一种基于NORFLASH阵列的卷积运算方法与流程
本发明属于半导体集成电路及其制造技术领域,更具体地,涉及一种基于NOR FLASH阵列的卷积运算方法。
背景技术:
卷积运算作为一种线性运算,在信号和系统方面占据非常重要的地位,包括图像识别、地震勘测、超声诊断、人工智能等系统中广泛存在着卷积运算。这些系统中的卷积运算具有计算量大、数据通量大和计算方式固定等特点。利用传统的通用处理器CPU做卷积计算,存在计算效率低、速度慢,无法满足数据实时处理的需求。利用GPU做卷积方案也存在硬件开销资源大的问题。近年来,人工智能迅速发展,对卷积运算的需求呈海量增加,因此必须发展一种高效卷积运算方式。
技术实现要素:
(一)要解决的技术问题
鉴于上述问题,本发明基于NOR flash结构提出一种能够高效卷积运算的方法,可以实现NOR flash乘法计算,NOR flash阵列卷积运算以及NOR flash卷积运算的并行执行。
(二)技术方案
一种基于NOR FLASH阵列的卷积运算方法,所述NOR FLASH阵列包括多个NOR flash单元组成的二维阵列,包括以下步骤:
S1:将卷积核矩阵的元素存储到NOR flash单元中;
S2:输入矩阵的元素转换成电压施加在NOR flash单元的栅端,同时在NOR flash单元的源端施加一个驱动电压,NOR flash单元的漏端输出电流;
S3:由NOR flash单元漏端的输出电流得到卷积运算结果。
上述方案中,在所述S1中,分别经字线、公共源线和位线向NOR flash单元的栅端、源端和漏端施加电压,将卷积核矩阵元素写入到NOR flash单元中。
上述方案中,当卷积核矩阵元素为1或者-1时,NOR flash单元的阈值电压被调整为低阈值电压;当卷积核矩阵元素为0时,NOR flash单元阈值电压被调整为高阈值电压。
上述方案中,在所述S2中,
将输入矩阵元素转换为电压,电压通过字线输入到NOR flash单元的栅端,同时通过公共源线向NOR flash单元的源端施加驱动电压。
上述方案中,
当输入矩阵元素为1时,所述电压为NOR flash单元的高阈值电压与低阈值电压之和的二分之一;当输入矩阵元素为0时,所述电压为0。
上述方案中,在所述S3中,NOR flash单元漏端的输出电流经位线汇集至运算放大器,运算放大器输出端的值构成输出矩阵,得到卷积运算结果。
上述方案中,与正位线连接的NOR flash单元漏端的输出电流输入到运算放大器的正输入端,与负位线连接的NOR flash单元漏端的输出电流输入到运算放大器的负输入端,运算放大器输出端的值为输出矩阵元素。
上述方案中,所述NOR FLASH阵列还包括多条字线、多条位线和公共源线;
每一行的NOR flash单元的栅端通过字线相连,每一列的NOR flash单元的漏端通过位线相连,NOR flash单元的源端由一条公共源线相连
上述方案中,还包括多条源线,每一行的NOR flash单元的源端通过源线相连,每条源线连接到公共源线。
上述方案中,输入矩阵大小为m×m,卷积核矩阵大小为n×n,得到的输出矩阵大小为(m-n+1)×(m-n+1)。
(三)有益效果
本发明基于NOR flash阵列提出一种能够高效卷积运算的方法,利用NOR flash结构实现乘法计算,利用NOR flash阵列实现卷积运算以及卷积运算的并行高效执行,本发明计算效率高、可满足数据实时处理的需求。
附图说明
图1是矩阵卷积原理示意图;
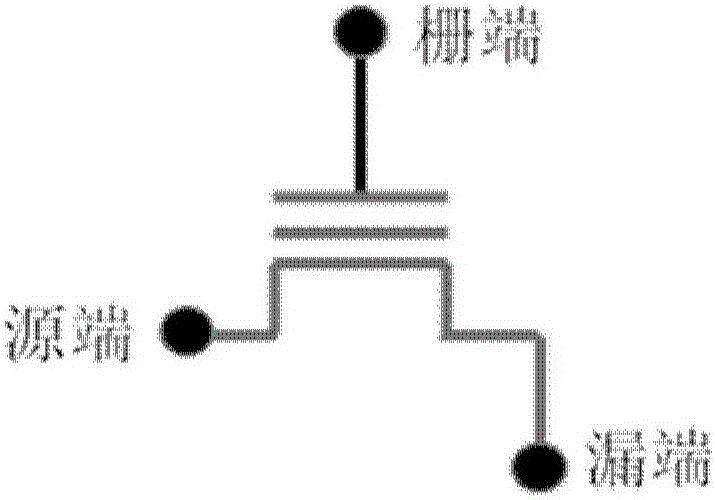
图2是本发明实施例的NOR flash单元示意图;
图3是本发明实施例的NOR flash阵列作卷积计算的示意图;
图4是本发明实施例的基于NOR FLASH阵列的卷积运算设备示意图;
图5为本发明实施例的基于NOR flash阵列的卷积运算方法流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明作进一步的详细说明。
