一种列式存储格式文件快速合并方法及其系统与流程
本发明涉及分布式文件系统领域,特别涉及一种列式存储格式文件快速合并方法及其系统、及计算机存储介质、电子设备。
背景技术:
parquet是面向分析型业务的列式存储格式,由twitter和cloudera合作开发,是2015年5月从apache的孵化器里毕业成为apache顶级项目。
目前,parquet文件和传统的行式存储格式文件相比有几点优势:
(1)可以跳过不符合条件的数据,只读取需要的数据,降低io数据量;
(2)压缩编码可以降低磁盘存储空间,由于同一列的数据类型是一样的,可以使用更高效的压缩编码,例如runlengthencoding和deltaencoding,能进一步节约存储空间;
(3)只读取需要的列,支持向量运算,能够获取更好的扫描性能。
parquet列式存储带来的性能上的提高在业内已经得到了充分的认可,例如impala、spark、hive/pig都原生支持parquet。
但是,parquet文件的存储格式设计也决定了其不支持简单的追加操作,在一个提供实时查询的分布式存储系统中,每当有新数据到达需要形成parquet文件时,都必须重新生成一个新的parquet文件,而不能追加到已有的parquet文件的后面,这样时间一长就会造成分布式存储系统中有大量的数据量很小的parquet文件,对io和存储系统的某些组件(比如hdfs的namenode、impala的statenode)造成巨大压力,此时需要对这些数据量很小的parquet文件进行合并,重新生成小量的数据量较大的parquet文件。
目前,最简单的parquet文件的合并思路是:依次读取待合并的每个parquet文件的每行内容,将每行内容重新写入新的parquet文件。但是,这种方法存在以下明显的缺点:
(1)由于要读取待合并的每个parquet文件的每行内容,再将每行内容写入新的parquet文件,相当于对每行内容进行了“parquet格式->普通格式->parquet格式”这样的一个转换过程,如此一来对cpu消耗较大,且速度较低;
(2)parquet文件在写入的过程中,数据都是先暂缓在内存当中的,等要close的时候再一次性吐出,也就是说待合并的每个parquet文件的每行内容都必须先暂缓在内存里面,如此一来对内存消耗较大。
技术实现要素:
为了解决现有技术的问题,本发明实施例提供了一种列式存储格式文件快速合并方法及其系统、及一种计算机存储介质及电子设备。所述技术方案如下:
一方面,一种列式存储格式文件快速合并方法,其中,所述方法包括以下步骤:
读取每个待合并的列式存储格式文件的文件元数据,所述文件元数据包含所述列式存储格式文件的数据模型结构;
遍历所述数据模型结构一致的待合并的列式存储格式文件,并按照按块读取方式合并到新列式存储格式文件中。
进一步的,所述读取每个待合并的列式存储格式文件的文件元数据的步骤具体包括:
定位到每个待合并的列式存储格式文件的文件元数据的起始位置和长度;
根据所述起始位置和长度将每个待合并的列式存储格式文件的文件元数据读取到内存结构中。
进一步的,在所述遍历所述数据模型结构一致的待合并的列式存储格式文件的步骤之前,所述方法还包括以下步骤:
对比每个待合并的列式存储格式文件的所述数据模型结构;
判断所述数据模型结构是否一致;
如果所述数据模型结构一致,则在所述新列式存储格式文件的起始位置写入起始位置固定字符;
如果所述数据模型结构不一致,则停止所述列式存储格式文件的合并。
进一步的,所述列式存储格式文件的结构包括起始位置固定字符、行群组、文件元数据、文件元数据长度以及结束位置固定字符,其中,所述按照按块读取方式合并到新列式存储格式文件中的步骤具体包括:
将每个待合并的列式存储格式文件中的行群组按照按块读取方式追加到所述新列式存储格式文件的行群组中;
将每个待合并的列式存储格式文件中的文件元数据追加到所述新列式存储格式文件的文件元数据中;
计算所述新列式存储格式文件的文件元数据的长度并更新至所述新列式存储格式文件中;
在所述新列式存储格式文件的结束位置写入结束位置固定字符。
进一步的,所述列式存储格式文件的文件元数据的结构还包括附加信息以及行群组元数据,其中,所述将每个待合并的列式存储格式文件中的文件元数据追加到所述新列式存储格式文件的文件元数据中的步骤具体包括:
