本发明涉及统计学习分类技术领域,更具体地说是一种基基于部分平均随机优化模型的医学影像分类方法。
背景技术:
随着大数据时代的到来,计算机科学与技术迅猛发展。逐渐对生物医疗、文本分类等领域产生了十分深远的影响。这使得人们试图让计算机逐渐代替人类专家从事十分具有挑战性的疾病诊断工作。自1985年伦琴发现x射线,尤其是1979年ct技术的出现以来,医学影像学获得了极大发展。近些年来,新的医学影像技术更是层出不穷。
然而,医学影像由于病人个体差异、影像的模糊和分布不均、存在噪声且数据存在很高的不平衡率等问题,导致医学专家对于一些疾病的诊断遇到了极难突破的瓶颈。而在面对诸如医学影像这类涉及不平衡数据集的学习问题,研究的困难主要来自于不平衡数据本身的特点:不平衡数据集中的少数类样本不足,样本的分布并不能很好的反映整个类的实际分布;多数类通常会夹杂噪声数据,使得两类样本往往会出现不同程度的重叠。传统的机器学习领域的分类方法,在直接应用与不平衡数据的分类问题时,容易对少数类的样本错分,使得少数类的分类准确率非常低。并且面对大量的数据传统的批学习算法运算代价太大,计算速度慢,有时甚至无法使用此类算法。
而近些年的研究表明:很多直接优化不平衡分类问题的方法都可以看成某种形式的代价敏感问题。在这个工作中,包含下列不平衡评测指标:f-measure,jaccardcoefficient,a-mean等。近些年的研究表明,这些评测方法都是伪线性的方法,并可以被简化为代价敏感的问题。并且此类问题更是以算法的稀疏度及收敛速率表现作为评判其优劣性的重要指标。而这些工作大都采用基于l2范数,无法保证训练结果的稀疏性,因此在具有大规模特征的医学影像数据集的分类问题上,上述方法并不适用。
技术实现要素:
本发明为避免上述现有技术存在的不足之处,提供一种基于部分平均随机优化模型的医学影像分类方法,以期能提高分类器对大规模,尤其是不平衡医学影像数据集的分类精度及稀疏度,并利用随机学习的特点加快分类速度,从而能快速、有效的实现医学影像分类,达到辅助诊断的作用。
为了达到上述目的,本发明所采用的技术方案为:
本发明一种基于部分平均随机优化模型的医学影像分类方法的特点是按以下步骤进行:
步骤1、采集由n个带有类标签的医学影像构成的图像集并进行去冗余及直方图均衡化处理,得到灰度图像集;
提取所述灰度图像集中每个灰度图像的灰度共生矩阵,再提取所述灰度共生矩阵的特征向量,由n个特征向量分别作为医学影像样本并构成医学影像数据集,记为xi表示第i个医学影像样本,且xi∈rd;rd表示实数的d维空间;yi表示第i个医学影像样本所对应的类标签,且yi∈{+1,-1};当yi=+1,表示第i个医学影像xi为相关样本,当yi=-1,表示第i个医学影像xi为不相关样本;1≤i≤n;
步骤2、基于结构化svm框架,定义如式(1)所示的目标函数:
式(1)中,cpos表示相关样本的代价敏感系数,cneg表示不相关样本的代价敏感系数,并且cpos+cneg=1;r(w)是正则化项;表示所有相关样本,表示所有不相关样本;w为一个d维向量,表示待求解的分类器;l(xi,yi,w)表示损失函数,并有:
步骤3、对式(1)中的损失函数累加和进行求导,得到总梯度g:
式(3)中,n+表示相关样本的总数,n-表示不相关样本的总数,且n++n-=n;xk表示第k个医学影像相关样本;yk表示第k个医学影像相关样本所对应的类标签;xs表示第s个医学影像不相关样本;ys表示第s个医学影像不相关样本所对应的类标签;1≤k≤n+,1≤s≤n-;
步骤4、初始化分类器的相关参数:
定义迭代次数为t,迭代终止次数为t,步长参数为σ;
在1到n之间随机生成矩阵[r1,r2,...,rt,...,rt],rt表示第t个随机数所指向的样本序号;
步骤5、初始化t=1,令
步骤6、利用坐标下降优化算法对所述目标函数进行处理,得到如式(4)所示的第t+1轮的解析解wt+1:
式(4)中,ηt表示第t轮的步长参数,gt为一个d维向量,表示第t轮的梯度,<>表示向量间的内积;bφ(wt+1,wt)表示凸函数的bregman散度,且bφ(wt+1,wt)=||wt+1-wt||2,||||2表示l2范数;p(wt)表示第t轮的解析解wt的范数,并有p(wt)=|w|,||表示l1范数;
由式(4)经过化简得到式(5):
式(5)中,λ是正则化项r(w)的参数;
步骤7、抽取第t轮的第rt个医学影像样本并对所述总梯度g进行无偏估计,得到第t轮的梯度gt:
步骤8、利用ηt=1/σt更新第t轮的步长参数;
步骤9、利用式(7)得到第t+1轮的解析解wt+1的第j个维度值,从而得到第t+1轮的解析解wt+1的d个维度值:
式(7)中,表示第t轮的梯度gt的第j个维度值;1≤j≤d;
步骤10、判断是否成立,若成立,则利用式(8)得到第t+1轮的部分平均参数后执行步骤11,否则,直接执行步骤11;
式(8)中,ρ是为所设定的参照系数,表示第t轮的部分平均参数;
步骤11、判断t<t是否成立,若成立,则将t+1赋值给t,并返回步骤7执行;否则,表示获得第t轮的部分平均参数并利用第t轮的部分平均参数作为最优分类器对其他医学影像数据集进行分类。
与已有技术相比,本发明的有益效果体现在:
1、本发明结合了医学影像分类问题,将医学影像分类这类具有伪线性特征的问题看作代价敏感问题,使用随机优化方法,提高了计算速度,并使用l1正则化构造了代价敏感框架来优化伪线性性能指标,使得对不平衡医学影像数据集的分类结果更加精确。
2、传统医学影像分类方法中,简单在目标函数中添加l1正则化项并不能导致稀疏。因此,本发明使用梯度下降算法作为内部的优化方法,在求解梯度时将正则化项和损失函数分别看待,在步骤7中只对损失函数求导,从而获得有效的稀疏模型比较结果,提高了对医学影像的分类效率。
3、本发明提出一个基于部分平均的方法,传统的平均方法需要保留所有迭代中间值,而本发明方法在内存中只使用了两个变量,在没有增加计算代价的前提下减少了对内存空间的使用,该方法不仅能获得医学影像分类问题最佳的优化速度o(1/t),并且计算速度也很高。
附图说明
图1是本发明的实现流程图;
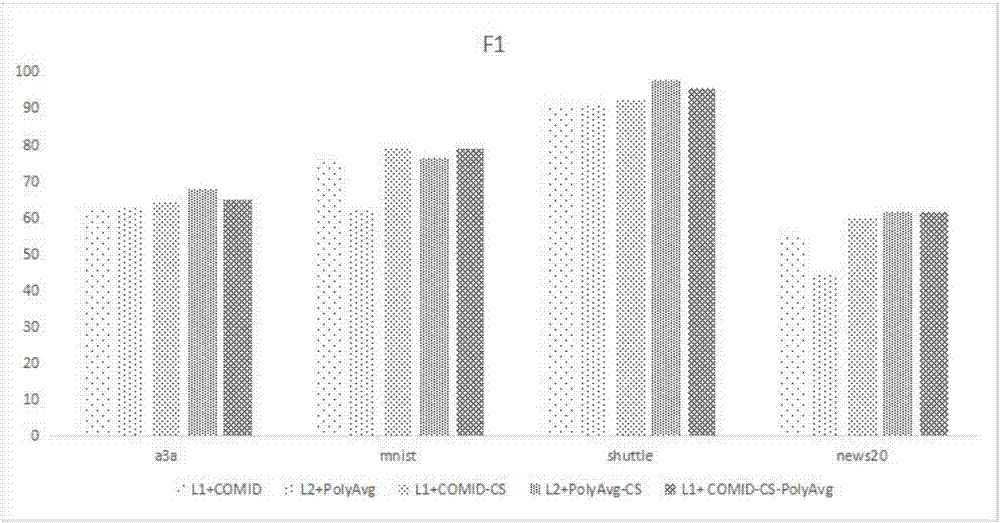
图2是本发明与现有技术在不平衡数据集上得到的以f1为评价指标的对比图。
具体实施方式
本实施例中,如图1所示,一种基于部分平均随机优化模型的医学影像分类方法是按以下步骤进行:
步骤1、采集由n个带有类标签的医学影像构成的图像集并进行去冗余及直方图均衡化处理,得到灰度图像集;
提取所述灰度图像集中每个灰度图像的灰度共生矩阵,再提取所述灰度共生矩阵的特征向量,由n个特征向量分别作为医学影像样本并构成医学影像数据集,记为xi表示第i个医学影像样本,且xi∈rd;rd表示实数的d维空间;yi表示第i个医学影像样本所对应的类标签,且yi∈{+1,-1};当yi=+1,表示第i个医学影像xi为相关样本,当yi=-1,表示第i个医学影像xi为不相关样本;1≤i≤n;
步骤2、基于结构化svm框架,定义如式(1)所示的目标函数:
式(1)中,cpos表示相关样本的代价敏感系数,cneg表示不相关样本的代价敏感系数,并且cpos+cneg=1;r(w)是正则化项;表示所有相关样本,表示所有不相关样本;w为一个d维向量,表示待求解的分类器;l(xi,yi,w)表示损失函数,并有:
步骤3、对式(1)中的损失函数累加和进行求导,得到总梯度g:
式(3)中,n+表示相关样本的总数,n-表示不相关样本的总数,且n++n-=n;xk表示第k个医学影像相关样本;yk表示第k个医学影像相关样本所对应的类标签;xs表示第s个医学影像不相关样本;ys表示第s个医学影像不相关样本所对应的类标签;1≤k≤n+,1≤s≤n-;
步骤4、初始化分类器的相关参数:
定义迭代次数为t,迭代终止次数为t,步长参数为σ;
在每次需要时生成一个随机数,面对数据量极大的情况下调用随机函数产生的开销将变得很大,为了加快计算速度,在算法开始前生成随机矩阵。
在1到n之间随机生成矩阵[r1,r2,…,rt,…,rt],rt表示第t个随机数所指向的样本序号;
步骤5、初始化t=1,令