卷积是一个广义的积分概念,在数字信号处理、概率论、图像处理等领域都有广泛的应用。图1的是一个5×5大小的输入矩阵经过一个2×2大小的卷积核矩阵处理之后得到的4×4大小的输出矩阵的计算过程示意图。输入矩阵中的元素用xi,j表示,元素为x1,1~x5,5,卷积核矩阵中各元素用fi,j表示,元素为f1,1~f2,2,输出矩阵中元素用yi,j表示,元素为y1,1~y4,4。首先要对卷积核矩阵进行翻转,即旋转180度操作,然后将翻转后的卷积核矩阵首先与输入矩阵的左上角部分重叠,之后计算该重叠部分的对应元素乘积并求和,作为第一个输出结果,即输出矩阵中的元素y1,1=x1,1·f2,2+x1,2·f2,1+x1,1·f1,2+x2,2·f1,1;之后翻转后的卷积核矩阵向x方向(行方向)右移一位,继续计算重叠部分的乘积和作为下一个输出结果,直到x方向全部重叠过,则卷积核矩阵向y方向(列方向)平移一位并平移到x方向的起始点进行计算,重复以上过程直至输入矩阵中的元素全被卷积核矩阵覆盖过,输出矩阵中元素yi,j可由公式yi,j=xi,j·f2,2+xi,j+1·f2,1+xi+1,j·f1,2+xi+1,j+1·f1,1表示,可得到16个输出结果,因此输出矩阵的大小为4×4。对于一个m×m大小规模的输入矩阵,经由一个n×n(m>n)大小规模的卷积核矩阵进行卷积操作之后得到的输出矩阵大小为(m-n+1)×(m-n+1)规模。
本发明的目的是提供一种利用NOR Flash阵列来进行卷积运算的方法。NOR FLASH阵列包括多个NOR FLASH单元,NOR Flash单元可以通过PROGRAM/ERASE(编程/擦除)操作来改其阈值电压,从而存储不同的逻辑值。当进行PROGRAM操作时,NOR Flash衬底的电子在栅压的控制下会通过隧穿层到浮栅层中,从而造成NOR flash单元的阈值电压上升;而当进行ERASE操作时,在栅压的控制下电子会从浮栅层出去或有空穴进入到浮栅层中,此时阈值电压下降。
卷积运算当中存在大量乘法运算,图2所示是一个三端的NOR flash单元,包括一个栅端、一个漏端和一个源端。首先通过图2来说明如何用NOR flash单元进行乘法运算。通过ERASE或PROGRAM操作可以将NORflash单元的阈值电压调整为高阈值电压(Vth_high)或低阈值电压(Vth_low)。对于A×B(A为卷积核矩阵元素,为乘数,B为输入矩阵元素,为被乘数)的二进制运算来说,A值可以通过编程或擦除写入到NOR flash单元中,B值在运算过程转化为电压加载在栅端上,A,B两个的值共同决定了NOR flash单元的开启状态,在NOR flash的源端加载一个电压,根据每个NOR flash单元不同的开启状态,可以得到不同大小的电流,收集每列NOR flash单元对应的漏端电流即可得到乘法运算的结果。这里的flash单元可以是传统的闪存,也可以是新型电荷捕获闪存。
NOR flash阵列结构如图3所示,对于5×5大小的输入矩阵、2×2大小的卷积核矩阵、4×4大小的输出矩阵的卷积运算,NOR flash阵列结构为NOR flash单元组成的25行32列的二维阵列,其中包含沿第一方向延伸的互相平行的16组位线,每组位线包括两条位线,每条位线与一列25个NOR Flash单元的漏端相连;沿与第一方向交叉的第二方向延伸的25条相互平行的字线,每条字线与一行32个NOR Flash单元的栅端相连;每个NOR Flash单元的源端由源线连接至一条公共源线,16个运算放大器,每个运算放大器连接一组位线,每组位线的一条位线作为正位线连接运算放大器的正输入端,另一条位线作为负位线连接运算放大器的负输入端。
