一种基于可编程器件的卷积神经网络加速方法与系统与流程
本发明涉及集成电路领域及深度学习领域,特别是涉及一种基于可编程器件的卷积神经网络加速方法与系统。
背景技术:
卷积神经网络是一个多层感知器,具有良好的容错能力、并行处理能力和自学习能力。在处理图形问题上,特别是在识别位移、缩放及其他形式扭曲不变性的问题上具有良好的鲁棒性和运算效率,因此被广泛应用在深度学习中作为基准神经网络架构。
现场可编程门阵列(fieldprogrammablegatearray,fpga)是一种可编程器件,它具有计算源丰富、灵活可重配置、开发周期短以及功耗低等优点。相比于cpu(centralprocessingunit)以及gpu(graphicsprocessingunit),现场可编程门阵列因可达到较高的性能功耗比而被广泛应用于神经网络的实现。然而,受到现有资源及通信带宽的限制,大规模卷积神经网络在现场可编程门阵列上的实现仍然是一项具有挑战的工作。卷积神经网络应用时的性能主要以计算吞吐量进行评估。如公式(1)所示,吞吐量主要由时钟频率和单位时间内的操作数计算得到,其中卷积神经网络加速器单位时间内执行的操作数主要由网络实现的并行度决定。
吞吐量=单位时间内操作数×时钟频率(1)
卷积神经网络主要由卷积层、池化层、全连接层等组成。卷积层对图片进行特征提取,卷积的计算核可以实现为一维或者二维基本处理单元。池化层(poolinglayer)是对特征图进行子采样,用于来减少图片的分辨率,进而减少整个网络的计算量和参数数量。池化层一般出现在卷积层后,因此在实现上通常和卷积层一起实现。全连接层是对前面得到的特征对图片进行分类,它一般以矩阵乘法运算实现。
在现场可编程门阵列上,卷积神经网络加速器的设计空间探索(性能空间探索)方法主要分为两类:寄存器传输(registertransferlevel,rtl)级设计和实现级设计。它们的特征分别如下。
rtl级设计是指在rtl阶段针对并行度或者计算吞吐量进行提升。其中,针对并行度而进行设计的rtl级设计方法主要通过提升卷积层,或者整个卷积神经网络的并行度而实现。在fpga的实现上,加速器的并行度主要受到fpga计算资源及带宽两方面的限制,通过屋顶模型(rooflinemodel)对卷积层的计算及带宽需求进行建模,可以寻求得到卷积层的最优设计参数;此外,采用奇异值分解(singularvaluedecomposition,svd)、动态精度调整(dynamic-precisiondataquantization)的方法可以减少整个网络的参数数量,进而减小带宽负担;采用快速傅里叶变换(fastfouriertransformation,fft)或流水线(pipeline)架构可以提升加速器的计算效率,从而增强加速器的并行度。另一方面,针对吞吐量而进行的设计的rtl级设计方法以整个计算吞吐量为优化目标进行设计空间探索,由于卷积神经网络的最高频率与并行策略、各类计算资源与并行策略间的关系均可以通过实验来经验性的给出,网络的吞吐量可以经验性的表达为关于并行参数的函数来进行设计空间的探索,由此实现较为综合的性能优化。
实现级设计是指完成rtl级的并行度提升之后,在布局布线阶段进一步提升加速器频率的设计方法。在布局阶段,将神经网络的计算核预先放置在离控制单元很近的位置可以减短数据的传输延时,进而增大频率。此外,根据商业工具在布局布线后报出的时序信息,在数据通路扇出较大的地方插入缓冲器(buffer),往复执行可使得关键路径的时延有效降低,从而显著提升加速器计算核的频率。
