本发明涉及分布式信息检索领域,尤其涉及一种基于图知识库的分布式信息检索集合选择方法。
背景技术:
在过去的十年中,信息检索技术的发展使web搜索引擎的质量达到了一个新的水平,web搜索引擎已经成为用户发现和获取信息的常规和首选渠道。然而,随着万维网的不断发展,非结构化数据以指数级地形式增长,传统的集中式信息检索系统面临着很多难以克服的困难,无法有效管理海量文本数据,无法提供快速、稳定的检索服务。尽管单台计算机的处理能力不断提高,但在面对海量信息检索服务时也束手无策。为了适应现代海量数据的检索要求,解决传统的集中式信息检索系统存在的问题,分布式信息检索已成为一种有效的解决方案。
分布式信息检索也称为联合搜索、或联合信息检索,将多个可检索的信息集合组织成一个检索接口,并对外提供检索服务。在具体的检索中,用户通常只关心排名靠前的检索结果。然而,并不是所有的信息集合都包含了用户需要的信息,检索所有的信息集合,不但增加系统的计算开销,还会占用大量的网络带宽。如果只检索部分集合,能够得到类似搜索所有集合的检索效果,将大幅提升系统的检索效率。因此,集合选择对于提升分布式检索系统的性能有着举足轻重的作用,具有重要的研究价值。
传统集合选择方法使用集合的词汇统计信息来表示整个集合,基于词汇统计特征计算查询与集合的相关度,并按相关度高低对集合进行排序,选择排名靠前的集合。然而,此类方法要求每个集合提供基于所有文档的词汇直方图,包括词典和词频等统计信息。在复杂的网络环境中获取所有集合的词汇直方图是不切实际的,尤其是在非协同式的环境下。此外,词汇直方图丢失了大量文本语义信息,如近义词、多义词和词序等信息,直接导致了集合语义信息表示不准确。
为进一步提高集合语义信息表示的准确度,目前也出现了基于复杂语义信息的集合选择方法,使用esa向量、lda主题模型或分布式表征向量对集合的语义信息进行建模。此类方法充分挖掘了文本语义信息,包括文本主题、词序等信息,而不是仅使用词汇直方图。但是,此类方法仅考虑文本的“形态句法”信息,忽略了词汇之间更深层次、细粒度的语义关系,如主谓宾关系。
技术实现要素:
本发明为克服上述的不足之处,目的在于提供一种基于图知识库的分布式信息检索集合选择方法,本发明方法利用图知识库中蕴含的实体关系和网络结构,对集合的语义信息进行建模,首先从各个集合的样本文档中获取集合的实体词集;其次,基于上下文相关度和结构相关度,计算实体词的权重,使用加权的实体词集表示集合的语义信息;然后,采用查询扩展方法扩展查询中包含的实体词,并为查询实体词赋予不同的权重;最后,采用查询与集合相关度度量方法计算集合评分,选择评分较高的若干个集合;提高了集合选择方法的准确度。
本发明是通过以下技术方案达到上述目的:一种基于图知识库的分布式信息检索集合选择方法,包括如下步骤:
1)离线处理阶段:
1.1)采用实体链接方法抽取集合样本文档中存在的实体词,得到集合c的实体词集ec;
1.2)计算实体词之间的上下文相关度和结构相关度;
1.3)基于上下文相关度和结构相关度,计算实体词之间的总体语义相关度;
1.4)基于总体语义相关度,分别计算ec中的每个实体词到其他所有实体词的总体语义相关度之和,得到集合c的加权实体词集wec;
2)在线处理阶段:
2.1)接收用户查询θ,采用实体链接方法抽取原始查询中存在的实体词,得到原始查询实体词集oθ;
2.2)基于wikipedia文章索引,检索得到与θ相关的wikipedia文章标题,在dbpedia图知识库中找到与检索到的文章标题一一对应的实体词,得到初始候选扩展实体词集rθ;
2.3)基于dbpedia图结构,将rθ中的实体词组织成实体图gθ,枚举gθ中所有的路径,计算所有路径的评分,选择评分高的前若干条路径,保留路径对应的实体词,得到中间候选扩展实体词集pθ;
