一种分布式爬虫系统及周期性增量抓取方法与流程
本发明涉及互联网大数据的高效数据采集技术领域,尤其涉及一种分布式爬虫系统及周期性增量抓取方法。
背景技术:
网络爬虫是从一个或若干初始网页的url(uniformresourcelocator,统一资源定位符)开始,获得初始网页上的url,在抓取网页的过程中,根据不同的抓取策略,不断从当前页面上抽取新的url放入任务队列,直到满足系统的停止条件。
随着互联网的高速发展,网络数据呈现爆炸式增长,网络数据源也越来越趋于多元化。面对如此庞大而多元化的互联网数据,如何提高网络爬虫的抓取效率,如何针对不同的数据源进行可定制化的爬取策略,显得至关重要。
相比于传统单机爬虫,分布式爬虫可以明显提高爬虫的抓取效率,但随之也引入了新的问题:分布式环境下多节点的任务下发问题、负载均衡问题、网页重复性问题和周期性增量抓取问题等。
综上所述,如何在解决分布式爬虫带来的一系列问题的同时,能够有效地提高爬虫的抓取速度,并在此基础上实现分布式爬虫的周期性增量抓取是目前现有技术中存在的主要问题。
技术实现要素:
本发明所要解决的技术问题是,提供一种分布式爬虫系统及周期性增量抓取方法,解决如何将单机爬虫有效的结合在一起,实现集群环境下高可用、高稳定和高吞吐率的分布式爬虫,并实现周期性增量抓取。本发明解决上述问题所采用的技术方案是:
本发明公开一种分布式爬虫系统,该系统被配置为基于zookeeper的分布式服务、系统组件和数据库三大部分,其中,系统组件包括系统监控组件monitor、协调组件coordinator、日志收集组件logger、基础爬虫组件spider,数据库包括redis内存数据库,redis是key-value的存储形式,redis内存数据库中存放有分布式url任务队列和分布式bloomfilter;其中,基于zookeeper的分布式服务为各系统组件提供分布式协调服务;所述系统监控组件monitor负责系统的动态配置和系统的状态监控;所述协调组件coordinator负责将种子url导入到基于redis的分布式任务队列、周期性汇总各节点状态到zookeeper、为日志收集组件logger动态分配日志源和集群节点的检测与管理中的一种或多种;所述日志收集组件logger负责从集群中各基础爬虫组件spider收集日志数据;所述基础爬虫组件spider负责处理网页的爬取任务;所述基于redis的分布式url任务队列负责存储所有待爬取的任务url;所述基于redis的分布式bloomfilter负责集群中所有基础爬虫组件spider的url去重请求。
进一步的,基于zookeeper的分布式服务通过与各系统组件相互协调工作,为各系统组件提供包括动态配置、集群节点检测与管理、master选举、分布式锁、全局url的id生成的分布式服务中的一种或多种。
进一步的,系统监控组件monitor具有monitor界面,用户可以通过monitor界面修改存在于zookeeper上的系统配置参数,集群中的协调组件coordinator、日志收集组件logger和基础爬虫组件spider会监听zookeeper上的相应数据节点,并在数据节点内容被修改后得到相应的通知,进而根据修改后的配置参数做相应调整。
进一步的,monitor界面还能实时显示存在于zookeeper上的各系统状态参数和各组件状态参数。
进一步的,基础爬虫组件spider组件具有多种组件内核,且各组件内核的爬取策略不完全一致。
进一步的,基础爬虫组件spider组件具有高扩展性,以方便针对新的数据源编写新的组件内核。
进一步的,分布式url任务队列的任务分发方式采用基础爬虫组件spider的拉取(pull)方式。
进一步的,分布式bloomfilter采用分段机制将bit向量分段存储在redis不同的key之上,并通过分段乐观锁实现各基础爬虫组件spider访问的同步性控制。