在卷积神经网络rtl级的设计方法中,针对并行度的rtl级设计方法虽然能够有效地优化加速器的计算资源及带宽,得到较优的并行策略,然而由于这类方法很少考虑频率对性能的影响,因此所采用的频率通常不超过150mhz,这使得加速器整体的性能并没有达到综合最优。另一方面,针对吞吐量的rtl级设计方法考虑了频率的影响,然而目前这类方法中的绝大部分模型,例如资源使用或计算时间都是依托于实验而经验性地给出的,因此应用的准确性和灵活性不高。此外,使用商用工具报出的频率过于保守,损失了根据实际情况进一步提升频率的优化空间。
卷积神经网络实现级的设计方法能够有效地提升加速器的频率以及并行度,然而这类方法的并行策略和频率提升策略是分开进行的,并没有考虑彼此间的互相影响。由于神经网络加速器的并行度和频率都与计算资源的使用及带宽需求有关,因此将二者分开优化虽然能够提升加速器的性能,但未必达到了综合考虑下的最优点。
本发明对神经网络加速器的并行度、频率及其二者之间的关系进行了深入分析,发现加速器的频率主要受到三个方面的影响:
(1)在计算资源方面,加速器实际可达的最高频率受到并行度的间接影响。较高的并行度需要较多的计算资源,然而计算资源的增多会造成可编程器件的布线拥塞,从而降低了加速器实际可达的最高频率。
(2)在带宽方面,加速器的频率同样受到并行度的间接影响。加速器的带宽需求与硬件资源所能提供的带宽相匹配时才能实现带宽资源的最大化利用,进而实现较高的性能。由于加速器的带宽需求是由时钟频率与单个周期内的访存次数计算得到的,较高的并行度会导致较频繁的外存访问,在给定的带宽上限之下,频率的提升空间就会变小。
(3)在特定的器件下,加速器实际可达的最高频率受到实际电压、温度、工艺偏差的影响。电路的频率与电压呈正相关、与温度呈负相关。出于可靠性的考虑,商业工具在时序分析中往往根据最恶劣的电压、温度及工艺偏差情况分析得到电路的最高时钟频率。然而这一假定的情况往往与实际情况存在较大偏差,因此加速器的实际频率存在进一步的提升空间。
本发明通过对上述三个方面的深入研究,提出了一种同时考虑以上三个因素的卷积神经网络加速器设计空间探索方法。针对前两个方面,本发明根据采用的卷积计算核结构和神经网络实现结构,建立了计算资源与并行化参数、带宽上限频率与并行化参数的量化模型。针对第三个方面,在不同的并行化参数下,本发明通过实验探索得到加速器在实际电压、温度、工艺偏差下可达的最高频率与并行化参数间的分析模型。在设计空间探索中,根据所述的模型建立,以卷积神经网络计算吞吐量为优化目标进行问题抽象,采用一定搜索算法进行求解,即可得到性能最优的并行化参数。
技术实现要素:
为了解决上述技术问题,本发明的目的是在卷积神经网络的设计空间探索中考虑实际电压、温度、工艺偏差下可达的最高时钟频率,提出一种综合考虑并行度及频率的设计空间探索方法。
具体地说,本发明提供了一种基于可编程器件的卷积神经网络加速方法,其中包括:
步骤s1、设计卷积神经网络在可编程器件上的基本结构,并根据该可编程器件所拥有的计算资源、可用带宽以及该基本结构,建立卷积神经网络加速器计算资源与并行化参数、带宽上限频率与并行化参数的量化模型,其中该基本结构包括该卷积神经网络加速器;