2.4)基于dbpedia图结构,将pθ中的实体词组织成实体图gp,并选择pθ在dbpedia图知识库中的所有邻居节点作为待选实体词集nθ;依次将nθ中的每个实体词作为节点及其与gp中实体词存在的关系作为边合并到gp;若gp的紧密程度增加,则保留此节点,否则删除;遍历完nθ每个实体词后,将gp中的所有实体词作为最终扩展实体词集cθ;
2.5)去除cθ中包含与oθ重复的实体词,得到互相不包含冗余实体词的cθ与oθ,cθ与oθ构成最终的新查询qθ;
2.6)计算qθ中各个实体词的权重,得到查询的加权实体词集wqθ;
2.7)基于wec、wqθ、实体词之间的总体语义相关度、集合大小与集合实体词频率,计算查询与集合的相关度,选择评分高的前若干集合。
作为优选,所述步骤1.1)与步骤2.1)使用的实体链接方法具体为采用成熟的实体链接工具进行抽取,实体链接工具优选采用dbpediaspotlight。
作为优选,所述步骤1.1)得到实体词集ec的方法如下:
1.1.1)针对集合c,其样本文档集为其中|sc|为样本文档集sc中的文档总数,选择任意一个未处理的样本文档di;
1.1.2)利用实体链接工具抽取样本文档中存在的实体词ei;
1.1.3)将实体词ei更新到集合的实体词集ec中,若仍有未处理的样本文档,则返回执行步骤1.1.1);否则,结束。
作为优选,所述步骤1.2)计算实体词之间的上下文相关度和结构相关度的方法如下:
1.2.1)基于wikipedia上两个实体词共享的文章数,来计算两个实体词e1和e2之间的上下文相关度,计算公式如下:
其中,e1和e2分别是e1和e2出现在wikipedia中的文章总数,w是wikipedia中包含的文章总数,dist(e1,e2)表示e1和e2两个实体词在dbpedia图知识库中的最短距离;
1.2.2)采用广度优先遍历算法,得到任意两个实体词e1和e2在dbpedia图知识库中的最短路径path(e1,e2)={edge1,edge2,...,edgek};
1.2.3)给定dbpedia中的一条边edge={subj,pred,obj},其中subj与obj均是实体词,pred为谓词,计算谓词的信息量ic(ωpred),计算公式如下:
其中,|ωpred|是相同类型谓词的总数,|t|是dbpedia图中所有三元组的总数;
1.2.4)计算谓词的条件信息量ic(ωobj|ωpred),计算公式如下:
其中,|ω(pred,obj)|是连接到实体词obj的谓词总数;
1.2.5)计算谓词的信息量和条件信息量之和得到边权值,公式如下:
wjointic(edge)=ic(ωpred)+ic(ωobj|ωpred)
其中,wjointic(edge)为边edge={subj,pred,obj}的权值;
1.2.6)基于两个实体词e1和e2在dbpedia图知识库中的最短路径上边权值之和得到结构相关度,计算公式如下:
其中,若实体词e1和e2之间存在多条最短路径,则e1和e2之间的结构相关度设置为所有最短路径上边权重之和的最大值。
作为优选,所述总体语义相关度的计算方法为将上下文相关度和结构相关度的线性组合得到,权重参数为λ,公式如下:
simoverau(e1,e2)=λ×ctxt(e1,e2)+(1-λ)×steruct(e1,e2)。
作为优选,所述步骤1.4)计算ec中的每个实体词到其他所有实体词的总体语义相关度之和即为对实体词集ec的实体词e进行权重计算,公式如下:
其中,|ec|为集合实体词集ec中实体词总数,采用上述权重计算公式计算ec中各个实体词的权重,从而得到wec。
作为优选,所述步骤2.3)得到pθ的方法如下:
2.3.1)基于dbpedia图结构,将rθ中的实体词组织成实体图gθ,其中,rθ中的实体词作为gθ中的节点,实体词之间的关系作为gθ中的边;
2.3.2)对gθ中的所有顶点依次采用深度优先遍历算法,枚举出实体图中所有的路径;
