特征选择和标记相关性联合学习的多标记数据分类方法与流程
本发明涉及机器学习和模式识别技术领域,特别是一种基于特征选择和标记相关性联合学习的多标记数据分类方法。
背景技术:
在真实世界中,用一个标记难以确切地描述一些复杂的对象,学习对象可能与多个标记有关,如,在文本分类中,一则关于上海踩踏事件的新闻报道可能同时包含“上海”、“外滩”、“陈毅广场”、“踩踏事件”和“跨年夜活动”等多个概念类别标记;在图像分类中,一幅关于校园的图像可能同时与“草地”、“操场”、“建筑物”、“蓝天”和“白云”等多个语义概念标记有关。可见,同时具有多个标记的对象无处不在,而传统的监督学习方法难以很好地处理同时包含多个语义概念的对象,致使多标记学习成为机器学习、模式识别等领域中一个重要的研究热点。同时,在许多情况下,获得一个样本所属的完全标记是比较困难的,相反,获得部分标记却相对来说更容易些,即有部分标记缺失。在缺失标记的情况下,由于有些标记信息是缺失的,故难以通过计算标记的共现性或构建基于标记的邻接图来事先获得标记之间的标记性,也事先难以准确的给出先验知识来刻画标记之间的相关性。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的不足,而提供一种基于特征选择和标记相关性联合学习的多标记数据分类方法,以此来有效地提高多标记数据的分类精度。
本发明为解决上述技术问题采用以下技术方案:
根据本发明提出的一种基于特征选择和标记相关性联合学习的多标记数据分类方法,包括以下步骤:
步骤1、初始化标记相关性矩阵,对多标记数据的各个特征做归一化处理;
步骤2、运用特征选择和标记相关性联合学习算法学习得到标记相关性矩阵和分类器参数:交替迭代更新标记相关性矩阵和分类器参数,直到满足迭代终止条件输出学习得到的标记相关性矩阵和分类器参数;具体如下:
首先给出基于特征选择和标记相关性联合学习算法jlfllc的模型如下所示:
s.t.sq,q=1,q=1,...,q
其中,xi表示第i个样本,xi∈rd,q表示标记个数,rd为d维特征空间,d为特征个数,yiq=+1表示第i个样本隶属于第q个标记,yiq=-1表示第i个样本不隶属于第q个标记,yiq=0表示第i个样本关于第q个标记的信息是缺失的,b表示偏差向量,b=[b1,...,bq]∈r1×q,bq为第q个偏差项,r1×q为1×q维的实数空间,sq=[sq,1,...,sq,q-1,1,sq,q+1,...,sq,q]t∈rq,rq为q维的实数空间,sq,m为第q个标记与第m个标记的相关性大小,1≤m≤q、m为整数且m≠q,t为转置,w为权重矩阵,α和β为正则化参数,λ为惩罚参数;
固定s,更新w和b,分类器参数包括w和b;将jlfllc的模型的优化问题转化为如下等价的约束光滑凸优化问题,定义函数g(u,w)如下:
其中,u=[u1,...,ud]t,
采用基于nesterov的加速梯度求解方法来求解问题(1),从而得到分类器参数;
固定w和b,更新s;w和b固定时,将jlfllc的模型的优化问题退化为如下问题:
s.t.sq,q=1,q=1,...,q
进一步,上式进一步分解成q个独立的子优化问题,其中,第q个子优化问题表示为:
s.t.sq,q=1
该问题是个光滑的凸优化问题,利用最优化方法直接求解得到s;
步骤3、运用学习得到的标记相关性矩阵和分类器参数进行标记预测,得到分类结果;根据该分类结果获得多标记数据的分类模型,并根据该多标记数据的分类模型预测所有待分类的多标记数据的标记,输出多标记数据的分类结果。
作为本发明所述的一种基于特征选择和标记相关性联合学习的多标记数据分类方法进一步优化方案,步骤1中初始化标记相关性矩阵,即假设初始化时同一标记之间是相关的,而不同标记之间不相关。
