一种基于概率分布的假牌车二次筛选方法与流程
本发明属于智能交通领域,尤其涉及一种基于概率分布的假牌车二次筛选方法。
背景技术:
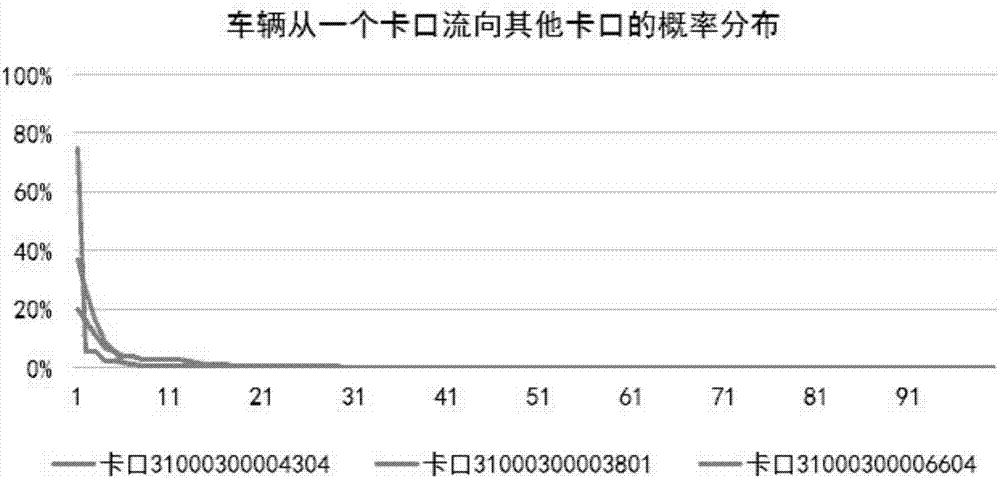
:近年来,随着我国国民经济的不断发展,机动车保有量不断增长,各种交通违法违章现象也日渐增多,其中“假牌”、“套牌”是具有严重危害的违法行为。车辆“假牌”现象,指的是车辆伪造、变造机动车号牌,非法使用在机动车辆管理所车辆登记信息中不存在的车牌号的现象。“假牌”会造成严重的危害。使用假车牌的车辆往往肆意超速、不按交通信号灯行驶,严重扰乱交通秩序。一旦发生交通事故,这些司机在侥幸心理的驱使下,往往会选择逃逸,使办案民警难以确定肇事车辆。同时,“假牌”车也往往是犯罪分子的作案工具,增加破案难度。查处“假牌”车辆,已成为各地公安部门和交通管理部门的重要任务。目前,“假牌”车发掘主要是通过卡口采集的信息与数据库对比,数据库中不存在的定义为“假牌”车,由于卡口号牌识别精度有限,初步筛选的假牌车往往多达几十万辆,需要进行二次筛选。从已有文献和公开的专利提出的假牌车筛选识别方法来看,目前涉及假牌筛选识别的方法主要方法可分为两类:(1)基于辅助设备。如专利申请号cn201210187968.0采用预留安全监测密码的方式。在交警内部管理系统平台预留车辆安全检测码,执法交警现场通过手持终端,将车辆信息和安全监测密码与预留信息对比,判断是否为假牌车;专利申请号cn201320577360.9采用一种基于rfid技术的虚假车牌识别装置,通过将射频芯片及微电子芯片组成的电子标签安装在车身,利用射频识别技术来判断车辆是否假牌套牌。(2)基于车辆信息对比的检测识别方法,如专利申请号201510744990.4采用图片相似度识别。首先提取图片中车辆区域的sift特征,利用聚类算法离散化后,转换成邻域特征,作为基础的车辆描述特征,然后利用随机森林方法进行相似度学习,得到相似度预测模型,用来判断图片中两个车辆是否属于相似车辆。上述方法在实际应用时存在一些弊端:第一种基于辅助设备的检测识别方法,需要给机动车安装额外设备,现实中难以推广;第二种基于车辆外观信息比对的方法,受光照、环境影响较大,准确率不高。为了解决上述方法的弊端,实现快速有效地分析大规模交通数据,从大量初筛的疑似“假牌”车辆中,精确锁定真正的“假牌”车,需要一种新的技术方案来满足交管部门的需求。技术实现要素:本发明提出了一种可以有效的把识别错误和真正的“假牌”车区分开来,大大缩小了“假牌”车的排查范围,无需额外设备,部署方便,适用性广,识别准确率较高,极大地提高后续核查和布控效率的基于概率分布的假牌车二次筛选方法。本发明采用的技术方案是:一种基于概率分布的假牌车二次筛选方法,包括以下步骤:s1.获取卡口过车记录数据,并进行数据清洗得到卡口过车记录数据;s2.对原始卡口过车记录数据排序,提取车辆行驶卡口对向量(ki,kj),ki和kj表示卡口编号,与hphm一起放入集合k中,hphm表示车辆号牌;s3.计算卡口间车辆流向的空间概率pij,并将所有概率(ki,kj,pij)保存在集合p中;s4.基于s1中卡口过车记录数据获取车牌集合h,并与车驾管数据库比对初步筛选假车牌,得到初步筛选假车牌集合f1;s5.基于s3中车辆流向的空间概率分布计算集合f1中每一辆车正常跳转次数jnor和异常跳转次数jp,并将符合空间概率分布的车牌放入集合h1中,不符合空间概率分布的车牌放入集合h2中;s6.基于集合h1和集合h2中字符占比计算车牌字符识别错误概率lx;s7.基于集合f1中每一辆车正常跳转次数jnor和异常跳转次数jp以及车牌字符识别错误概率lx对车牌二次筛选,综合判定车牌假牌概率。