人脸部位运动检测方法和装置及活体识别方法和系统与流程
本发明涉及人脸识别领域,尤其涉及一种人脸部位运动检测方法和装置、活体识别方法和系统。
背景技术:
随着人脸识别技术的发展,越来越多的场景需要用到人脸检测去快速的识别一个人的身份。但是有不法份子会利用图片或者视频代替真人去进行人脸识别,这样整个人脸识别系统的安全性就得不到保证。而人脸活体识别可以检测出当前待测人脸是活体人脸而非照片或者视频中的人脸,从而保证了人脸识别系统的安全性。在进行人脸识别时,可以通过对待测人脸的部位运动的检测有助于识别人脸是否为活体;因而,需要一种简单有效的人脸部位运动检测的技术方案。
技术实现要素:
本发明实施例的目的是提供一种人脸部位运动检测方法,计算效率高,且准确率较高。
为实现上述目的,本发明提供了一种人脸部位运动检测方法,包括:
从待测人脸视频中抽取若干视频帧;
获取从所述待测人脸视频中抽取的每一所述视频帧的待测人脸部位的若干关键点位置;
基于所述待测人脸部位的若干关键点位置,通过分类模型对抽取的每一所述视频帧的待测人脸部位进行预测,从而获取抽取的每一所述视频帧的待测人脸部位的状态值;其中,所述分类模型为通过分类器基于若干预先标注待测人脸部位的状态值的人脸图片训练好的分类模型;
基于抽取的每一所述视频帧的待测人脸部位的状态值的变化程度判断所述待测人脸视频的待测人脸部位运动的情况。
与现有技术相比,本发明从待测人脸视频中获取若干视频帧,然后根据从抽取的每一视频帧中确定待测人脸部位的若干关键点位置,并用预先训练好的分类模型对抽取的每一视频帧的待测人脸部位的状态进行预测,获取视频帧的部位状态值;最后,基于抽取的每一视频帧的待测人脸部位的状态值的变化程度判断待测人脸视频的待测人脸部位运动的情况;该方案采用分类模型基于视频帧的对应部位的关键点位置来预测视频帧的待测人脸部位的状态值,并通过状态值来判断待测人脸视频的部位运动的情况,简单高效,且准确率较高;任何普通摄像头或者移动端手机的摄像头均可作为待测人脸视频的输入硬件,对设备硬件要求简单。
进一步的,所述待测人脸部位为眼部,则,
所述分类模型具体为通过soft-max回归分类器基于若干预先标注所述眼部的状态值的人脸图片训练好的分类模型;
或,所述分类模型具体为通过svm分类器基于若干预先标注所述眼部的状态值的人脸图片训练好的分类模型。
进一步的,所述待测人脸部位为嘴部,则,
所述分类模型具体为通过soft-max回归分类器基于若干预先标注嘴部的状态值的人脸图片训练好的分类模型;
或,所述分类模型具体为通过svm分类器基于若干预先标注嘴部的状态值的人脸图片训练好的分类模型。
进一步的,所述基于抽取的每一所述视频帧的待测人脸部位的状态值的变化程度判断所述待测人脸视频的待测人脸部位运动的情况包括:
计算抽取的每一所述视频帧的待测人脸部位的状态值中的最大值和最小值的差值,若所述差值大于预设阈值,则判定所述待测人脸视频的待测人脸部位有运动。
相应的,本发明还提供一种人脸部位运动检测装置,包括:
视频帧抽取单元,用于从待测人脸视频中抽取若干视频帧;
部位关键点位置检测单元,用于获取从所述待测人脸视频中抽取的每一所述视频帧的待测人脸部位的若干关键点位置;
状态值获取单元,用于基于所述待测人脸部位的若干关键点位置,通过分类模型对抽取的每一所述视频帧的待测人脸部位进行预测,从而获取抽取的每一所述视频帧的待测人脸部位的状态值;其中,所述分类模型为通过分类器基于若干预先标注待测人脸部位的状态值的人脸图片训练好的分类模型;
部位运动判断单元,用于基于抽取的每一所述视频帧的待测人脸部位的状态值的变化程度判断所述待测人脸视频的待测人脸部位运动的情况。
与现有技术相比,本发明通过视频帧抽取单元11从待测人脸视频中获取若干视频帧,然后通过部位关键点位置检测单元12根据从抽取的每一视频帧中确定待测人脸部位的若干关键点位置,并通过状态值获取单元13用预先训练好的分类模型对抽取的每一视频帧的待测人脸部位的状态进行预测,获取对应的视频帧的待测人脸部位的状态值;最后,通过部位运动判断单元14基于抽取的每一视频帧的待测人脸部位的状态值的变化程度判断待测人脸视频的待测人脸部位运动的情况;该装置的计算简单有效,任何普通摄像头或者移动端手机的摄像头均可作为待测人脸视频的输入硬件,对设备硬件要求简单。
进一步的,所述待测人脸部位为眼部,则
所述分类模型具体为通过soft-max回归分类器基于若干预先标注所述眼部的状态值的人脸图片训练好的分类模型;
或,所述分类模型具体为通过svm分类器基于若干预先标注所述眼部的状态值的人脸图片训练好的分类模型。
进一步的,所述待测人脸部位为嘴部,则
所述分类模型具体为通过soft-max回归分类器基于若干预先标注所述嘴部的状态值的人脸图片训练好的分类模型;
或,所述分类模型具体为通过svm分类器基于若干预先标注所述嘴部的状态值的人脸图片训练好的分类模型。
进一步的,所述部位运动判断单元包括:
差值计算模块,用于计算抽取的每一所述视频帧中待测人脸部位的状态值中的最大值和最小值的差值;
部位运动判断模块,用于若差值计算模块计算所得的所述差值大于预设阈值,则所述待测人脸视频的待测人脸部位有运动。