作为本发明所述的一种基于特征选择和标记相关性联合学习的多标记数据分类方法进一步优化方案,初始化标记相关性矩阵为单位矩阵,归一化处理是使每个特征对应的特征向量的2范数为1。
作为本发明所述的一种基于特征选择和标记相关性联合学习的多标记数据分类方法进一步优化方案,所述步骤2具体如下:
首先给出基于特征选择和标记相关性联合学习算法的模型如下所示:
s.t.sq,q=1,q=1,...,q
其中,xi表示第i个训练集样本,xi∈rd,q表示标记个数,rd为d维特征空间,d为特征个数,yiq=+1表示第i个样本隶属于第q个标记,yiq=-1表示第i个样本不隶属于第q个标记,yiq=0表示第i个样本关于第q个标记的信息是缺失的,b表示偏差向量,b=[b1,...,bq]∈r1×q,bq为第q个偏差项,r1×q为1×q维的实数空间,sq=[sq,1,...,sq,q-1,1,sq,q+1,...,sq,q]t∈rq,rq为q维的实数空间,sq,m为第q个标记与第m个标记的相关性大小,1≤m≤q、m为整数且m≠q,t为转置,w为权重矩阵,α和β为正则化参数,λ为惩罚参数;
固定s,更新w和b,分类器参数包括w和b;
当标记相关矩阵s已知时,上式的模型的优化问题退化为:
该式为一个非光滑的凸问题,设数据矩阵x和标记矩阵y已经中心化,此时所有的偏差项{bq}为0,该式改写为:
其中,η为折中因子,
其中,u=[u1,...,ud]t,
采用基于nesterov的加速梯度求解方法来求解对问题(1),具体步骤如下:
a、初始化:设初始化步长γ0>0,初始解(u0,w0),设置最大迭代次数;
b、令(u1,w1)=(u0,w0),初始迭代步数t=1,β-1=0以及β0=1;
c、执行以下步骤,直到满足停止准则,停止准则为收敛或迭代次数t达到最大迭代次数;
(3.1)令
(3.2)(vt,zt)=(ut+αt(ut-ut-1),wt+αt(wt-wt-1)),其中,ut、wt、vt、zt分别是第t次迭代的参数,αt为连接系数;
(3.3)循环执行步骤3.3.1-3.3.2,直到
(3.3.1)
(3.3.2)
(3.4)
(3.5)若满足停止准则,则(u,w)=(ut,wt);
其中,γt表示第t次迭代步长,πω(v,z)表示(v,z)到凸集ω上的欧式投影,其定义为:
固定w和b,更新s;
w和b固定时,优化问题退化为如下问题:
s.t.sq,q=1,q=1,...,q
进一步,上式进一步分解成q个独立的子优化问题,其中,第q个子优化问题表示为:
s.t.sq,q=1
该问题是个光滑的凸优化问题,利用最优化方法直接求解得到s。
作为本发明所述的一种基于特征选择和标记相关性联合学习的多标记数据分类方法进一步优化方案,采用nesterov方法求解优化问题(1)的时间复杂度为
作为本发明所述的一种基于特征选择和标记相关性联合学习的多标记数据分类方法进一步优化方案,步骤3中所述得到分类结果是指计算出未知样本xu的预测值
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
(1)设计了将多标记数据的标记相关性和特征选择策略融合,构建联合的多标记数据分类学习模型;对构建的非光滑凸函数采用基于nesterov的加速梯度求解方法进行有效求解;融合标记相关性和特征选择策略的学习模型可有效获得标记相关矩阵和分类器参数,进而可有效提高多标记数据的分类效果,本发明可直接用于多标记数据的分类;