本发明还公开一种基于上述分布式爬虫系统的周期性增量抓取方法,包括:协调组件coordinator周期性导入任务到分布式url任务队列,并唤醒正在休眠的spider组件;spider组件根据当前分布式url任务队列的执行情况进行休眠或周期性增量抓取,在没有抓取任务时,spider组件就会进入休眠状态,休眠的spider组件会被其他spider组件或coordinator组件唤醒时会继续进行抓取任务。
进一步的,该方法包括如下步骤:
s1、协调组件coordinator周期性导入任务到分布式url任务队列,并唤醒正在休眠的spider组件。即,系统的coordinator组件会周期性导入任务到分布式url队列,任务导入后,coordinator会唤醒所有在休眠的spider组件开始新一轮的增量抓取任务。执行抓取任务是周期性一直进行的,每一个周期都是从导入种子任务开始。
s2、spider组件判断是否结束系统周期性增量抓取,若为是,执行s6,否则,执行s3。即,spider组件中的抓取线程会检查zookeeper中相应的数据节点信息,该数据节点信息由monitor来设置,当读取到结束系统周期性增量抓取时,spider组件会进行一系列清理保存工作后结束自己的进程;否则,会继续进行周期性增量抓取。
s3、判断当前分布式任务队列是否为空,若为是,执行s4,否则,跳转s5。即,spider组件中的抓取线程会检查redis中分布式任务队列中是否还有待抓取的任务,若有,则会获取任务并进入抓取阶段;否则,会进入休眠阶段。
s4、进入基础爬虫组件spider休眠阶段,主要包括:1)阻塞抓取线程或休眠基础爬虫组件(spider)组件,2)唤醒线程;
具体包括如下步骤:a)判断当前spider组件除当前抓取线程外,其它抓取线程是否均已阻塞,若是,则执行步骤b),否则,执行步骤c);b)在zookeeper中创建休眠标示节点,该节点可以用来表示当前spider组件已经休眠,当其他组件需要唤醒该spider组件时只需删除该数据节点即可;c)阻塞该抓取线程;d)抓取线程已经阻塞,等待其他线程唤醒;e)抓取线程被其它线程唤醒,并执行s2。
在没有抓取任务时,spider组件就会进入该阶段,休眠自己,避免系统资源的空耗,当其他spider组件有新的任务添加到任务队列或新的一轮增量抓取开始时,休眠的spider组件会被其他spider组件或coordinator组件唤醒,继续进行抓取任务。
s5、进入基础爬虫组件(spider)抓取阶段,具体包括如下步骤:包括:1)从分布式url任务队列获取任务,2)spider执行抓取任务;3)唤醒抓取线程或基础爬虫组件(spider)组件。
具体包括如下步骤:a)从分布式url队列获取抓取任务;b)根据获取的任务,抓取相应网页并存储结果;c)分析抓取到的网页超链接并获取新的任务集合;d)将获取到的新任务发送到分布式bloomfilter去重;e)将去重后的新任务添加到分布式任务队列;f)判断当前spider组件是否有抓取线程阻塞,若有,则执行步骤g),否则,执行步骤h);g)唤醒当前spider组件中阻塞的抓取线程;h)判断当前集群中是否有其他的spider组件休眠,若有,则唤醒相应休眠spider,否则,执行s2。
s6、结束。即当各组件检测到系统需要停止工作时,会在进行必要的清理工作后结束各自的进程。
针对庞大而多元化的互联网数据,本发明的一种分布式爬虫系统及周期性增量抓取方法和现有技术相比,具有以下有益效果:
1)实现简单:本发明基于开源的分布式协调服务zookeeper和开源的分布式内存数据库redis构建分布式爬虫系统,在利用技术框架基础上进行深度开发,既满足了特定需求,又降低了开发成本。
2)高性能:抓取任务采用多节点多线程工作方式,实现了网页抓取的高性能,并支持spider组件的线性扩展。
3)高可用:基于zookeeper和redis,系统各个组件均以集群形式工作,避免了单节点崩溃问题,对外实现了一种高可用高稳定的网页抓取服务。
4)自动化周期性增量抓取:一次性设定初始任务和相关系统参数后,系统会自动进行周期性地增量抓取服务,不需人为干预。