2.3.3)采用路径评分计算公式,计算所有路径的评分,公式如下:
其中,p为实体图gθ中的一条路径,p={a1,a2,...,as},ai为路径上的实体词,s为路径上实体词的个数;
2.3.4)按路径评分高低进行排序,选择评分高的前若干条路径,将这些路径对应的实体词ai更新到pθ,得到中间候选扩展实体词集pθ。
作为优选,所述步骤2.4)得到cθ方法如下:
2.4.1)基于dbpedia图结构,将pθ中的实体词组织成实体图gp,其中,pθ中的实体词作为gp中的节点,实体词之间的关系作为gp中的边;
2.4.2)对于pθ中所有的实体词,选择其在dbpedia图知识库中的所有邻居节点作为待选实体词集nθ;
2.4.3)若nθ中有未处理的实体词,选择未处理的实体词ei,进入步骤
2.4.4);否则,进入步骤2.4.6);
2.4.4)将实体词ei以及其与gp中所有实体词存在的边合并到gp;
2.4.5)计算gp的紧密程度,紧密程度由图中点和边构成三角形的数目来度量;若gp的紧密程度增加,则保留该节点所对应的实体词ei后返回步骤2.4.3);否则,在gp中删除节点所对应的实体词ei及其连接的边后返回步骤2.4.3);
2.4.6)获取gp中存在的实体词,更新得到最终扩展实体词集cθ。
作为优选,所述步骤2.6)计算qθ中实体词的权重的公式如下:
其中,γ是权重参数;当实体词e属于oθ时,实体词e具有相等的权重,当实体词e属于cθ时,根据实体词e到pθ中实体词的最短距离,实体词e具有不同的权重;第一层次由pθ中的实体词构成,第l层次中的第i层由来自到pθ中实体词的最短距离为i-1的扩展实体词构成,hi是第i层中的实体词。
作为优选,所述步骤2.7)的具体方法如下:
2.7.1)针对每个集合c,获取wec中每个实体词ej(1≤j≤n)的权重,n为wec中的实体词个数;
2.7.2)针对查询qθ,获取wqθ中每个实体词ei(1≤i≤m)的权重,m为wqθ中的实体词个数;
2.7.3)计算实体词ei与实体词ej的总体语义相关度simoverall(ei,ej);
2.7.4)计算集合c的集合大小εc,由集合中的文档总数|c|除以最大集合的文档总数|cmax|得到,计算公式如下:
其中,|sc|表示集合c的样本文档总数;
2.7.5)计算集合实体词ej的频率f(c,ej),由实体词ej的词频除以集合样本文档中所有实体词的词频总数得到,计算公式如下:
其中,eh(1≤h≤n)是集合样本文档中的实体词;
2.7.6)采用查询与集合相关度计算公式计算得到各个集合评分,其中查询与集合相关度计算公式如下:
2.7.7)按集合评分高低进行排序,选择评分高的前若干个集合。
本发明的有益效果在于:(1)本发明利用图知识库提供的实体关系与网络结构,使用上下文相关度和结构相关度计算集合中实体词的权重,并使用加权的实体词集表示集合的语义信息,保留了词汇之间更细粒度的语义关系,提高了集合语义信息表示的准确度;(2)基于wikipedia文章与dbpedia网络结构,发现并扩展了简短查询词中包含的实体词,且为查询实体词赋予了不同的权重,准确地表达了用户查询意图;(3)基于加权的实体词,查询与集合相关度度量方法综合考虑了集合大小、实体词频率等因素,提高了计算查询与集合相关度的准确度。
附图说明
图1是本发明的方法流程示意图;
图2是本发明实施例集合的实体词集的获取流程示意图;
图3是本发明实施例查询的最终扩展实体词集的获取流程示意图。
具体实施方式
下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此:
实施例:如图1所示,一种基于图知识库的分布式信息检索集合选择方法,包括在线处理、离线处理两个阶段,具体如下:
(1)离线处理阶段,其步骤如下:
步骤1,采用实体链接方法抽取集合样本文档中存在的实体词,得到集合的实体词集ec。