相应的,本发明还提供一种活体识别方法,包括步骤:
检测待测人脸视频中的待测人脸的至少两部位运动的情况,其中,一部位运动采用本发明提供的一种人脸部位运动检测方法检测部位运动的情况;
基于部位运动的情况获取所述待测人脸的每一部位运动对应的运动分值;
计算每一所述部位运动对应的运动分值加权后的总和,并将计算得到的所述总和作为活体识别分值;其中,每一所述部位运动已预设相应的权值;
判定所述活体识别分值不小于预设阈值的所述待测人脸为活体。
与现有技术相比,本发明公开的一种活体识别方法,通过检测待测人脸的至少两部位的运动情况,其中一部位运动的检测采用本发明提供的一种人脸部位运动检测方法;基于每一部位运动的情况获取运动分值,对部位运动分值进行加权后求和作为活体识别分值,利用活体识别分值作为所述待测人脸是否为活体的判断标准的技术方案;其中,本发明提供的一种人脸部位运动检测方法计算过程简单高效,设备硬件要求简单;检测多部位运动解决了现有技术中算法单一,安全性不高的问题,可扩展性强,且基于人脸部位运动的检测可以通过二维图像实现,对硬件要求不高;另外,采用对不同部位运动加权再进行分数融合,活体识别准确度高,本活体识别方法准确率高、硬件要求低和安全性高。
相应的,本发明还提供一种活体识别系统,包括:
至少2个人脸部位运动检测装置,每一所述人脸部位运动检测装置用于检测待测人脸对应的部位运动的情况,其中一人脸部位运动检测装置为本发明提供的一种人脸部位运动检测装置;
部位运动分值获取装置,用于基于每一所述部位运动的情况获取所述待测人脸的每一部位运动对应的运动分值;
活体识别分值计算装置,用于计算每一所述部位运动对应的运动分值加权后的总和,并将计算得到的所述总和作为活体识别分值;其中,所述活体识别分值计算装置已预设与每一所述部位运动相对应的权值;
活体判断装置,用于判定所述活体识别分值不小于预设阈值的所述待测人脸为活体。
与现有技术相比,本发明公开的一种活体识别系统通过至少2个人脸部位运动检测装置获取所述待测人脸上的至少两个部位的运动分值,其中,一人脸部位运动检测装置采用本发明提供的一种人脸部位运动检测装置;通过活体识别分值计算装置对部位运动分值进行加权后求和作为活体识别分值,通过活体判断装置利用活体识别分值作为所述待测人脸是否为活体的判断标准的技术方案;本发明提供的一种人脸部位运动检测装置计算简单高效,设备硬件要求简单;采用检测至少两种部位运动装置检测至少两种部位的运动情况解决了现有技术中算法单一,安全性不高的问题,可扩展性强,且基于人脸部位运动的检测可以通过二维图像实现,对硬件要求不高,另外,通过活体识别分值计算装置对不同部位运动加权再进行分数融合,活体识别准确度高,获得了活体识别准确率高、硬件要求低和安全性高的有益效果。
附图说明
图1是本发明一种人脸部位运动检测方法提供的实施例一的流程示意图;
图2是本发明一种人脸部位运动检测方法提供的实施例一的步骤s14的流程示意图;
图3是本发明一种人脸部位运动检测方法提供的实施例一的步骤s12的流程示意图;
图4是待测人脸的68个关键点的模型示意图;
图5是本发明一种人脸部位运动检测装置提供的实施例一的结构示意图;
图6是本发明一种活体识别方法提供的实施例的流程示意图;
图7是本发明一种活体识别方法提供的实施例的步骤s24流程示意图;
图8是本发明一种活体识别系统提供的实施例的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明一种人脸部位运动检测方法提供的实施例一,参见图1,图1是本实施例一的流程示意图,包括步骤:
s11、从待测人脸视频中抽取若干视频帧;
s12、获取从待测人脸视频中抽取的每一视频帧的待测人脸部位的若干关键点位置;
s13、基于待测人脸部位的若干关键点位置,通过分类模型对抽取的每一视频帧的待测人脸部位进行预测,从而获取抽取的每一视频帧的待测人脸部位的状态值;其中,分类模型为通过分类器基于若干预先标注待测人脸部位的状态值的人脸图片训练好的分类模型;
s14、基于抽取的每一视频帧的待测人脸部位的状态值的变化程度判断待测人脸视频的待测人脸部位运动的情况。
在本实施例中,所检测的待测人脸部位为眼部;则对应的,在步骤s13中所采用的预先训练好的分类模型有两种:
第一种分类模型为通过soft-max回归分类器基于若干预先标注眼部的状态值的人脸图片训练好的分类模型;具体,若干预先标注眼部的状态值的人脸图片为根据眼部睁开的不同程度进行眼部的状态值标注的人脸图片。示例,按照眼部的睁开程度给眼部标注分数,以标注的分数来表示眼部的状态值,分数分为10级,取值在0到1之间,完全闭眼为0分,完全睁开为1分,半睁眼为0.5分;对若干已标注的眼部的状态值的人脸图片的眼部进行关键点检测,以获取每一人脸图片的眼部的关键点位置;然后以每一人脸图片的眼部关键点位置为特征,采用soft-max回归分类器训练一个分类模型;该分类模型用于步骤s12中对抽取的每一视频帧的待测人脸的眼部进行预测,从而获抽取的每一视频帧的眼部的分数,即眼部的状态值。
