一种基于多模态信息的自动化结果生成方法与流程
本发明涉及网络信息交互领域,尤其涉及一种基于多模态信息的自动化结果生成方法。
背景技术:
我们生活在网络和社会信息的洪流中,庞大的信息量提供了大量实时新闻。随着社会网络的发展,越来越多的人开始上传图片或评论到不同的社交平台上,并从社交网络中获取信息。社交媒体为人们的生活提供了很多便利,如旅行建议、场地主题提取、目标推荐、事件检测等等。然而,用户原创内容中由于包含大量的视觉和文本信息噪声,很难为其他用户提供有用的信息或结果。
近年来,现有技术中已提出很多方法来解决此问题:
1、一种基于官方网站新闻的事件检测方法,可以有效地用于广播新闻报道[1];
2、一个新的框架,以社交网络平台提供的旅游信息为基础,为用户推荐相关旅游信息,大大丰富用户的选择范围[2];
3、利用图聚类方法收集大规模多模态信息,寻找信息检索的潜在主题[3]。
然而,上述方法只能用于用户有针对地查询的情况。当查询不明确时,很难向用户提出一些有用信息。例如,当折扣信息出现在网站中时,用户只想获取自己感兴趣的目标信息。
技术实现要素:
本发明提供了一种基于多模态信息的自动化结果生成方法,本发明实现了利用在不同模态和不同社交网络上的多媒体数据自动生成相关结果,详见下文描述:
一种基于多模态信息的自动化结果生成方法,所述自动化结果生成方法包括:
对文本信息进行预处理,对预处理后的文本信息生成潜在的文本主题,作为文本主题集;
采用基于部分检测模型对视觉信息进行处理,获取预处理后的事件图片集;
根据文本主题集、预处理后的事件图片集生成多模态图,将分类后的多模态图作为稠密子图,将稠密子图的局部最大值作为一个主题,进行多模态主题的提取。
其中,所述基于部分检测模型具体为:
由pascal数据库、与harr人脸检测模型组成。
其中,所述多模态图具体为:
g=(v,e,w)
其中,g表示多模态图的结构,v={v1,...,vn}表示顶点集,
其中,所述将稠密子图的局部最大值作为一个主题具体为:
通过拉格朗日函数的优化、以及karush-kuhn-tucker条件,获取稠密子图的局部最大值。
本发明提供的技术方案的有益效果是:
1、提出了一个有效的自动化结果生成框架,可以有效地从官方网站检测流行事件,并通过多模态社交网络数据来突出流行事件,为用户生成最终的结果;
2、利用图聚类算法对图结构进行聚类,从而得到一系列的子图结构,提取多模态的话题模型,根据不同主题生成最终结果;且通过相应的实验验证了方法的实用性。
附图说明
图1为一种基于多模态信息的自动化结果生成方法的流程图;
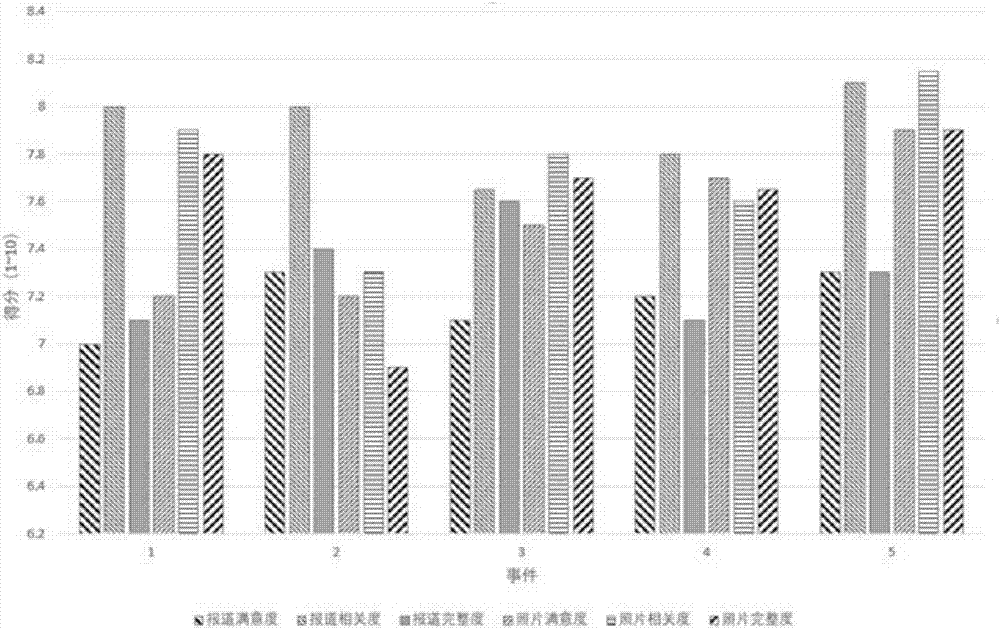
图2为生成报道的平均满意度。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
实施例1
一种基于多模态信息的自动化结果生成方法,参见图1,该自动化结果生成方法包括:
101:对文本信息进行预处理,对预处理后的文本信息生成潜在的文本主题,作为文本主题集;
102:采用基于部分检测模型对视觉信息进行处理,获取预处理后的事件图片集;
103:根据文本主题集、预处理后的事件图片集生成多模态图,将分类后的多模态图作为稠密子图,将稠密子图的局部最大值作为一个主题,进行多模态主题的提取。
综上所述,本发明实施例通过上述步骤101-步骤103实现了利用修改后的图聚类方法,提取多模态的话题模型,根据不同主题生成最终结果,满足了实际应用中的多种需要。
实施例2
下面结合具体的计算公式,对实施例1提出的一种基于多模态信息的自动化结果生成方法做出详细说明,详见下文描述:
201:对文本信息进行预处理,对预处理后的文本信息生成潜在的文本主题,作为文本主题集;
其中,对文本信息的处理包括:滤除不相关的推特信息、滤除所有冗余单词、移除诸如网页和邮件地址等链接,同时收集在其他网站上关于相关事件的数据。
将同一事件的文本数据统一看作一个文档文件。利用三层贝叶斯概率模型lda(latentdirichletallocation),为每一个事件生成一系列潜在文本主题t={t1,t2,...,tn},每个文本主题用tn表示,n的取值为正整数,
202:采用基于部分检测模型对视觉信息进行处理,获取预处理后的事件图片集;
与文本信息类似,根据不同事件,用户上传的图片相关性也会不同[4][5]。不同的用户有不同的习惯和兴趣。表示不同事件的图片之间关联性低。通过观察发现,含有人的图像与事件的相关性程度较低[6]。人占图像的面积越大,图像的相关性就越低。为了消除相关性低的图像,采用基于部分检测模型dpm(part-baseddetectionmodel)检测传统对象[7]如人脸和人,即包括:
1、在本发明实施例中采用pascal(patternanalysis,staticalmodelingandcomputationallearning,模式分析,统计建模,计算学习)数据库训练人体检测模型;
若人占图像的面积超过45%,就会删除该张图片。通过统计实验得到,将阈值设为45%最为合理。
2、移除人脸图像,采用经典的harr人脸检测模型,将过滤阈值设置为45%。
即,本发明实施例通过pascal数据库、与harr人脸检测模型组成的基于部分检测模型,对图片进行处理,获取预处理后的事件图片集。
其中,本发明实施例对上述的检测模型、数据库、以及设定的阈值等不做限制,可以根据实际应用中需要进行组合,或参数的设定,只要能实现上述功能的方法、参数均可。
203:根据文本主题集、预处理后的事件图片集生成多模态图,将分类后的多模态图作为稠密子图,将稠密子图的局部最大值作为一个主题,进行多模态主题的提取。
给定一个地理区域,t={t1,...,tn}表示文本主题集,p={p1,...,pn}分别表示事件图片集。通过建立一个多模态图来表示多媒体文件之间的关系。每个多媒体文件,包括文本主题和图像,用图像里的一个节点来表示。因此,在多模态图结构中有两类顶点:
g=(v,e,w)
其中,g表示多模态图结构,v={v1,...,vn}表示顶点集,
每个点v可以是文本主题ti或图片集pj。边代表点与点之间的关系,边权重反映了一对相邻顶点之间的相似度。将多模态图g相对应的加权相似度矩阵表示为a∈rn×n,rn×n为n×n的实数域矩阵。
多模态图构建后,对构建的多模态图进行分类,将多模态图g分类之后的子图作为稠密子图,可以将稠密子图作为一个语义主题。为了检测稠密子图,将采用扩展图移位的成对聚类方法[8]。然而,图像尺度不变特征转换方法(gs)假设节点具有相同的模态,不能保证子图中含有不同类型的节点。因此,将图移位的成对聚类方法扩展到不同媒体类型节点的处理上。每个局部最大值表示多模态图的一个稠密子图,被定义为一个主题:
g(x)=xtax
其中,a是相似度矩阵,概率集群x∈δn表示分类后的子类,将概率集群x用向量表示。
其中,δn={x|x∈rn,x≥0,|x|1=1},rn为n维向量,|x|1为x的1-范数。
实际上,x是单位映射向量,用于表示子图包含的每个顶点的概率。特别地,xi=0表示不包含在该子类中的第i个顶点。gs方法通过g(x)测量子图x*的平均连接强度,找到分类后分值最大的g(x)。
上述gs成功将一个标准的二次优化问题转换为子图检测问题,并提出邻域展开法,将子图模式的支持扩展到邻域,以解决这个二次规划问题。发现稠密子图与g(x)的最大值是相等的,此时∑xi=1,xi≥ci。其中i=2,...n时,ci=0。c1被设为一个正数,这样稠密子图才能总是包括主题节点。
本发明实施例的目标是要找到包含一个文本主题及其相应视觉信息的稠密子图,每次只考虑一个主题节点和所有的图片节点。下面给出一个约束的优化问题,得到拉格朗日函数:
其中,用x1表示主题节点,因此,c1被设为一个正数,且当i=2,...n时,ci=0。这样稠密子图才能总是包括主题节点λ,αi为拉格朗日乘数。
任何局部最大值x*都必须满足karush-kuhn-tucker(kkt)条件。如下:
其中
综上所述,本发明实施例通过上述步骤201-步骤203实现了可以有效地从官方网站检测流行事件,并通过多模态社交网络数据来突出流行事件,为用户生成最终的结果。
实施例3
下面结合图2,以及实验数据对实施例1和2中的方案进行可行性验证,详见下文描述:
本实验选取了6个可信任且有影响力的网站,包括straitstimes,todayonline,channelnewsasia,landtransportauthority,therealsingapore,和asiaone构建数据库。利用丰富站点摘要rss(richsitesummary)技术收集在新加坡发生的新闻文章。使用新闻爬虫工具,每一小时爬一次。共计爬了7700条新闻并以json格式储存在mongodb数据库,时间是从2015年2月24日到2015年5月30日。也使用twitter流api(applicationprogramminginterface)爬了地理标记的推特信息,时间是从2014年10月30日至2015年5月15日,地理位置坐标范围为[103.600333,1.199395,104.087852,1.476724],因为新加坡位于此范围内。此外,对不位于新加坡的推特信息进行过滤,通过使用新加坡地域多边形,共收集了1396745个推特信息。