步骤s2、输入多个并行化参数,根据该可编程器件的实际供电电压、片内温度、元件工艺,分别探索该可编程器件在各个该并行化参数下所能达到的最高时钟频率,集合该最高时钟频率作为实验结果,并根据该实验结果建立该最高时钟频率关于并行化参数的分析模型;
步骤s3、根据该分析模型和该量化模型,求解出使该卷积神经网络性能最优的并行化参数,作为最优并行化参数,并根据该最优并行化参数推导出该卷积神经网络各层具体的最优并行策略,使得该卷积神经网络加速器运行该最优并行策略。
该基于可编程器件的卷积神经网络加速方法,其中该并行化参数为该卷积神经网络进行一次前馈运算的时钟周期数。
该基于可编程器件的卷积神经网络加速方法,其中该步骤2包括:
步骤s301、遍历该多个并行化参数从中选取一个并行化参数,推导其相应的并行策略;
步骤s302、基于该并行策略,并使用通用工具完成该卷积神经网络加速器的设计,获取通用工具报出的保守最高时钟频率;
步骤s303、在该可编程器件上采用该并行策略运行该卷积神经网络加速器,该卷积神经网络加速器根据已知的测试集进行循环读入输出运算;
步骤s304、初始化该可编程器件的运行频率为该保守最高时钟频率;
步骤s305、实时监测该可编程器件的片内温度,判断该片内温度是否稳定,若是,则执行步骤s306,否则,重复该步骤s305继续监测该可编程器件的片内温度;
步骤s306、检验该可编程器件的运算结果是否正确,若正确,则执行步骤s307;否则,执行步骤s308;
步骤s307、提升该可编程器件的运行频率,并判断是否超出该可编程器件时钟源所能提供的上限频率,若是,则执行步骤s308,否则,执行步骤s305;
步骤s308、停止该运行频率的提升,报出该并行化参数下运算结果正确的该最高时钟频率;
步骤s309、判断是否对该多个并行化参数遍历完全,若是,则结束;否则,继续执行步骤s301。
该基于可编程器件的卷积神经网络加速方法,其中该分析模型具体为反比例指数衰减拟合模型。
本发明还提供了一种基于可编程器件的卷积神经网络加速系统,其中包括:
量化模型建立模块、用于设计卷积神经网络在可编程器件上的基本结构,并根据该可编程器件所拥有的计算资源、可用带宽以及该基本结构,建立卷积神经网络加速器计算资源与并行化参数、带宽上限频率与并行化参数的量化模型,其中该基本结构包括该卷积神经网络加速器;
分析模型建立模块、输入多个并行化参数,根据该可编程器件的供电电压、片内温度、元件工艺,分别探索该可编程器件在各个该并行化参数下所能达到的最高时钟频率,集合该最高时钟频率作为实验结果,并根据该实验结果建立该最高时钟频率关于并行化参数的分析模型;
最优并行策略运行模块、用于根据该分析模型和该量化模型,求解出使该卷积神经网络性能最优的并行化参数,作为最优并行化参数,并根据该最优并行化参数推导出该卷积神经网络各层具体的最优并行策略,使得该卷积神经网络加速器运行该最优并行策略。
该基于可编程器件的卷积神经网络加速系统,其中该并行化参数为该卷积神经网络进行一次前馈运算的时钟周期数。
该基于可编程器件的卷积神经网络加速方法,其中该分析模型建立模块包括:
遍历模块、用于遍历该多个并行化参数从中选取一个并行化参数,推导其相应的并行策略;
通用设计模块、基于该并行策略,并使用通用工具完成该卷积神经网络加速器的设计,获取通用工具报出的保守最高时钟频率;
循环计算模块、用于在该可编程器件上采用该并行策略运行该卷积神经网络加速器,该卷积神经网络加速器根据已知的测试集进行循环读入输出运算;
