基于改进粒子群算法供应链生产运输协同调度方法及系统与流程
本发明涉及供应链技术领域,具体涉及一种基于改进粒子群算法供应链生产运输协同调度方法及系统。
背景技术:
近年来,生产与运输协同调度问题已成为供应链调度研究领域的热点问题之一。2003年hall等首次阐述了供应链调度概念的问题,并针对单个工厂和多个客户的供应链调度问题,提出了动态规划算法用来优化配送时间和成本。随后调度问题的研究越来越深入。本文中为最大化供应链收益问题构建的改进粒子群算法是建立在已有的粒子群算法(kennedyandeberhart,1995)基础上的,通过引入交叉和变异算子,改善粒子过早陷入早熟的情况,提高粒子的多样性,以实现合理安排工件排序、工件组批、运输配送方案。粒子群算法的步骤一般包括:(1)初始化粒子群位置和速度;(2)计算适应度,记录当前代最优解和全局最优解;(3)更新粒子的速度和位置;(4)更新当前代最优解和全局最优解。通过重复以上步骤在整个空间内搜索最优解。
然而,目前对半成品的生产和运输的协同调度问题的研究相对较少,很多学者提出的调度模型大多集中在机器环境、生产特征、资源优化上面,而忽略了半成品的运输以及成品的分配对生产的影响,同时考虑机器调度和产品运输的协同对提高生产企业的生产率尤为重要,会大大降低供应链成本,提高供应链竞争力。除此之外,在方法上,粒子群算法也存在着全局收敛性不足和容易早熟等缺点,特别是在某些特定的优化问题中无法提供稳定可靠的解决方案,不利于在供应链协同效率的提升。因此,我们有必要根据具体的实施项目,有针对性的改进粒子群算法,从而实现供应链协同优化决策。
技术实现要素:
本发明实施例的一个目的在于提高批处理机工件的过程中调度的合理性。
第一方面,本发明实施例提供了一种基于改进粒子群算法的供应链生产运输协同调度方法,包括:
步骤1、获取得到每个仓库运送工件的数量;根据先到达的工件先安排生产原则,获得工件序列;采用0-1编码方式,使用一个xm={x1m,x2m,...,xim,...,xnm}向量来表示第m个粒子的编码,元素取值为0或1,当元素数值为1时,与所述元素前面的数值0形成一批,第n维向量数值均取1;
步骤2、对粒子群进行初始化,确定粒子群的种群规模m,粒子的维度d,迭代次数t=0,最大迭代次数tmax,粒子的位置xim和速度vim,并按照编码规则给每个粒子的各个维度赋值0或1;取一个0到1之间的随机数rand,粒子的位置和速度计算方式如下:
其中,w,c1,c2均是常系数;
步骤3、根据bu规则对初始解进行修正,再利用mf批次分配规则将批次分配到合适的机器上进行加工,然后用适应度函数计算各个粒子的适应度值,并初始化个体最优位置pb和全局最优位置gb;
步骤4、利用“锦标赛”方式选择粒子,将粒子按照适应度值从小到大排序,选择前20%的粒子随机两两进行交叉,保证粒子数为偶数,如为小数则四舍五入,如为奇数则加1,产生相应的子代粒子,用子代代替父代;
步骤5、根据bu规则对初始解进行修正,再利用mf批次分配规则将批次分配到合适的机器上进行加工,然后用适应度函数计算各个粒子的适应度值,并初始化个体最优位置pb和全局最优位置gb;
步骤6、计算粒子的变异概率进行变异操作,根据bu规则和mf批次分配规则计算出粒子的适应度值,更新个体最优位置pb和全局最优位置gb;
步骤7、计算出所有粒子的速度和位置,更新粒子的位置xim,计算各个粒子的适应度值,并初始化个体最优位置pb和全局最优位置gb,令t=t+1;
