一种基于并行快速FIR滤波器算法的卷积神经网络硬件加速器的制作方法
本发明设计计算机及电子信息技术领域,特别涉及一种基于并行快速fir滤波器算法的卷积神经网络硬件加速器。
背景技术:
卷积神经网络(cnn)是当今最流行的深度学习算法之一。由于它在图像和声音识别等方面卓越的表现,现已在学术和工业界被广泛地应用。将基于卷积神经网络算法的识别系统应用在本地处理器上有着巨大的前景,也是未来发展的方向。然而由于深度卷积神经网络有着很高的计算复杂度,一般专用的图形处理器才能做快速的训练和识别,但是并不能减少计算复杂度。卷积神经网络主要由卷积层、池化层和全连接层构成一个前馈架构,每一层接受上一层的输出当作其输入,并且提供自己的输出结果给下一层。卷积层中的卷积操作承担了卷积神经网络的大部分计算并且在实际应用中占据着主要的功耗。池化层分为最大池化和平均池化两种,一般现在使用的都是最大池化。
并行快速有限冲击响应(fir)算法(简称并行ffa)是算法强度缩减在并行fir滤波器中的应用。强度缩减利用共享子结构达到了缩减硬件复杂度的效果。在一个vlsi实现或者一个可编程dsp实现的迭代周期中,用这种变换可以降低硅面积和功耗。基于并行快速有限脉冲响应(fir)算法,本文设计了针对深度卷积神经网络的硬件加速器架构。基于并行快速fir算法的快速卷积单元能够在根本上减小卷积的计算复杂度并且同时输出多个神经元。
技术实现要素:
本发明旨在解决深度卷积神经网络计算复杂度高,并行度低等技术问题,或至少提出一种有用的商业选择。为此本发明的目的在于提出一种基于并行快速fir滤波器算法的卷积神经网络硬件加速器,用来完成卷积神经网络中的高复杂度卷积运算,并且在三种层面上提高计算并行度,提高数据吞吐率。
从该计算模块的整体上来看,其包含了:
1.p(设卷积核大小为k×k)个多用处理器,用于接收输入像素神经元,完成位宽转换、卷积、加法树、线性修正、最大池化等操作,并把结果存入相应的存储单元。
2.像素存储器,用于存储部分输入图片及特征图片。
3.权值缓存,用于缓存部分卷积核的权值。
4.附加存储器,用于存储输入图片和特征图片卷积计算的中间结果。
5.片外动态存储器,用于存储全部的卷积核权值和要处理的整幅输入图片。
在基于并行快速fir滤波器算法的卷积神经网络硬件加速器的一些实施例中,多用处理器包含了:
1.位宽转换器,用于将存储数据的位宽和计算数据的位宽进行转换,为了减小需要保存数据的存储器资源,存储数据和计算数据被设置成了不同的位宽大小。
2.t个卷积计算阵列,每个卷积计算阵列用于完成一幅图像的二维卷积。
3.加法压缩器,用于将多个卷积计算阵列的结果相加,功能类似于加法树,但比加法树高效的多。
4.线性修正单元,用于将偏置和加法压缩器计算的结果进行相加,并完成线性修正操作。
5.最大池化单元,用于完成最大池化操作。
在基于并行快速fir滤波器算法的卷积神经网络硬件加速器的一些实施例中,卷积计算阵列包含了:
k×(k-1)个快速卷积单元,每个快速卷积单元由并行快速fir算法导出,用于计算一幅输入图片或者特征图片某一行(列)上的一维卷积,每个快速卷积单元同时处理并同时输出k个特征图片像素(神经元)
附图说明
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
图1是本发明的加速器整体结构图。
图2是本发明中的多用处理器架构图。
图3是本发明中由快速卷积单元组成的卷积计算阵列图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出。其中自始至终使用相同的名称表示相同或有类似功能的模块。下面通过参考附图描述的实施示例来具体说明。
如图1所示为本发明的整体结构图。该基于并行快速fir滤波器算法的卷积神经网络硬件加速器包含了:
1.p(设卷积核大小为k×k)个多用处理器,用于接收输入像素神经元,完成位宽转换、卷积、加法树、线性修正、最大池化等操作,并把结果存入相应的存储单元。
2.像素存储器,用于存储部分输入图片及特征图片。
3.权值缓存,用于缓存部分卷积核的权值。
4.附加存储器,用于存储输入图片和特征图片卷积计算的中间结果。
5.片外动态存储器,用于存储全部的卷积核权值和要处理的整幅输入图片。
每个多用处理器用于生成一幅输出特征图片,因此整体架构可同时生成p幅输出特征图片。
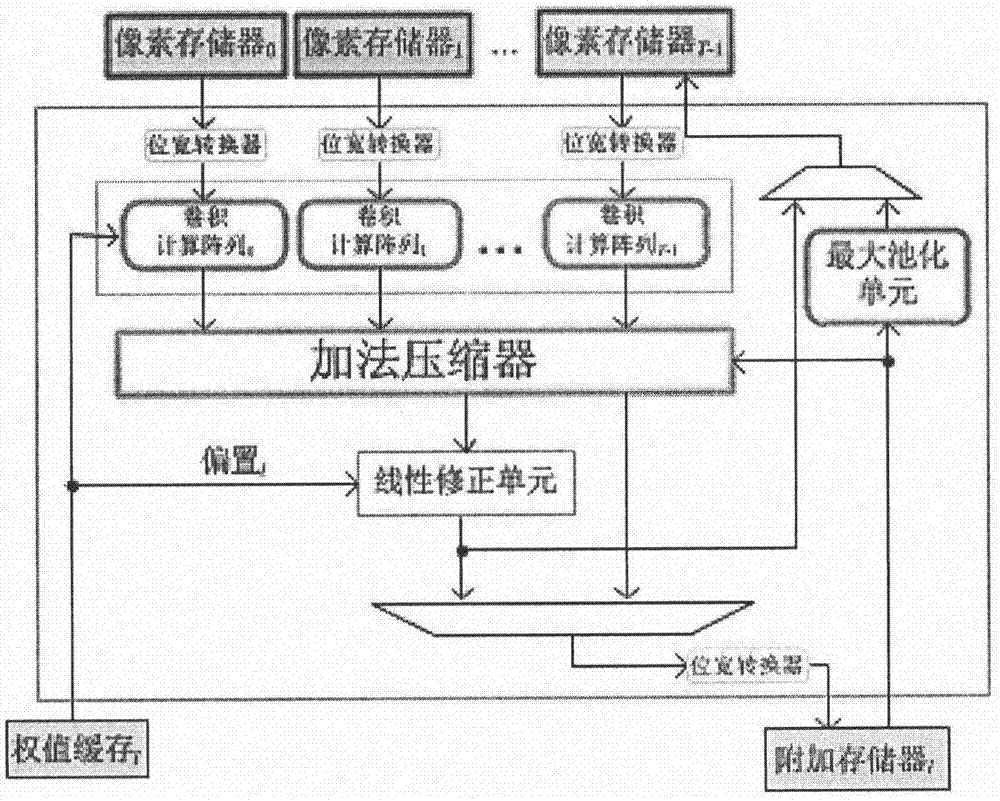
如图2所示是一个多用处理器的内部详细结构图,包含了:
1.位宽转换器,用于将存储数据的位宽和计算数据的位宽进行转换,为了减小需要保存数据的存储器资源,存储数据和计算数据被设置成了不同的位宽大小。
2.t个卷积计算阵列,每个卷积计算阵列用于完成一幅图像的二维卷积。
3.加法压缩器,用于将多个卷积计算阵列的结果相加,功能类似于加法树,但比加法树高效的多。
4.线性修正单元,用于将偏置和加法压缩器计算的结果进行相加,并完成线性修正操作。
5.最大池化单元,用于完成最大池化操作。
其中卷积计算阵列是多用处理器的核心计算单元,每个卷积计算阵列用于处理一幅输入特征图片,一个多用处理器包含了t个卷积计算阵列,因此可以同时处理t幅输入特征图片,整个处理器可以同时并行处理pt幅输入特征图片。由于输入特征图片是复用的,因此实际输入的特征图片只有t幅。
如图3所示,卷积计算阵列由k×(k-1)个快速卷积单元构成,每个快速卷积单元由并行快速fir算法导出,用于计算一幅输入图片或者特征图片某一行(列)上的一维卷积,每个快速卷积单元同时处理并同时输出k个特征图片像素(神经元)。由于一个二维k×k卷积是由k个一维卷积相加构成,因此一个卷积计算阵列可以同时并行处理(k-1)个二维卷积。
下面详述本处理器是如何在三个层面进行并行处理的:
在进行卷积计算时,在每个计算周期中,t幅输入特征图片,每幅特征图片的(2k-2)行,每行的k个像素同时输入,即同时输入t×(2k-2)×k个像素。
在行列并行层面,每个卷积计算阵列可以同时处理2k-2行(列)像素数据同时输出k-1行(列)像素数据;在每一行(列)的方向上,每个快速卷积单元可以同时处理k个像素数据,同时输出k个像素数据。
在层内并行层面,首先将像素存储器里的像素数据通过位宽转换器把位宽转换成快速卷积单元需要的位宽,然后t个卷积计算阵列同时处理t幅输入图像的2k-2行(列)像素数据,再通过加法压缩器将多个卷积计算阵列的结果相加,如果相加的和是中间结果,那么将中间结果存入附加存储器,如果相加的和是最终结果,那么将最终结果加上偏置,同时用线性修正单元将其进行修正,再将结果存入附加存储器。在将像素数据存入附加存储器之前,需要将数据位宽转换成存储数据位宽。最后,附加存储器中存储的像素数据根据不同的场合决定是否用最大池化单元对其进行最大池化,然后将结果存回像素存储器。这样就构成了一个完整的多用处理器,每个多用处理器输出一幅输出特征图片,整体架构由p个多用处理器构成,那么可以同时处理t幅输入图片同时生成p幅输出图片。
在层间并行层面,可以将多种不同的计算同时并行处理,例如,在进行卷积计算的同时,可以同时从片外动态存储器加载原始图像数据,也可以同时进行最大池化操作;当得到全连接层的部分输入图片像素数据后,在进行卷积或者最大池化操作的同时可以进行全连接层的乘加操作。
综上所述,利用本发明实施例提出的基于并行快速fir滤波器算法的卷积神经网络硬件加速器,可以有效地提高卷积神经网络的吞吐率,且能够有效地节省存储资源,适用于需要应用卷积神经网络算法进行实时处理的低功耗嵌入式系统。
尽管已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下载本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!