基于加号模型的光伏发电功率预测方法与流程
本发明涉及新能源控制技术领域,涉及一种发电功率预测方法,尤其涉及一种基于加号模型的光伏发电功率预测方法。
背景技术:
近年来,在各国政府的大力支持下,分布式发电技术得到了快速的发展,尤其是具有清洁环保、无污染、分布广泛、可再生等优点的风力发电和光伏发电。然而,随着光伏发电大规模的接入电网,光伏出力的随机性、间歇性和波动性给电网的稳定运行带来了前所未有的压力,不但影响电能质量,加剧电网的调峰运行负担,而且也给电网的调度工作带来很大的困难。
为了应对大规模光伏发电接入对电网稳定性的影响,我国各高校及电力企业相继开展了对光伏发电功率预测的研究工作,目前已有光伏功率预测系统正在运行中。光伏功率预测系统对于减小光伏发电功率波动性对电网稳定运行和经济调度的影响,具有重要的现实意义。
然而,目前国内现有的功率预测系统大部分都是采用单个模型的预测系统,如神经网络模型、支持向量机模型等。虽然这种系统也能预测光伏发电功率,但这种系统较之于组合多个单模型的多模型系统往往准确率较低,性能有待提高。
技术实现要素:
本发明为了解决现有技术问题,构建新的加号模型,设计一种基于加号模型的光伏发电功率预测方法,用以解决现有预测方法精度低的问题。
本发明提供一种基于加号模型的光伏发电功率预测方法,包括:
步骤1、首先选取设定时间段数据采集模块采集的实际历史气象数据及光伏电站的输出功率,作为用于学习模型的训练样本集d;
步骤2、使用训练样本集d,迭代学习每个模式树,对于第i迭代,使用如下步骤学习模式树ti;
步骤2.1、修订训练数据集得到新训练数据集di,修改的方法为:设置每个实例xj∈d的输出功率为前i-1个模式树的残差值,即:
其中,tk(xj)为库中第k棵模式树在实例xj上的预测值;
步骤2.2、在di上,使用贪心方法训练模式树ti,训练过程为:(1)构建一个结点作为根结点,(2)如果di中输出功率的标准差为0或di中的实例数小于给定的阈值,则设置结点为叶结点,该叶结点输出为di中输出功率的均值,(3)否则,使用目标函数搜索测试条件,根据测试条件划分di到两个不同的子集并构建该结点的两个孩子结点,(4)对于每个子集,重复步骤(2)和步骤(3);目标函数为:
其中,dt为当前结点t对应的数据集,dtk是到达结点t的孩子结点k的数据集,sd(d)为d的标准差;
步骤3、对于新的待预测样本xj,使用累加的方法累积每个模式树预测结果得到模型最终的预测结果;累积方法对应的函数为:
其中ti(xj)为库中第i棵模式树在实例xj上的预测值,具体预测方法为:根据模式树内部结点的测试条件,沿着某条路径,分派待预测实例到相应的叶结点,该叶结点直接给出预测值。