第二种分类模型为通过svm分类器基于若干预先标注眼部的状态值的人脸图片训练好的分类模型,具体,若干预先标注眼部的状态值的人脸图片标注的眼部的状态值包括两类。示例,人工选择一定数量睁眼的人脸图片,标注人脸图片的眼部的状态值为1,然后人工选择一定数量的闭眼的人脸图片,标注人脸图片的眼部状态为0,对若干已标注的眼部的状态值的人脸图片的眼部进行关键点检测,以获取每一人脸图片的眼部的关键点位置;然后以每一人脸图片的眼部关键点位置为特征,采用svm分类器训练一个分类模型;该分类模型用于步骤s12中对抽取的每一视频帧的待测人脸的眼部进行预测,从而获取抽取的每一视频帧的眼部的状态值。
上述两种实施方式均在本实施例的保护范围之内。
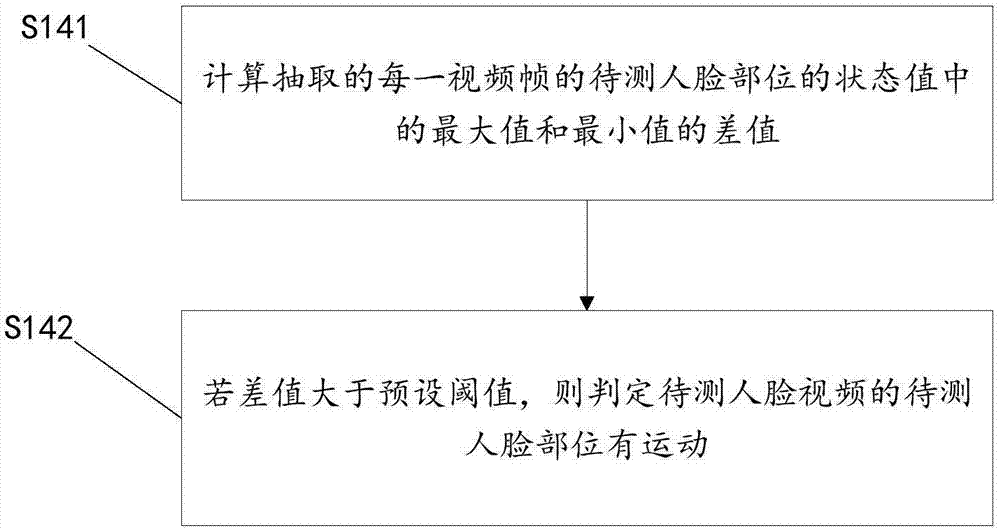
参见图2,图2为本实施例的步骤s14流程示意图,步骤s14包括:
s141、计算抽取的每一视频帧的待测人脸部位的状态值中的最大值和最小值的差值;
s142、若差值大于预设阈值,则判定待测人脸视频的待测人脸部位有运动。
由于本实施例检测的部位运动为眼部运动,则通过步骤s142判断的待测人脸视频的待测人脸的对应部位为眼部,此处,若当步骤s13中采用的分类模型为svm分类器时,示例,当预先标注眼部的状态值的人脸图片的眼部状态值包括1和0两类状态值时,此时步骤s142对应设置的预设阈值为1;即可对应检测待测人脸视频帧中是否同时包括眼部为睁开状态的视频帧和眼部为闭眼状态的视频帧,从而判断待测人脸视频帧的是否有运动。
步骤s11优选从待测人脸视频中抽取每一视频帧;或,步骤s11按照一定的频率抽取视频帧。
参见图3,图3是步骤s12的流程示意图,步骤s12具体包括:
s121、对从待测人脸视频中抽取的每一视频帧用dlib库做人脸检测和人脸关键点检测,获取待测人脸的若干关键点位置;
参见图4,图4是采用dlib库做人脸检测和人脸关键点检测获取的待测人脸的68点模型示意图;步骤s121中获取的若干人脸关键点位置即为图4中关键点1~关键点68所示的关键点位置;
s122、从每一抽取的视频帧的若干人脸关键点中获取待测人脸部位的若干关键点位置。
由于本实施例的待测人脸部位为,则通过步骤s122获取待测人脸部位的若干关键点位置为眼部的若干关键点位置,图4中,步骤s122获取的眼部的若干关键点位置即为关键点37~关键点48这12个关键点所示的关键点位置;其中,左眼的若干关键点位置为关键点37~关键点42这6个关键点所示的关键点位置,右眼的若干关键点位置为关键点43~关键点48这6个关键点所示的关键点位置。
另外,在获取分类模型的预设步骤中,对若干已标注的眼部的状态值的人脸图片的眼部进行关键点检测,以获取每一人脸图片的眼部的关键点位置的步骤可以参照本实施例步骤s12的过程,采用dlib库获取人脸图片的眼部的关键点位置,此处不赘述。
具体实施时,本实施例从待测人脸视频中获取若干视频帧,然后根据从抽取的每一视频帧中确定待测人脸的眼部的若干关键点位置,并通过预先训练好的分类模型对抽取的每一视频帧的眼部的状态进行预测,获取对应的视频帧的眼部状态值;最后,通过计算抽取的每一视频帧的眼部的状态值中的最大值和最小值的差值,并判定差值大于预设阈值的待测人脸视频的待测人脸的眼部有运动。
与现有技术相比,本实施例采用分类模型基于视频帧的眼部的关键点位置来预测视频帧的状态值,并通过视频帧的状态值来判断待测人脸视频的眼部运动的情况,简单高效,且准确率较高;任何普通摄像头或者移动端手机的摄像头均可作为待测人脸视频的输入硬件,对设备硬件要求简单。
本发明一种人脸部位运动检测方法提供的实施例二,由于本实施例与本发明一种人脸部位运动检测方法提供的实施例一的主要流程相似,可参见图1的流程示意图,包括步骤:
s11、从待测人脸视频中抽取若干视频帧;
s12、获取从待测人脸视频中抽取的每一视频帧的待测人脸部位的若干关键点位置;
s13、基于待测人脸部位的若干关键点位置,通过分类模型对抽取的每一视频帧的待测人脸部位进行预测,从而获取抽取的每一视频帧的待测人脸部位的状态值;其中,分类模型为通过分类器基于若干预先标注待测人脸部位的状态值的人脸图片训练好的分类模型;
s14、基于抽取的每一视频帧的待测人脸部位的状态值的变化程度判断待测人脸视频的待测人脸部位运动的情况。
在本实施例中,所检测的待测人脸部位为嘴部;则对应的,在步骤s13中所采用的预先训练好的分类模型有两种:
第一种分类模型为通过soft-max回归分类器基于若干预先标注嘴部的状态值的人脸图片训练好的分类模型;具体,若干预先标注嘴部的状态值的人脸图片为根据嘴部张开的不同程度进行嘴部的状态值标注的人脸图片。示例,按照嘴部的张开程度给嘴部标注分数,以标注的分数来表示嘴部的状态值,分数分为10级,取值在0到1之间,完全闭合为0分,完全张开为1分,半张嘴为0.5分;对若干已标注的嘴部的状态值的人脸图片的嘴部进行关键点检测,以获取每一人脸图片的嘴部的关键点位置;然后以每一人脸图片的嘴部关键点位置为特征,采用soft-max回归分类器训练一个分类模型;该分类模型用于步骤s12中对抽取的每一视频帧的待测人脸的嘴部进行预测,从而获取抽取的每一视频帧的嘴部的分数,即嘴部的状态值。