将每个待合并的列式存储格式文件中的附加信息追加到所述新列式存储格式文件的附加信息中;
将每个待合并的列式存储格式文件中的行群组元数据追加到所述新列式存储格式文件的行群组元数据中,其中,每个所述行群组元数据包括一个或者多个列元数据,每个列元数据包括一个或者多个offset;
在所述新列式存储格式文件中的新写入的所述行群组元数据的列元数据中的offset上加上值rsize;
将所述rsize加上新写入的所述行群组元数据的大小;
将追加之后得到的新的文件元数据经过协议转换方式写入到所述新列式存储格式文件中。
另一方面,一种列式存储格式文件快速合并系统,其中,所述系统包括:
文件读取模块,用于读取每个待合并的列式存储格式文件的文件元数据,所述文件元数据包含所述列式存储格式文件的数据模型结构;
文件合并模块,用于遍历所述数据模型结构一致的待合并的列式存储格式文件,并按照按块读取方式合并到新列式存储格式文件中。
进一步的,所述文件读取模块具体用于:
定位到每个待合并的列式存储格式文件的文件元数据的起始位置和长度;
根据起始位置和长度将每个待合并的列式存储格式文件的文件元数据读取到内存结构中。
进一步的,所述系统还包括对比判断模块和终止合并模块,其中:
所述对比判断模块,用于对比每个待合并的列式存储格式文件的所述数据模型结构,并判断所述数据模型结构是否一致;
所述文件合并模块,还用于如果所述数据模型结构一致,则在所述新列式存储格式文件的起始位置写入起始位置固定字符;
所述终止合并模块,用于如果所述数据模型结构不一致,则停止所述列式存储格式文件的合并。
进一步的,所述列式存储格式文件的结构包括起始位置固定字符、行群组、文件元数据、文件元数据长度以及结束位置固定字符,其中,所述文件合并模块具体用于:
将每个待合并的列式存储格式文件中的行群组按照按块读取方式追加到所述新列式存储格式文件的行群组中;
将每个待合并的列式存储格式文件中的文件元数据追加到所述新列式存储格式文件的文件元数据中;
计算所述新列式存储格式文件的文件元数据的长度并更新至所述新列式存储格式文件中;
在所述新列式存储格式文件的结束位置写入结束位置固定字符。
进一步的,所述列式存储格式文件的文件元数据的结构还包括附加信息以及行群组元数据,其中,所述文件合并模块具体还用于:
将每个待合并的列式存储格式文件中的附加信息追加到所述新列式存储格式文件的附加信息中;
将每个待合并的列式存储格式文件中的行群组元数据追加到所述新列式存储格式文件的行群组元数据中,其中,每个所述行群组元数据包括一个或者多个列元数据,每个列元数据包括一个或者多个offset;
在所述新列式存储格式文件中的新写入的所述行群组元数据的列元数据中的offset上加上值rsize;
将所述rsize加上新写入的所述行群组元数据的大小;
将追加之后得到的新的文件元数据经过协议转换方式写入到所述新列式存储格式文件中。
又一方面,一种计算机存储介质,其中,所述计算机存储介质存储有计算机可执行指令,所述计算机可执行指令用于使所述计算机执行上述任一项所述的方法。
再一方面,一种电子设备,其中,所述电子设备包括:
存储器,用于存储程序指令;
处理器,用于调用所述存储器中存储的程序指令,按照获得的程序指令执行上述任一项所述的方法。
本发明实施例提供的技术方案带来的有益效果是:对于列式存储格式(parquet)文件中占数据量最大部分的行群组(rowgroup)按块读取并追加到新列式存储格式文件中,而不需要解析出parquet文件的每一行的具体内容,再把每一行的具体内容按parquet文件的格式化写入新parquet文件,进而大幅减少对cpu的消耗,使得合并速度大幅提升,且由于在内存中只需要保存新的文件元数据(filemetadata),而不是整个新parquet文件的内容,所以对内存的占用也大幅降低。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一实施方式中列式存储格式文件快速合并方法流程图;
图2为本发明一实施方式中图1所示步骤s1的具体流程图;
图3为本发明一实施方式中列式存储格式文件的结构与filemetadata的结构示意图;
图4为本发明一实施方式中图1所示步骤s5的具体流程图;
图5为本发明一实施方式中图4所示步骤s52的具体流程图;