初始化模块、用于初始化该可编程器件的运行频率为该保守最高时钟频率;
温度检测模块、用于实时监测该可编程器件的片内温度,判断该片内温度是否稳定,若是,则调用结果检验模块,否则,继续监测该片内温度直到其稳定;
结果检验模块、用于检验该可编程器件的运算结果是否正确,若正确,则调用升频模块;否则调用停止模块;
升频模块、用于提升该可编程器件的运行频率,并判断是否超出该可编程器件时钟源所能提供的上限频率,若是,则调用停止模块,否则调用该温度检测模块;
停止模块、用于停止该运行频率的提升,报出该并行化参数下运算结果正确的该最高时钟频率;
判断模块、用于判断是否对该多个并行化参数遍历完全,若是,则结束;否则调用遍历模块。
该基于可编程器件的卷积神经网络加速系统,其中该分析模型具体为反比例指数衰减拟合模型。
本发明还提供了一种包括该卷积神经网络加速系统的可编程器件。
本发明所具有的的技术效果包括:
1、通过采用卷积神经网络完成一次前馈运算的时钟周期数为并行化参数进行设计空间探索,精简了设计参数,有效降低了设计空间探索的复杂度。
2、在实际电压、温度、工艺偏差下进行的最高频率探索所需的模块在可编程器件上几乎不占用额外的逻辑资源,其结构简单灵活,易于实现。
3、使用实际电压、温度、工艺偏差下可达的最高频率进行设计空间探索,可进一步提升加速器的频率,从而有效提升其性能。
附图说明
图1为本发明的关键步骤流程图;
图2为本发明的结构设计框架图;
图3为本发明中的实际可达最高频率探索流程图;
图4为本发明实施例中基本运算单元子模块的结构框图;
图5为本发明实施例的设计空间探索结果图。
具体实施方式
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
本发明属于一种深度学习的硬件实现设计方法。如图1所示,本发明提供了一种基于可编程器件的卷积神经网络加速器设计方法,该方法可实验得到该可编程器件在实际供电电压、温度、元件工艺水平下可达的最高频率,并根据该最高频率来有效提升卷积神经网络加速器的性能,具体包括以下步骤:
步骤s1,设计卷积神经网络在可编程器件上的基本结构,并根据该可编程器件所拥有的计算资源、带宽以及该基本结构,分别建立计算资源、带宽上限频率关于并行化参数的量化模型,其中该并行化参数为该卷积神经网络进行一次前馈运算的时钟周期数;需要注意的是,本发明针对的器件是可编程器件,方法是对可编程器件的电路设计实现的优化,因此电路结构是通过rtl的设计进行修改的,并不是通常意义上的纯软件或硬件设计。
步骤s2,输入多个供实验所用的并行化参数,根据该可编程器件的供电电压、片内温度、元件工艺,分别探索该可编程器件在各个该并行化参数下所能达到的最高时钟频率,集合该最高时钟频率作为实验结果,并根据该实验结果建立该最高时钟频率关于并行化参数的分析模型;
步骤s3,以计算吞吐量为优化目标,根据该分析模型和该量化模型,即以该分析模型和该量化模型为约束条件,进行设计空间探索的问题抽象,采用搜索算法求解出性能最优的并行化参数,以推导出该卷积神经网络各层具体的并行策略,从而使得该卷积神经网络加速器运行该最优并行策略,以加速该卷积神经网络在可编程器件的计算效率。
本发明使用实际电压、温度、工艺偏差下可达的最高时钟频率进行设计空间探索,可进一步提升加速器的频率,从而有效提升其性能。