卷积核矩阵的元素存储在NOR flash单元中,输入矩阵的元素转换成电压通过字线输入栅端,在NOR flash阵列的公共源端施加一个驱动电压通过漏端收集电流进行卷积运算。卷积运算中的乘法运算由每一个NORFlash单元完成,同一位线上的电流汇集到一起实现卷积运算中加法运算。位线的一端接运算放大器,对汇集的电流转换成输出结果。由于卷积核矩阵中通常具有负数元素,因此对于每一个输出矩阵的元素,我们需要两列互相平行的NOR Flash单元,两条位线中的一条作为正输出线,将卷积核矩阵正元素对应写入该位线连接的NOR flash单元中,该位线连入运算放大器的正输入端,另一条位线作为负输出线,将卷积核矩阵中的负元素对应写入该位线连接的NOR flash单元中,该位线连入运算放大器的负输入端,这两列NOR flash单元中每一列的漏端通过位线分别连接到运算放大器的两个输入端,这样运算放大器的输出与正负电流的加和成正比,通过电流差分来实现具有负值卷积核矩阵元素的卷积的运算。上述只是作为举例,实际应用中输入矩阵及卷积核矩阵可扩展成任意规模的矩阵,相应地,NOR flash阵列应扩展为与输入矩阵及卷积核矩阵适应的规模。
图4是基于NOR FLASH阵列的卷积运算设备,包括NOR flash阵列、控制器、字/源线控制单元、位线控制单元、输入模块和输出模块,其中字/源线控制单元的第一端连接NOR flash阵列的字线和源线,另一端连接输入模块,字/源线控制单元包含多个脉冲发生器和选通器,多个脉冲发生器与字线和源线连接,由选通器选通不同的字线或源线施加电压,位线控制单元的第一端连接NOR flash阵列的位线,另一端连接到输出模块,位线控制单元包含多个脉冲发生器和选通器,脉冲发生器与位线连接,由选通器选通不同的位线施加电压,输入模块包括多个信号发生器,输出模块包括多个运算放大器。
控制器接收控制信号对字/源线和位线控制单元进行控制,分别对字线、源线和位线实现不同的输入和输出,从而实现卷积核矩阵元素的写入和卷积运算以及在这两种操作之间的切换。首先控制器控制字/源线控制单元和位线控制单元对NOR Flash阵列施加电压进行擦除以及编程操作,将卷积核矩阵元素写入到NOR Flash阵列中;在NOR Flash阵列中存储卷积核矩阵后,通过控制器控制输入模块将输入矩阵元素转换成电压信号,将电压信号传输至字/源线控制单元,由字/源线控制单元中的脉冲发生器产生电压通过字线施加到NOR Flash阵列中,同时在公共源线上施加驱动电压,在NOR Flash阵列中漏端相连的位线输出的电流经过运算放大器的处理得到卷积结果。
如图5所示,本发明实施例的基于NOR flash阵列的卷积运算方法为:
S1:将卷积核矩阵的元素存储到NOR flash单元中;
在控制器的控制下,分别经字线、公共源线和位线向栅端、源端和漏端施加电压,把乘数(卷积核矩阵元素)的值,写入到NOR flash单元中。如果乘数为1或者-1,则将NOR flash单元的阈值电压调整为低阈值电压Vth_low,如果乘数为0,则将NOR flash单元阈值电压调整为高阈值电压(Vth_high)。
在本发明实施例中,我们选择Roberts算子作为卷积核,此时f1,1=-1,f1,2=0,f2,1=0,f2,2=1,我们把Roberts算子的值写入到如图3所示的NOR flash阵列中。
对于卷积核矩阵中存在负数元素的情况,可将每组两条位线接入一个运算放大器来实现实数域卷积核的计算,具体规则如下:两条位线中的一条作为正输出线,将卷积核矩阵正元素按位对应写入该位线连接的NORflash单元中,该位线连入运算放大器的正输入端,如图3所示,将f2,2写入到与y1,1对应的运算放大器“+”端相连的位线和V11对应的字线交叉点处的NOR flash单元;另一条位线作为负输出线,将卷积核矩阵中的负元素按位对应写入该位线的NOR flash单元中,该位线连入运算放大器的负输入端,如图3所示,将f1,1写入到与y1,1对应的运算放大器“-”端相连的位线和V22对应的字线交叉点处的NOR flash单元,这样运算放大器的输出与正负电流的加和成正比,可以实现实数域的卷积核的计算。