(2)本发明能够通过嵌入标记相关性和特征选择策略可得到标记相关性矩阵和更有判别能力的分类器,以此来提高多标数据的分类精度,此外,本发明中通过挖掘标记之间的相关性,进而估计出缺失标记,适用于标记缺失情况下的多标记数据的分类,因此具有较高的使用价值;针对缺失标记的情况,通过学习来获得高阶非对称的标记相关性,并且同时学习分类模型以及对特征空间进行降维,可有效改进有标记缺失情况下的多标记数据分类精度。
附图说明
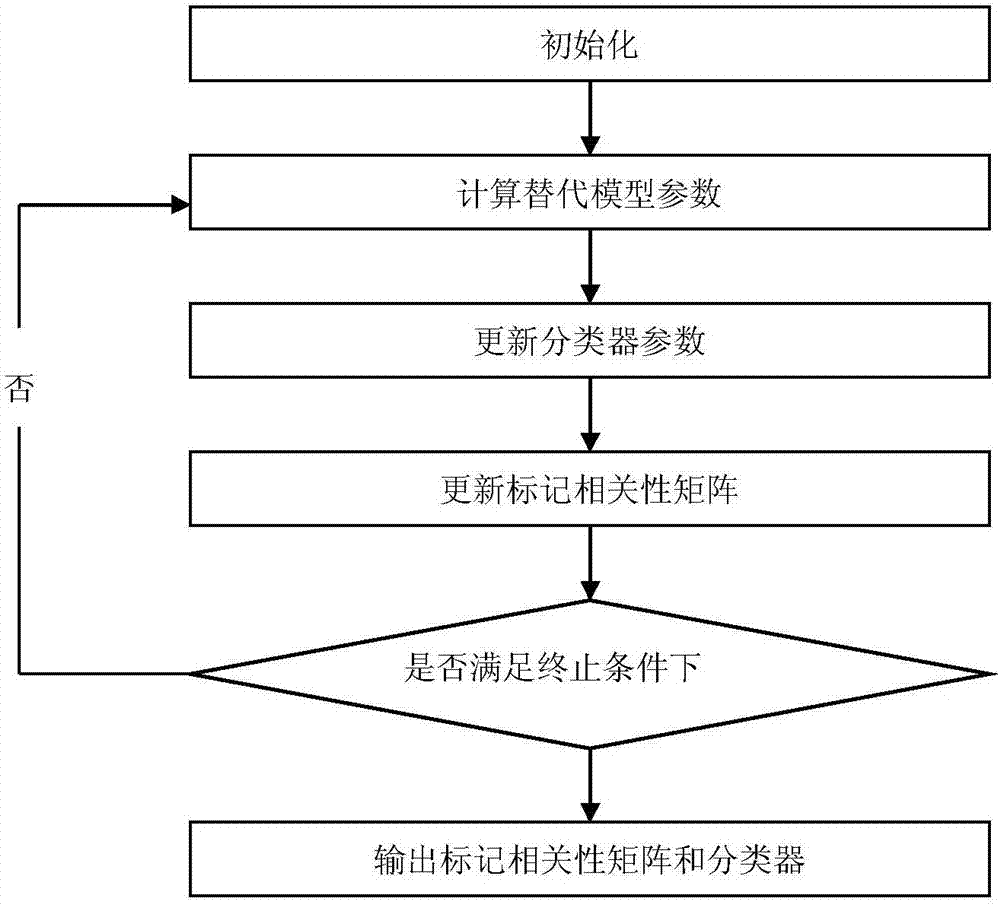
图1是本发明流程图。
图2是本发明中运用jlfllc学习得到标记相关性矩阵和分类器步骤子流程图。
图3是本发明中分类步骤子流程图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
如图1所示,本发明公开了本发明公开了基于特征选择和标记相关性联合学习的多标记数据分类算法,包含如下步骤:
步骤1,标记相关性矩阵初始化为单位矩阵,即假设初始化时同一标记之间是相关的,而不同标记之间不相关,不同标记之间的相关性通过步骤2的学习得到;
步骤2,运用特征选择和标记相关性联合学习算法jlfllc学习得到标记相关性矩阵和分类器参数:交替迭代更新标记相关性矩阵和分类器参数,直到满足迭代终止条件输出学习得到的标记相关性矩阵和分类器参数;
步骤3,模型预测:运用学习得到的标记相关性矩阵和分类器参数进行标记预测,得到分类结果;根据多标记数据的分类模型预测所有待分类的多标记数据的标记;输出多标记数据的分类结果。
需要说明的是本发明的核心步骤是运用jlfllc学习得到标记相关性矩阵和分类器,并给出各步骤的具体实施方法。
如图2所示,标记相关性矩阵初始化及特征并归一化处理的具体实施步骤如下:
步骤4,标记相关性矩阵s=iq,其中,iq为单位矩阵;步骤5,归一化处理,使每个特征对应的特征向量的2范数为1。
如图2所示,运用jlfllc学习得到标记相关性矩阵和分类器具体实施步骤如下:
对有缺失标记情况的多标记数据分类,挖掘标记之间的相关性才能有效克服标记缺失的情况。提出的模型同时考虑多标记分类,标记相关性以及特征选择,这样可以联合学习分类模型参数,标记相关性矩阵,并且可以进行特征选择。同时,为了考虑标记之间的相关性,构建了一个条件依赖网络,将输入向量和其他标记变量作为每个节点的父亲节点,然而其他标记变量不是一个固定的值,而是一个变量。此外,通过引入权重矩阵的l2,1范数选择多个两类分类任务之间共享的稀疏特征结构。由此,构建了一个联合学习模型,包括一个损失项(考虑缺失标记),两个正则化项:分别控制模型复杂度和标记相关性大小,以及权重矩阵的l2,1范数
综上可见,提出的模型具有以下特点:(1)提出了一个新的多标记分类算法,同时考虑了标记之间的相关性,缺失标记问题以及特征选择;(2)标记之间的相关性不是事先计算得到,而是通过学习得到,而且标记之间的相关性可以是负的,非对称的;(3)提出的模型不仅可以处理缺失标记的多标记数据集,也可以处理完全标记的多标记数据集。
先给出一些符号说明:
假设
其中,wq∈rd和bq∈r分别表示第q个预测函数所对应的权重向量和偏差,
其中,sq=[sq,1,...,sq,q-1,1,sq,q+1,...,sq,q]t∈rq,权重矩阵w=[w1,...,wq]∈rd×q,偏差向量b=[b1,...,bq]∈r1×q。为了便于表示,令标记相关矩阵s=[s1,...,sq]∈rq×q。
首先给出jlfllc的模型如下:
s.t.sq,q=1,q=1,...,q
