一种基于统计和浅层语言分析的维吾尔文语义串抽取方法与流程
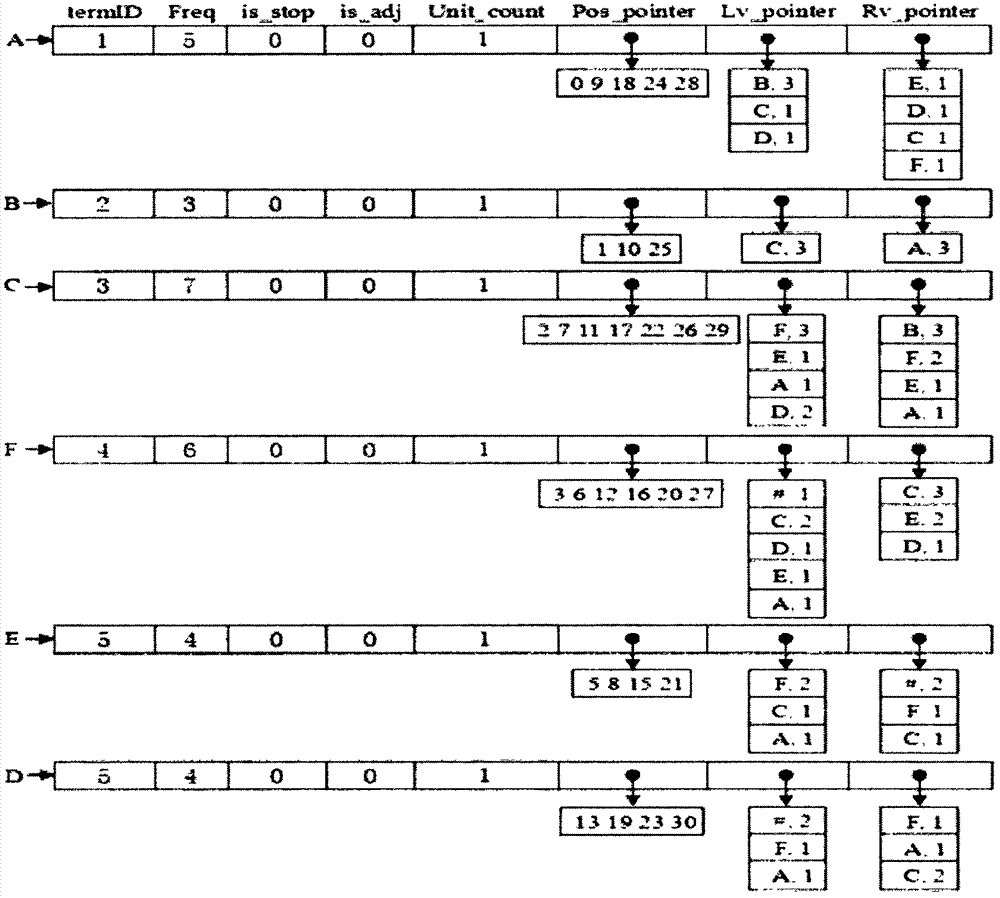
本发明具体涉及一种基于统计和浅层语言分析的维吾尔文语义串抽取方法,属于少数民族语言语义串抽取
技术领域:
。
背景技术:
:关于语义串的识别和抽取,国内外很早就有学着开展一些研究工作。可以定义语义串为:是文本中上下文任意多个连续字符(字或词)的稳定组合,其语义完整及独立的,能作为文本中线索词,包括人名、地名、机构名等命名实体,还有实词(科学家)、新词(自贸区)、词组或短语(地方政府阳光举债)、领域术语(人感染h7n9确诊病例)、固定搭配(严格监管)等。语义串抽取是文本处理中的基础技术,可以直接应用到文本挖掘多个领域中。如应用到分词中,可以提高新词识别效率。应用到搜索引擎中索引词的抽取、查询词的修正、以及相关搜索分析中,可以达到索引压缩目的的同时也可以大大提高搜索效率。应用到网络舆情系统中,可以将语义串作为主要的舆情线索进行网络舆情热点的有效发现和跟踪。应用到本发明中,以语义串作为特征表征文本,可以构造泛化能力更强、更经凑的文本模型,这就会明显提高聚类和分类准确率。除此之外,专业术语抽取及领域词典编撰等更多的领域,语义串的抽取仍能作为有效手段。随着维吾尔文文本挖掘更多领域研究工作的深入开展,维吾尔文现有分词方法开始暴露出其潜在的不足和缺陷,维吾尔文语义串抽取方法的研究变得为尤为必要和迫切。技术实现要素:因此,本发明目的是为解决现有技术中的上述问题,提出了一种基于统计和浅层语言分析的维吾尔文语义串抽取方法,并通过实验验证其可行性和有效性。具体的,本发明的方法包括:步骤1确定文本索引结构及定义模式规则:确定包括词典、一级索引、二级索引的三层索引结构;定义文本中的可信频繁模式;定义频繁模式发现中的语言规则;步骤2频繁模式发现;大规模文本中维吾尔文频繁模式发现步骤具体包括:步骤2a建索引;对于经过预处理的文本集,首先按单词在文本中出现的顺序建立词典,然后对于生成的单词id序列建词索引;步骤2b串扩展及频繁模式发现;让所有单词id进入一个队列中,然后根据每个单词的索引信息从每个单词扩展得到其二词或三词串,让该单词出队并将新产生的扩展串入队,继续从n词串扩展到n+1词或n+2词串,反复迭代,直到队列为空;步骤3串完整性评价及语义串抽取;根据上下文邻接特征来判断每一个语义串候选的结构完整性,用公式一为每一个候选语义串赋权重:aeweight(s)=min(lae(s),rae(s))公式一其中,aeweight(s)是串s的邻接熵权重,lae(s)是串s的左邻接熵,rae(s)是串s的右邻接熵,左邻接熵、右邻接熵按公式二计算:其中,m是串s的左邻接种类数,ni是串s的第i个左邻接的频次,所有左邻接频次总和为n,计算邻接特征量所需要的全部信息在它们被发现时记录好并存入索引中,依次输出邻接特征量达到阈值的频繁模式,即为最终抽取到的语义串。进一步的,所述方法步骤1中的包括词典、一级索引、二级索引的三层索引结构具体为:词典:将不同长度的词条或串转换成整个索引空间中唯一的词条id或串id;一级索引:作为索引项的每一个单词或串,经过词典管理工具翻译成全索引空间唯一的id,这个id作为该索引项对应的一级索引入口,一级索引包含的数据有:freq是该索引项在语料中的频次;is_stop是停用词标志;is_adj是形容词标志;unit_count是该索引项的单词长度;pos_pointer,lv_pointer和rv_pointer分别是对应二级索引入口地址偏移量;二级索引:二级索引又是一个索引项列表,其入口由一级索引获取,二级索引表中的每一项是该索引项在文本集中的概要描述,其中,第一个索引表是position,是该索引项的位置倒排;第二个是左邻接列表,是该索引项所有的左邻接及其频次;第三个是右邻接列表,是该索引项所有的右邻接及其频次。