基于匈牙利算法的工厂制造流程模型相似检索方法与流程
本发明属于业务流程管理领域,涉及流程模型间的相似度计算方法,特别是一种基于匈牙利算法的工厂流程模型相似检索方法。
背景技术:
随着业务流程管理技术的发展,越来越多的流程模型创建,如产品制造工厂就拥有大量流程模型,包括生产管理流程、采购流程、供应商选择/评价流程、物料管理流程、成品检验流程、不合格品管理流程、样品作业流程、产品再加工流程等。这么多流程模型对制造工厂来说是一大笔宝贵的财富,对其进行有效地管理能为工厂带来巨大的效益。检索相似流程就是一种有意义的流程管理技术,指的是给定一个检索流程模型,该流程模型将在工厂制造流程模型库中找到它的相似流程。在对工厂制造流程模型库中添加一个新的制造流程模型之前,要先在流程库中检索出新流程模型的相似流程并判断这些相似流程是否与新流程模型重复了,这样可以避免冗余。
随着工厂制造流程库规模的不断扩大,现有检索流程方法在效率和准确率方面的弊端日益突出。首先,现有流程检索方法在寻找匹配节点的过程中包含多次计算图编辑距离的步骤,导致流程检索的时间消耗变得很大。其次,现有流程检索方法均侧重于特定的应用场景问题,仅对流程模型中表示实际业务的任务元素进行处理,而忽略或简化了流程间非任务元素的匹配过程,因此这些方法尚未能在实际中得到有效地应用。最后,在一些流程检索方法中,对非任务节点的相似度衡量标准存在问题,使得对两个流程的相似度衡量存在问题,从而在某种程度上降低了流程检索的质量。
技术实现要素:
为了解决现有流程检索方法中存在的问题,本发明首先重新定义了两个petri网建模的流程模型的库所之间的上下文环境相似度,不仅考虑库所对周边相同变迁个数,而且考虑了库所对之间相同的执行路径,这样能在某种程度上提高两个流程的相似度计算的准确性,从而改善流程检索的质量。其次,本发明采用匈牙利算法来找到两个流程模型间的最佳库所节点对组合,引入匈牙利算法,不仅能保证找到的两个流程间的匹配库所对组合是全局最优的,而且耗时非常少,大大提高了流程检索的效率。最后,本发明设计了一种适用于petri网建模的流程模型间相似度衡量标准,该衡量标准更加简洁明了。
基于匈牙利算法的工厂制造流程模型相似检索方法,包括以下步骤:
(1)输入要对工厂制造流程库进行检索的检索流程q,将q用petri网来建模并解析出q的变迁集合、库所集合;
(2)取出工厂制造流程库中的一个未处理过的流程模型c,用petri网来建模并解析出c的变迁集合、库所集合;
(3)对q与c之间进行变迁节点的匹配,得到匹配变迁集合;
(4)基于匹配变迁集合,对q与c进行库所节点的匹配;
(5)计算q与c之间的相似度并将其加入到相似度集合s中;
(6)判断流程库中是否还有未处理的工厂制造流程模型,若还有,则执行步骤(2),否则,执行步骤(7);
(7)在相似度集合s中选出前k个相似度最大的工厂制造流程模型,其中k是由用户设置的。
进一步,在步骤(3)中,两个工厂制造流程模型q和c间的变迁节点对应的标签(即变迁节点的名称)若相同,则它们能匹配,否则不能进行匹配。
进一步,步骤(4)具体包括:
(4.1)计算q与c中所有可能匹配的库所对的相似度,得到一个初始库所匹配表;
(4.2)用匈牙利算法找出最佳库所匹配对的组合;
进一步,在步骤(4.1)中,两个库所p、p’间的相似度由以下公式来进行计算:
其中,·p表示边流入库所p的所有变迁的集合,称之为库所p的前集;p·则表示边从库所p流出的所有变迁的集合,称之为库所p的后集。|·p∩·p’|+|p·∩p·’|代表的是p、p’的周围相同变迁个数。·p×p·表示的是库所p的前集与后集的笛卡尔积,且·p×p·中每一个元素代表的是通过库所p的一个路径,因此|(·p×p·)∩(·p’×p’·)|指的是库所p与库所p’的共同路径个数。
进一步,在步骤(4.2)中,初始库所匹配表记录的是两个工厂制造流程模型间所有库所对组合的相似度,其实质是一个全局的库所相似度矩阵。在完成步骤(4.1)后,将初始库所匹配表作为匈牙利算法的输入。使用匈牙利算法可以找到两个流程图中库所相似度之和最大的库所匹配对组合。在有些情况下,库所相似度之和最大的值同时存在多个,即相同的相似度之和但对应不同的库所匹配对组合。此时,我们计算这些库所对组合的图编辑距离,选择图编辑距离最小的库所对组合作为两个流程图间最终的库所匹配对。
