基于可控塔式分解和字典学习的煤岩识别方法与流程
本发明涉及基于可控塔式分解和字典学习的煤岩识别方法,属于图像识别技术领域。
背景技术:
煤岩识别是指通过某种手段辨别煤炭和岩石的相关技术,它在采煤机滚筒高度调整、综采放顶煤过程控制、选煤厂矸石初步筛选等方面有着良好的应用前景。自20世纪中叶以来,中国、美国、南非、澳大利亚等世界主要产煤国在寻找或尝试煤岩识别技术上做了大量工作,涌现出γ射线探测法、雷达探测法、红外探测法、震动检测法、声音检测法等多种煤岩识别方法。然而复杂的地质条件、多样的采煤工艺、恶劣的开采环境等因素使得现有煤岩识别方法的通用性不强,成熟的煤岩识别方法一直没有问世。煤炭和岩石的视觉差异明显,而且同一矿区或矿井的煤炭种类和岩石种类相对单一,再加上图像识别技术日新月异,这就给从图像分析角度发明煤岩识别方法带来了机遇。
技术实现要素:
为了克服现有煤岩识别方法存在的不足,本发明提出基于可控塔式分解和字典学习的煤岩识别方法,该方法具有实时性强、识别率高、稳健性好等优点,能够进一步推进煤炭开采与加工的少人化甚至无人化。
本发明所述的煤岩识别方法采用如下技术方案实现,包括样本训练阶段和煤岩识别阶段,具体步骤如下:
RS1.在样本训练阶段,采集相同光照条件下的m幅煤炭样本图像和m幅岩石样本图像,截取不含非煤岩背景的子图像并对其进行灰度化处理,处理后的煤炭样本子图和岩石样本子图分别记为c1,c2,…,cm和r1,r2,…,rm;
RS2.采用面向可控塔式分解的3阶滤波器组分别对子图c1,c2,…,cm和r1,r2,…,rm进行N级可控塔式分解,每幅子图经过N级可控塔式分解以后得到4N个方向子带,子图经过第i级可控塔式分解以后的第d个方向子带记为其中i为可控塔式分解的级数序号,i=1,2,…,N,d为方向序号,d=0,1,2,3,分别对应0,这4个方向;
RS3.分别由步骤RS2所述的所有子图的4N个方向子带提取得到2m个20N维特征向量,然后构建样本特征矩阵Y=[y1,y2,…,ym,ym+1,ym+2,…,y2m]∈R20N×2m及其对应的类别标签向量u=[1,1,…,1,2,2,…,2]∈R1×2m,其中Y的前m列y1,y2,…,ym分别为c1,c2,…,cm的特征向量,Y的后m列ym+1,ym+2,…,y2m分别为r1,r2,…,rm的特征向量,u是由2m个整数构成的行向量,在u中,1代表煤炭,2代表岩石,Y的第k列20N维特征向量yk所属的煤岩类别由u的第k个整数元素uk表示,k=1,2,…,2m;
RS4.设置参数η1,η2,η3和字典原子数2τ,其中η1>0,η2>0,η3>0,τ≤m,利用Y和u进行字典学习,得到字典矩阵D、权重矩阵W和偏移行向量b;
RS5.在煤岩识别阶段,获取相同光照条件下拍摄的未知类别煤岩图像,截取不含非煤岩背景的子图像并对其进行灰度化处理,得到未知类别子图tx;
RS6.与上述步骤RS2类似,对tx进行N级可控塔式分解,得到4N个方向子带;
RS7.由步骤RS6所述的4N个方向子带,提取tx的20N维特征向量yx;
RS8.利用yx,η2和步骤RS4中字典学习完成以后得到的D,W,b,执行煤岩类别的判定。
步骤RS3和步骤RS7所述的20N维特征向量的数据结构采用的格式,T表示转置运算,20N维特征向量中的每一个α元素、β元素、γ元素、μ元素和δ元素可以分别表示为和i为可控塔式分解的级数序号,i=1,2,…,N,d为方向序号,d=0,1,2,3,分别对应0,这4个方向,和分别为的子带系数绝对值的均值和方差,和分别指在满足子带系数服从概率密度函数为
的非对称广义高斯分布条件下的α,β和γ参数,其中随机变量x为子带系数,t为积分变量,[0,+∞)为积分区间,e为自然常数。