进一步的,所述方法步骤1中定义文本中的可信频繁模式具体为:设s=w1w2…wn是一个长度为n的维吾尔文单词串,以空格隔开的n个单词序列,t=s1#s2#…sm#是由m个单词串构成的文本语料,#标志文本中的各种标点符号;定义1:对于单词串s=w1w2…wn,如果文本语料中至少存在两个位置pos1和pos2,并使得则s称为语料t中的一个模式,也称为重复串;定义2:根据事先设定的各个参数阈值,如果support(s)>minsup(minsup为最小支持度)或frequency(s)>minfreq,minfreq为最小出现频次,则称s为语料t中的频繁模式,如confidence(s)>minconf,minconf为最小置信度,则可确定s为可信频繁模式;设wi-1wi是语料t中维吾尔文词对,wi-1是上文,wi是下文,观察候选频繁模式s=(wi-1wi)是否为可信频繁模式时,将frequency(s)>2(minfreq=2)的模式都选为频繁模式,再评价wi-1→wi的置信度confidence(wi-1→wi)来选取可信频繁模式;置信度confidence(wi-1→wi)是指上文wi-1出现的情况下,其下文出现wi的后验概率,是对单词关联wi-1→wi的准确度的衡量,当confidence(wi-1→wi)>minconf时,可确定s=(wi-1wi)是一个可信频繁模式,按公式三计算:定义3:逆置信度是指单词关联wi-1→wi的下文wi出现的情况下,其上文是wi-1的条件概率,按公式四计算:定义4:对于语料t中的一个频繁模式s,如confidence(s)>minconf或r-confidence(s)>minconf,则可确定s为可信频繁模式。进一步的,所述方法步骤1中步骤1中定义频繁模式发现中的语言规则具体为:对于文本中的相邻词对“ab”,如成立条件:a∈{iw}orb∈{iw}orb∈{adj},则判断a与b不能结合成为关联模式。进一步的,所述方法步骤2b中单词或词串的扩展条件具体为:设xy是文本中相邻的两个单词或串,x是y的右邻接词,y是x的左邻接词,要进行x→xy的扩展,则要满足以下条件:条件1x不是停用词,即is_stop(x)=0;条件2x是频繁模式,即freq(x)>=2;条件3y不是停用词或形容词,即is_adj(y)=0且is_stop(y)=0;条件4y是频繁模式,即freq(y)>=2;条件5xy是可信频繁模式,即confidence(x→y)>minconf且r-confidence(x→y)>minconf;单词或词串的扩展流程具体为:词或词串索引id入队,队头词或词串出队,读入一级索引链,判断是否满足条件1及条件2,如果不满足条件1及条件2,则下一词或词串出队,读入一级索引链,继续判断是否满足条件1及条件2;如果满足条件1及条件2,则读入2级索引链中读取满足条件1及条件2的这一词或词串的左邻接列表,根据条件3、条件4、条件5依次判断这一词与这一词的每一个左邻接词构成新串的可能性,新产生的二词或三词串作为可信频繁模式入队,等待继续被扩展,依次对每一个单词进行二词或三词扩展,同时将新产生的二词或三词串作为可信频繁模式入队,等待继续被扩展,直至串扩展候选队列为空,频繁模式发现过程结束。