进一步,在步骤(5)中,两个用petri网建模的工厂制造流程模型g1,g2用以下公式来计算相似度:
其中,m指的是经过步骤(4.2)得到的两个模型间的库所匹配结果,p1,p2分别指的是g1、g2中的库所集合。
附图说明
图1为本发明的总的流程图
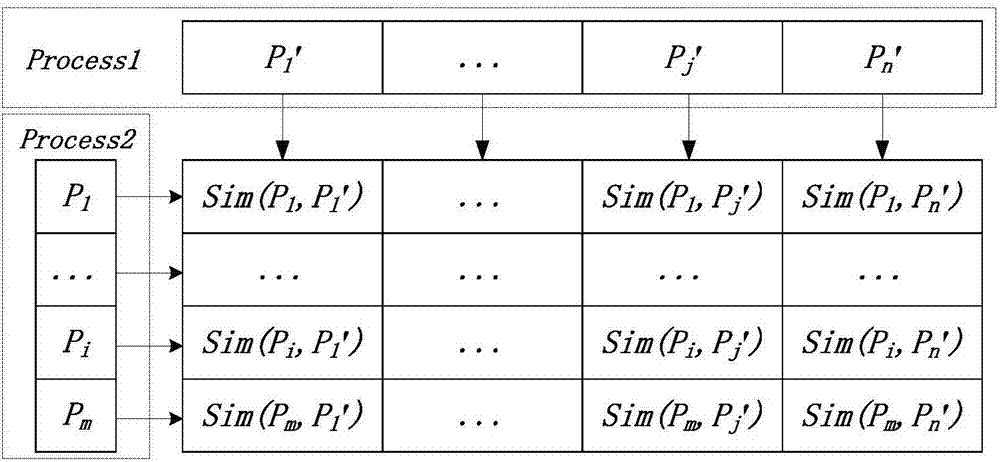
图2为初始库所匹配表
图3为两个模具制造流程模型的相似度计算实例图
具体实施方式
实施例一
参考附图1
(1)输入要对工厂制造流程库进行检索的检索流程q,将q用petri网来建模并解析出q的变迁集合、库所集合;
(2)取出工厂制造流程库中的一个未处理过的流程模型c,用petri网来建模并解析出c的变迁集合、库所集合;
(3)对q与c之间进行变迁节点的匹配,得到匹配变迁集合;
(4)基于匹配变迁集合,对q与c进行库所节点的匹配,该步骤由以下步骤组成:
(4.1)计算q与c中所有可能匹配的库所对的相似度,得到一个初始库所匹配表;
(4.2)用匈牙利算法找出最佳库所匹配对的组合;
(5)计算q与c之间的相似度并将其加入到相似度集合s中;
(6)判断流程库中是否还有未处理的工厂制造流程模型,若还有,则执行步骤(2),否则,执行步骤(7);
(7)在相似度集合s中选出前k个相似度最大的工厂制造流程模型,其中k是由用户设置的。
实施例二
参考附图2,3
此处只展示本发明的核心部分,即计算两个工厂制造流程模型间的相似度。图3的最上边部分是两个流程模型process1、process2,它们代表的是两个用petri网建模的模具制造厂的模具制造流程,其中a表示“材料准备”,b表示“打磨”,c表示“抛光”,d表示“切割”,e表示“组装”,s和s’表示开始,e和e’表示结束,p1表示“主体材料已准备好”,p2表示“主体材料已完成”,p3表示“配件材料已准备好”,p4表示“配件材料已准备好”,p1’表示“开始打造主体材料”,p2’表示“主体材料打造完毕”,p3’表示“开始打造配件材料”,p4’表示“配件材料打造完毕”。
计算process1、process2的相似度的步骤如下:
(1)对process1、process2分别进行解析,得到process1的变迁集合为{a,b,c,d,e},库所集合为{p1,p2,p3,p4},process2的变迁集合为{a,b,c,d,e},库所集合为{p1,p2,p3,p4};
(2)对process1、process2进行变迁节点匹配,结果为{a-a,b-b,c-c,d-d,e-e},其中“-”表示匹配;
(3)对process1、process2进行库所节点匹配,具体包括:
(3.1)计算process1、process2中所有可能匹配的库所对的相似度,并得到一张初始库所匹配表,该表如图2所示;假设流程process1包含n个库所,流程process2包含m个库所,且m<n,则横向虚线框中是流程process1的所有库所(由pj’表示),右下角虚线框中每一列链表包含了流程process2的所有库所,由pi表示;库所匹配表剩余部分中,位置(i,j)上存储的是process1的第j个库所与process2的第i个库所间的上下文环境相似度;
仅考虑对两个流程虚线框中的库所进行匹配,由于process1与process2包含的库所数目一样多,因此可将process2的库所作为行,process1的库所作为列,根据公式(1)分别计算所有库所对的相似度,如:sim(p1,p1’)=3/5,sim(p4,p3’)=0,完成一个全局库所匹配表的初始化;
(3.2)将初始库所匹配表作为匈牙利算法的输入,在此例中匈牙利算法的输出只有一组:{(p1,p1’),(p2,p2’),(p3,p3’),(p4,p4’)};
(4)根据公式(2)对process1、process2进行相似度计算:sim(process1,process2)=0.8。
- 还没有人留言评论。精彩留言会获得点赞!