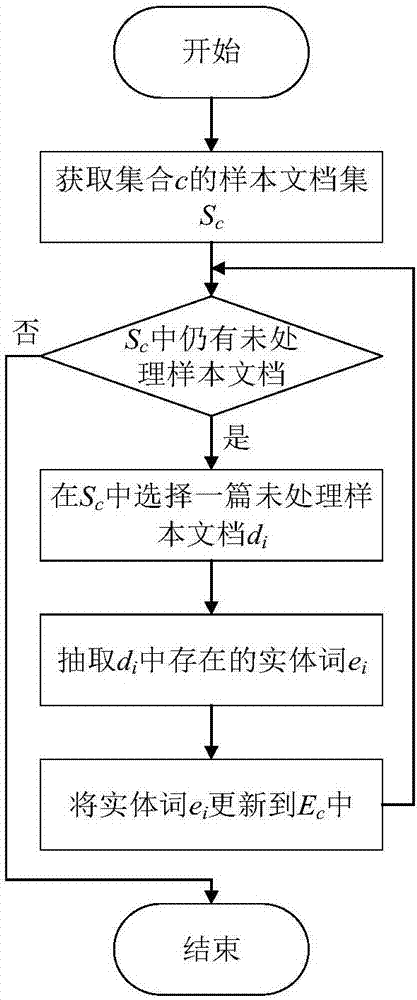
采用成熟的实体链接工具(如:dbpediaspotlight),进行实体词抽取。具体步骤如图2所示,包括:
a)针对集合c,其样本文档集为其中|sc|为样本文档集sc中的文档总数,选择一篇未处理的样本文档di;
b)利用实体链接工具抽取样本文档中存在的实体词ei;
c)将实体词ei更新到集合的实体词集ec中,若仍有未处理的样本文档,返回步骤a,否则,结束。
步骤2,计算实体词之间的上下文相关度和结构相关度,具体步骤包括:
a)计算任意两个实体词e1(e1∈ec)和e2(e2∈ec)之间的上下文相关度。其基于wikipedia上两个实体词共享的文章数,来计算两个实体词之间的上下文相关度,计算公式如下:
其中,e1和e2分别是e1和e2出现在wikipedia中的文章总数,w是wikipedia中包含的文章总数,dist(e1,e2)表示e1和e2两个实体词在dbpedia图知识库中的最短距离。
b)采用广度优先遍历算法,得到任意两个实体词e1(e1∈ec)和e2(e2∈ec)在dbpedia图知识库中的最短路径path(e1,e2)={edge1,edge2,...,edgek}。
c)给定dbpedia中的一条边edge={subj,pred,obj},其中subj与obj均是实体词,pred为谓词,计算谓词的信息量,计算公式如下:
ic(ωpred)表示谓词的信息量,在dbpedia中存在的同种类型边越多,即此谓词总数越多,重要性越低,具有较低的信息量。|ωpred|是相同类型谓词的总数,|t|是dbpedia图中所有三元组的总数。
d)计算谓词的条件信息量,计算公式如下:
ic(ωobj|ωpred)表示谓词的条件信息量,考虑了谓词所指向实体词的特殊性,若连接到此实体词的谓词越少,则此类谓词越重要,具有较高的信息量。|ω(pred,obj)|是连接到实体词obj的谓词总数。
e)计算边权值,其由谓词的信息量和条件信息量之和得到,计算公式如下:
wjointic(edge)=ic(ωpred)+ic(ωobj|ωpred)
wjointic(edge)表示边edge={subj,pred,obj}的权值。
f)计算任意两个实体词e1(e1∈ec)和e1(e1∈ec)之间的结构相关度。其基于两个实体词在dbpedia图知识库中的最短路径上边权值之和得到,计算公式如下:
若实体词e1和e2之间存在多条最短路径,则e1和e2之间的结构相关度设置为所有最短路径上边权重之和的最大值。
步骤3,基于上下文相关度和结构相关度,计算实体词之间的总体语义相关度。
对于任意两个实体词e1(e1∈ec)和e2(e2∈ec),总体语义相关度为上下文相关度和结构相关度的线性组合,权重参数为λ,计算公式如下:
simoverall(e1,e2)=λ×ctxt(e1,e2)+(1-λ)×struct(e1,e2)
步骤4,基于总体语义相关度,对ec中的每个实体词,计算其到其他所有实体词的总体语义相关度之和,得到集合的加权实体词集wec。
给定集合的实体词集ec,实体词e(e∈ec)的权重计算公式如下:
其中,|ec|为集合实体词集ec中实体词总数。采用集合的实体词权重计算公式,能够计算ec中各个实体词的权重,得到wec。
(2)在线处理阶段,其步骤如下:
步骤1,接收用户查询θ,采用实体链接方法抽取原始查询中存在的实体词,得到原始查询实体词集oθ。
采用成熟的实体链接工具(如:dbpediaspotlight),对用户查询θ进行实体词抽取,得到原始查询实体词集oθ。
步骤2,基于wikipedia文章索引,检索得到与θ相关的一组wikipedia文章标题,在dbpedia图知识库中找到与上述文章标题一一对应的实体词,得到初始候选扩展实体词集rθ。