本发明的有益效果在于:本发明提供一种基于统计和浅层语言分析的维吾尔文语义串抽取方法,采用一种多层动态索引结构为大规模文本建词索引,然后是结合维吾尔文词间关联规则采用一种改进的n元递增算法进行词串扩展并发现文本中的可信频繁模式,最终依次判断频繁模式串结构完整性从而得到语义串。通过在不同规模的语料上实验发现,此方法可行有效,能够应用到维吾尔文文本挖掘多个领域。本发明提出的语义串抽取方法不仅可以应用到维吾尔文文本挖掘中,还能应用到哈萨克文、柯尔克孜文等同语系语言文本挖掘中。附图说明图1为具体实施方式中索引结构示意图;图2为具体实施方式中建立索引结构的示意图;图3为具体实施方式中串扩展初始状态示意图;图4为具体实施方式中扩展候选队列及索引变化情况示意图;图5为具体实施方式中所有单词都被访问完之后,队列及索引变化情况示意图;图6为具体实施方式中维吾尔文语义串发现过程总体流程图;图7为具体实施方式中从频繁模式集中抽取语义串流程流程图;图8a为具体实施方式中minconf不同取值下sdc上评价指标变化情况示意图;图8b为具体实施方式中minconf不同取值下ssc上评价指标变化情况示意图;图9a为具体实施方式中单策略实验结果图;图9b为具体实施方式中双策略实验结果图;图10为具体实施方式中逐步增加策略实验结果图;图11为具体实施方式中大规模语料实验结果图。具体实施方式下面结合附图对本发明的具体实施方式进行说明:1、文本表示:影响浅层语言分析效率的主要因素是文本表层质量,主要包括文本书写规范性和词法正确性。因此,先对待处理文本进行正则化,拼写校对,词干切分等必要的预处理。词索引是将单词作为term,与单词属性之间建立映射的数据结构,是常见、高效的大规模文本表示方法。本发明语义串抽取方法在单词索引基础上,考察单词扩展到串,串扩展到更长的串的可能性,因此新产生的串还需要写入索引中,这就要求索引具有动态特性,和更好的规模扩展性。因此,本发明设计了如图1所示的索引结构,由三个部分组成。1)词典:是每一个词条与它对应的id之间的管理工具。对于本发明研究工作来说,初始索引项是单词(词干),经过词条扩展后会产生长度不同的新的串,而这些串都作为新的索引项追加到索引中。显然,这不利于存储和运算。在本发明研究中,我们设计了一个基于双数组trie树优化算法的维吾尔文词典管理工具,将不同长度的词条(串)转换成整个索引空间中唯一的词条(串)id,这样节省了存储空间,同时极大提高了运算效率。2)一级索引:作为索引项的每一个单词或串,经过词典管理工具翻译成全索引空间唯一的id,然后用这个id就可以找到该索引项对应的一级索引入口。一级索引包含的数据有:freq是该索引项在语料中的频次;is_stop是停用词标志;is_adj是形容词标志;unit_count是该索引项的单词长度(串中包含的单词个数);pos_pointer,lv_pointer和rv_pointer分别是对应二级索引入口地址偏移量。3)二级索引:二级索引又是一个索引项列表,其入口由一级索引获取。二级索引表中的每一项是该索引项在文本集中的概要描述。其中,第一个索引表是position,是该索引项的位置倒排;第二个是左邻接列表,是该索引项所有的左邻接及其频次;第三个是右邻接列表,是该索引项所有的右邻接及其频次。通过这种索引结构,可以描述每一个单词或串尽可能多的属性,其动态性,效率和可扩展性等方面也符合海量文本处理需求。2、可信频繁模式发现及语义串抽取:语义串作为可独立运用的语言单元,在真实语言环境中有一定的流通度,其内部单词之间存在一定的并发关系(co-occurrencerelationships)。在数据挖掘领域中,并发关系也称为关联(association),则文本集中频繁出现的单词关联,我们可以称它为频繁关联模式,简称为频繁模式(frequentpattern:fp)。