为了评估本方法的性能,选取20个用户为一组,采用如下的三个评判标准:
(1)每一事件的多媒体报道的一致性水平;
(2)每一事件的多媒体报道的完整程度;
(3)多媒体报道的满意度。
本方法邀请了20人参加该次测试,评估结果如图2所示。一般来说,本方法生成的报告基本能够满足用户的需求。
从文章中提取的关键词作为新闻twitter的共享信息,并使用此信息查询在twitter的数据库搜索相关的推特信息。
该数字表明,密集度最高的地方在新加坡的cbd周围,假设为“妆艺”的位置。此处同样也是最拥挤的位置,很多人聚集在此参加活动。这与报道该事件的新闻网站所检测到的新闻是一致的,但它提供了更详细的信息,包括在事件中人们的兴趣分布情况。
总之,该实验表明,通过聚类和融合社会数据的方法,从新闻中侦测该事件,不仅可以找到人们感兴趣的事件在整个新加坡是如何分布的,也涵盖了人们对于该事件的评论。本方法提供了一个非官方报道的标准新闻文章,满足时效性和新奇性。
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
参考文献
[1]xiel,sundaramh,campbellm(2008)eventmininginmultimediastreams.procieee96(4):623–647
[2]huat,chenf,zhaol,luct,ramakrishnann(2013)sted:semi-supervisedtargeted-interesteventdetectionintwitter.in:proceedingsofthe19thacmsigkddinternationalconferenceonknowledgediscoveryanddatamining,pp1466–1469
[3]niew,wangx,zhaoyl,gaoy,suy,chuats(2013)venuesemantics:multimediatopicmodelingofsocialmediacontents.in:pacific-rimconferenceonadvancesinmultimediainformationprocessingpcm,pp574–585
[4]aggarwalcc,zhaicx(2012)asurveyoftextclusteringalgorithms.springer,us
[5]liua-a,suy-t,jiap-p,gaoz,haot,yangz-x(2015)multipe/single-viewhumanactionrecognitionviapart-inducedmultitaskstructurallearning.ieeetranscybern45(6):1194–1208
[6]wengj,leebs(2011)eventdetectionintwitter.in:internationalconferenceonweblogsandsocialmedia,barcelona,cataloniaspain,pp311–312
[7]zhangy,lig,chul,wangs(2013)cross-mediatopicdetection:amultimodalityfusionframework.in:ieeeinternationalconferenceonmultimedia&expo,pp1–6
[8]beckerh,dani,naamanm,gravanol(2015)identifyingcontentforplannedeventsacrosssocialmediasites.ph.d.dissertation,us
[9]larivireb,joostenh,malthouseec,birgelenmv,aksoyp,kunzwh,mhhuang(2013)valuefusion:theblendingofconsumerandfirmvalueinthedistinctcontextofmobiletechnologiesandsocialmedia.jservmanag24(3):268–293
- 还没有人留言评论。精彩留言会获得点赞!