一种基于多标记学习的浏览类业务感知指标预测方法与流程
本发明属于网络业务技术领域,尤其涉及一种基于多标记学习的浏览类业务感知指标预测方法。
背景技术:
移动网络用户在使用ott业务(如网页浏览,视频播放等)过程中,其业务体验的好坏一般可用一套kqi(关键质量指标)指标进行评价,比如网页打开时延、下载速率等。这种体验的好坏受多种因素的影响,包括终端质量、使用业务时所处位置的移动网络质量、app质量、sp网站服务器集群的带宽和负荷等。
电信运营商作为各类业务的传输通道提供方和业务体验保障的关键环节,需要尽可能保障用户的业务体验,否则可能导致用户投诉甚至离网。
目前一般是电信运营商的网络运维和优化部门通过日常的网络优化作业来保障网络质量,但网络质量与用户的业务体验之间仍然存在较大的差异,好的网络质量并不一定能保障良好的业务体验(由于业务体验是受前述的众多因素的综合作用)。客服部门只有在接到用户投诉时才发现业务体验的问题,再去协调网络运维和优化部门去排查问题和解决,往往很被动。
如果能在日常的网络运营中持续监测用户的业务体验,并根据海量的用户业务感知历史数据(不同场景下的业务感知指标的好坏),对用户在特定场景下的业务体验好坏做出预测和预警,则有助于及早发现业务体验问题并及时采取相关措施进行改善,并有效降低投诉率和离网率。
技术实现要素:
本发明要解决的问题是如何根据用户所处的场景对用户的网页浏览类业务的kqi指标进行及时、准确的预测,提供一种基于多标记学习的浏览类业务感知指标预测方法。
为实现上述目的,本发明采用如下的技术方案:
一种基于多标记学习的浏览类业务感知指标预测方法,包括以下步骤:
步骤s1、对浏览业务感知样本数据集构造训练样本集;
步骤s2、构造训练样本的k最近邻样本集;
步骤s3:计算先验概率和归一化频数矩阵
对每个标记项yj,j=1~q,按下面的公式(1)计算先验概率
其中,hj和
按下面的公式(2)(3)计算归一化频数矩阵[fj[r]k×q和
其中,δj(xi)表示的训练样本xi的近邻样本中具有标记yj的样本个数,[·]表示取整,fj[r]表示训练样本集中具有标记yj并且同时有占比为
步骤s4:构造未知样本x的k近邻样本集
对未知样本x,按照步骤s2的方法在训练样本集中构造出该样本的k近邻样本集
步骤s5:计算未知样本x的同标记统计
对每一个标记项yj,j=1~q,按照公式(4)统计
步骤s6:计算未知样本x的似然概率
按公式(5)(6)计算似然概率
其中,
步骤s7:估计未知样本x的标记值
由下式(7)和(8)计算得到未知样本x的标记集y的估计值{y1,y2},即
考虑到首包时延和页面打开时延两个指标的强相关性,尤其是首包时延对页面打开时延的影响,在估计y2也即页面打开时延的标记项是否成立(即标记值为1)时,采用如下方式计算:
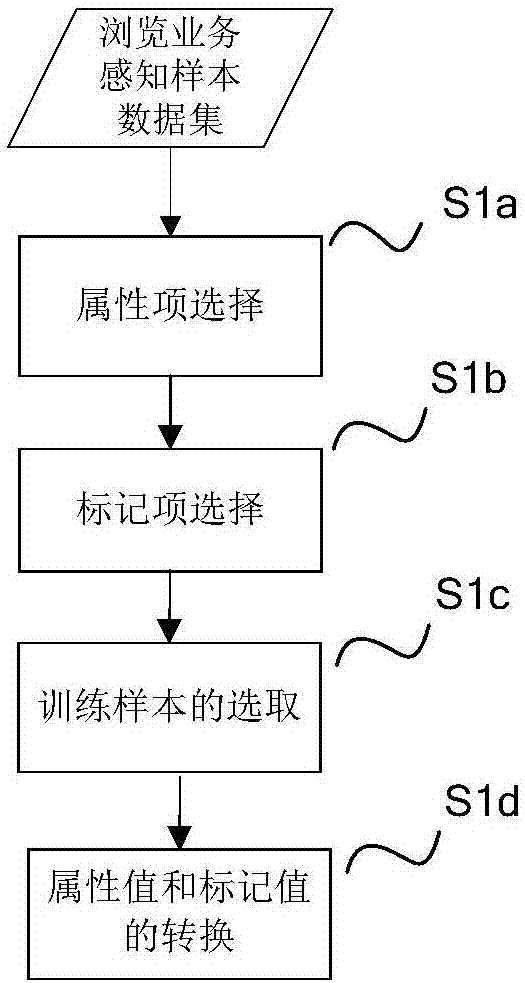
作为优选,步骤s1包括以下步骤:
步骤s1a、训练样本集的属性项选择
从样本的所有字段中选择其子集,即{日期,时间,经度,纬度,大区编号,小区编号,场强,信号质量,网站名称,网站ip,dnsip,用户标识,终端型号},作为训练样本的属性集x={x1,x2,...,xd},d为属性集的维度;其中,属性字段{日期,时间,经度,纬度,场强,信号质量}为数值型数据,属性字段{大区编号,小区编号,网站名称,网站ip,dnsip,用户标识,终端型号}为名目型数据;
步骤s1b、训练样本集的标记项选择