步骤RS4所述的字典学习包括以下步骤:
RS31.构建初始字典矩阵D∈R20N×2τ,其中D的前τ列和后τ列分别从Y的前m列和后m列中随机抽取得到;
RS32.构建稀疏矩阵H∈R2τ×2m并用H=(DTD+η2I2τ)-1DTY初始化,其中I2τ为2τ阶单位矩阵,T表示转置运算,-1表示求逆运算,构建权重矩阵W∈R2τ×2和2维偏移行向量b并分别初始化为零矩阵和零向量;
RS33.把H的每一列视为1个2τ维数据样本,以u为与H相对应的类别标签向量,η1为正则化参数,通过学习线性支持向量机更新权重矩阵W和偏移行向量b;
RS34.对于H的前m列数据的更新,反复求问题描述为
的解h'∈R2τ×1,并用h'更新H的第k列hk,其中yk为Y的第k列,k=1,2,…,m,w1和w2分别为W的第1列和第2列,b1和b2分别为b的第1个元素和第2个元素,T表示转置运算;
RS35.对于H的后m列数据的更新,反复求问题描述为
的解h*∈R2τ×1,并用h*更新H的第k列hk,其中yk为Y的第k列,k=(m+1),(m+2),…,2m,w1和w2分别为W的第1列和第2列,b1和b2分别为b的第1个元素和第2个元素,T表示转置运算;
RS36.求问题描述为
的解D*∈R20N×2τ,其中||·||F为矩阵的Frobenius范数,为D*的第j列,j=1,2,…,2τ;
RS37.把H的每一列视为1个2τ维数据样本,以u为与H相对应的类别标签向量,η1为正则化参数,通过学习线性支持向量机更新权重矩阵W和偏移行向量b;
RS38.如果满足其中||·||F为矩阵的Frobenius范数,那么用D*更新D,接着执行步骤RS34-RS37;如果满足那么用D*更新D;
RS39.完成字典学习,输出D,W和b。
步骤RS8所述的执行煤岩类别的判定,包括以下步骤:
RS401.由hx=(DTD+η2I2τ)-1DTyx计算得到稀疏向量hx,其中T表示转置运算,I2τ为2τ阶单位矩阵,-1表示求逆运算;
RS402.如果满足(w1Thx+b1)≥(w2Thx+b2),那么判定tx为煤炭;反之,则判定tx为岩石。
附图说明
图1是基于可控塔式分解和字典学习的煤岩识别方法的基本流程图;
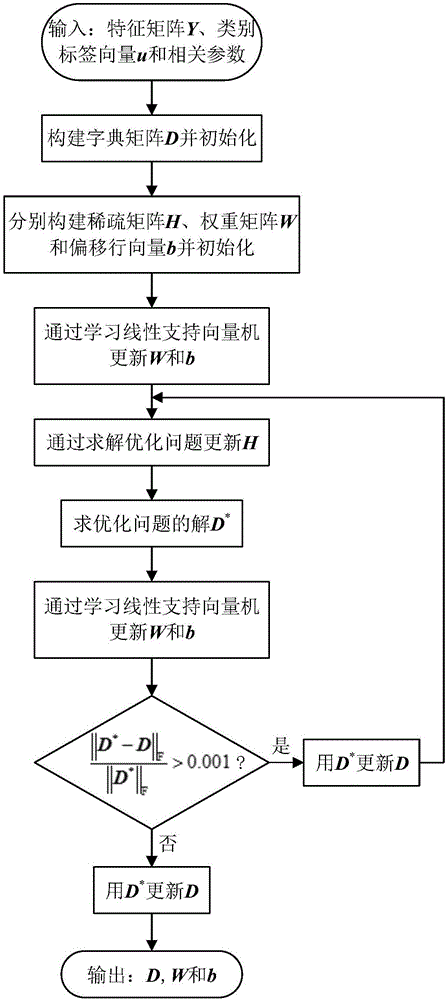
图2是本发明所述字典学习的基本流程图。
具体实施方式
在对我国山西、河南等地主要煤种和岩种的图像进行实验分析的基础上,本发明提出了基于可控塔式分解和字典学习的煤岩识别方法,该方法可以有效判别煤炭和岩石。下面结合附图和具体实施方式对本发明作进一步的详细描述。
参照图1,基于可控塔式分解和字典学习的煤岩识别方法的具体步骤如下:
SS1.在样本训练阶段,采集相同光照条件下的m幅煤炭样本图像和m幅岩石样本图像,截取不含非煤岩背景的子图像并对其进行灰度化处理,处理后的煤炭样本子图和岩石样本子图分别记为c1,c2,…,cm和r1,r2,…,rm;
SS2.采用面向可控塔式分解的3阶滤波器组分别对子图c1,c2,…,cm和r1,r2,…,rm进行N级可控塔式分解,每幅子图经过N级可控塔式分解以后得到4N个方向子带,子图经过第i级可控塔式分解以后的第d个方向子带记为其中i为可控塔式分解的级数序号,i=1,2,…,N,d为方向序号,d=0,1,2,3,分别对应0,这4个方向;
SS3.分别由步骤SS2所述的所有子图的4N个方向子带提取得到2m个20N维特征向量,然后构建样本特征矩阵Y=[y1,y2,…,ym,ym+1,ym+2,…,y2m]∈R20N×2m及其对应的类别标签向量u=[1,1,…,1,2,2,…,2]∈R1×2m,其中Y的前m列y1,y2,…,ym分别为c1,c2,…,cm的特征向量,Y的后m列ym+1,ym+2,…,y2m分别为r1,r2,…,rm的特征向量,u是由2m个整数构成的行向量,在u中,1代表煤炭,2代表岩石,Y的第k列20N维特征向量yk所属的煤岩类别由u的第k个整数元素uk表示,k=1,2,…,2m;