本发明利用车辆行驶的空间特性,提出了概率分布的概念,通过计算车辆每一次跳转的概率,判断车辆在空间上的连续性。如果车辆轨迹在空间上的连续性较高,说明该轨迹有较大的可能性是一辆车;如果车辆轨迹在空间上的连续性较低,说明该轨迹有较大的可能性是多辆车的,也就是说该号牌的识别正确率较低,通过计算排除不符合空间概率分布的车牌。同时,由于卡口设备对不同的字符识别精度不一样,将空间上比较符合分布概率的车牌和不符合概率分布的车牌,分成两个集合,分别统计两个集合中字符占比,如果字符占比出现明显误差,说明该字符识别正确率可能较低,可以通过字符识别概率,再次排除部分识别错误率较高的车牌。进一步,步骤s1的卡口过车记录数据获取方法如下:获取一个周期内原始卡口过车记录数据,并根据设定的数据清洗规则,删除不符合规则的数据,并保留需要的维度,包括卡口编号、号牌号码、过车时间。进一步,步骤s2得到集合k的步骤如下:(1)根据号牌号码进行分组,每一组内按照过车时间排序,然后每一组进行以下操作:步骤一、取出第一条记录,记作记录1;步骤二、取出下一条记录,记作记录2;步骤三、计算记录1和记录2的时间差δt;如果时间差δt小于阈值t,转到步骤四;如果时间差δt大于阈值t,将记录2赋值给记录1,转到步骤二;步骤四、将号牌和两条记录的卡口编号组成卡口向量对(hphm,ki,kj),放入集合k中;将记录2赋值给记录1,转到步骤二;(2)遍历所有的组,得到集合k。进一步,步骤s3中计算车辆流向的空间概率pij的步骤包括:统计集合k中每一个向量(ki,kj)的数量,记为cout(ki,kj),那么卡口ki流出车辆总和为车辆从卡口ki到卡口kj的流向概率进一步,步骤s4中的车牌集合h为s1中卡口过车记录数据中不重复的车牌。进一步,步骤s4中初步筛选是将不存在车驾管数据库中的车牌集合形成初步筛选假车牌集合f1。进一步,步骤s5中计算集合f1中每一辆车正常跳转次数jnor和异常跳转次数jp步骤包括:(i)根据集合f1中的车牌,获取每一个车牌在集合k中对应的所有记录;(ii)如果该车牌在集合k中没有对应的记录,将该号牌正常跳转的次数jnor以及异常跳转次数jp均记为0;(iii)如果该车牌在集合k中有对应的记录,那么根据每一条记录的(ki,kj)获取集合p中对应的流向概率pij,如果pij大于等于阈值pi,那么认为车辆这一次跳转是正常的,如果pij小于阈值pi,那么认为车辆这一次跳转是异常的;(iv)统计每一个车牌正常跳转的次数jnor,即pij>=pi的次数以及异常跳转的次数jp,即pij<pi的次数。进一步,步骤s6中计算车牌字符识别错误概率lx的步骤包括:分别统计集合h1和集合h2中每一个字符的占比记为lx1和lx2,其中x代表可能字符,计算h2集合中每一个字符相较于h1中占比的误差lx=abs((lx2-lx1)/lx1)。进一步,步骤s7中车牌二次筛选公式如下:fb的数值越大,代表假牌的可能性越高,否则识别错误的可能性越高;ε按照经验值,一般取周期天数。本发明是为了克服在实际情况中,由于光线、角度、号牌污损等因素,卡口对于号牌的识别率无法达到100%(一般在96%-98%左右)的限制,实际情况中,卡口很有可能把一些字符识别成其他字符,把正常的车牌识别成不在车驾管数据库中的车牌,导致初筛的假牌车名单过多,人工核查工作量大。本发明的构思为:车辆经过的下一个卡口,应该符合空间上指数概率分布,如果某个牌号比较不符合空间概率分布,很有可能是同时将两个不同的车牌识别成了同一个车牌,也就是识别错误。同时,车牌由不同的字符组成,每一种字符识别概率不一样,对于由识别概率较高的字符组成的车牌优先排查,可以尽量减少识别错误的影响,从而可以极大的缩小人工排查范围,并提高假牌命中率。