优选的,数据集的采集输入属性包括:风向、风速、环境温度、湿度、云量、气压、法向直射辐照度、散射辐照度、总辐照度。
优选的,步骤1中获得的训练样本集d中和步骤3中的预测样本xj中的样本的缺失属性值,模式树自动处理。
与相关技术相比,本发明提供的基于加号模型的光伏发电功率预测方法能够有效地组合多个模式树的预测,大幅度提高最终模型的预测精度。
附图说明
图1为本发明提供的基于加号模型的光伏发电功率预测方法中加号模型示意图;
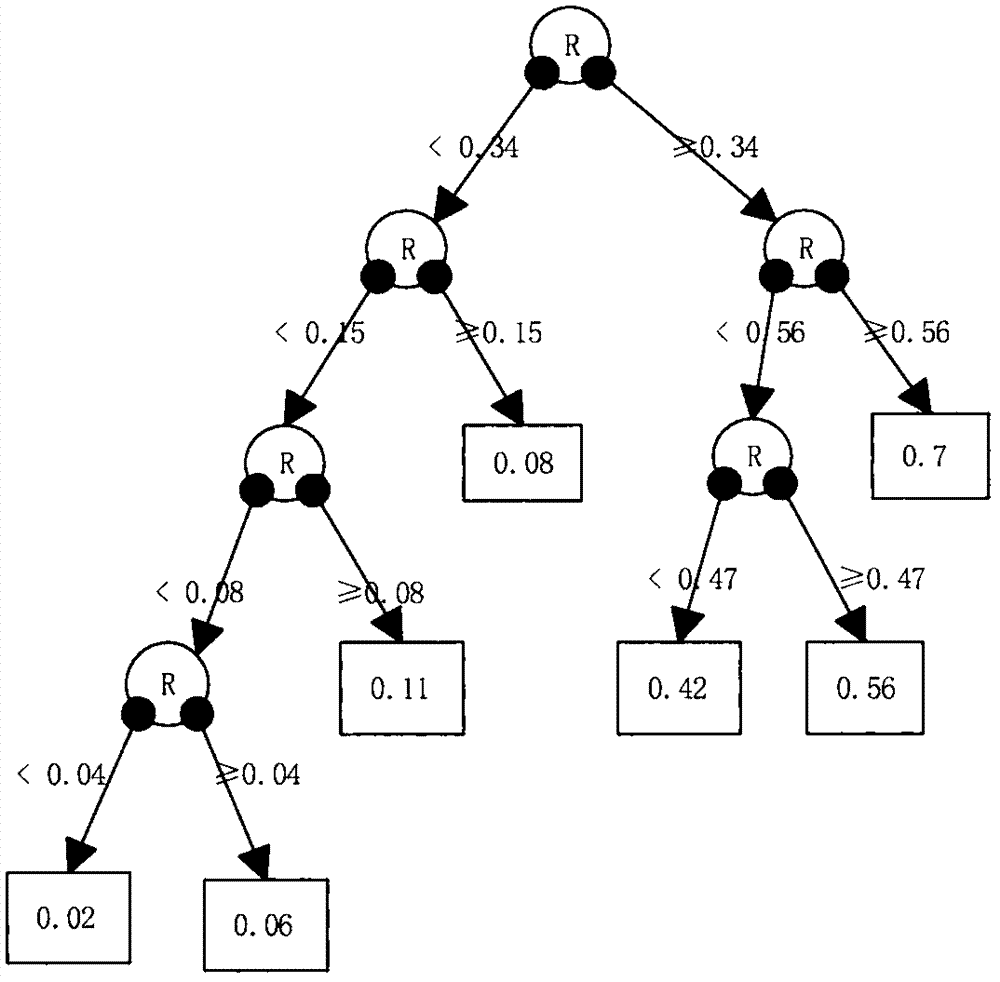
图2为单个模式树模型示意图。
具体实施方式
以下将参考附图并结合实施例来详细说明本发明。
一种基于加号模型的光伏发电功率预测方法,包括:
步骤1、首先选取设定时间段(一般为使用数据采集模块采集一个月以上的历史气象数据)数据采集模块采集的实际历史气象数据及光伏电站的输出功率,作为用于学习模型的训练样本集d。并对其进行预处理(比如对所选数据的合理性和完整性进行检验,对缺测和异常数据进行补充和修正,并进行归一化处理)。
数据集的采集输入属性包括:风向、风速、环境温度、湿度、云量、气压、法向直射辐照度、散射辐照度、总辐照度。
设置i=1,并设置第一次迭代用到训练样本集d1为d,即:d1=d。
步骤2、使用训练样本集d,迭代学习每个模式树,对于第i迭代,使用如下步骤学习模式树ti;
步骤2.1、修订训练数据集得到新训练数据集di,修改的方法为:设置每个实例xj∈d的输出功率为前i-1个模式树的残差值,即:
其中,tk(xj)为库中第k棵模式树在实例xj上的预测值;
步骤2.2、在di上,使用贪心方法训练模式树ti,训练过程为:(1)构建一个结点作为根结点,(2)如果di中输出功率的标准差为0或di中的实例数小于给定的阈值,则设置结点为叶结点,该叶结点输出为di中输出功率的均值,(3)否则,使用目标函数搜索测试条件,根据测试条件划分di到两个不同的子集并构建该结点的两个孩子结点,(4)对于每个子集,重复步骤(2)和步骤(3);目标函数为:
其中,dt为当前结点t对应的数据集,dtk是到达结点t的孩子结点k的数据集,sd(d)为d的标准差;
步骤3、对于新的待预测样本xj,使用累加的方法累积每个模式树预测结果得到模型最终的预测结果;累积方法对应的函数为:
其中ti(xj)为库中第i棵模式树在实例xj上的预测值,具体预测方法为:根据模式树内部结点的测试条件,沿着某条路径,分派待预测实例到相应的叶结点,该叶结点直接给出预测值。
步骤1中获得的训练样本集d中和步骤3中的预测样本xj中的样本的缺失属性值,模式树自动处理。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!