5)可定制抓取策略:spider组件包含多种组件内核,每一个组件内核对应不同的爬取策略,并且spider被设计成一种高扩展的组件,可以很方便地针对新的数据源编写新的组件内核。
6)扩展性好:系统所有组件均以低耦合组织在一起,任何单一节点的上下线对系统造成的影响微乎其微,支持各组件的线性扩展。
由此可见,本发明具有设计合理、架构简单、高可用、高稳定、高性能、扩展性好等优势。
附图说明
图1为该分布式爬虫系统架构图
图2为周期性增量抓取方法主流程图
图3为spider抓取阶段流程图
图4为spider休眠阶段流程图
具体实施方式
为了更好的了解本发明的技术内容,特举具体实施例并配合所附图示作进一步说明。
图1为本发明的一种分布式爬虫系统架构图,该系统包括基于zookeeper的分布式服务、系统组件和数据库三大部分。其中,基于zookeeper的分布式服务为各系统组件提供分布式协调服务;系统组件包括系统监控组件monitor、协调组件coordinator、日志收集组件logger、基础爬虫组件spider;数据库包括redis内存数据库和其他存储抓取网页的数据库,redis内存数据库中存放有分布式url任务队列和分布式bloomfilter。
基于zookeeper的分布式服务通过与各系统组件相互协调工作,为各系统组件提供包括动态配置、集群节点检测与管理、master选举、分布式锁、全局url的id生成等分布式协调服务。zookeeper在内存中维护了一个类似文件系统的树形数据结构,基于zookeeper的这些分布式服务可以通过创建、查询、删除和监听各组件在zookeeper数据结构上的相应数据节点来实现。
系统监控组件monitor负责系统的动态配置和系统的状态监控。用户可以通过monitor界面修改存在于zookeeper上的系统配置参数(如各基础爬虫组件spider的参数),集群中各个相应组件(包括spider、coordinator和logger)会监听zookeeper上的相应数据节点,并在在数据节点内容被修改后各个相应组件会得到相应的通知,即由zookeeper发送的数据变更的通知,进而各组件会根据修改后的配置参数做相应调整。monitor界面还会实时显示存在于zookeeper上的各系统状态参数和各组件状态参数,以便用户进行实时监控,及时发现问题并进行相应的补救措施。其中,系统配置参数主要包括种子导入周期、正则约束、抓取线程数、抓取深度、最大错误数等等,还有许多其他很细节的配置参数。
协调组件coordinator负责导入种子网页url到基于分布式任务队列、周期性汇总各节点状态到zookeeper、为日志收集组件logger动态分配日志源和集群节点的检测与管理。
日志收集组件logger负责从集群中各基础爬虫组件spider收集日志数据,以便后续日志分析。
基础爬虫组件spider负责具体的网页爬取任务,spider组件包含多种组件内核,每一个组件内核对应不同的爬取策略,并且spider被设计成一种高扩展的组件,可以很方便地针对新的数据源编写新的组件内核。在爬取过程中,spider组件首先根据系统配置进行相应初始化,之后会不断从分布式任务队列中请求url、根据相应url切换相应爬取策略、爬取网页、提取网页特征及正文、存储抽取结果、分析网页超链接、将新获取url经分布式bloomfilter去重后添加到分布式任务队列中,直到分布式任务队列为空。
基于redis的分布式url任务队列负责存储所有待爬取的任务url。任务的分发方式采用基础爬虫组件spider的拉取(pull)方式,当spider当前的爬取任务结束时,spider会主动到分布式队列中拉取新的任务,进行下一轮的工作。值得注意的是,在当前采用基于redis的分布式队列的情况下,拉取(pull)方式是最优最简单的一种方式,其他还有推送和推拉结合的方式也可以实现,但这两种方式都需要做额外的实现,而拉取方式不需要额外的实现。
