本发明属于电子取证领域,涉及手机取证,尤其涉及一种解析英飞凌手机字库的方法。
背景技术:
随着移动通信技术所提供服务水平和服务种类的不断提高和扩充,手机已日益成为人们工作生活中不可缺少的联系工具。然而,利用手机进行诈骗、诽谤和伪造等犯罪活动也屡见不鲜,手机数据恢复与手机取证是打击这类犯罪的一个有效手段。
从概念上讲,手机取证就是从手机sim卡、手机内、外置存储卡以及移动网络运营商数据库中收集、保全和分析相关的电子证据,并最终从中获得具有法律效力、能被法庭所接受的证据的过程。目前牵涉到手机的犯罪行为大致有三种:一种是在犯罪行为的实施过程中使用手机来充当通信联络工具;第二种是手机被用作一种犯罪证据的存储媒质;第三种是手机被当作短信诈骗、短信骚扰和病毒软件传播等新型手机犯罪活动的实施工具。这些都充分地表明进行手机取证技术的相关研究对于维持社会稳定、保障人民权益和打击犯罪行为具有充分的必要性和极大的迫切性。
现有技术中,涉及智能手机的取证较多,但涉及非智能手机的取证技术却很少,例如,对于搭载英飞凌cpu的非智能手机,其cpu为早期产品,加之内部数据结构较为复杂,因此,现有技术中尚未涉及此类手机的取证,因此,急需一种解析英飞凌手机字库结构并解析其中的短信、通讯录以及通话记录的方法。
技术实现要素:
本发明针对现有技术的不足和上述问题,提出一种解析英飞凌手机字库的方法,通过查找字库中的有效数据的总管理字段,找出地址指示,再根据该地址指示进行手机数据的寻址并解析出手机数据中的短信、通讯录以及通话记录,最终达到解析英飞凌手机数据的目的,所述方法包括以下步骤:
s1:查找所述字库中的管理字段标识;
s2:判断所述管理字段标识所标识的管理字段是否为总管理字段,如果是,执行步骤s3,否则执行步骤s1;
s3:判断所述总管理字段是否为有效数据的总管理字段,如果是,执行步骤s4,否则执行步骤s1;
s4:根据所述有效数据的总管理字段中的地址指示进行寻址,获取手机数据;
s5:解析所述手机数据,合并所解析的结果;
s6:判断是否完成所述有效数据的总管理字段的解析,如果是,执行步骤s7,否则执行步骤s4;
s7:判断是否完成所述字库的解析,如果是,结束流程,否则执行步骤s1。
作为优选,所述管理字段标识为0x30fcffff。
作为优选,所述步骤s2的具体方法为:以所述管理字段标识的首地址为起始位置,向后跳转0x45字节,读取0x45字节的内容,判断所述0x45字节的内容是否为0xff,如果是,执行步骤s1,否则执行步骤s3。
作为优选,所述步骤s3的具体方法为:以所述管理字段标识的首地址为起始位置,向后跳转至0x17字节并读取该字节的内容,并顺序读取0x19、0x1b、0x1d、0x1f……字节的内容,直至所读出的所述字节内容为0xff,判断所述0xff之前所读出的所述字节内容是否为连续递增的数列,如果不是,则所述总管理字段为有效数据的总管理字段,执行步骤s4,否则执行步骤s1。
作为优选,所述步骤s4包括以下步骤:
s401:以所述管理字段标识的首地址为起始位置,向后跳转至0x16字节并以所述0x16字节的地址为起始位置,以两字节为一组,读取所述两字节的内容0xmmnn为地址指示,其中,mm和nn为任意非零的十六进制数,0xnn为数据大段号,表示所述字库中的第0xnn个数据大段,0xmm为段内偏移量;
s402:查找所述字库中所述0xnn数据大段的数据大段标识0x4365nn00,其中,0x4365为数据大段的固定标识,0xnn为所述数据大段号,表示所述字库中的第0xnn个数据大段;
s403:以所述数据大段标识的后一字节的地址为起始位置,将所述0xmm加上所述0xnn的和乘以0x100作为偏移量进行寻址,以获取手机数据。
作为优选,所述步骤s5包括以下步骤:
s501:判断当前位置起始的两字节内容是否为数据小段标识,如果是,执行步骤s502,否则执行步骤s6;
s502:判断所述数据小段标识后是否为短信标识,如果是,执行步骤s505,否则执行步骤s503;
s503:判断所述数据小段标识后是否为通讯录标识,如果是,执行步骤s506,否则执行步骤s504;
s504:判断所述数据小段标识后是否为通话记录,如果是,执行步骤s507,否则,执行步骤s508。