本发明的有益效果主要表现在:能够较好的克服由于卡口识别错误引起的假牌车初筛名单过多,极大的缩小排查范围,提高假牌命中率、实用性良好;无需依赖路网结构,适用性较强。附图说明图1为本发明的流程图。图2为本发明的车辆流向的空间概率分布图。具体实施方式下面结合具体实施例来对本发明进行进一步说明,但并不将本发明局限于这些具体实施方式。本领域技术人员应该认识到,本发明涵盖了权利要求书范围内所可能包括的所有备选方案、改进方案和等效方案。参照图1,一种基于概率分布的假牌车二次筛选方法,包括以下步骤:s1.获取卡口过车记录数据,并进行数据清洗得到卡口过车记录数据;卡口指的是,采用先进的光电、计算机、图像处理、模式识别、远程数据访问等技术,对监控路段的机动车道、非机动车道进行全天候实时监控并记录相关图像数据,并自动获取车辆的通过时间、地点、行驶方向、号牌号码、号牌颜色、车身颜色等数据。车辆的过车记录会以格式化数据存储在数据库中。获取一个周期内卡口过车记录数据。为了减小样本过小带来的偶然性,周期可以选得长一点,一般为1-6个月,优先选择为3个月。原始卡口数据存在一些脏数据,包括没有车牌信息,车牌无法识别,部分字符无法识别等等,清洗掉这些脏数据,并保留需要的维度,包括卡口编号、号牌号码、过车时间。s2.对卡口过车记录数据排序,提取车辆行驶卡口对向量(ki,kj),ki和kj表示卡口编号,与hphm一起放入集合k中,hphm表示车辆号牌;车辆在正常行驶过程中会不断的被卡口捕获,理论上车辆会有较高的概率被比较邻近的卡口捕获,被越远的卡口捕获的概率越低。如果一个车辆经常被概率较低的卡口捕获,说明该车辆不太符合空间概率分布。考虑到卡口的识别精度无法达到100%,有可能导致在路上行驶的不同车辆,被识别成同一个号牌,从而导致车辆不符合空间概率分布,反过来讲,符合空间概率分布的车牌,识别正确的可能性较高。在现实中,由于卡口故障,网络故障,卡口的捕获率无法达到100%等因素,车辆在经过部分卡口的时候,有可能不会被记录下来。一般认为车辆从1个卡口出发,一定的时间内没有被任何卡口捕获,有可能是发生了数据缺失(也有可能是车辆静止),数据缺失有可能导致下一个捕获车辆的卡口不太符合空间概率分布。这个时间称为阈值t,如果车辆两个卡口之间的间隔时间超过了阈值t,这组卡口对不参与计算。提取车辆行驶卡口对向量的过程如下:(1)将s1清洗后的数据,根据号牌号码进行分组,每一组内按照过车时间排序,然后每一组进行以下操作:步骤一、取出第一条记录,记作记录1;步骤二、取出下一条记录,记作记录2;步骤三、计算记录1和记录2的时间差δt;如果时间差δt小于阈值t,转到步骤四;如果时间差δt大于阈值t,将记录2赋值给记录1,转到步骤二;步骤四、将号牌和两条记录的卡口编号组成卡口向量对(hphm,ki,kj),放入集合k中;将记录2赋值给记录1,转到步骤二;(2)遍历所有的组,得到集合k。s3.计算卡口间车辆流向的空间概率pij,并将所有概率(ki,kj,pij)保存在集合p中;根据集合k计算车辆从一个卡口出发,到达其他每一个卡口的概率,将这个概率称为卡口间流向概率。流向概率反映了车辆下一个卡口在空间上概率分布。卡口流向概率(ki,kj)=(从卡口ki出发到达卡口kj的车辆数)/从卡口ki出发的车辆总数。统计集合k中每一个向量(ki,kj)的数量,记为cout(ki,kj),那么卡口ki流出车辆总和,为卡口ki到卡口kj的流向概率计算所有卡口对之间的流向概率,如果两个卡口之间的通行记录数为零,那么通行概率记为0%。s4.