对于本发明实施例中,采用Roberts算子作为卷积核矩阵进行计算时输出矩阵中元素yi,j可由公式yi,j=xi,j-xi+1,j+1计算得到。
S2:输入矩阵的元素转换成电压施加在NOR flash单元的栅端,同时在源端施加一个驱动电压,NOR flash单元的漏端输出电流;
本发明实施例中,输入矩阵采用5×5大小的矩阵,各元素用xi,j表示,将输入矩阵转换成为电压值并通过字线输入到如图3所示的NOR flash单元的栅端,元素xi,j对应输入电压的大小用Vij表示。
作乘法运算时,将输入矩阵一维展开,分别将大小为V11到V55的25个代表输入矩阵元素的电压输入到25条互相平行的字线上,如果输入矩阵元素为1,Vij则取为(Vth_high+Vth_low)/2;如果输入矩阵元素为0,Vij则为0。
同时在公共源端处施加驱动电压VS,通过NOR flash单元输出电流的大小判断运算结果,如果乘数为1或者-1,即NOR flash单元的阈值电压为低阈值电压Vth_low,同时被乘数为1,即Vij为(Vth_high+Vth_low)/2,则NOR flash单元处于开启状态,漏端的输出电流较大,表示输出结果为1或者-1;对于乘数为0或被乘数为0的情况,NOR flash单元处于关断状态,漏端的输出电流较小,表示输出结果为0。
S3:由NOR flash单元漏端的输出电流得到卷积运算结果。
NOR flash单元漏端的输出电流经位线汇集至运算放大器,运算放大器输出端的值构成输出矩阵,得到卷积运算结果。
利用运算放大器搜集来自输出矩阵元素y1,1对应的正负两列位线的电流值,正的卷积核元素所在列上的NOR flash单元输出的电流输入到运算放大器的“+”端,负的卷积核元素所在列上的NOR flash单元输出的电流输入到运算放大器的“-”端,放大器输出端的值构成输出矩阵。对于输出矩阵的y1,1,其值为:x1,1·f2,2+x1,2·f2,1+x2,1·f1,2+x2,2·f1,1,其中f1,1=-1,f1,2=0,f2,1=0,f2,2=1,因此输出端y11对应的运算放大器“+”端相连的位线和V11对应的字线交叉点处的NOR flash单元写入到Vth_low状态,为叙述简单,此单元定义为1单元;与输出y1,1的放大器“-”端相连的位线和V22输入的字线交叉点处设置的NOR flash单元写入到Vth_low状态,此单元定义为2单元;其他与输出y1,1的放大器相连的NORflash单元写入到Vth_high状态。在卷积运算过程,由于代表输入矩阵的输入电压要不为0,要不为(Vth_high+Vth_low)/2,因此除1,2单元外,其他与输出y1,1的放大器相连的单元始终处于关闭状态,单元1,2根据输入矩阵中x11,x22的值决定是否开启。如果x1,1或x2,2的值为1,则对应单元1/2开启;如果x1,1或x2,2的值为0,则对应单元1/2关闭。根据电流差分电流放大器的原理,则其输出y1,1可以表示为x1,1·f2,2+x1,2·f2,1+x2,1·f1,2+x2,2·f1,1,其中f1,1=-1,f1,2=0,f2,1=0,f2,2=1,实现了卷积运算。对于输出矩阵中的其他元素原理是一样的,可得到y1,1到y4,4,将输出矩阵元素编码排列即可得到如图1所示的输出矩阵。
在实际场景应用中,需要做同样卷积运算的矩阵很多,此时在一次矩阵卷积运算完成了,只需要不断地将需要作卷积计算的矩阵输入即可,无须再输入卷积核。当需要对矩阵做不同类型卷积运算再改写卷积核。如果在实际场景应用中,需要对同一个矩阵作不同的卷积运算,可以采用多个NOR flash阵列写入对应的卷积核,然后同时输入运算矩阵和输出运算结果,实现并行计算,进一步提高运算效率。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!