一种RTDS自定义元件的多线程实时仿真方法与流程
本发明涉及自定义元件仿真技术领域,特别是涉及一种rtds自定义元件的多线程实时仿真方法。
背景技术:
现如今,能够对如此复杂的自定义元件进行实时计算,一般使用两种方法:
1.逐步增大计算步长,尝试单个cpu能否在一个步长内完成计算,为了保证仿真的实时性和计算精度,计算步长的增加是有限度的,一般要控制在100μs以内;
2.是将复杂的自定义元件代码分割成若干部分,保证每个部分能够使用单个cpu在一个步长内完成计算,再将分隔的若干部分生成若干个自定义元件,但这样,每一个自定义元件都需占用一个cpu进行计算。
上述两种方法都可以实现自定义元件的实时计算,但是第一种方法由于计算步长的增加非常有限,且只能满足逻辑简单和代码量较少的自定义元件,而第二种方法自定义元件分隔后的数量增加,直接影响cpu的数量也随之增加,这样会造成占用的硬件资源较多,同时,带来比较大的经济问题。
因此,针对现有技术不足,提供一种rtds自定义元件的多线程实时仿真方法以克服现有技术不足甚为必要。
技术实现要素:
本发明的目的在于避免现有技术的不足之处而提供一种rtds自定义元件的多线程实时仿真方法,该rtds自定义元件的多线程实时仿真方法提出的多线程实时仿真是将用户生成的自定义元件的代码文件在导入cbuilder事前进行代码分割和优化,能够将包含过计算周期的复杂自定义元件在rtds的单个cpu上完成。
本发明的上述目的通过如下技术手段实现。
提供一种rtds自定义元件的多线程实时仿真方法,将用户生成的自定义元件的代码文件进行多线程代码分割优化处理使得包含多计算周期的复杂自定义元件能够在rtds的单个cpu上完成计算,再导入cbuilder中通过rtds的单个cpu完成计算并生成rtds自定义元件。
具体而言的,rtds自定义元件的生成步骤,具体包括:
1)以图形化方式搭建模型;
2)根据步骤1)中的搭建的模型转换成代码文件;
3)对步骤2)转换的代码文件进行多线程代码分割优化处理,再导入cbuilder中通过rtds的单个cpu完成计算并生成rtds自定义元件,即得到封装的rtds自定义元件。
具体而言的,步骤2)中转换后得到的是c代码文件。
进一步的,一个复杂的自定义元件包含n个计算周期t1、t2、......、tn,其中,n为自然数,tn>t1,tn>t2,......t,n>tn-1,每个计算周期均大于t0,t0为rtds的计算步长;
多线程代码分割优化处理的具体步骤如下:
(s1)计算单个cpu在t0内能够计算的代码量x0;
(s2)统计n个计算周期的代码量分别为x1、x2、......、xn,n个计算周期的资源系数分别为k1、k2、......、kn,
(s3)判断步骤(s2)中计算出的资源系数是否满足
(s4)对每个计算周期的代码分配优先级,优先级的分配方式为计算周期越小,优先级越高;
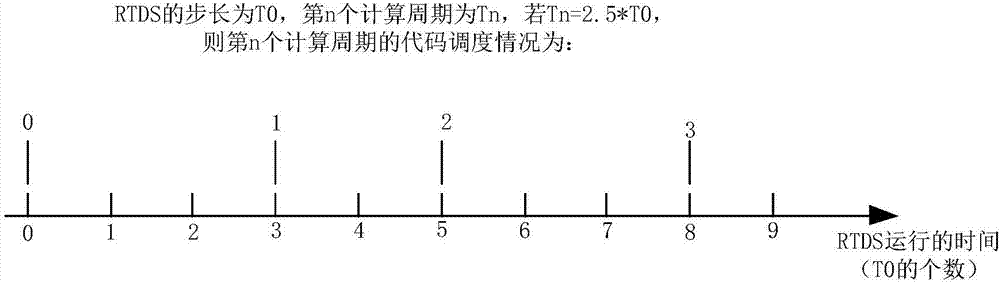
(s5)生成优化调度程序,第n个计算周期的代码第m次调度时刻为第x个t0时刻,
(s6)将n个计算周期平均分成两部分,两部分分别作为独立的对象,进入步骤(s2)。
优选的,所述生成优化调度程序遵循优先级进行处理。
优选的,所述步骤1)具体是使用matlab中的simulink以图形化方式搭建模型。
进一步的,rtds自定义元件是通过权利要求1-6任意一项所述的方法获得的。
发明的一种rtds自定义元件的多线程实时仿真方法,将用户生成的自定义元件的代码文件在导入cbuilder之前进行代码处理,具有以下优点:
1.提高了单个cpu对rtds自定义元件的计算规模;
2.真实的模拟自定义元件中的计算周期,使仿真计算更真实;
3.将复杂的单个自定义元件分隔成多个自定义元件,建模过程更加简单、简洁。
附图说明
利用附图对本发明作进一步的说明,但附图中的内容不构成对本发明的任何限制。
图1是本发明一种rtds自定义元件的多线程实时仿真方法的示意图。
图2是本发明一种rtds自定义元件的多线程实时仿真方法中的调度示意图。
图3是本发明一种rtds自定义元件的多线程实时仿真方法图1中多线程代码分隔优化的流程图。
具体实施方式
结合以下实施例对本发明作进一步描述。
如图1-3所示,一种rtds自定义元件的多线程实时仿真方法,将用户生成的自定义元件的代码文件进行多线程代码分割优化处理使得包含多计算周期的复杂自定义元件能够在rtds的单个cpu上完成计算,再导入cbuilder中通过rtds的单个cpu完成计算并生成rtds自定义元件。
rtds自定义元件的生成步骤,具体包括:
1)以图形化方式搭建模型。
2)根据步骤1)中的搭建的模型转换成代码文件。
3)对步骤2)转换的代码文件进行多线程代码分割优化处理,再导入cbuilder中通过rtds的单个cpu完成计算并生成rtds自定义元件,即得到封装的rtds自定义元件。
步骤2)中转换后得到的是c代码文件。
一个复杂的自定义元件包含n个计算周期t1、t2、......、tn,其中,n为自然数,tn>t1,tn>t2,......t,n>tn-1,每个计算周期均大于t0,t0为rtds的计算步长。
多线程代码分割优化处理的具体步骤如下:
(s1)计算单个cpu在t0内能够计算的代码量x0。
(s2)统计n个计算周期的代码量分别为x1、x2、......、xn,n个计算周期的资源系数分别为k1、k2、......、kn,
(s3)判断步骤(s2)中计算出的资源系数是否满足
(s4)对每个计算周期的代码分配优先级,优先级的分配方式为计算周期越小,优先级越高。
(s5)生成优化调度程序,第n个计算周期的代码第m次调度时刻为第x个t0时刻,
(s6)将n个计算周期平均分成两部分,两部分分别作为独立的对象,进入步骤(s2)。
所述生成优化调度程序遵循优先级进行处理。
所述步骤1)具体是使用matlab中的simulink以图形化方式搭建模型。
rtds自定义元件是通过权利要求1-6任意一项所述的方法获得的。
需要说明的是,复杂的自定义元件是包含多个计算周期的自定义元件。
故本发明的多线程实时仿真方法用代码分割优化的方法,降低了计算所需的cpu数量,使用单个cpu即可完成处理包含多个计算周期的自定义元件,大大的提高了硬件的计算效率,同时,还适用于不同计算周期的自定义元件。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
- 还没有人留言评论。精彩留言会获得点赞!