩大两个不同类物体之间的距离。三元组的生成首先从训练数据集中随机选一个样本锚点,然后再随机选取一个和锚点属于同一类的正样本和不同类的负样本,由此构成三元组(锚点,正样本,负样本),则对应的损失函数L可表示为:
这里损失用欧式距离进行度量,与分别表示锚点、正样本与负样本的特征向量,N表示网络训练的批大小,式子最后的正号表示括号内式子的值大于零的时候取该值为损失,反之则损失为零,其中α表示为可接受的不同类样本间的距离间隔。
图2是局部特征融合操作示意图,即将GoogLeNet网络中不同层得到的特征图谱进行融合,这样不仅利用了高层特征的抽象语义信息,还考虑到了低层特征的细节纹理信息,是检索结果更加精确,包含如下步骤:
1)将GoogLeNet网络中3个inception层(inception 4b、inception 4e、inception 5b)的特征图谱提取出来分别使用最大池化层进行最大值池化,其中inception 4b和inception 4e层后的最大池化层的大小为3×3,步长为2,扩充边缘为0,输出的特征图大小分别为512×7×7和832×7×7;inception 5b使用大小为3×3,步长为1,扩充边缘为1的最大池化层计算,输出大小为1024×7×7的特征图。
2)将池化后的特征图分别使用卷积层进行卷积操作,其中卷积核的大小为3×3,步长为1,输出3个大小为256×5×5的特征图。
3)用合并层将卷积处理后的3个相同个数和尺度特征图进行拼接,得到大小为768×5×5的特征图。
4)使用大小为1×1的卷积核对拼接后的特征图进行卷积操作,生成大小为128×5×5的特征图,其中卷积层的步长为1,扩充边缘为0,卷积核个数为128。
5)使用总和池化层对上步得到的特征图进行池化操作,池化层大小为5×5,步长为1,扩充边缘为0,生成大小为128×1×1的特征向量,其表达式如下:
其中H、W分别为特征图的高度与宽度,x、y为特征图的空间坐标,I是输入的特征图,则f(x,y)表示特征图I上对应点(x,y)的值,总和池化实际上是对得到的每一个特征图I进行累加求和,如果有n个特征图,最终会生成一个n×1×1的特征向量。这里H和W取值为5,n为128,得到一个128×1×1维的向量。
6)在上步得到的128×1×1特征向量后紧接一个结点个数为1024的全连接层,得到1024维局部聚合向量并对其进行L2范数归一化,定义局部聚合向量为Y(y1,y2,...,yp),将归一化后的向量表示为Y'(y1',y'2,...,y'p),归一化操作的表达式如下:
其中,1≤k≤p。
图3是图像检索框架流程图。图像的检索过程就是先对图像数据库的图像进行去均值预处理操作,然后抽取每张图像的哈希码与局部聚合特征,存储与数据库中。对于待检索的图像,先去均值然后用同样的方式抽取哈希码与特征向量。在进行相似度匹配时,先找出哈希码相同或相近的图像进行粗检索,然后利用局部聚合向量进行精检索并重排,最终返回重排结果。
图4是基于深度学习的两步快速分层图像检索示意图。第一步,在对指定图像进行检索之前,需要先使用准备的数据集对网络进行微调,微调前应更改网络中对应4个分类层的结点数为数据集的类别个数,然后提取所有数据集的哈希码与局部聚合特征。第二步,利用微调好的网络对需要检索的图像进行前向计算,取出哈希码与局部聚合特征。在粗检索阶段,利用二进制哈希码计算图像相似度时使用汉明距离,给定一个检索图像Ir和它的二进制哈希码Hr(h1,h2,...,hn),定义一共有m个候选类,即有m个哈希桶,将汉明距离低于阈值的图像归到一个哈希桶里面。在精检索阶段,给定检索图像Ir与粗检索阶段生成的哈希码,将哈希桶内所有图像的高维局部聚合向量提取出来。计算查询图像的局部聚合向量Vr与哈希桶内所有图像的欧氏距离Disti,表示为:
Disti=||Vr-ViK|| (5)
其中K表示返回给用户的图像个数,Vi表示哈希桶内前K个图像特征的局部聚合向量,最后对距离Disti进行升序重排,返回的前K个图像即为检索结果。
一实施例之中,分别在CIFAR-10,NUS-WIDE和LEAVESDATA-85三个数据集上进行实验并评估。CIFAR-10数据集包含了马、飞机、船等10个类别,每个类别包含6000张图像,共有60000张图像,每张图像的大小是32×32像素,其中训练集有50000张图像,测试集有10000张图像。NUS-WIDE是一个网络图像数据集,包含269648张图像,每张图像会从81个类别中选择一个或多个类别进行标记,其中训练集包含161789张图像,测试集包含张107859图像。LEAVESDATA-85是一个植物叶片数据集,一共有38067张图像共85类植物叶片,其中训练集包含33817张图片,测试集包含4250张图片。
为了评估图像检索性能并与已有的方法作比较,采用了MAP(Mean Average Precision)平均精度均值度量方法,计算过程主要分为两步,第一步计算AP(Average Precision)平均准确度,对不同召回率上的正确值进行平均。定义检索有N个相关结果,经过检索系统返回K个相关图像,其位置分别为x1,x2,...xK,则单个类别的平均准确度APi表示为:第二步对AP进行算术平均,定义图像类别数为M,则平均精度均值MAP为:
图5给出不同哈希方法在CIFAR-10数据集上的检索精度图,实验统一使用48位哈希码,并利用汉明距离度量图像间的相似性。从图5中可看出检索精度稳定在0.92附近,比核监督哈希方法(KSH)提高了47%,比主流的基于深度学习的哈希方法(CNNH+)提高了32%,比目前最优的快速二值哈希方法(DLBHC)提高了3%,本发明方法明显优于其他哈希方法。
图6给出了在CIFAR-10数据集上两张查询图像的Top10检索结果,由图6可看出48位哈希码成功检索出了类别和语义相似的图像,当哈希码从48位变成128位时,更倾向于检索出外观上更相似的图像,最后一行是利用1024维的局部聚合向量进行重排序得到更加精确的结果。
图7展示了在LEAVESDATA-85数据集上检索植物叶片返回的结果。实验证明,本发明方法在图像细粒度分类与检索上也具有很好的效果。
表1给出了本发明方法分别在CIFAR-10与NUS-WIDE数据集上不同哈希位检索得到的平均检索精度值。由表可知,与其他现有方法相比,发明算法在CIFAR-10数据集上检索精度达到最优,各个哈希位的平均检索精度值都达到了0.92以上。另外在NUS-WIDE数据集上采用81个概念类别图像进行训练,本发明方法的平均检索精度同样高于其他算法。
表1
本实施例中,在GPU为Tesla K40c的机器上提取单张图像卷积特征花费0.072s,检索过程使用CPU进行计算,利用1024维特征向量直接检索需要0.614s。若使用48位哈希码进行粗检索耗时为0.023s,在粗检索之后进行精检索的耗时约为0.009s,可得使用本发明方法检索图像总耗时约为0.032s,相比于其他方法,检索质量和速度都有很大的提高,可以满足用户的日常需求,并且随着图像集的增大,近似最近邻搜索策略的高效性会更加突出。
上述仅为本发明的具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明保护范围的行为。
- 还没有人留言评论。精彩留言会获得点赞!