s505:解析短信的数据结构,跳转至步骤s508;
s506:解析通讯录的数据结构,跳转至步骤s508;
s507:解析通话记录的数据结构,跳转至步骤s508;
s508:根据解析结果,将短信、通讯录及通话记录分别进行合并。
作为优选,所述数据小段标识为0xc0ff或0xf0ff。
作为优选,所述短信标识为0x0108或0x0208,其中,0x0108表示未读短信,0x0208表示已读短信。
作为优选,所述通讯录标识为0xkk00,其中,0xkk为顺序递增的非零的十六进制数。
作为优选,所述步骤s505包括以下步骤:
s5051:查找并解析基站信息:所述短信标识的末字节位置向后偏移1字节的内容为所述基站标识,所述基站标识后的字节内容为所述基站号码,所述基站号码以字节交换的格式存储,以f作为所述基站号码的结束标识;
s5052:查找并解析对端号码:所述基站号码的末字节向后偏移4字节的内容为所述对端号码,所述对端号码以字节交换的格式存储,以f作为所述对端号码的结束标识;
s5053:查找并解析短信收发时间:所述对端号码的末字节向后偏移2字节的内容为所述短信收发时间的长度,所述长度包括1字节的长度信息和7字节的所述短信收发时间,所述短信收发时间的长度后的7字节内容为所述短信收发时间,其中,所述短信收发时间按字节交换的格式存储,所述7字节按地址由低至高的内容分别表示年、月、日、时、分、秒及固定填充字节0x23;
s5054:查找并解析短信内容:所述固定填充字节0x23后的1字节内容为所述短信的实际长度,所述实际长度后的字节内容为所述短信内容,所述短信内容以unicode大端格式存储。
s5055:以所述数据小段标识的首字节地址为起始位置,判断所解析的字节长度是否超过0x100字节,如果是,结束所述步骤s505的流程,否则,执行步骤s5056;
s5056:在当前所述数据小段中查找下一所述短信标识并执行步骤s5051。
作为优选,所述步骤s506包括以下步骤:
s5061:解析所述通讯录的条目序号:所述通讯录标识的低字节内容0xkk为所述条目序号,表示第0xkk条通讯录,其中,0xkk为顺序递增的非零的十六进制数;
s5062:解析联系人姓名:所述条目序号后为联系人姓名,所述联系人姓名以unicode小端格式储存并以0x0000为结束符、且长度不超过0x2a字节;
s5063:解析联系人电话号码:以所述通讯录标识的首字节地址为起始位置,向后跳转0x2d字节,顺序读取的内容为所述联系人电话号码,所述联系人电话号码以ascii码格式储存并以0x0000为结束符、且长度不超过0x2a字节;
s5064:以所述数据小段标识的首字节地址为起始位置,判断所解析的字节长度是否超过0x100字节,如果是,结束所述步骤s506的流程,否则,执行步骤s5065;
s5065:由于所述通讯录的每一所述条目的长度为0xll字节,故以当前所述条目序号的首字节地址为起始位置,读取0xll+1字节和0xll+2字节的内容作为下一条目序号,执行步骤s5062。
作为优选,所述通讯录的每一所述条目的长度为0x56字节。
作为优选,所述步骤s507包括以下步骤:
s5071:以所述数据小段标识的首地址为起始位置,向后跳转0x10字节,顺序读取所述0x10字节至0x1e字节的内容;
s5072:判断所述0x10字节的内容是否为ascii码格式存储的“+”号,如果是,执行步骤s5073,否则执行步骤s5074;
s5073:判断0x11字节至所述0x1e字节的内容是否均为ascii码格式存储的数字,如果是,执行步骤s5075,否则结束所述步骤507的流程;
s5074:判断所述0x10字节至0x12字节的内容是否为ascii码格式存储的数字,如果是,执行步骤s5075,否则结束所述步骤507的流程;
s5075:查找通话时间:以所述数据小段标识的首地址为起始位置,向后跳转0x2字节至所述通话时间的首地址;
s5076:解析所述通话时间:以当前地址为首地址,顺序读取前十个字节的内容,其中,第一字节的内容为秒,第二字节的内容为分,第三字节的内容为时,第六字节的内容为日,第七字节的内容为月,所述秒、分、时、日、月均以十六进制数表示,第九和第十字节的内容为年并以unicode小端格式存储;