第二种分类模型为通过svm分类器基于若干预先标注嘴部的状态值的人脸图片训练好的分类模型,具体,若干预先标注嘴部的状态值的人脸图片标注的嘴部的状态值包括两类。示例,人工选择一定数量张嘴的人脸图片,标注人脸图片的嘴部的状态值为1,然后人工选择一定数量的闭合的人脸图片,标注人脸图片的嘴部状态为0,对若干已标注的嘴部的状态值的人脸图片的嘴部进行关键点检测,以获取每一人脸图片的嘴部的关键点位置;然后以每一人脸图片的嘴部关键点位置为特征,采用svm分类器训练一个分类模型;该分类模型用于步骤s12中对抽取的每一视频帧的待测人脸的嘴部进行预测,从而获取抽取的每一视频帧的嘴部的状态值。
上述两种实施方式均在本实施例的保护范围之内。
本实施例的步骤s14与本发明一种人脸部位运动检测方法的步骤s14相似,可以参见图2的流程示意图,步骤s14包括:
s141、计算抽取的每一视频帧的待测人脸部位的状态值中的最大值和最小值的差值;
s142、若差值大于预设阈值,则判定待测人脸视频的待测人脸部位有运动。
由于本实施例检测的部位运动为嘴部运动,则通过步骤s142判断的待测人脸视频的待测人脸的对应部位为嘴部。此处,若当步骤s13中采用的分类模型为svm分类器时,示例,当预先标注嘴部的状态值的人脸图片的嘴部状态值包括1和0两类状态值时,此时步骤s142对应设置的预设阈值为1;即可对应检测待测人脸视频帧中是否同时包括嘴部为张开状态的视频帧和嘴部为闭眼状态的视频帧,从而判断待测人脸视频帧的是否有运动。
步骤s11优选从待测人脸视频中抽取每一视频帧;或,步骤s11按照一定的频率抽取视频帧。
本实施例的步骤s12与本发明一种人脸部位运动检测方法的步骤s12相似,可以参见图3的流程示意图,参见图3,图3是步骤s12的流程示意图,步骤s12具体包括:
s121、对从待测人脸视频中抽取的每一视频帧用dlib库做人脸检测和人脸关键点检测,获取待测人脸的若干关键点位置;
dlib库指的是一个使用c++技术编写的跨平台的通用库。
参见图4,图4是采用dlib库做人脸检测和人脸关键点检测获取的待测人脸的68点模型图;步骤s121中获取的若干人脸关键点位置即为图4中关键点1~关键点68所示的关键点位置;
s122、从每一抽取的视频帧的若干人脸关键点中获取待测人脸部位的若干关键点位置。
由于本实施例的待测人脸部位为嘴部,则通过步骤s122获取待测人脸部位的若干关键点位置为嘴部的若干关键点位置;获取的嘴部的若干关键点位置即为图4中关键点49~关键点68这20个关键点所示的关键点位置。
具体实施时,本实施例从待测人脸视频中获取若干视频帧,然后根据从抽取的每一视频帧中确定待测人脸的嘴部的若干关键点位置,并通过预先训练好的分类模型对抽取的每一视频帧的嘴部的状态进行预测,获取对应的视频帧的嘴部状态值;最后,通过计算抽取的每一视频帧的嘴部的状态值中的最大值和最小值的差值,并判定差值大于预设阈值的待测人脸视频的待测人脸的嘴部有运动。
与现有技术相比,本实施例采用分类模型基于视频帧的嘴部的关键点位置来预测视频帧的状态值,并通过视频帧的状态值来判断待测人脸视频的嘴部运动,简单高效,且准确率较高;任何普通摄像头或者移动端手机的摄像头均可作为待测人脸视频的输入硬件,对设备硬件要求简单。
本发明一种人脸部位运动检测装置提供的实施例一,参见图5,图5是本实施例一的结构示意图,包括:
视频帧抽取单元11,用于从待测人脸视频中抽取若干视频帧;
部位关键点位置检测单元12,用于获取从所述待测人脸视频中抽取的每一所述视频帧的待测人脸部位的若干关键点位置;
状态值获取单元13,用于基于所述待测人脸部位的若干关键点位置,通过分类模型对抽取的每一所述视频帧的待测人脸部位进行预测,从而获取抽取的每一所述视频帧的待测人脸部位的状态值;其中,所述分类模型为通过分类器基于若干预先标注待测人脸部位的状态值的人脸图片训练好的分类模型;
部位运动判断单元14,用于基于抽取的每一所述视频帧的待测人脸部位的状态值的变化程度判断所述待测人脸视频的待测人脸部位运动的情况。
本实施例,所检测的待测人脸部位为眼部;则对应的,在状态值获取单元13中所采用的预先训练好的分类模型有两种:
第一种分类模型为通过soft-max回归分类器基于若干预先标注眼部的状态值的人脸图片训练好的分类模型;具体,若干预先标注眼部的状态值的人脸图片为根据眼部睁开的不同程度进行眼部的状态值标注的人脸图片。示例,按照眼部的睁开程度给眼部标注分数,以标注的分数来表示眼部的状态值,分数分为10级,取值在0到1之间,完全闭眼为0分,完全睁开为1分,半睁眼眼为0.5分;对若干已标注的眼部的状态值的人脸图片的眼部进行关键点检测,以获取每一人脸图片的眼部的关键点位置;然后以每一人脸图片的眼部关键点位置为特征,采用soft-max回归分类器训练一个分类模型;该分类模型用于步骤s12中对抽取的每一视频帧的待测人脸的眼部进行预测,从而获取抽取的每一视频帧的眼部的分数,即眼部的状态值。