步骤8、判断t≤tmax是否成立,若成立,返回步骤3,否则,结束算法并输出全局最优解gb,输出最优的组批方式和批在每个机器上的加工顺序。
可选地,所述根据bu规则对初始解进行修正,包括:
步骤1’、对于一个给定的个体xm,设定i=1,j=1;
步骤2’、如果xim=0,将工件i分配至第j批,i=i+1;否则,j=j+1,将工件i分配至第j批;
步骤3’、判断i>1是否成立,若成立,则重复步骤2’;否则,得到所有批集合;
步骤4’、对于任意批次bj,如果bj容量大于b,那么:如果|bj|-b+|bj+1|≤b,|bj+1|表示批次bj所含的工件数量,则选择从仓库到制造商运输阶段最晚达到机器的工件j*,将工件j*归入批次bj+1中,否则在j+1位置重新插入新批次,将工件j*归入批次bj+1中,最后从bj中移除工件j*;
步骤5’、重复步骤4’,直至所有批均符合容量要求。
可选地,所述利用mf批次分配规则将批次分配到合适的机器上进行加工,包括:
步骤1”、根据批次修正的方法对工件进行组批后,得到每个批次bk的加工时间pb,设定参数ne;
步骤2”、按照以下法则确定批次分配的上下界:
对于下界:
如果
对于上界:
如果
步骤3”、令
步骤4”、一次选择一个批次分配到机器上,且保证该机器加工时间之和没有超过cmax;
如果批次不能在不超过cmax的限制下放到机器上,则重新设置lb=cmax;否则重新设置ub=cmax;
步骤5”、判断
可选地,所述利用“锦标赛”方式选择粒子,将粒子按照适应度值从小到大排序,选择前20%的粒子随机两两进行交叉,包括:
步骤41、随机选择两个个体,比较适应度大小,选择适应度较好的作为候选交叉粒子;选择种群规模20%的粒子,对该选择出的粒子群体随机两两进行交叉,保证粒子数为偶数,如为小数则四舍五入,如为奇数则加1,产生相应的子代粒子,用子代代替父代;具体交叉方式如下:以维为基准,每维随机生成0或1,如果该数等于1,则该维的数值进行互换,否则不互换;
步骤42、根据下式计算粒子m的变异概率
其中,fmin指全局最优位置的适应度值,favg指平均适应度值,f指当前粒子的适应度值,p1=0.1,p2=0.01;每个粒子生成[0,1]间的随机小数,并将其与pm进行比较,如果小于pm,则粒子进行变异操作,否则不变异;具体变异方法如下:以维为基准,每维随机生成0或1,如果该数等于1,则该维的数值进行变异,将1变成0或者将0变成1,否则不变异。
第二方面,本发明实施例提供了一种基于改进粒子群算法的供应链生产运输协同调度系统,包括:
计算模块,用于执行:
步骤1、获取得到每个仓库运送工件的数量;根据先到达的工件先安排生产原则,获得工件序列;采用0-1编码方式,使用一个xm={x1m,x2m,...,xim,...,xnm}向量来表示第m个粒子的编码,元素取值为0或1,当元素数值为1时,与所述元素前面的数值0形成一批,第n维向量数值均取1;
步骤2、对粒子群进行初始化,确定粒子群的种群规模m,粒子的维度d,迭代次数t=0,最大迭代次数tmax,粒子的位置xim和速度vim,并按照编码规则给每个粒子的各个维度赋值0或1;取一个0到1之间的随机数rand,粒子的位置和速度计算方式如下:
其中,w,c1,c2均是常系数;
步骤3、根据bu规则对初始解进行修正,再利用mf批次分配规则将批次分配到合适的机器上进行加工,然后用适应度函数计算各个粒子的适应度值,并初始化个体最优位置pb和全局最优位置gb;