图6为本发明一实施方式中合并两个parquet文件的示意图;
图7为本发明一实施方式中列式存储格式文件快速合并系统的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
以下将对本发明所提供的实施一中的一种列式存储格式文件快速合并方法进行详细说明。
请参阅图1,为本发明一实施方式中列式存储格式文件快速合并方法流程图。
在本实施方式中,该列式存储格式文件以parquet文件来举例说明,也可以是其它列式存储格式文件。
在步骤s1中,读取每个待合并的列式存储格式文件的文件元数据(filemetadata),所述文件元数据的结构包含所述列式存储格式文件的数据模型结构(schema)。
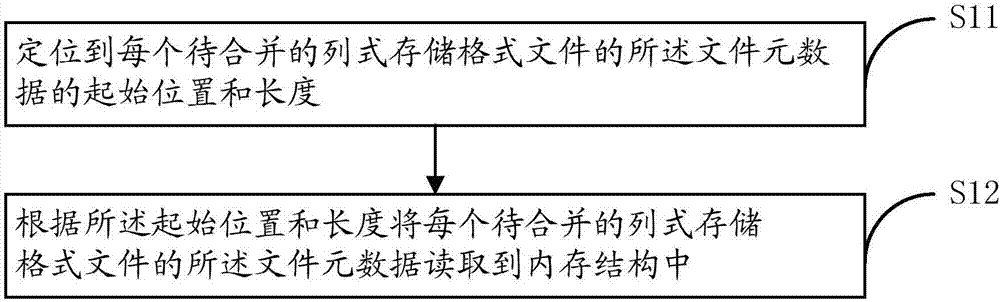
在本实施方式中,所述读取每个待合并的列式存储格式文件的文件元数据的步骤s1具体包括s11-s12,如图2所示。
请参阅图2,为本发明一实施方式中图1所示步骤s1的具体流程图。
在步骤s11中,定位到每个待合并的列式存储格式文件的文件元数据的起始位置和长度。
在本实施方式中,parquet文件的结构一般都包含footlength(可参阅图3),也即文件元数据长度,可以通过每个待合并的parquet文件的footlength定位到parquet文件的filemetadata的起始位置和长度。
在步骤s12中,根据起始位置和长度将每个待合并的列式存储格式文件的文件元数据读取到内存结构中。
在本实施方式中,也即根据起始位置和长度将每个待合并的parquet文件的filemetadata读取到内存结构中,由于filemetadata是通过thriftcompactprocotol协议转换存储的,所以读取时也需要经过thriftcompactprocotol协议反转换。
请继续参阅图1,在步骤s2中,对比每个待合并的列式存储格式文件的数据模型结构(schema)。
在本实施方式中,filemetadata是parquet文件的文件元数据,相当于parquet文件的目录数据,其中,filemetadata的结构如图3所示。
请参阅图3,为本发明一实施方式中列式存储格式文件的结构与filemetadata的结构示意图。其中,图3的左半部分为列式存储格式文件(即parquet文件)的结构,图3的右半部分为filemetadata的结构。
如图3所示,列式存储格式文件(即parquet文件)的结构包括起始位置固定字符(“par1”)、一个或者多个行群组(rowgroup)、文件元数据(filemetadata)、文件元数据长度(footlength)以及结束位置固定字符(“par1”),其中,起始位置固定字符(“par1”)为4个字节,每个rowgroup包括一个或多个的列(column),rowgroup是parquet文件的实际内容所在,也是整个parquet文件最大的部分,filemetadata是parquet文件的文件元数据,相当于parquet文件的目录数据,footlength是filemetadata的长度,包括4个字节,通过footlength就可以定位到parquet文件的文件元数据的起始位置,从而获取元数据,结束位置固定字符(“par1”)为4个字节。
如图3所示,filemetadata的结构包括版本号(version)、数据模型结构(schema)、附加信息(extrakey/valueparis)、一个或者多个行群组元数据(rowgroupmetadata)。其中,version为4个字节,schema是parquet文件的数据模型结构,extrakey/valueparis是附加的一些信息,每个行群组元数据(rowgroupmetadata)包括一个或多个列元数据(columnmetadata),每个columnmetadata里面有几个offset,用于指向对应的行群组(rowgroup)的列(column),通过这些offset就可以快速定位到所需要的列,并跳过不需要的列。
请继续参阅图1,在步骤s3中,判断数据模型结构是否一致。在本实施方式中,也即判断每个待合并parquet文件的schema是否一致。
