一种可保持titan实时数据一致性的高效并行加载方法与流程
本发明属于大数据处理领域,涉及一种高效安全的图数据库实时数据预处理加载方法,具体是一种可保持titan实时数据一致性的高效并行加载方法。
背景技术:
随着计算机技术的不断发展和信息化程度的不断提高,数据量在迅速增长,数据结构也在逐渐复杂化,传统的关系型数据库在很多场景下难以使用,因此诞生了各种非关系型数据库。
图数据库是非关系型数据库中的一种,擅长存储各种关系网络数据,在众多图数据库中,titan作为非常优秀好用的分布式图数据库,具有极高的可扩展性,通过扩大集群大小线性地提高图存储的上限,同时可支持超级大的图的存储检索;因此应用在很多场景下;但是在加载处理实时数据时,为了保证数据的一致性,titan只能进行单线程加载,实时数据加载的效率低下,具有很大局限性,不能满足大流量实时数据的加载需求。
技术实现要素:
针对现有技术中,图数据库titan在处理大流量实时数据时低效不安全性的问题,本发明提供了一种可保持titan实时数据一致性的高校并行加载方法。
具体步骤如下:
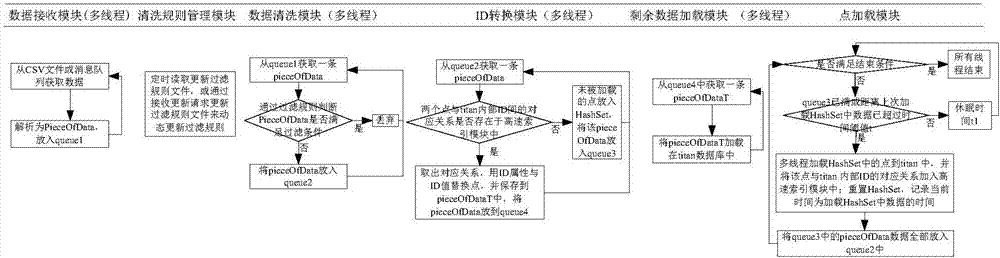
步骤一、将图数据库titan划分为7个模块,且7个模块并行操作;
7个模块包括:数据接收模块,清洗规则管理模块,数据清洗模块,id转换模块,高速索引模块,点加载模块和剩余数据加载模块;
数据接收模块负责接收需要被处理的数据,并放入有界队列中;
清洗规则管理模块通过监控规则文件实现过滤规则的动态更新;
数据清洗模块按清洗规则管理模块给定的规则过滤有界队列中不需要的数据;
id转换模块将清洗后的数据中的点替换为图数据库中对应点的id。
高速索引模块负责加速id的转化速度。
点加载模块,负责加载id转换时不存在于图数据库内的点;并在加载完成后将点及其id对应关系添加进高速索引模块。
剩余数据加载模块,通过并行加载大幅提升图数据的加载速度。
步骤二、数据接收模块的多线程同时并行工作,每个线程循环从消息队列或csv文件或消息队列等数据源获取数据,解析成多条pieceofdata数据,放入有界队列queue1中。
pieceofdata数据由两个点,两个点之间的关系,以及点与关系上的属性构成;
有界队列queue1用于存放从数据源获取的数据;
步骤三、清洗规则管理模块定时读取规则配置文件,或接受客户端请求读取规则配置文件,实时动态更新过滤规则;
步骤四、数据清洗模块多线程并行工作,每个线程循环依次从有界队列queue1获取一条pieceofdata数据,使用清洗规则进行判断,如果符合过滤条件,直接丢弃,否则,放入有界队列queue2。
queue2用于存放有界队列queue1中过滤之后的数据;
步骤五、id转换模块多线程并行工作,每个线程循环从有界队列queue2中取出清洗过滤之后的pieceofdata数据进行处理;
具体步骤为:
步骤501、判断当前pieceofdata数据中的两个点与titan内部id之间的对应关系是否都存在于高速索引模块中;如果是,进入步骤502,否则,进入步骤503;
步骤502、id转换模块从高速索引模块中取出对应关系,用id属性与id值替换对应的pieceofdata数据中的点,并保存到pieceofdatat数据中,将pieceofdatat数据放入到有界队列queue4;
pieceofdatat数据中保存的是pieceofdata数据中的点被对应的id属性与id值替换之后的pieceofdata;
queue4用于存放pieceofdatat数据;
步骤503、当前pieceofdata数据中至少一个点与titan内部id之间的对应关系未被加载到高速索引模块中,id转换模块将未被加载的点放入hashset中,并将该pieceofdata数据放入有界队列queue3中;
queue3用于存放从有界队列queue2中选出的pieceofdata数据,该pieceofdata数据中至少一个点与titan内部id之间的对应关系未被加载到高速索引模块中。