步骤4、利用“锦标赛”方式选择粒子,将粒子按照适应度值从小到大排序,选择前20%的粒子随机两两进行交叉,保证粒子数为偶数,如为小数则四舍五入,如为奇数则加1,产生相应的子代粒子,用子代代替父代;
步骤5、根据bu规则对初始解进行修正,再利用mf批次分配规则将批次分配到合适的机器上进行加工,然后用适应度函数计算各个粒子的适应度值,并初始化个体最优位置pb和全局最优位置gb;
步骤6、计算粒子的变异概率进行变异操作,根据bu规则和mf批次分配规则计算出粒子的适应度值,更新个体最优位置pb和全局最优位置gb;
步骤7、计算出所有粒子的速度和位置,更新粒子的位置xim,计算各个粒子的适应度值,并初始化个体最优位置pb和全局最优位置gb,令t=t+1;
步骤8、判断t≤tmax是否成立,若成立,返回步骤3,否则,结束算法并输出全局最优解gb;
输出模块,用于输出最优的组批方式和批在每个机器上的加工顺序。
可选地,所述计算模块执行根据bu规则对初始解进行修正的步骤,包括:
步骤1’、对于一个给定的个体xm,设定i=1,j=1;
步骤2’、如果xim=0,将工件i分配至第j批,i=i+1;否则,j=j+1,将工件i分配至第j批;
步骤3’、判断i>1是否成立,若成立,则重复步骤2’;否则,得到所有批集合;
步骤4’、对于任意批次bj,如果bj容量大于b,那么:如果|bj|-b+|bj+1|≤b,|bj+1|表示批次bj所含的工件数量,则选择从仓库到制造商运输阶段最晚达到机器的工件j*,将工件j*归入批次bj+1中,否则在j+1位置重新插入新批次,将工件j*归入批次bj+1中,最后从bj中移除工件j*;
步骤5’、重复步骤4’,直至所有批均符合容量要求。
可选地,所述计算模块执行利用mf批次分配规则将批次分配到合适的机器上进行加工的步骤,包括:
步骤1”、根据批次修正的方法对工件进行组批后,得到每个批次bk的加工时间pb,设定参数ne;
步骤2”、按照以下法则确定批次分配的上下界:
对于下界:
如果
对于上界:
如果
步骤3”、令
步骤4”、一次选择一个批次分配到机器上,且保证该机器加工时间之和没有超过cmax;
如果批次不能在不超过cmax的限制下放到机器上,则重新设置lb=cmax;否则重新设置ub=cmax;
步骤5”、判断
可选地,所述计算模块执行利用“锦标赛”方式选择粒子,将粒子按照适应度值从小到大排序,选择前20%的粒子随机两两进行交叉的步骤,包括:
步骤41、随机选择两个个体,比较适应度大小,选择适应度较好的作为候选交叉粒子;选择种群规模20%的粒子,对该选择出的粒子群体随机两两进行交叉,保证粒子数为偶数,如为小数则四舍五入,如为奇数则加1,产生相应的子代粒子,用子代代替父代;具体交叉方式如下:以维为基准,每维随机生成0或1,如果该数等于1,则该维的数值进行互换,否则不互换;
步骤42、根据下式计算粒子m的变异概率
其中,fmin指全局最优位置的适应度值,favg指平均适应度值,f指当前粒子的适应度值,p1=0.1,p2=0.01;每个粒子生成[0,1]间的随机小数,并将其与pm进行比较,如果小于pm,则粒子进行变异操作,否则不变异;具体变异方法如下:以维为基准,每维随机生成0或1,如果该数等于1,则该维的数值进行变异,将1变成0或者将0变成1,否则不变异。