第二种分类模型为通过svm分类器基于若干预先标注眼部的状态值的人脸图片训练好的分类模型,具体,若干预先标注眼部的状态值的人脸图片标注的眼部的状态值包括两类。示例,人工选择一定数量睁眼的人脸图片,标注人脸图片的眼部的状态值为1,然后人工选择一定数量的闭眼的人脸图片,标注人脸图片的眼部状态为0,对若干已标注的眼部的状态值的人脸图片的眼部进行关键点检测,以获取每一人脸图片的眼部的关键点位置;然后以每一人脸图片的眼部关键点位置为特征,采用svm分类器训练一个分类模型;该分类模型用于步骤s12中对抽取的每一视频帧的待测人脸的眼部进行预测,从而获取抽取的每一视频帧的眼部的状态值。
上述两种实施方式可任选一种,均在本实施例的保护范围之内。
部位运动判断单元14具体包括:
差值计算模块141,用于计算抽取的每一视频帧的待测人脸部位的状态值中的最大值和最小值的差值;
部位运动判断模块142,用于若差值大于预设阈值,则判定待测人脸视频的待测人脸的眼部有运动。
此处,若当状态值获取单元13中采用的分类模型为svm分类器时,示例,当预先标注眼部的状态值的人脸图片的眼部状态值包括1和0两类时,此时步骤部位运动判断模块142对应设置的预设阈值为1;即可对应检测待测人脸视频帧中是否同时包括眼部为睁开状态的视频帧和眼部为闭眼状态的视频帧,从而判断待测人脸视频帧的是否有运动。
优选,视频帧抽取单元11用于从待测人脸视频中抽取每一视频帧;或,视频帧抽取单元11用于按照一定的频率抽取视频帧。
具体,部位关键点位置检测单元12包括:
人脸关键点检测模块121,用于对从待测人脸视频中抽取的每一视频帧用dlib库做人脸检测和人脸关键点检测,获取待测人脸的若干关键点位置;
参见图4,通过人脸关键点检测模块121获取的若干人脸关键点位置即为图4中关键点1~关键点68所示的关键点位置;
部位关键点位置检测模块122,用于从每一抽取的视频帧的若干人脸关键点中获取待测人脸部位的若干关键点位置。
由于本实施例的待测人脸部位为眼部,则通过部位关键点位置检测模块122获取的待测人脸部位的若干关键点位置为眼部的若干关键点位置。图4中,眼部的若干关键点位置即为关键点37~关键点48这12个关键点所示的关键点位置;其中,左眼的若干关键点位置为关键点37~关键点42这6个关键点所示的关键点位置,右眼的若干关键点位置为关键点43~关键点48这6个关键点所示的关键点位置。
类似的,状态值获取单元13采用的分类模型中若干已标注的眼部的状态值的人脸图片预先进行的眼部的关键点检测,以获取每一人脸图片的眼部的关键点位置的过程与部位关键点位置12获取部位关键点位置的过程相似,此处不赘述。
具体实施时,本实施例通过视频帧抽取单元11从待测人脸视频中获取若干视频帧,然后通过部位关键点位置检测单元12根据从抽取的每一视频帧中确定待测人脸的眼部的若干关键点位置,并通过状态值获取单元13用预先训练好的分类模型对抽取的每一视频帧的眼部的状态进行预测,获取对应的视频帧的眼部状态值;最后,通过部位运动判断单元14计算抽取的每一视频帧的眼部的状态值中的最大值和最小值的差值,并判定差值大于预设阈值的待测人脸视频的待测人脸的眼部有运动。
与现有技术相比,本实施例采用分类模型基于视频帧的眼部的关键点位置来预测视频帧的状态值,并通过视频帧的状态值来判断待测人脸视频的眼部运动的情况,简单高效,且准确率较高;任何普通摄像头或者移动端手机的摄像头均可作为待测人脸视频的输入硬件,对设备硬件要求简单。
本发明一种人脸部位运动检测装置提供的实施例二,由于本实施例与本发明一种人脸部位运动检测装置提供的实施例一的主要流程相似,可参见图5,包括:
视频帧抽取单元11,用于从待测人脸视频中抽取若干视频帧;
部位关键点位置检测单元12,用于获取从所述待测人脸视频中抽取的每一所述视频帧的待测人脸部位的若干关键点位置;
状态值获取单元13,用于基于所述待测人脸部位的若干关键点位置,通过分类模型对抽取的每一所述视频帧的待测人脸部位进行预测,从而获取抽取的每一所述视频帧的待测人脸部位的状态值;其中,所述分类模型为通过分类器基于若干预先标注待测人脸部位的状态值的人脸图片训练好的分类模型;
部位运动判断单元14,用于基于抽取的每一所述视频帧的待测人脸部位的状态值的变化程度判断所述待测人脸视频的待测人脸部位运动的情况。
本实施例,所检测的待测人脸部位为嘴部;则对应的,在状态值获取单元13中所采用的预先训练好的分类模型有两种:
第一种分类模型为通过soft-max回归分类器基于若干预先标注嘴部的状态值的人脸图片训练好的分类模型;具体,若干预先标注嘴部的状态值的人脸图片为根据嘴部张开的不同程度进行嘴部的状态值标注的人脸图片。示例,按照嘴部的张开程度给嘴部标注分数,以标注的分数来表示嘴部的状态值,分数分为10级,取值在0到1之间,完全闭合为0分,完全张开为1分,半张嘴为0.5分;对若干已标注的嘴部的状态值的人脸图片的嘴部进行关键点检测,以获取每一人脸图片的嘴部的关键点位置;然后以每一人脸图片的嘴部关键点位置为特征,采用soft-max回归分类器训练一个分类模型;该分类模型用于步骤s12中对抽取的每一视频帧的待测人脸的嘴部进行预测,从而获取抽取的每一视频帧的嘴部的分数,即嘴部的状态值。