因此,我们可以用关联规则挖掘中的评价指标来衡量频繁模式中相邻单词之间的关联强度。2.1文本中的可信频繁模式根据关联规则的基本概念,一篇文本发明档甚至文档中的一句话我们都可以作为事务来对待。此时,文本中的单词就是一个项目(item),而文本集就是一个项目集(itemset)。因此,给定一个文本集或句子集,我们完全可以从中找出单词之间的并发关系(关联)。假设s=w1w2…wn是一个长度为n的维吾尔文单词串(以空格隔开的n个单词序列),t=s1#s2#…sm#是由m个单词串构成的文本语料,#标志文本中的各种标点符号。定义1:对于单词串s=w1w2…wn,如果文本语料中至少存在两个位置pos1和pos2,并使得则s称为语料t中的一个模式(pattern),也称为重复串(repeat)。定义2:根据事先设定的各个参数阈值,如果support(s)>minsup(minsup为最小支持度)或frequency(s)>minfreq(minfreq为最小出现频次),则称s为语料t中的频繁模式(frequentpattern:fp),如confidence(s)>minconf(minconf为最小置信度),则可确定s为可信频繁模式(crediblefrequentpattern:tfp)。设wi-1wi是语料t中维吾尔文词对,wi-1是上文(前件),wi是下文(后件),观察候选频繁模式s=(wi-1wi)是否为可信频繁模式时,我们没有使用支持度指标。因为,support(wi-1→wi)是语料t中wi-1和wi共现次数的百分比,是对这个单词关联重要性的衡量,说明它在语料t中有多大的代表性。但本发明研究是要找出语料中所有重复出现单词关联,而不关心这个单词关联在语料中的重要性。因此,我们将frequency(s)>2(minfreq=2)的模式都选为频繁模式,再评价wi-1→wi的置信度confidence(wi-1→wi)来选取可信频繁模式。置信度confidence(wi-1→wi)是指上文wi-1出现的情况下,其下文出现wi的后验概率,是对单词关联wi-1→wi的准确度的衡量。当confidence(wi-1→wi)>minconf时,可确定s=(wi-1wi)是一个可信频繁模式。计算公式如下:假如,对于语料t中频繁模式s=(wi-1wi)有:freq(wi-1)=100,freq(wi-1wi)=10,freq(wi)=10,则由公式(1)计算得出confidence(s)=0.1,因为置信度过小,模式s很可能被过滤掉。但是,我们观察s的下文wi,就发现它与上文wi-1的100%的并发率,很明确s是个可信频繁模式。针对这种情况,我们再引入了一个评价指标,称为逆置信度。定义3:逆置信度(r-confidence)是指单词关联wi-1→wi的下文(后件)wi出现的情况下,其上文是wi-1的条件概率,其计算公式如下:评价上例中s的逆置信度,由公式(2)计算得到r-confidence(s)=1,因此频繁模式s以极高的准确度被选为可信频繁模式。据此,我们定义可信频繁模式的评价准则。定义4:对于语料t中的一个频繁模式s,如confidence(s)>minconf或r-confidence(s)>minconf,则可确定s为可信频繁模式(tfp)。2.2频繁模式发现中的语言规则:本发明研究中,我们发现以下语言特性对于文本中关联模式的识别非常有用。特性1:维吾尔文中的助词(等)、连词(等)、副词(等)、量词(等)、代词(等)以及感叹词(等)等功能词,在文本中始终不跟其他单词结合成为语义串。本发明研究中,我们将这些词称为“独立词”(independentword:iw)。