本发明实施例针对考虑分布式仓库的生产运输协同调度问题,通过改进的粒子群算法,首先将工件以编码的方式,进行分批和修正,然后依据问题的性质提出相应批指派策略,计算相应个体的适应度值;基于解的适应度对粒子执行交叉变异操作,通过重复迭代,在整个解空间内进行搜索,更新种群,最终求的近似最优解。改进的粒子群算法在收敛速度和收敛结果上,是一种效率很高的算法;通过该算法,解决了考虑分布式仓库的生产运输协同调度问题,提高了供应链的生产效率,降低了供应链成本,提高了供应链的服务水平。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1是本发明一实施例提供的平行机生产与两阶段运输协同调度结构图示意图;
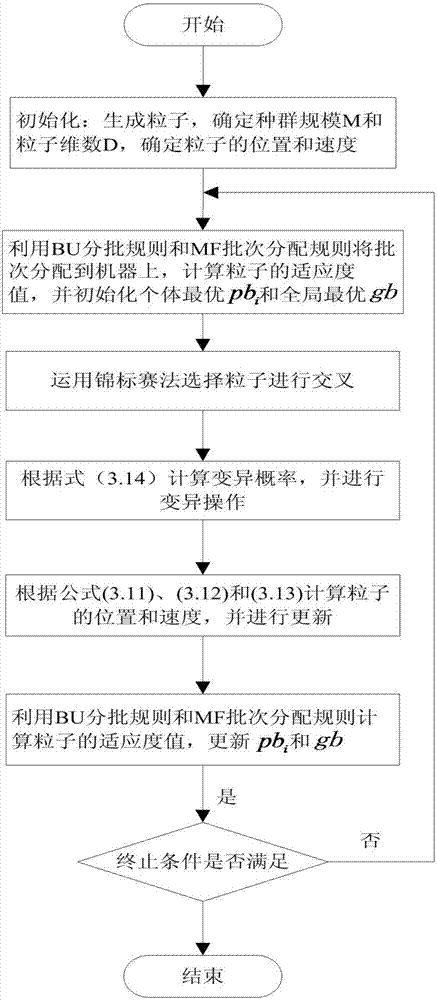
图2是本发明一实施例提供的一种基于改进粒子群算法的供应链生产运输协同调度方法的流程示意图;
图3是本发明一实施例提供的一种基于改进粒子群算法的供应链生产运输协同调度系统的结构示意图;
图4是本发明一实施例提供的一种电子设备的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的一个目的在于:解决考虑分布式仓储的平行机生产运输协同调度问题,该问题包括两个方面:(1)将工件进行分批;(2)将不同的批次分到相应的批处理机上进行加工。分批问题是指将从仓库运输到制造商处的工件在满足批处理机容量的条件下将工件分成多个批次;批次的分配问题是指将批次分到哪个机器上,确定安排在同一个机器的批次的加工顺序。本发明基于问题所特有的性质,克服了传统粒子群算法收敛性问题,提出了改进的粒子群算法,提高了智能化决策效率。
为便于理解,下面结合图1来说明本发明实施例提供的方法所要解决的问题。
考虑分布式仓库的平行机生产运输协同调度问题,目标为最小化制造跨度。该问题描述如下:给定一组包含n个工件的任务集合j={j1,j2,j3,···,jn},m个分布在不同地理位置的仓库。不同的工件具有不同的加工时间和尺寸,分别由由pi和si(i=1,2,···,n)表示。该问题包含三个阶段,即工件从仓库运输到制造商的运输阶段,工件在制造商机器上的加工阶段和从制造商运输到客户的运输阶段。该问题存在以下设定:
(1)在半成品工件从仓库运输到制造商的阶段,每个仓库都只有一辆运载工具。且每次仅能运载一个工件。假定每个仓库的运载工具到制造商的往返运输时间是固定的,记为t={t1,t2,t3,···,tn}。
(2)在工件加工阶段,批处理机属于同类平行机。每个批处理机的容量设为b,即任一批工件bk(k=1,2,...,l)中的所有工件尺寸之和不大于b,假设所有工件的尺寸均不大于机器容量。在加工过程中,同批次中的工件同时被处理,批次bk的加工时间是pb,pb的值等于批次中加工时间最长的数值。
(3)在工件从制造商运输到客户的阶段,制造商仅存在一辆运载车辆,将加工完成的工件运输给客户。运输车辆的容量与批处理机容量相等,即为b。假定运载车辆在制造商和客户之间的来回运输时间为t,则单程运输时间为t/2。为了方便描述,本文将装载和卸载工件的时间统一计算到运输时间中。
基于此,本发明实施例提供的一种基于改进粒子群算法的供应链生产运输协同调度方法,可以参考图2,包括:
步骤1、由模型分析可知,每个仓库的运载车辆无空闲,那么所有仓库的车辆从零时刻开始同时并且无空闲地运输工件,直到制造商处总工件数达到客户的订单数,运载车辆停止运输。因此可以获取得到每个仓库运送工件的数量;根据先到达的工件先安排生产原则,获得工件序列;采用0-1编码方式,使用一个xm={x1m,x2m,...,xim,...,xnm}向量来表示第m个粒子的编码,元素取值为0或1,当元素数值为1时,与所述元素前面的数值0形成一批,第n维向量数值均取1;
