一种自适应权重组合推荐算法的制作方法
本发明涉及人工智能技术领域,尤其涉及一种自适应权重组合推荐算法。
背景技术:
随着电子商务的领域不断发展,信息呈爆炸式增长导致用户想要在网络中找到有用的信息变得困难,个性化推荐系统已经成为电子商务领域必不可少的一部分。目前推荐算法主要有基于内容推荐、基于关联规则推荐、基于知识推荐和协同过滤推荐等,单一的推荐算法具有一些局限性已经不适用于复杂的电子商务系统中。
技术实现要素:
为解决上述技术问题,本发明提供一种权重自适应的组合推荐方法,采用几种推荐算法的组合,弥补或避免了单一推荐算法的弱点,可以应用到电子商务个性化推荐中。
本发明采用如下技术方案:
一种自适应权重组合推荐算法,包括以下步骤:
s1、统计用户的历史购买数据,建立用户模型矩阵;
s2、由每个推荐模块生成推荐集,并计算商品与用户模型相似度;
s3、根据用户的反馈计算每个推荐模块的推荐权重;
s4、利用贝叶斯公式计算权重值;
s5、计算每个商品的推荐度;
s6、将推荐度最高的商品推荐给用户;
s7、计算下一个时间周期内用户的反馈,并更新用户模型。
优选的,所述s1中用户模型矩阵m={m1,m2,…,mt},其中mu表示用户的兴趣属性,u∈[1,t]。
优选的,所述的兴趣属性包括商品的种类、商品的价格、商品的规格。
优选的,所述s2中推荐集x={x1,x2,…,x1},其中推荐商品xk的商品属性为p={p1,p2,…,pm},k∈[1,l];利用公式(1)计算每个推荐商品xk的属性集合p与用户模型m的相似度。
优选的,所述s3计算的具体步骤为:在时间周期t内,用户的点击和购买次数为f={f1,f2,…,fn},其中fi为点击和购买商品来自于第i个推荐模块的次数,根据式(2)计算第i个推荐模块的权重w′i的估计值。
优选的,为了覆盖整个权值的范围,对[0,1]之间均匀取10个数作为权重wi的取值域,即h={0.05,0.15,…,0.95},每个取值点的初始概率为0.1,即p(hj)=0.1;在一段时间以后有了wi的历史样本点,为了能更加准确的预测权重,采用时间窗的方法,只取s个最近的权重分布值,即
优选的,所述s4中计算的具体步骤为:
s4.1、首先要计算先验概率p(w′i|hj),定义公式(4)表示当权重取值hj越靠近权重估计值w′i则概率越大,原理权重估计值w′i概率越小。
s4.2、然后计算使用公式(5)后验概率p(hj|w′i);
s4.3、使用公式(6)计算第i个推荐模块的权重wi,并更新权重分布
s4.4、计算每个推荐模块的权重值。
优选的,所述s5计算的具体步骤为:使用公式(7)计算推荐集x={x1,x2,…,xl}每一个商品xi的推荐度ri。
ri=wi×simk(7)
本发明具有以下有益效果:主要解决组合推荐中权重分配的问题,通过用户的历史数据建立用户模型,在使用贝叶斯公式计算组合推荐中每一个推荐模块的权重,并更新历史权重数据作为下一次权重计算的参考,将商品的属性与用户模型的相似度和生成该推荐商品的推荐模块的权重相乘,确定该商品的推荐度,最后选取推荐度最高n个的商品推荐给用户。该算法通过用户在线行为来调整推荐权重,可以随着用户的兴趣变化进行自适应推荐,能更加准确的为用户推荐。