步骤6、利用坐标下降优化算法对所述目标函数进行处理,得到如式(4)所示的第t+1轮的解析解wt+1:
式(4)中,ηt表示第t轮的步长参数,gt为一个d维向量,表示第t轮的梯度,<>表示向量间的内积;bφ(wt+1,wt)表示凸函数的bregman散度,且bφ(wt+1,wt)=||wt+1-wt||2,||||2表示l2范数;p(wt)表示第t轮的解析解wt的范数,并有p(wt)=|w|,||表示l1范数;
由式(4)经过化简得到式(5):
式(5)中,λ是正则化项r(w)的参数;
步骤7、为了加快计算速度在每次更新时我们只针对随机抽取的样本进行优化,利用该样本更新梯度,这样可以极大的加快计算速度。抽取第t轮的第rt个医学影像样本并对所述总梯度g进行无偏估计,得到第t轮的梯度gt:
步骤8、利用ηt=1/σt更新第t轮的步长参数;
步骤9、式(5)实质上是一个凸优化问题令式(5)变成
设w*是问题的最优解,所以当上式对w求偏导为零可得到最优解,即满足λξ+γ+βw=0时,可以得到解析解。
|w|的次微分可以写成:
当|γ|≤λ时,令w*=0得此时满足偏导为零并且除此之外并无其他解。原因如下:
如果w>0,则ξ=1,这时
λξ+γ+βw=λ+γ+βw>λ+γ≥0
如果w<0,则ξ=-1,这时
λξ+γ+βw=-λ+γ+βw<-λ+γ≤0
所以,对于w≠0的情况,λξ+γ+βw=0均不满足。
当γ>λ>0时,一定有w*>0,则ξ=-1,从而并且除此之外无其他解。
当γ<-λ<0时,此时一定有w*>0,则ξ=1,从而
综上可得式(7)。利用式(7)得到第t+1轮的解析解wt+1的第j个维度值,从而得到第t+1轮的解析解wt+1的d个维度值:
式(7)中,表示第t轮的梯度gt的第j个维度值;1≤j≤d;
步骤10、判断是否成立,若成立,则利用式(8)得到第t+1轮的部分平均参数后执行步骤11,否则,直接执行步骤11;
式(8)中,ρ是为所设定的参照系数,表示第t轮的部分平均参数;与简单的对所有后半部分的迭代结果求平均相比,式(8)在不增加计算代价的情况下,使得在内存中只使用了两个变量,减少了内存开销并且获得了更高的计算速度和精度。
步骤11、判断t<t是否成立,若成立,则将t+1赋值给t,并返回步骤7执行;否则,表示获得第t轮的部分平均参数并利用第t轮的部分平均参数作为最优分类器对其他医学影像数据集进行分类。在
本发明的效果可以通过以下仿真实验进一步说明,大量不平衡医学影像数据集上的实践评估说明了本发明所提出方法的高效性和有效性:
一、实验条件和参数设置
实验在matlab环境下,基于结构化支持向量机svmstruct
表1是实验所采用的大规模、不平衡数据集及其特征;
表1实验数据集的特征
表2是实验中不同算法的f1值和稀疏度比较,表中每一项上面一行数据是稀疏度,下面一行数据是f1;有*标记的结果为最优值。
表2不同算法的f1值和稀疏度比较
二、实验内容与结果分析
表1是实验中使用的4个大规模、不平衡数据集。a3a、mnist、shuttle、news20,其不平衡比例从0.36721到0.05161。本发明和现有主流医学影像分类问题所采用的方法:l1+comid,l2+polyavg,l1+comid-cs和l2+polyavg-cs进行了比较。这些算法都是基于sgd的方法。前两个方法和本发明的工作是最相关的,因为本发明的l1+comid-cs-polyavg方法采用了优化框架,并使用了多项式衰减平均技术。然而,l1+comid和l2+polyavg是针对平衡二分类问题的,为了使实验结果更具可信度,本发明也将这两个算法的代价敏感的版本(l1+comid-cs,l2+polyavg-cs)作为另外两个对比算法。和所有的优化伪线性度量方法一样,本发明使用f-measure作为评估指标,并且对比算法的f1值和稀疏度(最终分类结果中的零权重特征比例)。显然,从表2及图2中可以看出,本发明的算法与其他算法相比拥有更高的精度及稀疏度。这使得其与的分类模型与传统分类方法相比分类的结果更为优越,对疾病诊断的辅助作用也更强。