步骤2、对粒子群进行初始化,确定粒子群的种群规模m,粒子的维度d,迭代次数t=0,最大迭代次数tmax,粒子的位置xim和速度vim,并按照编码规则给每个粒子的各个维度赋值0或1;取一个0到1之间的随机数rand,粒子的位置和速度计算方式如下:
其中,w,c1,c2均是常系数;
步骤3、根据bu规则对初始解进行修正,再利用mf批次分配规则将批次分配到合适的机器上进行加工,然后用适应度函数计算各个粒子的适应度值,并初始化个体最优位置pb和全局最优位置gb;
步骤4、利用“锦标赛”方式选择粒子,将粒子按照适应度值从小到大排序,选择前20%的粒子随机两两进行交叉,保证粒子数为偶数,如为小数则四舍五入,如为奇数则加1,产生相应的子代粒子,用子代代替父代;
步骤5、根据bu规则对初始解进行修正,再利用mf批次分配规则将批次分配到合适的机器上进行加工,然后用适应度函数计算各个粒子的适应度值,并初始化个体最优位置pb和全局最优位置gb;
步骤6、计算粒子的变异概率进行变异操作,根据bu规则和mf批次分配规则计算出粒子的适应度值,更新个体最优位置pb和全局最优位置gb;
步骤7、计算出所有粒子的速度和位置,更新粒子的位置xim,计算各个粒子的适应度值,并初始化个体最优位置pb和全局最优位置gb,令t=t+1;
步骤8、判断t≤tmax是否成立,若成立,返回步骤3,否则,结束算法并输出全局最优解gb,输出最优的组批方式和批在每个机器上的加工顺序。
其中,在具体实施时,这里的根据bu规则对初始解进行修正可以通过多种方式来实施,其中一种可选的实施方式包括如下步骤:
步骤1’、对于一个给定的个体xm,设定i=1,j=1;
步骤2’、如果xim=0,将工件i分配至第j批,i=i+1;否则,j=j+1,将工件i分配至第j批;
步骤3’、判断i>1是否成立,若成立,则重复步骤2’;否则,得到所有批集合;
步骤4’、对于任意批次bj,如果bj容量大于b,那么:如果|bj|-b+|bj+1|≤b,|bj+1|表示批次bj所含的工件数量,则选择从仓库到制造商运输阶段最晚达到机器的工件j*,将工件j*归入批次bj+1中,否则在j+1位置重新插入新批次,将工件j*归入批次bj+1中,最后从bj中移除工件j*;
步骤5’、重复步骤4’,直至所有批均符合容量要求。
在具体实施时,这里的利用mf批次分配规则将批次分配到合适的机器上进行加工可以通过多种方式来实施,其中一种可选的实施方式包括如下步骤:
步骤1”、根据批次修正的方法对工件进行组批后,得到每个批次bk的加工时间pb,设定参数ne;
步骤2”、按照以下法则确定批次分配的上下界:
对于下界:
如果
对于上界:
如果
步骤3”、令
步骤4”、一次选择一个批次分配到机器上,但一定要保证该机器加工时间之和没有超过cmax;
如果批次不能在不超过cmax的限制下放到机器上,则重新设置lb=cmax;否则重新设置ub=cmax;
步骤5”、判断
在具体实施时,这里的利用“锦标赛”方式选择粒子,将粒子按照适应度值从小到大排序,选择前20%的粒子随机两两进行交叉也可以通过多种方式来实施,其中一种可选的实施方式包括如下步骤:
步骤41、随机选择两个个体,比较适应度大小,选择适应度较好的作为候选交叉粒子;选择种群规模20%的粒子,对该选择出的粒子群体随机两两进行交叉,保证粒子数为偶数,如为小数则四舍五入,如为奇数则加1,产生相应的子代粒子,用子代代替父代;具体交叉方式如下:以维为基准,每维随机生成0或1,如果该数等于1,则该维的数值进行互换,否则不互换;
步骤42、根据下式计算粒子m的变异概率
其中,fmin指全局最优位置的适应度值,favg指平均适应度值,f指当前粒子的适应度值,p1=0.1,p2=0.01;每个粒子生成[0,1]间的随机小数,并将其与pm进行比较,如果小于pm,则粒子进行变异操作,否则不变异;具体变异方法如下:以维为基准,每维随机生成0或1,如果该数等于1,则该维的数值进行变异,将1变成0或者将0变成1,否则不变异。
本发明实施例提供的方法具有如下有益效果:
1、本发明实施例针对考虑分布式仓库的生产运输协同调度问题,通过改进的粒子群算法,首先将工件以编码的方式,进行分批和修正,然后依据问题的性质提出相应批指派策略,计算相应个体的适应度值;基于解的适应度对粒子执行交叉变异操作,通过重复迭代,在整个解空间内进行搜索,更新种群,最终求的近似最优解。改进的粒子群算法在收敛速度和收敛结果上,是一种效率很高的算法;通过该算法,解决了考虑分布式仓库的生产运输协同调度问题,提高了供应链的生产效率,降低了供应链成本,提高了供应链的服务水平。
2、本发明实施例依据该问题性质,在解的编码上采取二维编码方式,基于该编码方式,提出了在整个算法求解过程中适用的编码修正策略,保证在任意个体产生后对个体进行调整,避免了非可行解的产生,并采用启发式算法进行批的分配加工,提高了算法的搜索效率和收敛速度,有利于算法最大可能的在解空间内搜索问题的最优解。
3、本发明实施例针对粒子群算法全局收敛性较弱和容易早熟的问题,引入了基于二维编码的交叉和变异策略,既保留了原有粒子群算法的收敛速度优势,又提升了种群的多样性,通过融合两种算法的种群更新策略,提升了算法的性能。
基于相同的构思,本发明另一实施例还提供了一种基于改进粒子群算法的供应链生产运输协同调度系统,参见图3,包括:
计算模块201,用于执行:
步骤1、获取得到每个仓库运送工件的数量;根据先到达的工件先安排生产原则,获得工件序列;采用0-1编码方式,使用一个xm={x1m,x2m,...,xim,...,xnm}向量来表示第m个粒子的编码,元素取值为0或1,当元素数值为1时,与所述元素前面的数值0形成一批,第n维向量数值均取1;
步骤2、对粒子群进行初始化,确定粒子群的种群规模m,粒子的维度d,迭代次数t=0,最大迭代次数tmax,粒子的位置xim和速度vim,并按照编码规则给每个粒子的各个维度赋值0或1;取一个0到1之间的随机数rand,粒子的位置和速度计算方式如下:
其中,w,c1,c2均是常系数;
步骤3、根据bu规则对初始解进行修正,再利用mf批次分配规则将批次分配到合适的机器上进行加工,然后用适应度函数计算各个粒子的适应度值,并初始化个体最优位置pb和全局最优位置gb;
步骤4、利用“锦标赛”方式选择粒子,将粒子按照适应度值从小到大排序,选择前20%的粒子随机两两进行交叉,保证粒子数为偶数,如为小数则四舍五入,如为奇数则加1,产生相应的子代粒子,用子代代替父代;
步骤5、根据bu规则对初始解进行修正,再利用mf批次分配规则将批次分配到合适的机器上进行加工,然后用适应度函数计算各个粒子的适应度值,并初始化个体最优位置pb和全局最优位置gb;
步骤6、计算粒子的变异概率进行变异操作,根据bu规则和mf批次分配规则计算出粒子的适应度值,更新个体最优位置pb和全局最优位置gb;
