利用音形特征描述汉字的相码拼字法及以其为基础的相码输入法的制作方法
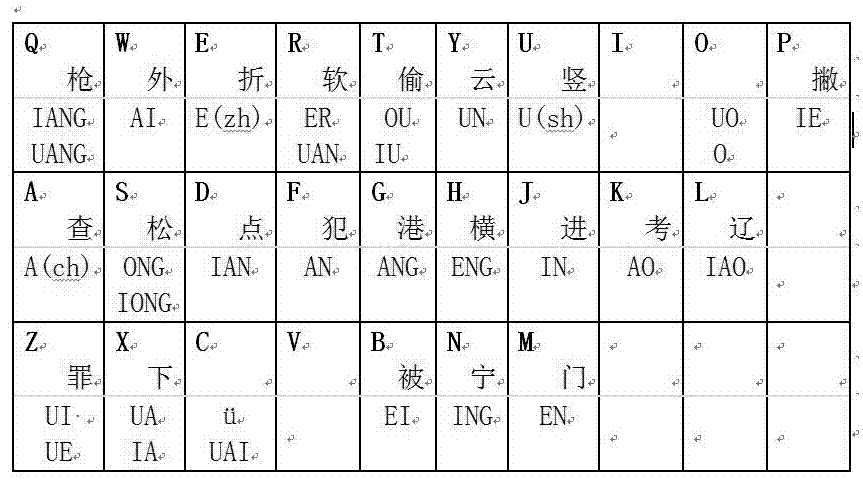
本申请涉及中文信息处理领域,尤其涉及利用音形特征描述汉字的相码拼字法及以其为基础的相码输入法。
背景技术:
随着信息技术的发展,汉字录入问题受到广泛关注。与英语等由字母直接拼写的文字不同,汉字是由笔画构成的方块形符号,且数量众多,用户想要输入汉字,不能由键盘字母键直接输入,必须依靠输入法完成。在输入法发展过程中,拼音输入法、五笔输入法扮演着重要角色,分别代表了音码输入和形码输入的技术成就,但拼音输入法重码多,特别在单字输入时缺点明显,五笔输入法重码率低,但比较难学。近年来,出现过不少音形结合的输入法,但并未在用户中广泛普及,一方面是因为拼音输入与五笔输入的传统影响力依然存在,另一方面是因为很多输入法在易用性、低重码率、码长控制等方面相比拼音与五笔并无明显优势。此外,五笔输入法的盲打特性和输入速度依然难寻对手,这一特色使其在汉字速录领域也曾占有一席之地。理想的输入法,应该能将五笔的低重码率、码长优势与拼音的易用性结合起来,如果有条件,还应同时向用户提供一种汉字快速拼写的辅助平台,使用户在录入、拼写、识别相互统一的环境中进行汉字的输入。
技术实现要素:
鉴于上述问题,本发明提出了一种利用音形特征描述汉字的相码拼字法及以其为基础的相码输入法,以便提供一种克服上述问题或者至少部分地解决上述问题的方法,包括以下内容。
一、相码拼字法基本设定
(1.1)使用26个英文字母(abcdefghijklmnopqrstuvwxyz)和10个数字“0123456789”共36个码元(其中5不参加具体编码,仅作为特殊连字符使用)对汉字及汉字词组进行拼写,26个字母拼写时不区分大小写;
(1.2)单字与词组的编码范围相互独立;使用相码拼字法表示汉语的单字或词组时,必需以字母码元开始,不能出现数字;单字拼写时编码最少为1码元;词组拼写时最少为4码元;对gb2312标准中的汉字单字,可利用31个码元(编码码元为26个英文字母和“01234”这5个数字)在4码内实现无重码拼写,且易于识读,便于手写,可作为汉字录入、盲文标注、手写速记、汉字辅助教学的编码方案;
(1.3)表示汉字发音时,采取类似于双拼的规则,用两个英文字母表示某个字的读音,第一个字母表示该汉字的声母,本方案称作双拼声母,第二个字母表示该汉字的韵母,本方案称作双拼韵母;本方案中用e、a、u表示声母zh、ch、sh,韵母自成音节的,将字母“o”作为其双拼声母,其余韵母对应的双拼韵母分别为:
a代表韵母a;b代表韵母ei;c代表韵母ü、uai;d代表韵母ian;
e代表韵母e;f代表韵母an;g代表韵母ang;h代表韵母eng;
i代表韵母i;j代表韵母in;k代表韵母ao;l代表韵母iao;