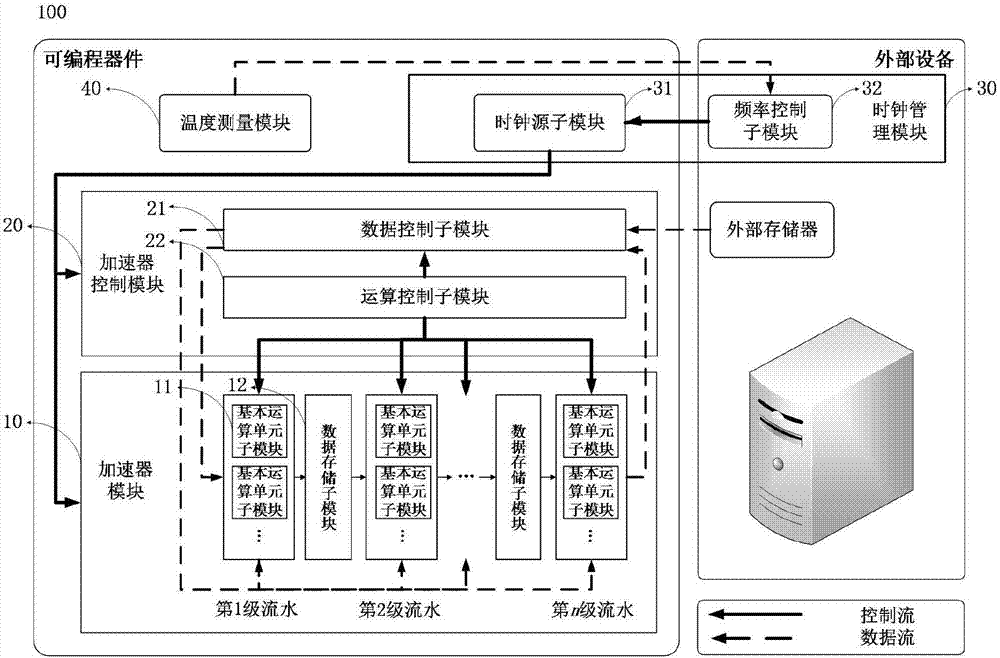
图2是图1步骤s1的卷积神经网络加速器基本结构设计框架图100。本发明的一个实施例所实现的是alexnet的加速器设计,包括加速器模块10,加速器控制模块20,时钟管理模块30,以及温度测量模块40。其中加速器模块10与加速器控制模块20相连,时钟管理模块30分别与加速器模块10、加速器控制模块20、温度管理模块40相连。本发明实施例的目标器件为intelalteraarria10芯片。
加速器模块10,采用流水线的结构实现卷积神经网络的各层,流水线的级数与卷积神经网络的层数相同。由于alexnet共有5个卷积层和3个全连接层,因此加速器模块10共包含8级流水。每级流水包含多个基本运算单元子模块11,用于实现卷积计算核、池化操作、非线性激活函数等运算。各级流水间通过数据存储子模块12相连接,在alexnet的加速器设计中共有7个数据存储子模块12,用于存储所述基本运算单元子模块计算输出的中间数据结果。
图4是基本运算单元子模块11的一个实施例。其中卷积计算核的实现可以多种,例如一维处理单元或二维处理单元。根据所实现网络的结构,在卷积计算核后可加入所需的计算函数,例如非线性激活函数,池化,局部响应归一化函数等。在本发明的一个实施例中,卷积计算核采用二维基本处理单元实现,后面连接非线性激活函数(relu)、池化(pooling)、局部响应归一化函数(lrn)。
加速器控制模块20,用于加速器模块10的数据传输及运算控制,包括数据控制子模块21,计算控制子模块22。数据控制子模块21与外部存储器和计算控制子模块22相连,用于为加速器模块10提供输入特征图数据、卷积核参数数据、偏置参数数据。计算控制子模块22与加速器模块10和数据控制子模块21相连,用于控制各个单级流水的计算。
数据控制子模块21的数据控制方式可以多种,例如直接存储器控制(directmemoryaccess,dma);与外部存储器的通信方式可以多种,例如采用总线接口标准(peripheralcomponentinterfaceexpress,pcie)或万兆以太网(gigabitethernet)。在本发明的一个实施例中,加速器控制模块20采用直接存储器控制(dma)进行数据控制,采用总线接口标准(pcie)与外部存储器相连。
时钟管理模块30,在设计空间探索阶段用于探索加速器在实际电压、温度、工艺偏差下可达的最高时钟频率,在应用阶段用于提供可编程器件实际所采用的频率,包括时钟源子模块31和频率控制子模块32。时钟源子模块31分别与加速器模块10、加速器控制模块20、频率控制子模块32相连,用于提供所要求的时钟。频率控制子模块32与温度测量模块40和时钟源子模块31相连,用于控制时钟源子模块31的频率,在实际最高频率探索中,还用于检验加速器计算结果的正确性。在本发明的一个实施例中,频率控制子模块32在外部主机(host)上实现。
温度测量模块40,与频率控制子模块32相连,用于向其传回片上的温度。
所述卷积神经网络的设计能够分别建立计算资源、带宽上限频率关于并行化参数的量化模型,采用卷积神经网络完成一次前馈运算的时钟周期数为并行化参数进行设计空间探索,有效地精简了参数设置,从而降低了设计空间探索的复杂度。所述时钟管理模块及温度测量模块在可编程器件上以硬核的方式实现,几乎不占用额外的逻辑资源,其结构简单灵活,易于实现。
