一种基于不充分模态信息的半监督网页自动分类方法与流程
本发明涉及一种新型的多模态半监督网页自动分类方法,属于计算机人工智能数据识别技术领域。
背景技术:
互联网中存在着大量数据,从这些数据中往往能够挖掘出许多有价值的信息,比如说,通过分析用户在新闻网站上的浏览记录,可以发现其感兴趣的新闻类型,从而更准确地为其推送新闻。为了对这些数据进行分析,经常需要对数量庞大的网页进行分类(例如将收集到的新闻根据其内容分成不同的类别),而手工分类的效率很低,会产生大量的人力成本,因此产生了使用计算机自动化分类的需求。机器学习技术是一类从数据中自动分析获得规律并对未知数据进行预测的技术。该技术通常需要在包含大量数据对象的训练集上构建预测模型。训练集中的每个数据对象都有一个代表其类别归属的类别标记,而通常获取这些标记需要人工参与,导致大量的人力消耗在标注训练集上。为此,机器学习领域中发展出了一类称为半监督学习的方法,该类方法利用大量未标注数据辅助少量有标注数据进行学习。网页数据的特点在于,每个网页的数据特征自然具有两种模态——网页本身的内容以及指向该网页的链接。但实际应用中训练数据的模态特征信息经常是不充分的,这使得一些训练数据与最优分类器不一致,从而导致学习算法的分类性能下降。本发明提出了一种基于新型的加权协同训练的半监督网页分类方法,该方法能够辨别出训练集中的那些可能导致算法性能下降的网页数据对象,并给它们赋予较低的权值,从而在实际应用中具有较高的分类准确率,且有更好的鲁棒性。此外,该方法可以利用未标记数据的信息,因而仅需要少量的有标记训练数据,可以进一步减少人力消耗,故具有更大的实用价值。
技术实现要素:
发明目的:实际应用中网页对象的模态信息往往是不充分的,这意味着有些训练样本的标记与该模态上的最优分类器可能会不一致,从而影响最终的性能,针对上述问题,本发明提出一种基于不充分模态信息的半监督网页自动分类方法,辨别出训练集中的那些可能导致算法性能下降的网页数据对象,并给它们赋予较低的权值,从而在实际应用中具有较高的分类准确率,且有更好的鲁棒性。
技术方案:本发明提出一种基于不充分模态信息的半监督网页自动分类方法,基于加权协同训练算法,通过给不同的数据分配不同的权值,包括如下步骤:
步骤1:构建训练数据集:选取网页对象库,其中的每个网页对象包含两个模态:即网页内容模态以及指向该网页的链接模态(部分研究者也将多模态数据称为多源数据),然后通过人工标注的方法为库中的少量网页对象提供一个类别标记,这些有类别标记的网页对象库称为初始的有标记训练数据,其和剩余的大量未标记网页对象一同构成训练数据集。
步骤2:提取网页对象特征:提取训练数据集中网页对象的特征,将所有网页对象转化成相应的特征向量,由于网页对象包含两个模态,最终得到的每个网页对象的特征向量也分为两部分,即双模态特征向量对。
步骤3:训练分类器:选择基分类器,将训练数据的双模态特征向量对和基分类器类型输入到加权协同训练算法中,训练后得到两个分类器。
步骤4:待测网页分类:提取待测网页在两个模态上的特征向量分别输入到训练得到的两个分类器中,得到待测网页的两个预测结果,再在两个预测结果中选择置信度较高的作为最终分类标记。
所述特征提取方法为选择网页文本中的每个词出现的次数作为该网页的特征,或者选择文本的长度作为该网页的特征,假设两个模态上特征的个数分别为d1和d2,那么每个网页对象就可以对应到d1和d2维欧式空间的两个特征向量。
所述基分类器包括支持向量机,决策树,神经网络。
所述加权协同训练算法包括如下步骤:
步骤3.1:选定每轮需要新标记的样本数目n,衰减系数α,最大迭代轮数t,松弛参数ξ;将迭代计数器初始化为t=0,将所有初始有标记训练数据的权值初始化为1/l,即两个模态上的权值向量为:
步骤3.2:判断是否达到最大迭代次数(即迭代次数是否满足t>t),若没有,则使用当前的分类器