s5077:查找并解析对端号码:以所述通话时间的首地址为起始位置,向后跳转0xe字节,顺序读取所述0xe字节及其后的字节内容为所述对端号码,所述对端号码以ascii码的数字格式储存、以0x0000为结束标识且长度不超过0x2a字节;
s5078:以所述数据小段标识的首字节地址为起始位置,判断所解析的字节长度是否超过0x100字节,如果是,结束所述步骤s507的流程,否则,执行步骤s5079。
s5079:寻址下一通话记录的通话时间:以当前所述通话时间的首字节地址为起始位置,跳转0x38字节至下一通话记录的通话时间的首字节地址,并执行步骤s5076。
作为优选,每一所述通话记录的长度为0x38字节。
作为优选,所述步骤s6的具体方法为,在所述有效数据的总管理字段中,读取下一所述地址指示0xmmnn,判断所述地址指示0xmmnn的值是否为0xffff,如果是,执行步骤s7,否则执行步骤s4。
本发明的有益效果是能够解析英飞凌手机的短信及通话记录,填补了现有技术中无法解析英飞凌手机字库的技术空缺,解决了无法针对英飞凌手机的取证问题,避免了无法获取此类电子证据的盲点。
附图说明
图1为本发明的主流程图;
图2为本发明中有效数据的总管理字段的数据结构图;
图3为本发明中无效数据的总管理字段的数据结构图;;
图4为本发明中包含数据大段标识的数据结构图;
图5为本发明中短信字段的数据结构图;
图6为本发明中解析手机数据的处理流程图;
图7为本发明中解析短信字段的处理流程图;
图8为本发明中解析通讯录字段的处理流程图;
图9为本发明中通讯录字段的数据结构图;
图10为本发明中解析通话记录的处理流程图;
图11为本发明中解析通话记录的数据结构图。
具体实施方式
下面结合附图和实施例对本发明作进一步阐述。
搭载英飞凌cpu的手机的短信、通讯录以及通话记录都存储于其字库中,字库容量包括但不限于4m、8m、16m及32m字节,本实施例中的字库容量为4m字节。
如图1所示,一种解析英飞凌手机字库的方法,包括以下步骤:
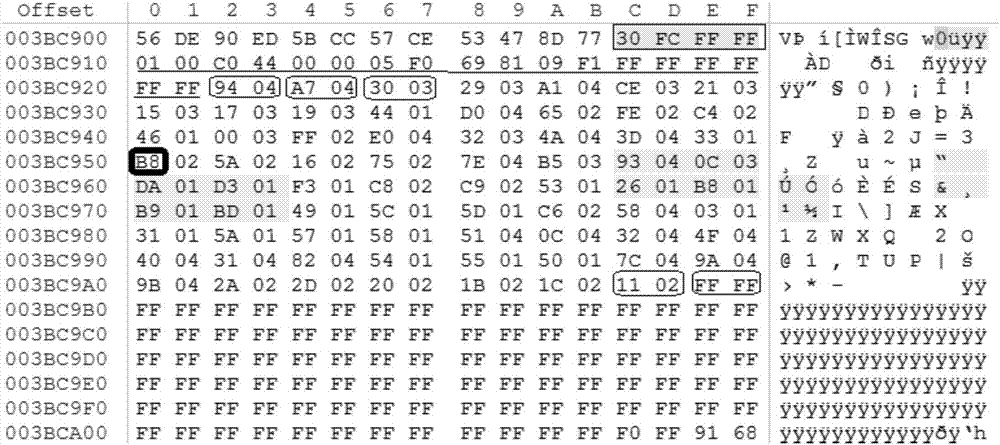
s1:查找字库中的管理字段标识:如图2所示,本实施例中的管理字段标识为0x30fcffff。
s2:判断管理字段标识所标识的管理字段是否为总管理字段,如果是,执行步骤s3,否则执行步骤s1;
本实施例中,以管理字段标识0x30fcffff的首地址为起始位置,向后跳转0x45字节,读取0x45字节的内容,判断0x45字节的内容是否为0xff,如果是,执行步骤s1,否则执行步骤s3;
如图2所示,本实施例中,0x45字节的内容为0xb8,故执行步骤s3。
s3:判断该总管理字段是否为有效数据的总管理字段,如果是,执行步骤s4,否则执行步骤s1;
以该管理字段标识0x30fcffff的首地址为起始位置,向后跳转至0x17字节并读取该字节的内容,并顺序读取0x19、0x1b、0x1d、0x1f……字节的内容,直至所读出的字节内容为0xff,判断该0xff之前所读出的字节内容是否为连续递增的数列,如果不是,则该总管理字段为有效数据的总管理字段,执行步骤s4,否则执行步骤s1;
如图2所示,本实施例中,顺序读取0x17、0x19、0x1b、0x1d、0x1f……等字节的内容分别为0x94、0xa7、0x30、0x29、0xa1……,可以看出该数列为非连续递增的数列,表示该总管理字段为有效数据的总管理字段,故执行步骤s4;
图3示出了本实施例中另一总管理字段的数据结构图,顺序读取0x17、0x19、0x1b、0x1d、0x1f……等字节的内容分别为0xbf、0xc0、0xc1、0xc2、0xc3……,可以看出该数列为连续递增的数列,表示该总管理字段为无效数据的总管理字段,即,该总管理字段中的地址指示的存储空间中无数据。
s4:根据有效数据的总管理字段中的地址指示进行寻址,获取手机数据,包
括以下步骤:
s401:如图2所示,本实施例中,以管理字段标识0x30fcffff的首地址为起始位置,向后跳转至0x16字节并以0x16字节的地址为起始位置,以两字节为一组,分别读取两字节的地址指示为0x9404、0xa704、0x3003……,其中的高字节的内容0x04、0x04、0x03……为数据大段号,表示手机数据分别存储在字库中第0x04、0x04、0x03……个数据大段中,低字节的内容0x94、0xa7、0x30……为段内偏移量。
s402:如图4所示,查找字库中第0x04数据大段的数据大段标识0x43650400,其中,0x4365为数据大段的固定标识,0x04为数据大段号,表示手机数据存储在字库中的第4个数据大段;
s403:如图4所示,以数据大段标识0x43650400的后一字节0xf0ff的地址为起始位置,将图2所示的第一个地址指示0x9404中的段内偏移量0x94加上数据大段号0x04的和,即0x98,再乘以0x100作为偏移量进行寻址,以获取手机数据,本实施例中,由于每一数据小段的长度为0x100字节,所以,从图4所示的0xf0ff的首字节为起始地址,向后跳转0x9800字节,寻址到手机数据,如图5所示。
s5:解析手机数据,合并所解析的结果,包括图6所示的以下步骤:
s501:判断当前位置起始的两字节内容是否为数据小段标识0xc0ff或0xf0ff,如果是,执行步骤s502,否则执行步骤s6;如图5所示,本实施例中,当前位置起始的两字节内容是0xf0ff,故执行s502;
s502:判断数据小段标识后是否为短信标识0x0108或0x0208,如果是,执行步骤s505,否则执行步骤s503;如图5所示,本实施例中,数据小段标识后为短信标识0x0108,故执行步骤s505;
s503:判断数据小段标识后是否为通讯录标识0xkk00,其中,0xkk为顺序递增的非零的十六进制数,如果是,执行步骤s506,否则执行步骤s504;
s504:判断数据小段标识后是否为通话记录,如果是,执行步骤s507,否则,执行步骤s508。
s505:解析短信的数据结构,跳转至步骤s508,包括图7所示的以下步骤:
s5051:查找并解析基站信息:如图5所示,本实施例中,短信标识0x0108的末字节位置向后偏移1字节的内容0x91为基站标识,基站标识0x91后的字节内容为基站号码0x683108301105f0,基站号码以字节交换的格式存储,以f作为基站号码的结束标识,因此,解析出此基站号码为8613800311500;
s5052:查找并解析对端号码:如图5所示,本实施例中,基站号码0x683108301105f0的末字节向后偏移4字节的内容为对端号码0x6851917664f2,该对端号码以字节交换的格式存储,以f作为对端号码的结束标识,因此,解析出此对端号码为8615194967462;
s5053:查找并解析短信收发时间:如图5所示,本实施例中,对端号码0x6851917664f2的末字节向后偏移2字节的内容为短信收发时间的长度0x08,即8个字节,其中,包括1字节的长度信息和7字节的短信收发时间,短信收发时间的长度后的7字节内容0x80904151429123为短信收发时间,其中,短信收发时间按字节交换的格式存储,该7字节按地址由低至高的内容分别表示年、月、日、时、分、秒及固定填充字节0x23,因此,解析出0x80表示2008年,0x90为09月,0x41为14日,0x51为15时;0x42为24分,0x91为19秒,0x23为固定填充字节;
s5054:查找并解析短信内容:如图5所示,本实施例中,固定填充字节0x23后的1字节内容0x86为短信的实际长度,实际长度0x86后的字节内容为短信内容,短信内容以unicode大端格式存储。
s5055:以数据小段标识0xf0ff的首字节地址为起始位置,判断所解析的字节长度是否超过0x100字节,如果是,结束步骤s505的流程,否则,执行步骤s5056;
s5056:在当前数据小段中查找下一短信标识0x0108或0x0208并执行步骤s5051。
s506:解析通讯录的数据结构,跳转至步骤s508,包括图8所示的以下步骤:
s5061:解析通讯录的条目序号:如图9所示,通讯录标识0x0100的低字节内容0x01为条目序号,表示第1条通讯录;