基于s1中卡口过车记录数据获取车牌集合h,并与车驾管数据库比对初步筛选假车牌,得到初步筛选假车牌集合f1;具体的,根据s1中过车记录数据,获取不重复的车牌,得到该周期内所有车牌的集合h。将集合h中的车牌同车驾管数据库中的进行比对,如果车牌不在数据库中,放入集合f1中,f1是初步筛选的假牌集合。s5.基于s3中车辆流向的空间概率分布计算集合f1中每一辆车正常跳转次数jnor和异常跳转次数jp,并将符合空间概率分布的车牌放入集合h1中,不符合空间概率分布的车牌放入集合h2中;具体步骤包括:(i)根据集合f1中的车牌,获取每一个车牌在集合k中对应的所有记录;(ii)如果该车牌在集合k中没有对应的记录,将该号牌正常跳转的次数jnor以及异常跳转次数jp均记为0;(iii)如果该车牌在集合k中有对应的记录,那么根据每一条记录的(ki,kj)获取集合p中对应的流向概率pij,如果pij大于等于阈值pi,那么认为车辆这一次跳转是正常的,如果pij小于阈值pi,那么认为车辆这一次跳转是异常的;阈值pi取值为0.2%。(iv)统计每一个车牌正常跳转的次数jnor,即pij>=pi的次数以及异常跳转的次数jp,即pij<pi的次数。如果车辆跳转不符合空间概率分布,说明该车牌有较大可能性为识别错误,反过来,符合概率分布的,说明该车牌识别正确性较高。s6.基于集合h1和集合h2中字符占比计算车牌字符识别错误概率lx;当样本足够大,车牌各个字符出现的频率应该趋于一个稳定值,如果某个字符出现的频率比较高,说明其他字符误识别成该字符的可能性较高,反过来,如果某个字符出现的平率比较低,说明该字符有较大的可能性识别成其他字符。将集合f1中的元素,按照跳转概率分成两个集合h1和h2,其中集合h1为跳转概率大于等于0.2%的元素,集合h1为跳转概小于0.2%的元素。由于集合h1中的车牌,比较符合空间概率分布,因此,集合h1中的字符识别正确率较高,反之,h2中字符识别概率较低。分别统计集合h1和集合h2中每一个字符的占比记为lx1和lx2,其中x代表可能字符,计算h2集合中每一个字符相较于h1中占比的误差lx=abs((lx2-lx1)/lx1)。lx可以近似的用来估算每一种字符识别错误的概率。s7.基于集合f1中每一辆车正常跳转次数jnor和异常跳转次数jp以及车牌字符识别错误概率lx对车牌二次筛选,综合判定车牌假牌概率。根据车辆流向是否符合空间概率分布,可以在一定程度上判断两个不同的车牌有没有识别成同一个车牌,通过去掉不符合空间概率分布的车牌,可去掉这部分识别错误的车牌。在剩下的车牌中,不同的车牌由不同的字符组成,每一种字符识别成功的概率不同,对于由识别概率较高的字符组成的车牌,如果不在车驾管数据中,假牌的可能性非常高,可以优先进行排查。最后可以根据公式fb的数值越大,代表假牌的可能性越高,否则识别错误的可能性越高。ε按照经验值,一般取周期天数。本发明利用车辆行驶的空间特性,提出了概率分布的概念,通过计算车辆每一次跳转的概率,判断车辆在空间上的连续性。如果车辆轨迹在空间上的连续性较高,说明该轨迹有较大的可能性是一辆车;如果车辆轨迹在空间上的连续性较低,说明该轨迹有较大的可能性是多辆车的,也就是说该号牌的识别正确率较低,通过计算排除不符合空间概率分布的车牌。同时,由于卡口设备对不同的字符识别精度不一样,将空间上比较符合分布概率的车牌和不符合概率分布的车牌,分成两个集合,分别统计两个集合中字符占比,如果字符占比出现明显误差,说明该字符识别正确率可能较低,可以通过字符识别概率,再次排除部分识别错误率较高的车牌。一种具体应用实施例如下:s1.卡口过车数据的提取:获取一个周期内卡口过车记录数据,保留需要的维度,包括卡口编号、号牌号码过车时间。