步骤六、剩余数据加载模块的多线程同时并行工作,每个线程循环从有界队列queue4中获取pieceofdatat数据,并加载在titan数据库中;
步骤七、点加载模块与高速索引模块交互,当满足结束条件后,结束所有线程;
具体步骤如下:
步骤701、判断是否满足结束条件,如果是,所有线程结束;否则,进入步骤702;
步骤702、判断有界队列queue3是否已满距离上次加载hashset中数据已经超过时间阈值t,如果是,执行步骤703,否则,休眠时间t1;返回步骤701继续;
阈值t是系统初始化参试,根据实际情况设定;
步骤703、点加载模块的每个线程加载hashset中的点,并将该点与titan内部id之间的对应关系加入高速索引模块中;
步骤704、点加载模块对hashset进行重置,记录当前时间为加载hashset中数据的时间;
步骤705、将有界队列queue3中的pieceofdata数据全部放入有界队列queue2中,清空有界队列queue3;返回步骤701。
本发明的优点在于:
1)、一种可保持titan实时数据一致性的高效并行加载方法,可大幅提高titan实时数据的加载性能,加载速度提升在20倍之上。
2)、一种可保持titan实时数据一致性的高效并行加载方法,是高效安全的实时数据预处理加载方法;可在保持数据一致性的前提下极大提高数据加载效率,并可实时修改添加数据过滤规则。
附图说明
图1为本发明图数据库titan划分为7个模块的结构图;
图2为本发明一种可保持titan实时数据一致性的高效并行加载方法流程图。
具体实施例
下面结合附图对本发明的具体实施方法进行详细说明。
本发明为了保证数据一致性的前提下极大地提高titan实时数据的加载性能,提出了一种可保持titan实时数据一致性的高校并行加载方法;总体包括三部分:实时数据清洗,入库控制和新点处理;
规则管理线程负责实时动态更新过滤规则;主线程接收pieceofdata数据,放入有界队列queue1中;数据清洗模块根据清洗规则过滤掉不合格的数据,放入有界队列queue2中;id转换模块从有界队列queue2中取数据,与高速索引模块交互;判断当前pieceofdata数据中的两个点与titan内部id之间的对应关系是否存在与图数据库中;如果是,从索引中取出点对应的titan内部id属性与id值替换点,并保存到pieceofdatat数据中,放入到有界队列queue4;否则,将未被加载的点放入hashset中,并将对应的该pieceofdata数据放入有界队列queue3中;剩余数据加载模块从有界队列queue4中获取pieceofdatat数据,多线程并行加载到在titan中;
点加载控制线程判断数据清洗是否结束,如果没有结束,继续判断有界队列queue3是否已满,如果未满,则线程休眠一段时间等待有界队列queue3满,否则,多线程加载hashset中的点,并将该点与titan内部id之间的对应关系加入高速索引模块中;然后,点加载模块重置hashset,将有界队列queue3中的pieceofdata数据全部放入有界队列queue2中,清空有界队列queue3。
具体步骤如图2所示,如下:
步骤一、将图数据库titan划分为7个模块,且7个模块并行操作;
如图1所示,7个模块包括:数据接收模块,清洗规则管理模块,数据清洗模块,id转换模块,高速索引模块,点加载模块和剩余数据加载模块;每个模块独自或交互完成部分功能,从而实现整体上加载效率的提升。
第一个模块数据接收模块,实现从消息队列或csv文件等地方接收需要被处理的数据,并放入有界队列中。
第二个模块数据清洗模块,负责按照给定规则过滤不需要的数据;给定规则包括精确匹配,模糊或正则匹配。
第三个模块清洗规则管理模块,通过监控规则文件实现过滤规则的动态更新。
过滤规则文件为json格式文件,具体结构见附录1。
过滤规则文件:
第四个模块id转换模块,负责将数据中的点替换为图数据库中对应点的id。