如果数据模型结构一致,则在步骤s4中,在新列式存储格式文件的起始位置写入起始位置固定字符。在本实施方式中,只有数据模型结构一致的parquet文件才能够合并起来,否则不能合并。
在步骤s5中,遍历所述数据模型结构一致的待合并的列式存储格式文件,并按照按块读取方式合并到新列式存储格式文件中。
如果数据模型结构不一致,则在步骤s6中,停止所述列式存储格式文件的合并。
在本实施方式中,在步骤s5中,所述按照按块读取方式合并到所述新列式存储格式文件中的步骤具体包括s51-s54,如图4所示。
请参阅图4,为本发明一实施方式中图1所示步骤s5的具体流程图。
在步骤s51中,将每个待合并的列式存储格式文件中的行群组按照按块读取方式追加到所述新列式存储格式文件的行群组中;
在步骤s52中,将每个待合并的列式存储格式文件中的文件元数据追加到所述新列式存储格式文件的文件元数据中;
在步骤s53中,计算所述新列式存储格式文件的文件元数据的长度并更新至所述新列式存储格式文件中;
在步骤s54中,在新列式存储格式文件的结束位置写入结束位置固定字符。
在本实施方式中,所述将每个待合并的列式存储格式文件中的文件元数据追加到所述新列式存储格式文件的文件元数据中的步骤s52具体包括s521-s525,如图5所示。
请参阅图5,为本发明一实施方式中图4所示步骤s52的具体流程图。
在步骤s521中,将每个待合并的列式存储格式文件中的附加信息追加到所述新列式存储格式文件的附加信息中;
在步骤s522中,将每个待合并的列式存储格式文件中的行群组元数据追加到所述新列式存储格式文件的行群组元数据中,其中,每个行群组元数据包括一个或者多个列元数据,每个列元数据包括一个或者多个offset;
在步骤s523中,在所述新列式存储格式文件中的新写入的所述行群组元数据的列元数据中的offset上加上值rsize;
在步骤s524中,将rsize加上新写入的所述行群组元数据的大小;
在步骤s525中,将追加之后得到的新的文件元数据经过协议转换方式写入到所述新列式存储格式文件中。
在本实施方式中,举例说明,假如待合并的parquet文件是oparq,filemetadata为ofmd,新parquet文件是nparq,新filemetadata为nfmd(在内存中),现举例说明将待合并的parquet文件合并到新parquet文件里面。合并前新parquet文件已经写入到nparq里面的rowgroup总大小为rsize,则合并过程为:(1)将每个oparq的rowgroup按照按块读取方式追加到nparq里面去;(2)ofmd里面如果有extrakey/valueparis,则追加到nfmd的extrakey/valueparis里面;(3)ofmd的rowgroupmetadata追加到nfmd的rowgroupmetadata里面,同时在nfmd这些新加的rowgroupmetadata的columnmetadata里面的offset加上值rsize,主要是三个offset:data_page_offset、index_page_offset(如果有)、dictionary_page_offset(如果有);(4)rsize加上新写入的rowgroup的大小。
请参阅图6,为本发明一实施方式中合并两个parquet文件的示意图。如图所示,parquetfile-1表示parquet文件1,parquetfile-2表示parquet文件2,parquetfile-new表示合并后的新parquet文件,合并前的每一个parquet文件均包括起始位置固定字符(“par1”)、多个行群组(rowgroups)、文件元数据(filemetadata)、文件元数据长度(footlength)以及结束位置固定字符(“par1”),filemetadatanew表示合并后的新parquet文件的文件元数据,footlengthnew表示合并后的新parquet文件的文件元数据长度。
本发明提供的列式存储格式文件快速合并方法,对于列式存储格式(parquet)文件中占数据量最大部分的rowgroup按块读取并追加到新列式存储格式文件中,而不需要解析出parquet文件的每一行的具体内容,再把每一行的具体内容按parquet的格式化写入新parquet文件,进而大幅减少对cpu的消耗,使得合并速度大幅提升,且由于在内存中只需要保存新的filemetadata,而不是整个新parquet文件的内容,所以对内存的占用也大幅降低。