根据以上结构设计,本发明可以分别建立计算资源、带宽上限频率关于并行化参数的量化模型。以ncycle表示完成一次前馈计算的时钟周期数,由于该参数限定了卷积神经网络各层并行策略的设计,因此以此表征卷积神经网络的并行化参数。
在计算资源方面,根据所述实施例所采用计算核结构,一个卷积计算核所需的专用数字信号处理器(digitalsignalprocessor,dsp)的个数为
在带宽方面,所述实施例结构下,神经网络的卷积层、全连接层所需的带宽资源分别为
图3是图1步骤s2的实际最高时钟频率探索流程图;该流程包括:
步骤s301,遍历该多个并行化参数从中选取一个并行化参数,推导其相应的并行策略,即选取一个不同的并行化参数,及对应的一组并行策略。
步骤s302,在指定的并行策略下,使用商业(通用)工具完成加速器的实现,获取商业工具报出的保守最高时钟频率,即使卷积神经网络加速器在商业工具的限制条件下运行该并行策略,限制条件包括多种安全阈值,例如温度安全阈值、电压阈值等。
步骤s303,在可编程器件上运行该并行策略下的加速器设计,加速器模块10循环读入输出已知的测试集进行运算。
步骤s304,在实际电压、温度、工艺偏差下,通过时钟管理模块30初始化可编程器件的运行频率为商业工具报出的保守最高时钟频率。
步骤s305,在一段时间内,实时监测该可编程器件的片内温度,读取温度测量模块40报出的器件温度,并实时判断该可编程器件温度是否稳定,若不稳定,则执行步骤s305继续监测该可编程器件的片内温度;否则,执行步骤s306。需要注意的是,这里的稳定指的是温度的变化范围在1摄氏度以内,也就是检测时发现温度不再上升。温度只要不影响器件安全运行,升到很高也可以接受;在商业工具中,温度高于安全阈值就会自动停掉,因此不用去考虑温度太高要执行308的环节,在这里,如果温度不稳定就依然执行305的目的是,要保证读取的计算结果是在器件热稳定的状态下读取的,以保证输出结果的稳定性及可靠性,判断器件是否达到热稳定的依据就是温度是否稳定。
步骤s306,检验该频率下卷积神经网络加速器的运算结果,即检验该可编程器件在当前频率下的运算结果是否正确。若正确,则执行步骤s307;否则,执行步骤s308。
步骤s307,通过时钟管理模块30提升可编程器件的运行频率。判断提升后的频率是否超出时钟源子模块31所能提供的频率上限值,若是,则执行步骤s308,否则,执行步骤s305。
步骤s308,停止频率提升,报出该并行化参数下,运算结果正确的最高时钟频率。
步骤s309,判断是否完成所有选取的并行化参数的探索实验,即判断是否对该多个并行化参数遍历完全,若是,则结束探索;否则,执行步骤s301。上述有关最高时钟频率的探索方法,可以根据实际的电压、温度、工艺偏差,利用商用设计工具针对最坏情况而预留的时延裕度,来获得更高的运行频率。
根据以上最高时钟频率探索结果,本发明通过拟合的方式建立加速器实际可达最高时钟频率关于并行化参数的分析模型,在本实施例中采用反比例指数衰减拟合模型,即
由于卷积神经网络加速器的计算资源及带宽使用不能超过目标器件所提供的最大值,假设目标器件的dsp、bram及带宽上限分别为
优化目标:maximize(f/ncycle)
约束条件:
f=min{fbw,fpvt}