s5062:解析联系人姓名:条目序号0x0100后为联系人姓名0x2d4e4c88,联系人姓名以unicode小端格式储存并以0x0000为结束符、且长度不超过0x2a字节,如图9所示,该联系人姓名为“中行”;
s5063:解析联系人电话号码:以通讯录标识0x0100的首字节地址为起始位置,向后跳转0x2d字节,顺序读取的内容为联系人电话号码0x3133303931313131353232,联系人电话号码以ascii码格式储存并以0x0000为结束符、且长度不超过0x2a字节,如图9所示,解析出该联系人电话号码为13091111522;
s5064:如图9所示,以数据小段标识0xf0ff的首字节地址为起始位置,判断所解析的字节长度是否超过0x100字节,如果是,结束步骤s506的流程,否则,执行步骤s5065;
s5065:由于通讯录的每一条目的长度为0x56字节,故以当前条目序号0x0100的首字节地址为起始位置,读取0x57字节和0x58字节的内容0x0200作为下一条目序号,执行步骤s5062。
s507:解析通话记录的数据结构,跳转至步骤s508,包括图10所示的以下步骤;
s5071:如图11所示,以数据小段标识0xf0ff的首地址为起始位置,向后跳转0x10字节,顺序读取所述0x10字节至0x1e字节的内容;由于电话号码可能含有+86的前缀,故电话号码需考虑0x10字节至0x1e字节的14个字节内容,此实施例中,顺序读取0x10字节至0x1e字节的内容为0x3033313038393031383039000000。
s5072:图10所示,判断0x10字节的内容是否为ascii码格式存储的“+”号,如果是,执行步骤s5073,否则执行步骤s5074;
s5073:图10所示,判断0x11字节至0x1e字节的内容是否均为ascii码格式存储的数字,如果是,执行步骤s5075,否则结束步骤507的流程;
s5074:图10所示,判断0x10字节至0x12字节的内容是否为ascii码格式存储的数字,如果是,执行步骤s5075,否则结束步骤507的流程;
s5075:查找通话时间:如图11所示,以数据小段标识0xf0ff的首地址为起始位置,向后跳转0x2字节至通话时间的首地址;
s5076:解析通话时间:如图11所示,以当前地址为首地址,顺序读取前十个字节的内容0x15030100d9110200d907,其中,第一字节的内容0x15为秒,表示15秒,第二字节的内容0x03为分,表示3分,第三字节的内容0x01为时,表示1时,第六字节的内容0x11为日,表示11日,第七字节的内容0x02为月,表示2月,秒、分、时、日、月均以十六进制数表示,第九和第十字节的内容0xd907为年并以unicode小端格式存储,即解析为十六进制07d9,表示2009年;
s5077:查找并解析对端号码:如图11所示,以通话时间0x15030100d9110200d907的首地址为起始位置,向后跳转0xe字节,顺序读取0xe字节及其后的字节内容0x3033313038393031383039为对端号码,对端号码以ascii码的数字格式储存、以0x0000为结束标识且长度不超过0x2a字节,本实施例中,对端号码为03108901809;
s5078:以数据小段标识0xf0ff的首字节地址为起始位置,判断所解析的字节长度是否超过0x100字节,如果是,结束步骤s507的流程,否则,执行步骤s5079。
s5079:寻址下一通话记录的通话时间:由于每一通话记录的长度为0x38字节,因此,以当前通话时间的首字节地址为起始位置,跳转0x38字节至下一通话记录的通话时间的首字节地址,并执行步骤s5076。
s508:根据解析结果,将短信、通讯录及通话记录分别进行合并。
s6:判断是否完成有效数据的总管理字段的解析,如果是,执行步骤s7,否则执行步骤s4;如图2所示,在有效数据的总管理字段中,读取下一地址指示0xa704,判断地址指示0xa704的值是否为0xffff,如果是,执行步骤s7,否则执行步骤s4。
s7:判断是否完成字库的解析,如果是,结束流程,否则执行步骤s1。
应当理解的是,本发明不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。