本实施例抽取了杭州市2016年1月1日-1月30日,累计30日数据,一共包含489个卡口,总共129534497条记录,卡口数据格式如下表1:表1字段数据类型含义kkidvarchar(20)卡口idhphmvarchar(10)号牌号码hplxvarchar(2)号牌种类jgsjvarchar(20)过车时间其中一个kkid对应一个道路断面,hphm+hpzl唯一确定一辆汽车。jgsj精确到秒,(以下步骤中,号牌号码包含了号牌种类,不再赘述)卡口数据的清洗:由于号牌号码是卡口系统根据图片识别,号牌识别率无法达到100%,原始卡口数据存在一些脏数据,包括车牌为空,无法识别,部分字符无法识别等等。清洗该部分数据,部分案例如下表2所示:表2序号号牌号码过车时间1???????2016-01-1514:52:512null2016-01-2019:32:303宁b?711t2016-01-2511:31:344浙a00?nt2016-01-2520:54:045浙a025x?2016-01-2114:18:136无法识别2016-01-1022:49:28s2.过车记录排序,并提取卡口向量过车记录排序:按照号牌号码,过车时间,对数据进行排序。部分数据如下表3所示(省略号部分为未显示部分)。表3序号号牌号码卡口id过车时间1浙a2m1**310003000074022016-01-0407:51:092浙a2m1**310003000107022016-01-0408:48:263浙a2m1**310003000109042016-01-0408:50:134浙a2m1**310003000045042016-01-0408:50:385浙a2m1**310003000045022016-01-0408:50:586浙a2m1**310003000199022016-01-0408:53:367浙a2m1**310003000054022016-01-0408:59:18·····················对排好序的记录,取出符合要求的卡口对向量。在本实施例中,阈值t设置为15分钟。以表3为例,取出卡口对的过程如下:1、取出记录1,记录2;2、计算记录1与记录2时间差,为57mins17s>15mins,舍弃记录1;3、取出记录3,计算记录2和记录3的时间差为1mins47s<15mins,将(浙a2m1**,31000300010702,31000300010904)放入集合k中。4、取下一条记录,重复以上操作。以上7条过车记录,可以取出5个卡口对。s3.计算卡口间流向概率统计集合k中所有的(ki,kj),可以得到从卡口ki流出,流向卡口kj的车辆数。统计count(ki,kj),可以得到从ki流出的车辆总数,得到如下表4所示(省略号部分为未显示部分)。表4卡口ki卡口kjcount(ki,kj)count(ki)概率31000300000102310003000018043543315635122.7%31000300000102310003000126193538415635122.6%31000300000102310003000018022653015635117.0%31000300000102310003000270011811715635111.6%3100030000010231000300009719101391563516.5%310003000001023100030000050252981563513.4%310003000001023100030000090442361563512.7%310003000001023100030000050338851563512.5%310003000001023100030000250421