步骤7、计算出所有粒子的速度和位置,更新粒子的位置xim,计算各个粒子的适应度值,并初始化个体最优位置pb和全局最优位置gb,令t=t+1;
步骤8、判断t≤tmax是否成立,若成立,返回步骤3,否则,结束算法并输出全局最优解gb;
输出模块202,用于输出最优的组批方式和批在每个机器上的加工顺序。
在具体实施时,所述计算模块201执行根据bu规则对初始解进行修正的步骤,包括:
步骤1’、对于一个给定的个体xm,设定i=1,j=1;
步骤2’、如果xim=0,将工件i分配至第j批,i=i+1;否则,j=j+1,将工件i分配至第j批;
步骤3’、判断i>1是否成立,若成立,则重复步骤2’;否则,得到所有批集合;
步骤4’、对于任意批次bj,如果bj容量大于b,那么:如果|bj|-b+|bj+1|≤b,|bj+1|表示批次bj所含的工件数量,则选择从仓库到制造商运输阶段最晚达到机器的工件j*,将工件j*归入批次bj+1中,否则在j+1位置重新插入新批次,将工件j*归入批次bj+1中,最后从bj中移除工件j*;
步骤5’、重复步骤4’,直至所有批均符合容量要求。
在具体实施时,所述计算模块201执行利用mf批次分配规则将批次分配到合适的机器上进行加工的步骤,包括:
步骤1”、根据批次修正的方法对工件进行组批后,得到每个批次bk的加工时间pb,设定参数ne;
步骤2”、按照以下法则确定批次分配的上下界:
对于下界:
如果
对于上界:
如果
步骤3”、令
步骤4”、一次选择一个批次分配到机器上,但一定要保证该机器加工时间之和没有超过cmax;
如果批次不能在不超过cmax的限制下放到机器上,则重新设置lb=cmax;否则重新设置ub=cmax;
步骤5”、判断
在具体实施时,所述计算模块201执行利用“锦标赛”方式选择粒子,将粒子按照适应度值从小到大排序,选择前20%的粒子随机两两进行交叉的步骤,包括:
步骤41、随机选择两个个体,比较适应度大小,选择适应度较好的作为候选交叉粒子;选择种群规模20%的粒子,对该选择出的粒子群体随机两两进行交叉,保证粒子数为偶数,如为小数则四舍五入,如为奇数则加1,产生相应的子代粒子,用子代代替父代;具体交叉方式如下:以维为基准,每维随机生成0或1,如果该数等于1,则该维的数值进行互换,否则不互换;
步骤42、根据下式计算粒子m的变异概率
其中,fmin指全局最优位置的适应度值,favg指平均适应度值,f指当前粒子的适应度值,p1=0.1,p2=0.01;每个粒子生成[0,1]间的随机小数,并将其与pm进行比较,如果小于pm,则粒子进行变异操作,否则不变异;具体变异方法如下:以维为基准,每维随机生成0或1,如果该数等于1,则该维的数值进行变异,将1变成0或者将0变成1,否则不变异。
本发明实施例还公开一种计算机程序产品,所述计算机程序产品包括存储在计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,计算机能够执行上述各方法实施例所提供的方法,例如包括:第一方面所述的方法。
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
类似地,应当理解,为了精简本公开并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。
- 还没有人留言评论。精彩留言会获得点赞!