第二种分类模型为通过svm分类器基于若干预先标注嘴部的状态值的人脸图片训练好的分类模型,具体,若干预先标注嘴部的状态值的人脸图片标注的嘴部的状态值包括两类。示例,人工选择一定数量张嘴的人脸图片,标注人脸图片的嘴部的状态值为1,然后人工选择一定数量的闭合的人脸图片,标注人脸图片的嘴部状态为0,对若干已标注的嘴部的状态值的人脸图片的嘴部进行关键点检测,以获取每一人脸图片的嘴部的关键点位置;然后以每一人脸图片的嘴部关键点位置为特征,采用svm分类器训练一个分类模型;该分类模型用于步骤s12中对抽取的每一视频帧的待测人脸的嘴部进行预测,从而获取抽取的每一视频帧的嘴部的状态值。
上述两种实施方式可任选一种,均在本实施例的保护范围之内。
部位运动判断单元14具体包括:
差值计算模块141,用于计算抽取的每一视频帧的待测人脸部位的状态值中的最大值和最小值的差值;
部位运动判断模块142,用于若差值大于预设阈值,则判定待测人脸视频的待测人脸的嘴部有运动。
此处,若当状态值获取单元13中采用的分类模型为svm分类器时,示例,当预先标注嘴部的状态值的人脸图片的嘴部状态值包括1和0两类时,此时步骤部位运动判断模块142对应设置的预设阈值为1;即可对应检测待测人脸视频帧中是否同时包括嘴部为张开状态的视频帧和嘴部为闭合状态的视频帧,从而判断待测人脸视频帧的是否有运动。
优选视频帧抽取单元11用于从待测人脸视频中抽取每一视频帧;或,视频帧抽取单元11用于按照一定的频率抽取视频帧。
具体,部位关键点位置检测单元12包括:
人脸关键点检测模块121,用于对从待测人脸视频中抽取的每一视频帧用dlib库做人脸检测和人脸关键点检测,获取待测人脸的若干关键点位置;
参见图4,通过人脸关键点检测模块121获取的若干人脸关键点位置即为图4中关键点1~关键点68所示的关键点位置;
部位关键点位置检测模块122,用于从每一抽取的视频帧的若干人脸关键点中获取对应部位的若干关键点位置。
由于本实施例的待测人脸部位为嘴部,则通过部位关键点位置检测模块122获取的待测人脸部位的若干关键点位置为嘴部的若干关键点位置;参见图4,获取的嘴部的若干关键点位置即为中关键点49~关键点68这20个关键点所示的关键点位置。
类似的,状态值获取单元13采用的分类模型中若干已标注的嘴部的状态值的人脸图片预先进行的嘴部的关键点检测,以获取每一人脸图片的嘴部的关键点位置的过程与部位关键点位置12获取部位关键点位置的过程相似,此处不赘述。
具体实施时,本实施例通过视频帧抽取单元11从待测人脸视频中获取若干视频帧,然后通过部位关键点位置检测单元12根据从抽取的每一视频帧中确定待测人脸的嘴部的若干关键点位置,并通过状态值获取单元13用预先训练好的分类模型对抽取的每一视频帧的嘴部的状态进行预测,获取对应的视频帧的嘴部状态值;最后,通过部位运动判断单元14计算抽取的每一视频帧的嘴部的状态值中的最大值和最小值的差值,并判定差值大于预设阈值的待测人脸视频的待测人脸的嘴部有运动。
与现有技术相比,本实施例采用分类模型基于视频帧的嘴部的关键点位置来预测视频帧的状态值,并通过视频帧的状态值来判断待测人脸视频的嘴部运动的情况,简单高效,且准确率较高;任何普通摄像头或者移动端手机的摄像头均可作为待测人脸视频的输入硬件,对设备硬件要求简单。
本发明一种活体识别方法提供的实施例,参见图6,图6是本实施例的流程示意图,其中,本实施例具体包括步骤:
s21、检测待测人脸视频中的待测人脸的至少两部位运动的情况,其中,一部位运动的检测采用本发明一种人脸部位运动检测方法提供的实施例一,对应检测的部位运动为眼部运动的情况,或,至少一部位运动的检测采用本发明一种人脸部位运动检测方法提供的实施例二,对应检测的部位运动为嘴部运动的情况,具体过程可以参见本发明一种人脸部位运动检测方法提供的实施例一或实施例二,此处不做赘述;
s22、基于部位运动的情况获取待测人脸的每一部位运动对应的运动分值;
s23、计算每一部位运动对应的运动分值加权后的总和,并将计算得到的总和作为活体识别分值;其中,每一部位运动已预设相应的权值;
s24、判定活体识别分值不小于预设阈值的待测人脸为活体。
示例,本实施例步骤s21中除了采用本发明一种人脸部位运动检测方法提供的实施例一检测眼部运动和/或采用本发明一种人脸部位运动检测方法提供的实施例二检测嘴部运动的检测,步骤s21还可以检测其它的部位运动为头部运动、面部运动、额头运动和眉毛运动中的至少一种;通常来说,头部运动包括头部是否转动;面部运动包括人脸部位的整体变化,如鬼脸动作,人脸的眼部和嘴部的整体变化程度超过预设条件;眉毛运动包括眉毛是否抖动;额头运动包括额头区域的皱纹有无变化。
示例,步骤s21中检测待测人脸的其它至少一个部位运动具体包括:检测待测人脸的人脸视频每隔预设帧数所抽取的每一视频帧检测部位运动对应的部位关键点位置,通过抽取的每一视频帧的部位关键点位置的变化程度来确定部位运动的情况;或者,检测待测人脸每隔预设帧数所抽取的每一视频帧检测部位运动对应的部位灰度值特征,通过抽取的每一视频帧的部位的灰度值的变化程度来确定部位运动的情况。上述实施方法仅为检测其它至少一个部位运动的示例;基于本实施例的活体识别方法的原理基础上,通过其它具体的实施方式实现对另外至少一部位运动的运动检测,也在本实施例的保护范围之内。