式中:第一项为损失项,当且仅当样本所对应的标记为已知标记时才发生,第二项控制模型的复杂度,第三项用来控制标记相关性的大小,a和β为正则化参数,用来平衡这三项,约束项用来约束标记自身的相关性为1。yiq=+1表示第i个样本隶属于第q个标记,yiq=-1表示第i个样本不隶属于第q个标记,yiq=0表示第i个样本关于第q个标记的信息是缺失的。b表示偏差向量,b=[b1,...,bq]∈r1×q,bq为第q个偏差项,r1×q为1×q维的实数空间,sq=[sq,1,...,sq,q-1,1,sq,q+1,...,sq,q]t∈rq,rq为q维的实数空间,sq,m为第q个标记与第m个标记的相关性大小,1≤m≤q、m为整数且m≠q,t为转置,w为权重矩阵,α和β为正则化参数,λ为惩罚参数;
上述问题可以分解为2个子问题进行求解,固定s,更新w和b;固定w和b,更新s,jlfllc的具体求解方法如下:
步骤5,固定s,更新w和b;改写模型,计算替代模型的优化参数:
固定s,更新w和b。当标记相关矩阵s已知时,模型中的第三项为常量,可以忽略,
同时约束项也可以忽略,因此模型的优化问题可退化为:
上式为一个非光滑的凸问题,直接求解困难。为了方便讨论,假设数据矩阵x和标记矩阵y已经中心化,此时所有的偏差项{bq}为0。上式可改写为:
其中,
其中,u=[u1,...,ud]t,
对问题(1),采用基于nesterov(y.nesterov,i.u.enesterov,introductorylecturesonconvexoptimization:abasiccourse,kluweracademicpublishers,holland,2004.)的加速梯度求解方法来求解,主要步骤如下:
(1)初始化:设γ0>0表示初始化步长,初始解(u0,w0),最大迭代次数为max_iter;
(2)令(u1,w1)=(u0,w0),t=1,β-1=0以及β0=1;
(3)反复执行以下步骤,直到收敛或迭代步数t为max_iter
(3.1)令
(3.2)(vt,zt)=(ut+αt(ut-ut-1),wt+αt(wt-wt-1)),其中ut、wt、vt、zt分别是第t次迭代的参数,αt为连接系数。
(3.3)循环执行下列步骤直到
(3.3.1)
(3.3.2)
(3.4)
(3.5)若满足停止准则,则(u,w)=(ut,wt),转(4)。
(4)结束.
其中,(3.3.2)中的γt表示第t次迭代步长,πω(v,z)表示(v,z)到凸集ω上的欧式投影,其定义为:
步骤6,由改写模型的解决得到原模型的解,即得到原模型中分类器参数。
步骤7,固定w和b,更新s:
w和b固定时,模型中的第四项为常数项,故可以忽略。因此,优化问题退化为如下问题:
s.t.sq,q=1,q=1,...,q
进一步,上式可以进一步分解成q个独立的子优化问题,其中第q个子优化问题表示为:
s.t.sq,q=1
该问题是个光滑的凸优化问题,利用最优化方法可直接求解得到s。
步骤8,若不满足终止条件,则转步骤5;否则转步骤9;
步骤9,得到标记相关性矩阵和分类器。
如图3所示,模型预测具体实施步骤如下:
步骤10,对未标记样本进行归一化处理;
步骤11,计算未知样本xu的预测值
步骤12,计算未知样本xu的类别标记向量h(xu)=sgn(f1(xu),...,fq(xu))。
步骤13,输出每个样本对应的标记集。
对所有待分类的多标记数据按上述方法进行分类,得到最终的多标记数据的分类结果。
以上对本发明所提供的基于特征选择和标记相关性联合学习的多标记数据分类方法进行了详细介绍。值得注意的是,具体实现该技术方案的方法和途径有很多,以上所述仅是本发明的优选实施方式,只用于帮助理解本发明的方法及核心思想;同时,对于本领域的一般技术人员,在本发明核心思想的基础上,做出的修改和调整都将视为本发明的保护范围。综上所述,本说明书内容不应理解为对本发明的限制,本发明的保护范围应由所附的权利要求来限定。
- 还没有人留言评论。精彩留言会获得点赞!