步骤3.3:置步骤3.2中新标记样本的权值为
步骤3.4:分别在模态v=1,2求解下述优化问题,得到t+1轮迭代时需要的权值向量,再令迭代计数器t加1,转至步骤3.2进行下一轮训练,所述优化问题具体为:
其中,
步骤3.5:输出分类器
有益效果:与现有的技术相比,本发明通过考虑数据模态特征信息的不充分性,在训练分类器的过程中给数据分配不同的权值,避免了训练数据中不一致样本可能带来的负面影响,最终取得了良好的分类效果。此外,本发明可以利用未标记数据的信息,因此只需少量初始有标记训练数据,可以用于标记数据匮乏的场景,具有更大的实用价值。
附图说明
图1是本发明的原理图;
图2是本发明的流程图;
图3是本发明中加权协同训练算法的流程图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
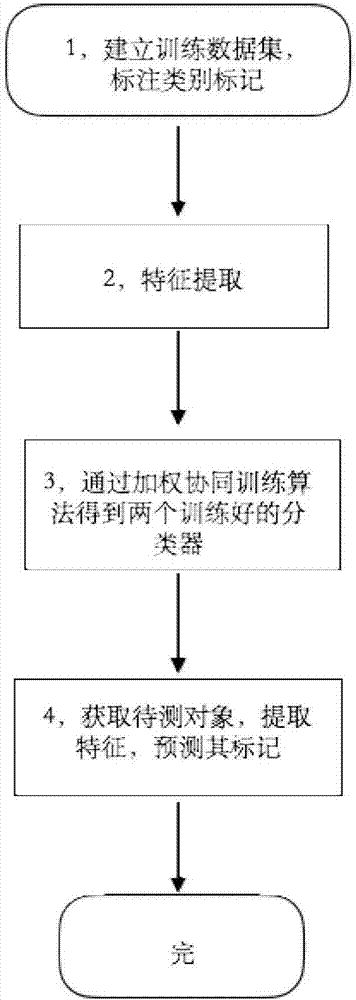
如图1所示,基于不充分模态信息的半监督网页自动分类方法:首先用户准备好一个包含网页信息的网页对象库,并且通过人工标注的方法为少量网页对象提供一个类别标记,将这个网页对象库称为训练数据集。然后,通过特征提取算法,将训练网页对象库中的对象转化成相应的特征表示,即提取网页对象库中对象的特征,将所有网页对象转化成相应的特征向量。接着选择要使用的基分类器类型,然后将训练数据的特征表示和类别标记一起输入到加权协同训练算法中,经过训练后就可以得到最终的分类器。最后在预测阶段,将待测的网页对象的特征向量输入给分类器,分类器就会给用户返回该对象的预测标记。
如图2-3所示,本发明的基于不充分模态信息的半监督网页自动分类方法,基于加权协同训练算法,通过给不同的数据分配不同的权值,提高分类精度和鲁棒性,具体包括如下步骤:
步骤1,建立一个包含n个网页信息的网页对象库作为训练数据集,通过人工标注的方式为对象库中的少量网页对象赋予一个类别标记,使用yi代表第i个对象的类别标记。对于二分类问题,比如说军事新闻网页是第一类,娱乐新闻网页是第二类。如果第i个网页对象中包含的内容是军事新闻,则yi=1,即该网页对象属于第一类,如果网页对象中用户包含的内容是娱乐新闻,则yi=0,该网页对象属于第二类。假设初始共有l个网页对象被赋予了标记,剩下的u=n-l个网页对象没有赋予标记。为了方便表示,用l表示已有标记的网页对象的集合,u表示目前仍未标记的网页对象的集合。
步骤2,通过特征提取算法,提取网页对象库中对象的特征,将所有网页对象转化成相应的双模态特征向量对,维度分别为d1,d2;使用xi=(x1,i,x2,i)表示其中经过特征提取后的第i个网页对象的双模态特征向量对,也可以称其为样本xi;
步骤3,选择需要使用的基分类器类型,可以是各种常见的经典分类器,包括支持向量机,决策树,神经网络等,并将训练数据的两个特征向量和基分类器类型输入到加权协同训练算法中,训练后得到两个分类器,具体方法包括如下步骤:
步骤3.1,选定每轮需要新标记的样本数目n,衰减系数α,最大迭代轮数t,松弛参数ξ;将迭代计数器初始化为t=0,并将所有初始有标记训练数据的权值初始化为1/l,即两个模态上的权值向量为:
步骤3.2,若t>t,转到步骤3.5;否则让当前的分类器
步骤3.3,分别为模态v=1,2,置步骤3.2中新标记的样本的权值为
步骤3.4,分别为模态v=1,2求解下述优化问题,得到t+1轮迭代时需要的权值向量,之后令迭代计数器t加1,转到步骤3.2,优化问题具体为:.
其中,
步骤3.5,输出
步骤4,获取待测网页对象,并用步骤2中相同的方法将其转换为包含两个模态特征的特征向量对,将得到的特征向量分别输入步骤,3得到的对应分类器
- 还没有人留言评论。精彩留言会获得点赞!