501563511.4%310003000001023100030000050411901563510.8%310003000001023100030000090211801563510.8%31000300000102310003000258199621563510.6%31000300000102310003000050028201563510.5%31000300000102310003000121208101563510.5%······················································卡口流向概率在另一种维度上体现了卡口分布和路网结构。计算卡口31000300004304到其他卡口的流向概率,并且将概率倒叙排列,绘制折线图,概率呈明显的指数分布。对卡口31000300003801和卡口31000300006604同样计算流向概率并绘制曲线图,概率也成明显的指数分布。三个卡口流向概率的分布曲线图,如图2所示。其中y轴表示概率,x轴表示其他卡口(按照概率倒序)。s4.卡口记录与车驾管数据库对比,初步确定假牌车范围:本实施例中,车驾管数据仅仅包含“浙a”开头的相关数据,非浙a号牌无法判断是否为假牌,因此假牌范围圈定为“浙a”的号牌。利用mapreduce获取s1中过车记录不重复的车牌,只保留以“浙a”开头的号牌,将这些号牌同车驾管数据进行对比,如果不包含在车驾管数据库中,放入集合f1中,f1为初筛的假牌车名单。本实施例中,共有235642个号牌为初筛疑似假牌。s5.计算集合f1中每一辆车正常跳转次数和异常跳转次数。根据集合f1中的车牌,获取每一个车牌在集合k中对应的所有记录。根据每一条记录的(ki,kj)获取集合p中对应的流向概率pij。部分结果如下:表5统计每一个号牌正常跳转的次数jnor,即pij>=pi的次数以及异常跳转的次数jp,即pij<pi的次数。,如果该号牌在集合k中没有对应的记录,将该号牌正常跳转的次数jnor以及异常跳转次数jp均记为0。部分结果如下表6:表6序号号牌号码正常跳转次数异常跳转次数1浙aa59**29372浙a925**18703浙a2em**37164浙a2ka**27025浙a255**16746浙ak5x**6607浙ac29**16448浙a9en**25949浙a295**458010浙ah52**2583················································s6.计算车牌字符识别错误概率。我们将集合f1中的元素,按照跳转概率,分成两个集合h1和h2,其中h1包含66460616个元素,h2包含23970273个元素。车牌由7位字符组成,其中前两位表示地方,后五位表示车牌。本实施例中,前两位以“浙a”为主,因此我们主要考虑后5位车牌字符。将h1和h2集合中的车牌后5位字符占比分别进行统计,得到如下表格:表7我们看到,集合h1和集合h2中,3、5、q、u这些字符占比比较接近,识别错误概率较小,t、x、n这些字符占比差别较大,识别错误概率较高。s7.二次筛选,假牌可能性排序:假牌可能性fb可以通过以下公式计算。本实施例中ε取值为15。部分结果如下。表8在本实施例中,从20多万的疑似套牌中,筛选出1895个套牌可能性较高的号牌(fb>0),筛选的范围缩小了100多倍。通过实际验证,如果仅仅按照“疑似假牌”出现次数排序,前50个疑似假牌中,仅有4个确定为假牌,其余为识别错误,按照本方法排序,前50个疑似假牌中,有24个确定为假牌,准确率提高了6倍。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1