从样本所有字段中选择其子集,即{首包时延,页面打开时延},作为训练样本的标记集y={y1,y2,...,yq},q为标记集的维度,其中,标记字段{首包时延,页面打开时延}为布尔型数据;
步骤s1c、训练样本的选取
根据步骤s1a和步骤s1b中选定的属性集和标记集,从浏览业务感知样本集中随机选择m个样本作为训练样本集d,即d={(xi,yi)|1≤i≤m};
步骤s1d、训练样本属性值和标记值的转换
如果训练样本中的日期和时间的原始值不是数值型数据,则进行转换:以某个日期为基准,将该日期取值定义为0,以距离基准日期的天数作为训练样本中日期值的表示,时间则以零时为基准点、以分钟为颗粒度表示,
对训练样本中的所有数值型数据利用以下公式进行归一化,即:
其中
对于训练样本中的各标记字段{首包时延y1,页面打开时延y2},其在原始的“浏览业务感知样本集”中均为数值型数据(分别记为
其中,函数[c]表示当条件c成立时返回1,否则返回0。
作为优选,步骤s2中对训练样本集中的每个样本矢量xi,i=1~m,在训练样本集中寻找该样本矢量的最多k个最近邻样本,构成该样本矢量的k最近邻样本集
步骤s2a、对样本矢量xi={xil,l=1~d},在训练样本集中根据日期属性,寻找所有与xi1的距离小于设定门限td(默认值为10)的样本,构成初始最近邻样本集
步骤s2b、在初始最近邻样本集
步骤s2c、计算中间最近邻样本集
本发明的有益效果如下:
根据海量的用户业务感知历史数据(不同场景下的业务感知指标的好坏),对用户在特定场景下的业务体验好坏做出预测和预警,有助于及早发现业务体验问题并及时采取相关措施进行改善,并有效降低投诉率和离网率。
附图说明
图1为本发明预测方法的流程图;
图2为构造训练样本集的流程图。
具体实施方式
如图1、2所示,本发明提出了一种基于多标记学习的浏览类业务感知指标预测方法,包括以下步骤:
步骤s1:构造训练样本集
已知某城市的本地移动网络下(如北京移动的lte网络),当用户在智能终端上使用网页浏览类业务app(如ucweb、qq浏览器等)浏览预定义的目标网页集合(如新浪主页,搜狐主页等)中的某个网页时,通过部署在用户终端上的数据采集app等方式,获取此时的“网页浏览业务感知样本”;在一定时间范围内、从海量用户终端上采集的全部样本构成了“浏览业务感知样本集”。
网页浏览业务感知样本其所包含的信息(即样本字段)应至少包括:日期,时间,网络制式,小区标识,终端当前经纬度,场强(不同的制式下名称不同:如gsm网络的rxlevel,lte网络的rsrp等),信号质量(不同的制式下名称不同:如c/i或sinr或rsrq等),用户标识(imsi),终端标识(imei或meid),终端型号,浏览器app名称,浏览网站名称,浏览网站url,浏览网站ip,dnsip,首包时延,页面打开时延,dns解析时延,tcp连接时延,get请求时延,接收响应时延。
其中:小区标识为唯一确定一个小区的标识参数的组合,一般由大区编号+小区编号组成。对不同网络所使用的参数名称不同,如gsm、wcdma、td-scdma网络为lac+ci,lte为tac+eci。
其中:“首包时延”定义为从用户发起网页浏览请求到收到目标服务器响应的第一个http200ok报文包之间的所经历的时长。首包时延=dns解析时延+tcp连接响应时延+get请求响应时延。
其中:“页面打开时延”定义为从用户发起浏览请求到整个http页面下载完毕(仅页面文本内容,不包含资源的二次加载)的时长。页面打开时延=首包时延+接收响应时延。