步骤3,基于dbpedia图结构,将rθ中的实体词组织成一个实体图gθ。枚举gθ中所有的路径,计算所有路径的评分,选择评分较高的若干条路径,保留这些路径上的实体词,得到中间候选扩展实体词集pθ,具体步骤包括如下:
a)基于dbpedia图结构,将rθ中的实体词组织成一个实体图gθ。其中,rθ中的实体词作为gθ中的节点,实体词之间的关系作为gθ中的边。
b)对gθ中的所有顶点依次使用深度优先遍历算法,枚举出实体图中所有的路径。
c)采用路径评分计算公式,计算所有路径的评分。路径评分计算公式为:
其中,p为实体图gθ中的一条路径,p={a1,a2,...,as},ai为路径上的实体词,s为路径上实体词的个数。
d)按路径评分高低进行排序,选择评分较高的若干条路径,将这些路径上的实体词ai更新到pθ。
步骤4,基于dbpedia图结构,将pθ中的实体词组织成一个实体图gp,并选择pθ在dbpedia图知识库中的所有邻居节点作为待选实体词集nθ;依次将nθ中的每个实体词作为节点及其与gp中实体词存在的关系作为边合并到gp。若gp的紧密程度增加,则保留此节点,否则删除。遍历完nθ每个实体词后,将gp中的所有实体词作为最终扩展实体词集cθ。具体流程如图3所示。包括如下步骤:
a)基于dbpedia图结构,将pθ中的实体词组织成一个实体图gp。其中,pθ中的实体词作为gp中的节点,实体词之间的关系作为gp中的边。
b)对于pθ中所有的实体词,选择它们在dbpedia图知识库中的所有邻居节点作为待选实体词集nθ。
c)若nθ中仍有未处理的实体词,选择一个未处理的实体词ei,进入步骤d。否则,进入步骤f。
d)将实体词ei,以及其与gp中所有实体词存在的边,合并到gp。
e)计算gp的紧密程度,其由图中点和边构成三角形的数目来度量。若gp的紧密程度增加,返回步骤c;否则,在gp中删除实体词ei及其连接的边,再返回步骤c。
f)获取gp中存在的实体词,更新到最终扩展实体词集cθ。
步骤5,去除cθ中包含与oθ重复的实体词,得到互相不包含冗余实体词的cθ与oθ,cθ与oθ构成最终的新查询qθ。
步骤6,计算qθ中各个实体词的权重,得到查询的加权实体词集wqθ。
给定某查询实体词e(e∈qθ),其权重计算公式如下:
其中,γ是权重参数。当实体词e属于oθ时,它们被赋予相等的权重。当实体词e属于cθ时,根据实体词e到pθ中实体词的最短距离,它们被赋予不同的权重。第一层次由pθ中的实体词构成。第l层次中的第i层(1<i≤l)由来自到pθ中实体词的最短距离为i-1的扩展实体词构成。hi是第i层中的实体词。采用查询的实体词权重计算公式,能够计算qθ中各个实体词的权重,得到wqθ。
步骤7,基于wec、wqθ、实体词之间的总体语义相关度、集合大小与集合实体词频率,计算查询与集合的相关度,选择评分较高的前若干个集合。具体步骤包括:
a)针对每个集合c,获取wec中每个实体词ej(1≤j≤n)的权重,n为wec中的实体词个数。
b)针对查询qθ,获取wqθ中每个实体词ei(1≤i≤m)的权重,m为wqθ中的实体词个数。
c)查询实体词ei与集合实体词ej的总体语义相关度simoverall(ei,ej)。
d)计算集合大小εc,将集合中的文档总数|c|,除以最大集合的文档总数(由|cmax|表示),计算公式如下:
其中,|sc|表示集合c的样本文档总数。
e)计算集合实体词频率f(c,ej),使用实体词ej的词频除以集合样本文档中所有实体词的词频总数,计算公式如下:
其中,eh(1≤h≤n)是集合样本文档中的实体词。
f)采用查询与集合相关度计算公式,得到各个集合评分。其中,查询与集合相关度计算公式如下:
g)按集合评分高低进行排序,选择评分较高的前若干个集合。
以上的所述乃是本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的精神时,仍应属本发明的保护范围。