附图说明
下面结合附图对本发明作优选的说明:
图1为本发明算法流程图;
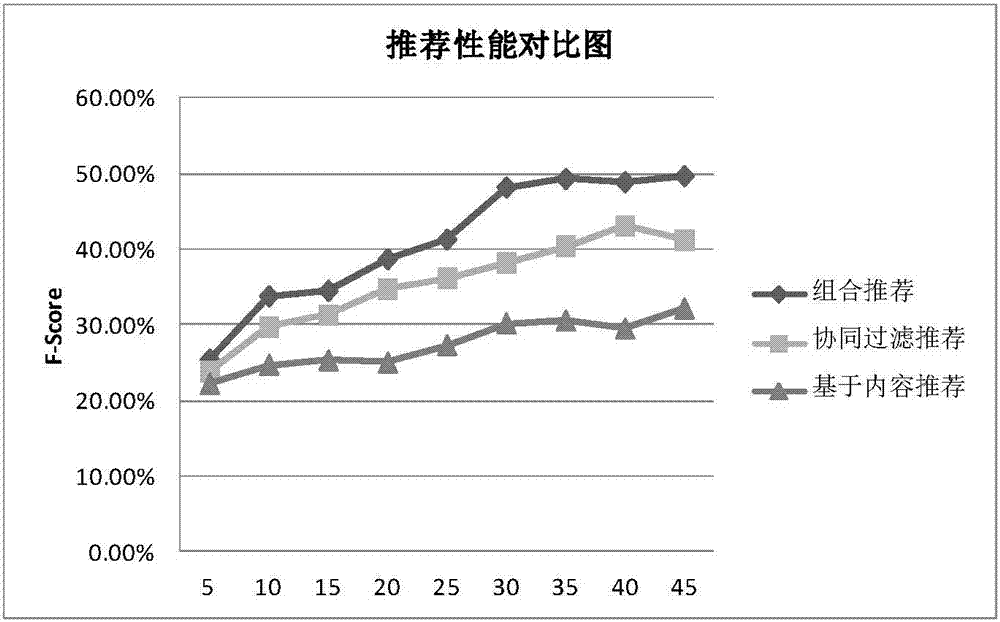
图2为本发明的算法与其他推荐算法的性能对比图;
具体实施方式
如图1至图2所示,为本发明一种自适应权重组合推荐算法,包括以下步骤:
s1、统计用户的历史购买数据,建立用户模型矩阵m={m1,m2,…,mt},其中mu表示用户的兴趣属性,u∈[1,t],包括商品的种类、商品的价格、商品的规格等;
s2、由每个推荐模块生成的推荐集x={x1,x2,…,xl},其中推荐商品xk的商品属性为p={p1,p2,…,pm},k∈[1,l];利用公式(1)计算每个推荐商品xk的属性集合p与用户模型m的相似度;
s3、根据用户的反馈计算每个推荐模块的推荐权重。在时间周期t内,用户的点击和购买次数为f={f1,f2,…,fn},其中fi为点击和购买商品来自于第i个推荐模块的次数,根据式(2)计算第i个推荐模块的权重w′i的估计值;
s4、为了覆盖整个权值的范围,对[0,1]之间均匀取10个数作为权重wi的取值域,即h={0.05,0.15,…,0.95},每个取值点的初始概率为0.1,即p(hj)=0.1;
在一段时间以后有了wi的历史样本点,为了能更加准确的预测权重,采用时间窗的方法,只取s个最近的权重分布值,即
s5、利用贝叶斯公式计算权重值。首先要计算先验概率p(w′i|hj),定义公式(4)表示当权重取值hj越靠近权重估计值w′i则概率越大,原理权重估计值w′i概率越小;
s6、利用贝叶斯公式计算权重值。然后计算使用公式(5)后验概率p(hj|w′i);
s7、使用公式(6)计算第i个推荐模块的权重wi,并更新权重分布
s8、重复步骤3~7,计算每个推荐模块的权重值;
s9、使用公式(7)计算推荐集x={x1,x2,…,xl}每一个商品xi的推荐度ri;
ri=wi×simk(7)
s10、将推荐度最高的top-n个商品推荐给用户;
s11、计算下一个时间周期t内用户的反馈f,并更新用户模型。
如图2所示的实验数据选自某网站2014年1月~2016年8月的商品销售数据,实验结果采用推荐评价指标为综合评价值(f-score),如式(8)所示:
其中,p用于度量推荐模型的准确率,如式(9)所示;r用于度量推荐模型的查全率如式(10)所示;
r(u)表示向用户u推荐的商品集合,t(u)表示用户u真实评分过的物品集合。f-score综合考虑了p和r指标,是两者的加权和的平均,图2为实验的性能对比,纵坐标表示计算的f-score值,横坐标表示推荐的轮次,从图中可以看出随着推荐轮次的增加推荐的f-score值增加,并且本专利的组合推荐方法优于单一的协同过滤算法和基于内容推荐算法。
以上仅为本发明的具体实施例,但本发明的技术特征并不局限于此。任何以本发明为基础,为解决基本相同的技术问题,实现基本相同的技术效果,所作出的简单变化、等同替换或者修饰等,皆涵盖于本发明的保护范围之中。
- 还没有人留言评论。精彩留言会获得点赞!