根据所述问题描述,图1步骤s3的设计空间探索采用穷举搜索算法完成。针对目标器件intelalteraarria10芯片,图5给出了该实施例下的优化目标在不同的频率和并行化参数下的分布结果。图中的最高点对应的并行化参数及频率即为所求性能最优的设计参数。
以下为与上述方法实施例对应的系统实施例,本实施系统可与上述实施方式互相配合实施。上述施方式中提到的相关技术细节在本实施系统中依然有效,为了减少重复,这里不再赘述。相应地,本实施系统中提到的相关技术细节也可应用在上述实施方式中。
本发明还提供了一种基于可编程器件的卷积神经网络加速系统,其中包括:
量化模型建立模块、用于设计卷积神经网络在可编程器件上的基本结构,并根据该可编程器件所拥有的计算资源、可用带宽以及该基本结构,建立卷积神经网络加速器计算资源与并行化参数、带宽上限频率与并行化参数的量化模型,其中该基本结构包括该卷积神经网络加速器;
分析模型建立模块、输入多个并行化参数,根据该可编程器件的供电电压、片内温度、元件工艺,分别探索该可编程器件在各个该并行化参数下所能达到的最高时钟频率,集合该最高时钟频率作为实验结果,并根据该实验结果建立该最高时钟频率关于并行化参数的分析模型;
最优并行策略运行模块、用于根据该分析模型和该量化模型,求解出使该卷积神经网络性能最优的并行化参数,作为最优并行化参数,并根据该最优并行化参数推导出该卷积神经网络各层具体的最优并行策略,使得该卷积神经网络加速器运行该最优并行策略。
该基于可编程器件的卷积神经网络加速系统,其中该并行化参数为该卷积神经网络进行一次前馈运算的时钟周期数。
该基于可编程器件的卷积神经网络加速方法,其中该分析模型建立模块包括:
遍历模块、用于遍历该多个并行化参数从中选取一个并行化参数,推导其相应的并行策略;
通用设计模块、基于该并行策略,并使用通用工具完成该卷积神经网络加速器的设计,获取通用工具报出的保守最高时钟频率;
循环计算模块、用于在该可编程器件上采用该并行策略运行该卷积神经网络加速器,该卷积神经网络加速器根据已知的测试集进行循环读入输出运算;
初始化模块、用于初始化该可编程器件的运行频率为该保守最高时钟频率;
温度检测模块、用于实时监测该可编程器件的片内温度,判断该片内温度是否稳定,若是,则调用结果检验模块,否则,继续监测该片内温度直到其稳定;
结果检验模块、用于检验该可编程器件的运算结果是否正确,若正确,则调用升频模块;否则调用停止模块;
升频模块、用于提升该可编程器件的运行频率,并判断是否超出该可编程器件时钟源所能提供的上限频率,若是,则调用停止模块,否则调用该温度检测模块;
停止模块、用于停止该运行频率的提升,报出该并行化参数下运算结果正确的该最高时钟频率;
判断模块、用于判断是否对该多个并行化参数遍历完全,若是,则结束;否则调用遍历模块。
该基于可编程器件的卷积神经网络加速系统,其中该分析模型具体为反比例指数衰减拟合模型。
本发明还提供了一种包括该基于可编程器件的卷积神经网络加速系统的可编程器件设计方案。
综上所述,本发明通过探索实际电压、温度、工艺偏差下,卷积神经网络可达的最高频率,并以此建模进行设计空间的探索,使得卷积神经网络加速器的性能得到有效提升。
虽然本发明以上述实施例公开,但具体实施例仅用以解释本发明,并不用于限定本发明,任何本技术领域技术人员,在不脱离本发明的构思和范围内,可作一些的变更和完善,故本发明的权利保护范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!