SS4.设置参数η1,η2,η3和字典原子数2τ,其中η1>0,η2>0,η3>0,τ≤m,利用Y和u进行字典学习,得到字典矩阵D、权重矩阵W和偏移行向量b;
SS5.在煤岩识别阶段,获取相同光照条件下拍摄的未知类别煤岩图像,截取不含非煤岩背景的子图像并对其进行灰度化处理,得到未知类别子图tx;
SS6.与上述步骤SS2类似,对tx进行N级可控塔式分解,得到4N个方向子带;
SS7.由步骤SS6所述的4N个方向子带,提取tx的20N维特征向量yx;
SS8.利用yx,η2和步骤SS4中字典学习完成以后得到的D,W,b,执行煤岩类别的判定。
步骤SS3和步骤SS7所述的20N维特征向量的数据结构采用的格式,T表示转置运算,20N维特征向量中的每一个α元素、β元素、γ元素、μ元素和δ元素可以分别表示为和i为可控塔式分解的级数序号,i=1,2,…,N,d为方向序号,d=0,1,2,3,分别对应0,这4个方向,和分别为的子带系数绝对值的均值和方差,和分别指在满足子带系数服从概率密度函数为
的非对称广义高斯分布条件下的α,β和γ参数,其中随机变量x为子带系数,t为积分变量,[0,+∞)为积分区间,e为自然常数。
参照图2,步骤SS4所述的字典学习包括以下步骤:
SS31.构建初始字典矩阵D∈R20N×2τ,其中D的前τ列和后τ列分别从Y的前m列和后m列中随机抽取得到;
SS32.构建稀疏矩阵H∈R2τ×2m并用H=(DTD+η2I2τ)-1DTY初始化,其中I2τ为2τ阶单位矩阵,T表示转置运算,-1表示求逆运算,构建权重矩阵W∈R2τ×2和2维偏移行向量b并分别初始化为零矩阵和零向量;
SS33.把H的每一列视为1个2τ维数据样本,以u为与H相对应的类别标签向量,η1为正则化参数,通过学习线性支持向量机更新权重矩阵W和偏移行向量b;
SS34.对于H的前m列数据的更新,反复求问题描述为
的解h'∈R2τ×1,并用h'更新H的第k列hk,其中yk为Y的第k列,k=1,2,…,m,w1和w2分别为W的第1列和第2列,b1和b2分别为b的第1个元素和第2个元素,T表示转置运算;
SS35.对于H的后m列数据的更新,反复求问题描述为
的解h*∈R2τ×1,并用h*更新H的第k列hk,其中yk为Y的第k列,k=(m+1),(m+2),…,2m,w1和w2分别为W的第1列和第2列,b1和b2分别为b的第1个元素和第2个元素,T表示转置运算;
SS36.求问题描述为
的解D*∈R20N×2τ,其中||·||F为矩阵的Frobenius范数,为D*的第j列,j=1,2,…,2τ;
SS37.把H的每一列视为1个2τ维数据样本,以u为与H相对应的类别标签向量,η1为正则化参数,通过学习线性支持向量机更新权重矩阵W和偏移行向量b;
SS38.如果满足其中||·||F为矩阵的Frobenius范数,那么用D*更新D,接着执行步骤SS34-SS37;如果满足那么用D*更新D;
SS39.完成字典学习,输出D,W和b。
步骤SS8所述的执行煤岩类别的判定,包括以下步骤:
SS401.由hx=(DTD+η2I2τ)-1DTyx计算得到稀疏向量hx,其中T表示转置运算,I2τ为2τ阶单位矩阵,-1表示求逆运算;
SS402.如果满足(w1Thx+b1)≥(w2Thx+b2),那么判定tx为煤炭;反之,则判定tx为岩石。
需要指出的是,以上所述实施实例用于进一步说明本发明,实施实例不应被视为限制本发明的范围。
- 还没有人留言评论。精彩留言会获得点赞!