其中:“dns解析时延”指从终端发起dns解析请求开始到完成dns解析的时延;“tcp连接时延”指从dns解析结束到tcp连接(三次握手)建立完成的时延;“get请求时延”指从发出get请求到收到第一个tcp数据包(含http200ok)的时延;“接收响应时延”指从收到第一个响应数据包开始到终端发出[fin,ack](即接收完成)的时延。
步骤s1a:训练样本集的属性项选择
从上述样本的所有字段中选择其子集,即{日期,时间,经度,纬度,大区编号,小区编号,场强,信号质量,网站名称,网站ip,dnsip,用户标识,终端型号},作为训练样本的属性集x={x1,x2,...,xd},d为属性集的维度,这里d=13;其中,属性字段{日期,时间,经度,纬度,场强,信号质量}为数值型数据,属性字段{大区编号,小区编号,网站名称,网站ip,dnsip,用户标识,终端型号}为名目型数据;
步骤s1b:训练样本集的标记项选择
从上述样本的所有字段中选择其子集,即{首包时延,页面打开时延},作为训练样本的标记集y={y1,y2,...,yq},q为标记集的维度,这里q=2;其中,标记字段{首包时延,页面打开时延}为布尔型数据;
步骤s1c:训练样本的选取
根据步骤s1a和s1b中选定的属性集和标记集,从浏览业务感知样本集中随机选择m个样本作为训练样本集d,即d={(xi,yi)|1≤i≤m};
步骤s1d:训练样本属性值和标记值的转换
如果训练样本中的日期和时间的原始值不是数值型数据,则进行转换:以某个日期为基准(如2015年1月1日),将该日期取值定义为0,以距离基准日期的天数作为训练样本中日期值的表示。时间则以零时为基准点、以分钟为颗粒度表示。
对训练样本中的所有数值型数据利用公式(1)进行归一化,即:
其中
对于训练样本中的各标记字段{首包时延y1,页面打开时延y2},其在原始的“浏览业务感知样本集”中均为数值型数据(分别记为
其中函数[c]表示当条件c成立时返回1,否则返回0。
步骤s2:构造训练样本的k最近邻样本集
对训练样本集中的每个样本矢量xi,i=1~m,在训练样本集中寻找该样本矢量的最多k个最近邻样本,构成该样本矢量的k最近邻样本集
步骤2a:对样本矢量xi={xil,l=1~d},在训练样本集中根据日期属性,寻找(除该样本自身之外)所有与xi1的距离小于设定门限td(默认值为10)的样本,构成初始最近邻样本集
步骤2b:在初始最近邻样本集
步骤2c:计算中间最近邻样本集
步骤s3:计算先验概率和归一化频数矩阵
对每个标记项yj,j=1~q,按下面的公式(2)计算先验概率
其中,hj和
然后,按下面的公式(3)(4)计算归一化频数矩阵[fj[r]]k×q和
其中,δj(xi)表示的训练样本xi的近邻样本中具有标记yj的样本个数,[·]表示取整。则fj[r]表示训练样本集中具有标记yj并且同时有占比为
步骤s4:构造未知样本x的k近邻样本集
对未知样本x,按照步骤s2的方法在训练样本集中构造出该样本的k近邻样本集
步骤s5:计算未知样本x的同标记统计
对每一个标记项yj,j=1~q,按照公式(5)统计
步骤s6:计算未知样本x的似然概率
按公式(6)(7)计算似然概率
步骤s7:估计未知样本x的标记值
在前面各步骤计算结果的基础上,即可由下式(8)和(9)计算得到未知样本x的标记集y的估计值{y1,y2}。其中:
考虑到首包时延和页面打开时延两个指标的强相关性,尤其是首包时延对页面打开时延的影响,在估计y2也即页面打开时延的标记项是否成立(即标记值为1)时,采用如下方式计算:
- 还没有人留言评论。精彩留言会获得点赞!