本实施例的步骤s23中设定每一部位运动相对应的权值的优选实施方式为根据每一部位运动的明显度设定。示例,当步骤s21检测待测人脸视频中的待测人脸的部位运动为眼部运动、嘴部运动和头部运动;嘴部运动比较明显,故权重最大,眼部次之,头部运动的模拟精度最小,那么,对应设置部位运动的权重策略为:嘴部运动>眼部运动>额头皱纹动作;
或,步骤s23中设定每一部位运动相对应的权值的另一优选实施方式为根据不同应用场景自动进行部位运动的权值调整而设定的,具体做法:在某一种场景下,收集待测人脸的各种部位运动的正常输入视频作为正样本,攻击视频作为负样本,取(正样本通过数+负样本拒绝数)/(正样本总数+负样本总数)作为该部位运动的准确率,然后把每一部位运动的准确率按照从大到小的顺序进行排序,每一部位运动的权重也按照此顺序从大到小,重新调整每一部位运动的权重。重新调整后的权重用以计算活体识别分值,该识别结果可以自适应不同场景下的部位运动检测的准确率,增加本实施例的活体识别结果的准确率。
上述两种设定每一部位运动相对应的权值的任一种优选实施方式均在本实施例的保护范围内。
具体地,参见图7,图7是步骤s24的流程示意图,包括步骤:
s241、通过活体识别分值占活体识别总分的比值计算待测人脸的活体识别置信度;
s242、当活体识别置信度不小于预设值时,确定活体识别分值不小于预设阈值;
s243、判定活体识别分值不小于预设阈值的待测人脸为活体。
具体地,在步骤s241中,活体识别总分即为本实施例对待测人脸进行识别后能获得的最大值,待测人脸的活体识别置信度通过下述公式计算:
f=(s/s_max)*100%
其中,s_max表示活体识别总分,f表示活体识别置信度,且0<f<1;
用e表示预设值,当f≥e,即活体识别置信度不小于预设值时,则确定活体识别分值不小于预设阈值,判定活体识别分值不小于预设阈值的待测人脸为活体;当f<e,即活体识别置信度小于预设值时,则确定活体识别分值小于预设阈值,判定活体识别分值小于预设阈值的待测人脸为非活体。
利用活体识别分值所获得的活体识别置信度,还可以进一步扩展,用于本实施例建立分级制度进行活体判断和活体分级,以获得丰富的活体识别结果。
步骤s22基于部位运动的情况获取待测人脸的每一部位运动对应的运动分值包括:
当步骤s21中的检测待测人脸的对应运动情况为待测人脸的对应部位有运动,则获取的对应部位运动的运动分值为1分;否则获取的运动分值为0分。
除了通过有无运动的判断获取对应的运动分值,若在步骤s21中所获取的部位运动的运动情况为部位运动的运动程度,还可以根据其运动程度在分值区间中获取对应的运动分值,如设定分数分为10级,取值在0到1之间。
具体实施时,检测待测人脸视频部位运动从而获得对应的部位的运动情况,其中,一部位运动的检测采用本发明提供的一种人脸部位运动检测方法的实施例一或实施例二;根据每一部位运动的情况获取对应的运动分值,具体为该部位运动有运动,则获取的运动分值为1分,否则获取的运动分值为0分;接着计算上述得到每一部位运动分值进行加权后的总和,该总和表示活体识别分值;最后用该活体识别分值占活体识别总分的比值计算活体识别置信度,其中,当活体识别置信度不小于预设值时,确定活体识别分值不小于预设阈值,从而判定待测人脸为活体;否则,判定待测人脸为非活体。
本实施例可运用于多种设备端,此处以运用于移动手机端的实施场景为例进行说明:在手机端活体识别时,随机出现一种活体动作要求顺序,例如为要求待测人脸分别进行张嘴、眨眼和头部左转的活体动作;此时若预设的部位运动的权重为:张嘴对应的嘴部运动的权重w1=3,眨眼对应的眼部运动的权重w2=2,头部左转对应的运动的权重w3=1;计算活体识别总分,即活体识别最高分s_max为3*1+2*1+1*1=6分。假设检测出张嘴得分为1分,眨眼得分为1分,头部左转得分为0分,活体识别分值s为每一部位运动加权后的总和,代入上述部位运动的运动分值,计算活体识别分值s=3*1+2*1+1*0=5分;最后,计算活体识别置信度f=s/s_max=5/6=83.33%。若设定此时设定值e为80%,则判定该待测人脸为活体,且活体置信度为83.33%。
本实施例解决了现有技术中算法单一,安全性不高的问题,可扩展性强;其中采用的本发明提供的一种人脸部位运动检测方法的实施例一或实施例二的计算简单高效,对设备的硬件要求不高;另外,在本实施例中采用对多个部位运动的检测来进行活体识别,并对不同部位运动加权再进行分数融合,活体识别准确度高,且有利于提高安全性。
本发明一种活体识别系统提供的实施例,参见图8,图8为本实施例的结构示意图,本实施例包括:
至少2个人脸部位运动检测装置1,每一个人脸部位运动检测装置1用于检测待测人脸一对应的部位运动的情况;图8中的人脸部位运动检测装置1a和人脸部位运动检测装置1b表示检测两不同人脸的部位运动的两人脸部位运动检测装置1;其中1个人脸部位运动检测装置1采用本发明一种人脸部位运动检测装置提供的实施例一或实施例二,可参见图5,此处不做赘述。
部位运动分值获取装置2,用于基于每一部位运动的情况获取待测人脸的每一部位运动对应的运动分值;
活体识别分值计算装置3,用于计算每一部位运动对应的运动分值加权后的总和,并将计算得到的总和作为活体识别分值;其中,活体识别分值计算装置3已预设与每一部位运动相对应的权值;