基于redis的分布式bloomfilter负责集群中所有基础爬虫组件spider的url去重请求。redis是key-value的存储形式,该分布式bloomfilter采用分段机制将bit向量分段存储在redis不同的key之上,并通过分段乐观锁实现各spider访问的同步性控制。分段乐观锁的实现机制为:每一个spider的去重请求会首先计算所要访问的bit向量的各段对应的key,之后会在在各个key(键)之上进行监听,然后发起各段bit向量更新请求的redis事务,该事务在执行时会首先检查所监听的key对应的bit向量是否在监听后被更改过,若是则放弃自此事务执行并自旋重新发起去重请求;否则,更新成功,去重url被成功添加到bloomfilter中。基于分段机制和乐观锁实现的分布式bloomfilter不仅可以提供高吞吐率的去重请求,而且可以随着redis集群的线性扩展而扩展,不存在容量限制。
实施例中还公开一种基于上述分布式爬虫系统的周期性增量抓取方法,结合附图2至图4对该方法进行详细说明。
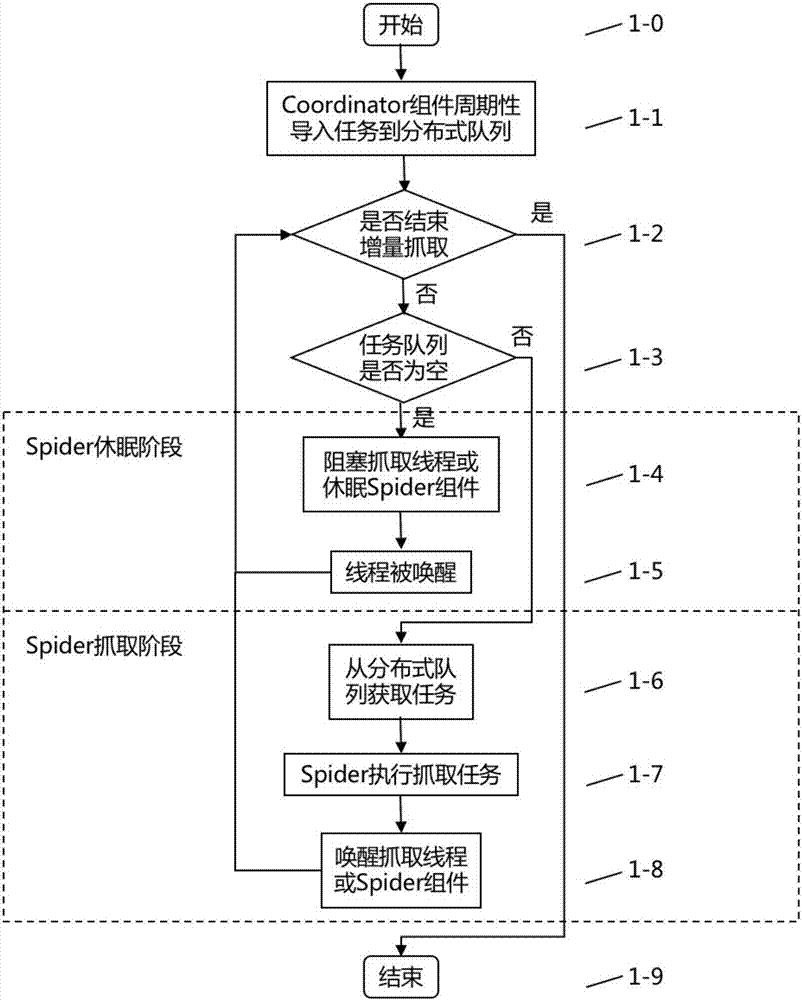
图2为实施例中周期性增量抓取方法的主流程图,具体介绍如下:
步骤1-0、周期性增量抓取方法的起始状态;
步骤1-1、协调组件coordinator周期性导入任务到分布式url任务队列;
步骤1-2、判断是否结束系统周期性增量抓取:若步骤1-2判断结果为是,则进入步骤1-9,否则执行步骤1-3;
步骤1-3、判断当前分布式任务队列是否为空;若判断结果为是,则进入spider休眠阶段,执行相应步骤1-4和步骤1-5,否则,进入spider抓取阶段,执行相应步骤1-6、步骤1-7和步骤1-8。
步骤1-4、阻塞抓取线程或休眠spider组件;
步骤1-5、阻塞线程被唤醒,并执行步骤1-2;
步骤1-6、从分布式队列获取任务;
步骤1-7、spider执行具体的抓取任务;
步骤1-8、唤醒抓取线程或spider组件,并执行步骤1-2;
步骤1-9、结束状态。
图3为实施例中spider抓取阶段流程图,具体介绍如下:
步骤2-0、spider抓取阶段开始状态,该步骤紧接步骤1-3;
步骤2-1、从分布式队列获取任务;
步骤2-2、根据获取的任务,抓取相应网页并存储结果;
步骤2-3、分析抓取到的网页超链接并获取新的任务集合;
步骤2-4、将获取到的新任务到分布式bloomfilter去重;
步骤2-5、将去重后的新任务添加到分布式任务队列;
步骤2-6、判断本spider组件是否有抓取线程阻塞,若有,则执行步骤2-7,否则,执行步骤2-8;
步骤2-7、唤醒阻塞的本spider组件的抓取线程;
步骤2-8、判断当前集群中是否有其他的spider组件休眠,若有,则执行步骤2-9,否则,执行2-10;
步骤2-9、唤醒休眠spider;
步骤2-10、spider抓取阶段的结束状态,之后会执行步骤1-2。
图4为实施例中spider休眠阶段流程图,具体介绍如下:
步骤3-0、spider休眠阶段开始状态,该步骤紧接步骤1-3;
步骤3-1、判断本spider组件除抓取线程外,其它抓取线程是否均已阻塞,若是,则执行步骤3-2,否则,执行步骤3-3;
步骤3-2、在zookeeper中创建休眠标示节点,该节点可以用来表示相应spider组件已经休眠,当其他组件需要唤醒该spider组件时只需删除该数据节点即可;
步骤3-3、阻塞本抓取线程;
步骤3-4、抓取线程已经阻塞,等待其他线程唤醒;
步骤3-5、抓取线程被其它线程唤醒;
步骤3-6、spider休眠阶段的结束状态,之后会执行步骤1-2。
尽管以上结合附图对本发明的实施方案进行了描述,但本发明并不局限于上述的具体实施方案和应用领域,上述的具体实施方案仅仅是示意性的、指导性的,而不是限制性的。本领域的普通技术人员在本说明书的启示下,在不脱离本发明权利要求所保护的范围的情况下,还可以做出很多种的形式,这些均属于本发明保护之列。
- 还没有人留言评论。精彩留言会获得点赞!