以下将对本发明所提供的一种列式存储格式文件快速合并系统进行详细说明。
请参阅图7,所示为本发明一实施方式中列式存储格式文件快速合并系统的结构示意图。
在本实施方式中,列式存储格式文件快速合并系统10包括文件读取模块11、对比判断模块12、文件合并模块13和终止合并模块14。
文件读取模块11,用于读取每个待合并的列式存储格式文件的文件元数据,所述文件元数据包含所述列式存储格式文件的数据模型结构。
在本实施方式中,所述文件读取模块11具体用于:
定位到每个待合并的列式存储格式文件的文件元数据的起始位置和长度;
根据起始位置和长度将每个待合并的列式存储格式文件的文件元数据读取到内存结构中。
对比判断模块12,用于对比每个待合并的列式存储格式文件的数据模型结构,并判断数据模型结构是否一致。
文件合并模块13,用于如果数据模型结构一致,则在新列式存储格式文件的起始位置写入起始位置固定字符。
终止合并模块14,用于如果数据模型结构不一致,则停止所述列式存储格式文件的合并。
文件合并模块13,用于遍历所述数据模型结构一致的待合并的列式存储格式文件,并按照按块读取方式合并到所述新列式存储格式文件中。
在本实施方式中,所述列式存储格式文件的结构包括起始位置固定字符、行群组、文件元数据、文件元数据长度以及结束位置固定字符,其中,所述文件合并模块13具体用于:
将每个待合并的列式存储格式文件中的行群组按照按块读取方式追加到所述新列式存储格式文件的行群组中;
将每个待合并的列式存储格式文件中的文件元数据追加到所述新列式存储格式文件的文件元数据中;
计算所述新列式存储格式文件的文件元数据的长度并更新至所述新列式存储格式文件中;
在新列式存储格式文件的结束位置写入结束位置固定字符。
在本实施方式中,所述列式存储格式文件的文件元数据的结构还包括附加信息以及行群组元数据,其中,所述文件合并模块13具体还用于:
将每个待合并的列式存储格式文件中的附加信息追加到所述新列式存储格式文件的附加信息中;
将每个待合并的列式存储格式文件中的行群组元数据追加到所述新列式存储格式文件的行群组元数据中,其中,每个行群组元数据包括一个或者多个列元数据,每个列元数据包括一个或者多个offset;
在所述新列式存储格式文件中的新写入的所述行群组元数据的列元数据中的offset上加上值rsize;
将rsize加上新写入的所述行群组元数据的大小;
将追加之后得到的新的文件元数据经过协议转换方式写入到所述新列式存储格式文件中。
本发明提供的一种列式存储格式文件快速合并系统10,对于列式存储格式(parquet)文件中占数据量最大部分的行群组(rowgroup)按块读取并追加到新列式存储格式文件中,而不需要解析出parquet文件的每一行的具体内容,再把每一行的具体内容按parquet文件的格式化写入新parquet文件,进而大幅减少对cpu的消耗,使得合并速度大幅提升,且由于在内存中只需要保存新的文件元数据(filemetadata),而不是整个新parquet文件的内容,所以对内存的占用也大幅降低。
另外,本发明还提供了一种计算机存储介质,其中,所述计算机存储介质存储有计算机可执行指令,所述计算机可执行指令用于使所述计算机执行本发明的列式存储格式文件快速合并方法。
此外,本发明还提供了一种电子设备,其中,所述电子设备包括:
存储器,用于存储程序指令;
处理器,用于调用所述存储器中存储的程序指令,按照获得的程序指令执行本发明的列式存储格式文件快速合并方法。
本发明提供的一种计算机存储介质和一种电子设备,对于列式存储格式(parquet)文件中占数据量最大部分的行群组(rowgroup)按块读取并追加到新列式存储格式文件中,而不需要解析出parquet文件的每一行的具体内容,再把每一行的具体内容按parquet文件的格式化写入新parquet文件,进而大幅减少对cpu的消耗,使得合并速度大幅提升,且由于在内存中只需要保存新的文件元数据(filemetadata),而不是整个新parquet文件的内容,所以对内存的占用也大幅降低。
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!