活体判断装置4,用于判定活体识别分值不小于预设阈值的待测人脸为活体。
除采用本发明一种人脸部位运动检测装置提供的实施例一对应检测眼部运动或采用本发明一种人脸部位运动检测装置提供的实施例二对应检测嘴部运动外,示例,另外一人脸部位运动检测装置1对应检测的待测人脸的部位运动包括头部运动、眉毛运动、额头运动和面部运动中的至少一部位运动;通常头部运动包括头部是否转动;眉毛运动包括眉毛是否有抖动动作;额头运动包括额头区域的皱纹有无变化;面部运动包括人脸部位的整体变化,如鬼脸动作,人脸的眼部和嘴部的整体变化程度超过预设条件。
示例,另外至少一人脸部位运动检测装置1具体用于检测待测人脸的人脸视频每隔预设帧数所抽取的每一视频帧检测部位运动对应的部位关键点位置,通过抽取的每一视频帧的部位关键点位置的变化程度来确定部位运动的情况;或者,人脸部位运动检测装置1还可以具体用于检测待测人脸每隔预设帧数所抽取的每一视频帧检测部位运动对应的部位灰度值特征,通过抽取的每一视频帧的部位的灰度值的变化程度来确定部位运动的情况,该实施方式通常适用于人脸部位运动检测装置1检测的部位运动为眼部运动或额头运动。上述实施方法仅为另外至少一人脸部位运动检测装置1检测部位运动的示例,当人脸部位运动检测装置1通过其他实施方式实现对另外至少一部位运动的运动检测,也在本实施例的保护范围之内。
部位运动分值获取装置2具体用于基每一部位运动的运动情况获取对应的运动分值:当待测人脸的对应的部位运动情况为有运动,则获取的对应部位运动的运动分值为1分;否则获取的运动分值为0分。
除上述部位运动分值获取装置2用于基于每一部位运动的是否有运动的情况而直接获得一个是否有运动的运动分值的实施方式,当通过人脸部位运动检测装置1中获取的部位运动的运动情况包括部位运动的运动程度,还可以通过部位运动分值获取装置2基于运动程度而获取一个在0到1之间的运动分值,如设定运动分值分为10级,取值在0到1之间,该替代实施方式不仅能表示是否有运动,还能体现运动的程度。
活体识别分值计算装置3中与每一部位运动相对应的权值为根据每一部位运动的明显度设定;如检测的部位运动为头部运动、眼部运动和嘴部运动时,此时,嘴部运动比较明显,故权重最大,眼部运动次之,头部运动权重最小,部位运动的权重策略对应为:嘴部运动>眼部运动>头部运动。
或,活体识别分值计算装置3中与每一部位运动相对应的权值为根据不同应用场景自动进行部位运动的权值调整而设定的,具体做法:在某一种场景下,收集待测人脸的各种部位运动的正常输入视频作为正样本,攻击视频作为负样本,取(正样本通过数+负样本拒绝数)/(正样本总数+负样本总数)作为该部位运动的准确率,然后把每一部位运动的准确率按照从大到小的顺序进行排序,每一部位运动的权重也按照此顺序从大到小,重新调整每一部位运动的权重。
上述两种设定每一部位运动相对应的权值的任一种优选实施方式均在本实施例的保护范围内。
活体判断装置4包括:
活体识别置信度计算单元41,用于通过活体识别分值占活体识别总分的比值计算待测人脸的活体识别置信度;
其中,活体识别总分即为通过活体识别分值计算装置3获取的所有部位运动的运动分值加权后的总和的最大值,活体识别总分用s_max表示;f表示活体识别置信度,且0<f<1;活体识别置信度计算单元41通过下述公式计算待测人脸的活体识别置信度:
f=(s/s_max)*100%
活体判断单元42,用于当活体识别置信度不小于预设值时,确定活体识别分值不小于预设阈值,判定活体识别分值不小于预设阈值的待测人脸为活体。
其中,用e表示预设值,通过活体判断单元42判断:当f≥e,即活体识别置信度不小于预设值时,则确定活体识别分值不小于预设阈值,判定活体识别分值不小于预设阈值的待测人脸为活体;当f<e,即活体识别置信度小于预设值时,则确定活体识别分值小于预设阈值,判定活体识别分值小于预设阈值的待测人脸为非活体。
通过活体识别置信度计算单元41所获得的活体识别置信度,还可以进一步扩展,用于本实施例活体识别系统建立分级制度进行活体判断和活体分级,以获得丰富的活体识别结果。
具体实施时,首先,通过每一人脸部位运动检测装置1获取对应的部位运动的运动的情况,其中,一人脸部位运动检测装置1为本发明一种人脸部位运动检测装置的实施例一或实施例二;并通过部位运动分值获取装置2基于部位运动的运动情况获取对应的运动分值;然后,通过活体识别分值计算装置3对获取的每一部位运动的运动分值进行加权后求和作为活体识别分值,最后,通过活体判断装置4的活体识别置信度计算单元41利用活体识别分值占活体识别总分的比值计算待测人脸的活体识别置信度,并通过活体判断单元42判定当计算所得的活体识别置信度不小于预设阈值的待测人脸为活体。
本实施例采用检测至少2个人脸部位运动检测装置解决了现有技术中算法单一,安全性不高的问题,可扩展性强,且所采用的本发明提供的一种人脸部位运动检测装置的实施例一或实施例二对硬件要求不高;另外,通过活体识别分值计算装置对不同部位运动加权再进行分数融合,活体识别准确度高,获得了活体识别准确率高、硬件要求低和安全性高的有益效果。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!