基于熵值法的改进协同过滤推荐算法的制作方法
本发明属于个性化推荐技术领域,涉及一种基于熵值法的协同过滤推荐算法。
背景技术:
协同过滤算法是应用最为广泛的个性化推荐算法,最早应用于新闻推荐系统和邮件过滤系统,目前被广泛应用于电子商务领域。典型的协同过滤算法应用案例包括国外的amazon推荐系统以及国内的豆瓣、淘宝、京东等购物网站。除此之外,youtube等视频网站、facebook等社交网站也采用协同过滤技术来提高服务质量。
协同过滤算法通过比较用户的历史行为(评分、购买历史、浏览次数、在某网页上的停留时间等),发现用户的相关性,或者物品本身的相关性,然后基于这些关联性进行推荐。目前协同过滤算法主要包含两种技术:基于用户的协同过滤(ubcf)和基于项目的协同过滤(ibcf)。ubcf的基本思想是通过分析用户的历史行为数据,找出与目标用户兴趣相似的邻居用户群,然后根据其邻居集对项目的评分预测目标用户对项目的评分,最后选择评分最高的若干个项目推荐给目标用户,它基于假设:喜欢相似物品的用户可能有相同偏好。ibcf的基本思想是通过分析用户的历史行为数据,找出与目标项目相似的邻居项目集,根据当前用户对近邻项目集的评分预测当前用户对目标项目的评分,把目标项目推荐给评分最高的若干个用户,它基于假设:若多数用户对一些项目的评分比较相似,则当前用户对这些项目的评分也相似。
技术实现要素:
针对现有技术中存在的不足,本发明提供了一种基于熵值法的改进协同过滤推荐算法,传统的基于用户的协同过滤算法(ubcf)在预测评分时仅仅利用用户间的相似度衡量其评分的影响,而把熵值法添加进ubcf后,同时考虑到了用户评分行为特征(评分次数多少、评分稳定性)对结果的影响。此外,考虑到两个用户在某类项目上的口味可能很接近,但是在另一类项目上的口味可能相差甚远,因此只针对与目标项目相似的项目进行用户间相似度的衡量,使得预测的评分结果更有说服力。
基于熵值法的改进协同过滤推荐算法,包括以下步骤:
步骤1,将用户对项目的评分记录的原始数据转换为用户-项目评分矩阵;
设原始数据中有n个用户,m个项目,则所述的用户-项目评分矩阵为:
步骤2,在用户-项目评分矩阵中,利用熵值法计算每个用户的权重,包括以下步骤:
步骤21,将用户-项目评分矩阵转置得到项目-用户评分矩阵;
所述项目-用户评分矩阵为:
步骤22,通过式(1)将a中的评分转换到[0,1]区间;
其中,i=1,2,…,m;j=1,2,…,n;
步骤23,通过式(2)得到第j个用户对第i个项目评分占该用户总评分的权重pij;
步骤24,通过式(3)得到第j个用户的权重;
其中,j=1,2,…,n;
gj为第j个用户的熵值冗余度:gj=1-ej;
ej为第j个用户的熵值:
步骤3,通过式(4)得到第j个项目与第i个项目的相似度,j=1,2…,n;
其中,sim(i,j)为第i个项目与第j个项目的相似度,uij为同时评论过第i个项目与第j个项目的所有用户集合,xpi为第p个用户对第i个项目的评分,
选择与第i个项目相似度最高的k1个项目作为第i个项目的最近邻居集ci,1≤k1<m;
步骤4,通过式(5)得到第v个用户与第u个用户的相似度;
其中,u=1,2,…,n;v=1,2,…,n;u≠v;sim(u,v,i)为第v个用户与第u个用户基于第i个项目的相似度;ui为第v个用户与第u个用户同时有过评分的项目集与第i个项目的最近邻居集ci的交集;
选择与第u个用户相似度最高的k2个用户作为第u个用户的最近邻居集uu,1≤k2<n;
步骤5,通过式(6)得到预测第u个用户对第i个项目的评分;
其中,wj为第j个用户的权重,sim(u,j,i)为第u个用户与第j个用户基于第i个项目的相似度,xji为第j个用户对第i个项目的评分。
进一步地,所述步骤1中的评分记录包括实际的项目的评分、浏览项目的次数、在包含项目的网页上停留的时间。
进一步地,所述步骤24中的
与现有技术相比,本发明具有以下技术效果:
本发明在不改变现实数据的基础上,充分利用稀疏的现有数据,把用户的活跃程度作为衡量该用户对目标用户预测评分影响力的一个因素,同时考虑用户评分行为的稳定性,越活越、越不稳定的用户影响力越高,反之影响力越低。通过实验证明,本发明的方法可以提高推荐结果的准确性。
附图说明
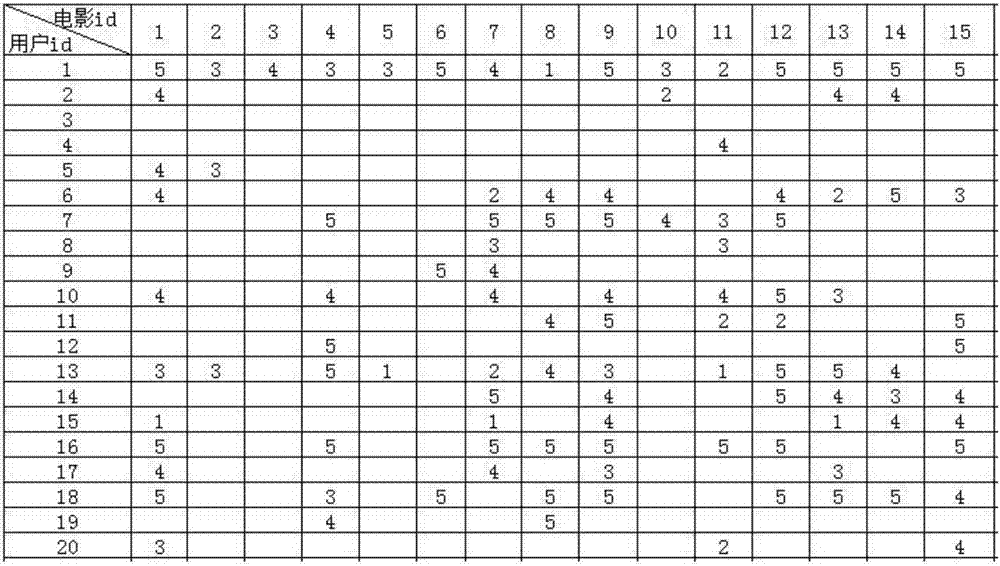
图1为实施例所采用数据集的原始数据示例;
图2为实施例所采用数据集的原始数据转换为的用户-项目评分矩阵;
图3为实施例运行结果示例;
图4为实施例本方法与传统方法的误差对比。
具体实施方式
下面通过附图和实施例对本发明作进一步说明。
实施例1
本实施例提供了基于熵值法的改进协同过滤推荐算法,包括以下步骤:
步骤1,将用户对电影的评分记录的原始数据转换为用户-项目评分矩阵。
设原始数据中有n个用户,m个电影,则所述的用户-项目评分矩阵为:
本实施例选取movielens数据集中的数据作为原始数据,如图1所示;本实施例中m为1682,n为943;图1中的原始数据转换为用户-项目评分矩阵后如图2所示。
步骤2,在用户-项目评分矩阵中,利用熵值法计算每个用户的权重,包括以下步骤:
步骤21,将用户-项目评分矩阵转置得到项目-用户评分矩阵;
所述项目-用户评分矩阵为:
步骤22,通过式(1)将a中的评分转换到[0,1]区间;
其中,i=1,2,…,1682;j=1,2,…,943;
步骤23,通过式(2)得到第j个用户对第i个电影评分占该用户总评分的权重pij;
步骤24,通过式(3)得到第j个用户的权重;
其中,j=1,2,…,943;
gj为第j个用户的熵值冗余度:gj=1-ej;
ej为第j个用户的熵值:
步骤3,设第i个电影为目标电影,通过式(4)得到第j个电影与目标电影i的相似度,j=1,2…,1682;
其中,sim(i,j)为目标电影i与第j个电影的相似度,uij为同时评论过目标电影i与第j个电影的所有用户集合,xpi为第p个用户对目标电影i的评分,
选择与目标电影i相似度最高的k1个电影作为目标电影i的最近邻居集ci,1≤k1<1682;
步骤4,通过式(5)得到第v个用户与第u个用户的相似度;
其中,u=1,2,…,n;v=1,2,…,n;u≠v;sim(u,v,i)为第v个用户与第u个用户基于目标电影i的相似度;ui为第v个用户与第u个用户同时有过评分的电影集与目标电影i的最近邻居集ci的交集;
选择与第u个用户相似度最高的k2个用户作为第u个用户的最近邻居集uu,1≤k2<943;
步骤5,通过式(6)预测第u个用户对目标电影i的评分;
其中,wj为第j个用户的权重,sim(u,j,i)为第u个用户与第j个用户基于目标电影i的相似度,xji为第j个用户对目标电影i的评分。
本实施例中预测的目标用户对目标电影的评分如图3所示。
实验结果:
为了证明本发明方法的性能,本实施例中选取movielens中的ua.test文件作为测试集,其中该文件包含943个用户对1682部电影的评分记录,每个用户有10条评分记录,数据格式与图1相同,选用matlabr2014a作为实验平台进行了实验。部分运行结果如图3所示,该图显示了某给定目标用户对目标电影的预测评分与实际评分,由图可见本方法预测的评分与真实评分十分接近。
同时,为了证明本发明方法的优越性,利用平均绝对误差(mae)指标分别对本方法与传统的基于用户的协同过滤方法进行了评测,其中mae是常用的衡量算法性能的评测指标,计算公式如下:
其中,t为测试集合,pui为用户u对电影i的预测评分,在该实施例中即为score(u,i),qui为用户u对电影i的实际评分,|t|为测试集中的评分记录数,本实施例中为9430。两种方法的mae值如图4所示,该图显示了不同数目用户近邻情况下本方法与传统的基于用户的协同过滤方法的测试误差,由此可见:本方法相较于传统的基于用户的协同过滤方法,预测误差有了很大的降低。
- 还没有人留言评论。精彩留言会获得点赞!