特性2:维吾尔文单词间的结合主要是在名词(n),形容词(adj)和动词(v)之间发生。其中,当形容词与名词或与动词结合时,形容词总是作为前驱,而不会出现在后继位置。因此,n+adj或v+adj关系的相邻单词绝不可能结合构成一个语义串。根据以上语言特性1和特性2,归纳出用于词间关联识别的单词结合规则(wordassociationrule:war)并定义如下:定义5(单词结合规则:war):对于文本中的相邻词对“ab”,如成立条件:a∈{iw}orb∈{iw}orb∈{adj},则判断a与b不能结合成为关联模式。2.3频繁模式发现过程本发明频繁模式发现是对n元递增算法的改进,根据主要思路及所采取的文本表示模型,大规模文本中维吾尔文频繁模式发现,是按照以下步骤进行。(1)建索引。对于经过预处理的文本集,首先按单词在文本中出现的顺序建立词典,然后对于生成的单词id序列建词索引。对于只有6个单词的文本“abcf#efceabcfd#efcadfecdabcfacd#”(#是标点符号),建词索引如图2所示。(2)串扩展及频繁模式发现。一开始,让所有单词(id)进入一个队列中,然后根据每个单词的索引信息从每个单词扩展得到其二词或三词串,让该单词出队并将新产生的扩展串入队,继续从n词串扩展到n+1词或n+2词串,反复迭代,直到队列为空。串扩展候选单词索引及队列初始状态如图3所示。假定xy是文本中相邻的两个单词(或串),x是y的右邻接词(上文),y是x的左邻接词(下文),要进行x→xy的扩展,则要满足以下条件:①x不是停用词,即is_stop(x)=0;②x是频繁模式,即freq(x)>=2;③y不是停用词或形容词,即is_adj(y)=0且is_stop(y)=0;④y是频繁模式,即freq(y)>=2;⑤xy是可信频繁模式,即confidence(x→y)>minconf且r-confidence(x→y)>minconf;当队头单词a出队后,因为a具备条件①和②,因此从二级索引中读取a的左邻接列表,然后根据条件③④⑤依次判断a跟其每一个左邻接(下文)词构成新串的可能性。本例中,a的第一个左邻接b具备条件③和④,同时a与b构成的扩展串ab也具备条件⑤,因此将新产生的串ab入队,同时将它信息追加到索引中,然后判断a跟其下一个左邻接词c的关联强度,依次判断并进行从单词到二词扩展,直到a的所有左邻接词都被访问完为止(a与c和d都不能结合)。此时,扩展候选队列及索引变化情况如图4所示。之后,让当前对头单词b出队,因为b已跟a结合,就不再进行扩展,然后是c出队。就这样,依次对每一个单词进行二词或三词扩展,同时将新产生的二词或三词串作为可信频繁模式入队,等待继续被扩展。所有单词都被访问完之后,队列及索引变化情况如图5所示。等所有单词的二词或三词串扩展进行完毕,就接着进入从候选串扩展更长串的过程,直到串扩展候选队列为空,此时,频繁模式发现过程就结束。总体流程如图6所示。2.4串完整性评价及语义串抽取如果一个串能成为语义串,那么它在结构、语用、语义以及统计上应该满足一定的特点。一般情况下,通过频繁模式发现得到的结果只能满足可统计性要求,称为语义串候选,这还需要采用上下文邻接分析或语言模型分析等方法进行进一步甄别和过滤。本发明研究中,判断语义串候选结构完整性,我们的方法与中文有所不同。主要原因如下:1)中文常用功能字会跟其它汉字构成实词,如“的士”等。因此,对于串首(串尾)出现功能字的情况,就需要判断串首(串尾)字对双字耦合度和首字词首(词尾)成词概率。另外,不是所有的汉字都能作为词首或词尾,因此可以根据单字位置成词概率来判断串首和串尾,可以有效过滤垃圾串。