第五个模块高速索引模块,结构为key-value类型;负责加速第四模块中id的转化速度。
第六个模块点加载模块,负责加载第四模块id转换时不存在于图数据库内的点;并在加载完成后将点及其id对应关系添加进高速索引模块。
第七个模块剩余数据加载模块,通过并行加载大幅提升图数据的加载速度。
步骤二、数据接收模块的多线程同时并行工作,每个线程循环从消息队列或csv文件等数据源获取图数据,解析成多条pieceofdata数据,放入有界队列queue1中。
图数据是各种由点和边构成的拓扑图数据;
pieceofdata数据由两个点,两个点之间的关系,以及点与关系的属性构成;点是一个用于唯一标识指定点的键值对,如uid=9867;
有界队列queue1用于存放从数据源获取的数据;
步骤三、清洗规则管理模块定时读取规则配置文件,或接受客户端请求读取规则配置文件,实时动态更新过滤规则;
步骤四、数据清洗模块多线程并行工作,每个线程循环依次从有界队列queue1获取一条pieceofdata数据,使用清洗规则进行判断,如果符合过滤条件,直接丢弃,否则,放入有界队列queue2。
queue2用于存放有界队列queue1中过滤之后的数据;
步骤五、id转换模块多线程并行工作,每个线程循环从有界队列queue2中取出清洗过滤之后的pieceofdata数据,并判断当前pieceofdata数据中的两个点与titan内部id之间的对应关系是否都存在于高速索引模块中;如果是,进入步骤六,否则,进入步骤八;
步骤六、id转换模块从高速索引模块中取出对应关系,用titan内部id属性与id值替换对应的pieceofdata数据中的点,并保存到pieceofdatat数据中,放入到有界队列queue4;
pieceofdatat数据中保存的是pieceofdata数据中的点被对应的id属性与id值替换之后的pieceofdata;
queue4用于存放pieceofdatat数据;
步骤七、剩余数据加载模块的多线程同时并行工作,每个线程循环从有界队列queue4中获取pieceofdatat数据,并加载在titan数据库中,返回步骤五;
步骤八、当前pieceofdata数据中至少一个点与titan内部id之间的对应关系未被加载到高速索引模块中,id转换模块将未被加载的点放入hashset中,并将对应的该pieceofdata数据放入有界队列queue3中;
queue3用于存放从有界队列queue2中选出的pieceofdata数据,该pieceofdata数据中至少一个点与titan内部id之间的对应关系未被加载到高速索引模块中。
步骤九、判断有界队列queue3是否已满或时间达到设定阈值t,如果是,执行步骤十,否则,返回步骤五;
阈值t是系统初始化参试,根据实际情况设定;
当有界队列queue3已满和时间达到设定阈值t两者的条件满足其中一个的时候,进入后续步骤继续;反之,当有界队列queue3未满并且时间未达到设定阈值t时,当前线程进行休眠,等待有界队列queue2中未被加载到高速索引模块中的数据,被id转换模块将点放入hashset中,且将对应的pieceofdata数据放入有界队列queue3中;直至有界队列queue3已满或者时间达到设定阈值t;
步骤十、点加载模块判断数据清洗是否结束,如果是,所有线程结束;否则,进入步骤十一;
步骤十一、点加载模块的每个线程加载hashset中的点,并将该点与titan内部id之间的对应关系加入高速索引模块中;
步骤十二、点加载模块对hashset进行重置,将有界队列queue3中的pieceofdata数据全部放入有界队列queue2中,清空有界队列queue3;返回步骤五。
应该注意到并理解,在不脱离后附的权利要求所要求的本发明的精神和范围的情况下,能够对上述详细描述的本发明做出各种修改和改进。因此,要求保护的技术方案的范围不受所给出的任何特定示范教导的限制。
- 还没有人留言评论。精彩留言会获得点赞!