但维吾尔文与中文不同,首先维吾尔文功能词不会跟其它词结合构成新词。另外,维吾尔文中的词本来就是一个独立运用的语言单位,词在串首、串尾位置用法没有特有规律(形容词除外)。2)维吾尔文语义串抽取中,我们也可以与中文类似的方法去判断串首和串尾“双词”耦合度,这对于垃圾串的过滤肯定会有一定的帮助。但是,这就需要大量学习语料、人工标注并构建双词耦合度词典,而本发明研究目的是无监督学习的语义串抽取方法。3)关于语言模型的分析方法,本算法又是引入单词结合规则,并将它嵌入到频繁模式发现过程中,因而有效避免串尾出现形容词的垃圾串产生的情况,减轻了垃圾串过滤任务。因此,本发明主要是根据上下文邻接特征来判断每一个语义串候选的结构完整性。中文相关研究结果表明,采用邻接熵的结果比其它三种邻接特征量(邻接种类,邻接对种类,邻接对熵)的结果好。因此,我们用以下计算公式为每一个候选语义串赋权重:aeweight(s)=min(lae(s),rae(s))(3)其中,aeweight(s)是串s的邻接熵(adjacencyentropy:ae)权重,lae(s)是串s的左邻接熵,rae(s)是其右邻接熵。左(右)邻接熵计算公式为:其中,m是串s的左邻接种类数,ni是串s的第i个左邻接的频次,所有左邻接频次总和为n,计算邻接特征量所需要的全部信息早在它们被发现时记录好并存入索引中。最后,依次输出邻接特征量达到阈值的频繁模式,那就是最终要得到语义串。流程如图7所示。3、实验设计与结果分析3.1实验语料本实验数据是来自新疆大学智能信息处理重点实验室提供的文本语料,根据不同实验目的准备如下实验语料:1)单文档小语料(singledocumentcorpus:sdc):2014年新疆维吾尔自治区两会政府工作报告(维吾尔文,144k)。1)小规模预料(smallscalecorpus:ssc):从各类网站收集3000个文档,大小为23.2m。2)大规模预料(largescalecorpus:lsc):从国内维吾尔文网站采集(采集时间介于2013年9月23日到2014年8月18日之间)并格式化后的112379个纯文本,大小为739m。3.2评价标准本发明提出的维吾尔文语义串抽取方法是建立在频繁模式统计的基础上,因此我们设计的评价指标是以频次统计而获取的频繁模式串为基准的,这样才能较准确的评价垃圾串过滤效率,同时还能减轻计算召回率的耗费。当然,频繁模式发现中的最小置信度minconf和最小频次minfreq也会影响最后语义串抽取效率。本发明将minfreq取2,对于minconf最佳取值下的实验结果进行评价,主要使用的评价指标有:其中,p@n是用来评价大规模预料实验结果的指标,是拿前n个结果的准确率来评价实验正确率。3.3实验结果及分析实验1:观察最小置信度阈值不同取值及可信频繁模式发现效率:分别在语料sdc和ssc上观察minconf不同取值对频繁模式发现效率的影响,并根根unit_count>1的频繁模式总数及其中的可作为语义串的可信频繁模式总数来计算各评价指标,从而为本发明实验确定串扩展准确率最高时的minconf阈值。结果如图8a、图8b所示。从不同minconf阈值下的频繁模式发现准确率和召回率变化情况看出,当minconf=0.4时,得到了最好的识别效率。因此,我们确定minconf=0.4为阈值进行后续试验和分析。实验2:对比使用不同策略情况下的识别效率:上下文邻接分析,单词结合规律和独立词隔离是维吾尔文语义串识别过程中的三个不同策略。为了观察它们对语义串识别效率的影响,我们采用不同策略的组合在语料ssc上分别做实验,不同策略组合及实验结果如表1所示。表1中,fpf指频繁模式发现(frequentpatternfind),ca是上下文邻接分析(contextanalysis),war指单词结合规则(wordassociationrule),iwi指独立词隔离(independentwordisolation)。表1序号实验策略频繁模式语义串准确率召回率f-measure1fpf153632337156124.4%2fpf+iwi75243141418255.5%3fpf+war89562987337846.9%4fpf+ca114872337206130.6%5fpf+war+72712987417854.0%6fpf+iwi+70973141448257.7%7fpf+iwi+45943792821090.4%8fpf+iwi+42573792891094.2%我们再把频繁模式(fpf)抽取结果作为实验基准,分析了不同策略单独使用或组合策略情况下的实验结果,如图9a、图9b所示。从图9(a)中f值来看,策略2是最有效的,这就表明我们在频繁模式发现过程中引入的独立词隔离策略起到了作用,有效避免了大量垃圾串的产生;单词结合规则比上下文邻接分析有效,因为使用单词结合规则同样避免了错误的串扩展而产生的垃圾串。从图9(b)中可以看出,在频繁模式发现阶段串扩展判断中使用的两种策略对语义串发现效率的影响最大,在此阶段就已经达到了相当高的识别准确率和召回率,这就表明这两种策略完全符合维吾尔文语言文字特性。我们还采用逐步增加策略的方式观察识别效率的变化情况,实验结果如图10所示。可以看出,每一步增加策略各个评价指标一直都是上升的趋势,说明每一种策略都在起作用。在频繁模式发现阶段引入独立词隔离策略,缩短处理时间的同时避免了大量垃圾串的产生,在此基础上使用单词结合规则进一步排出了以上情况的发生,最后使用上下文邻接分析策略再过滤少量垃圾串而得到了较高的准确率。实验3:大规模语料上的实验:在大规模语料lsc上做实验,得到unit_count>1的语义串个数为166334个,图11中显示结果集n从100增大到1500时,分别按邻接熵和频次排序时的p@n的变化情况。从图11中可以发现,将邻接熵作为权重排序比按频次排序有效,这就反映了上下文邻接变化多样性是语义串的固有属性。从结果上看,n从100增加到1500过程中,准确率一直在97%以上,基本接近于实用化的水平,说明了本发明提出的方法对于大规模语料是更有效的。只从某一条曲线变化情况来分析,呈现出了稳步下降的趋势,随着n的增加p@n逐渐降低,是因为排序越靠后的模式串成为语义串的可能性就越小,准确率也自然越低。浅层语言分析的方法能够抽取语言表层之下的特定关键信息,其时间效率、分析结果的准确性和系统的实用性等方面较能满足海量文本处理需求。因此,本发明研究一种基于浅层语言分析的维吾尔文语义串快速抽取方法。设计了一种多层动态索引结构,符合于大规模文本的表示及语义串抽取过程中的动态性和可扩展性需求。引入了维吾尔文独立词隔离及单词结合规则等语言特性,提出了一种基于n元递增算法的词串扩展及可信频繁模式发现算法,模式串结构完整性评价方法和权重计算方法等。经过几个实验来分别验证了本发明提出的方法在规模不同的语料上都是有效的,在单文档小语料上的实验准确率达到了76.3%,小规模语料上的实验准确率达到89.1%,在大规模语料上的实验p@n(n为1500)结果超过98%。本发明提出的语义串抽取方法不仅可以应用到维吾尔文文本挖掘中,还能应用到哈萨克文、柯尔克孜文等同语系语言文本挖掘中。以上是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1