m代表韵母en;n代表韵母ing;o代表韵母uo、o;p代表韵母ie;
q代表韵母iang、uang;r代表韵母er、uan;s代表韵母ong、iong;
t代表韵母ou、iu;u代表韵母u;w代表韵母ai;x代表韵母ua、ia;
y代表韵母un;z代表韵母ui、ue;
为方便记忆,有助记(助记汉字读音均为双拼声母键重复所得,其中cio重复后无相应读音的汉字)口诀为:点横撇竖折,cio,枪被偷,辽宁港外查罪犯,松下进门考软云;
(1.4)采取数字替代原则、备韵替代原则、声调识别策略降低词组的重码率;
(1.5)采取主备韵原则、偏旁分类原则、笔画识别策略降低汉字单字的重码率;
(1.6)将汉字笔画划分为“点、横、叉、撇、竖、折”六类;其中“点、横、撇、竖、折”依据《现代汉语通用字笔顺规范》划分,分别为一(横)、丨(竖)、丿(撇)、丶(点)、乛(折)这五种基本笔画,其中,一(提)归为一(横),亅(竖钩)归为丨(竖),丶(捺)归为丶(点),各种折笔笔画归为乛(折);“叉”类笔画包含“扌”、“艹”、“廴”、“乂”、“九”、“又”、“丰”、“毋”等,其主要特征是有两个及两个以上的基本笔画相交;
(1.7)将汉字划分两大类,一类为基本字,另一类为衍生字;当某一汉字无偏旁或该汉字加常用部首后能构成其他汉字时,可判定其为基本字,否则为衍生字;基本字在编码时用读音区分,若有重码,在双拼声母与双拼韵母中间位置插入(当该字声调为一声或二声)字母“v”或在双拼韵母位置后插入(当该字声调为三声或四声)字母“v”,然后在第四码元位置加笔画识别码区分;而衍生字则需在读音的基础上增加偏旁分类码区分,若仍有重码,则需再加笔画识别码区分;
(1.8)确定汉字读音编码时将读音编码划分两大类,一类为主韵码,另一类为备韵码;当汉字以“点、横、叉”笔画起笔(当汉字为衍生字时,起笔指除去偏旁后的起笔),其读音编码为主韵码,否则为备韵码;因编码空间有限,主韵码和备韵码可以相同;
(1.9)笔画识别策略是利用汉字本身的笔画特征作为单字的笔画识别码;主要方法是将组成该汉字的所有笔画中“点”、“横”、“叉”的数量值“模5”后(即除以5的倍数,保证余数在01234的范围内)所得余数值作为识别码;
(1.10)偏旁分类原则:将衍生汉字的偏旁划分为确定性偏旁和非确定性偏旁;确定性偏旁有“金、木、水、火、土、丝、竹、犬、鸟、虫、草、衣、言、手、足、刀、口、立、人、心”共20类,分别用“j、m、u、h、t、s、e、q、n、a、c、i、y、p、z、d、k、l、r、x”表示(不区分大小写);非确定性偏旁即确定性偏旁之外的其它偏旁,根据其起笔及其所构成汉字的读音声调,又可分为“变、改、往、复”四类,分别用“b、g、w、f”表示(不区分大小写);具体可见下表:
(1.11)声调识别策略:为准确反映词组中每个字的声调,引入声调识别码,因偶数词组可由前至后划分为若干二字词的组合,奇数词组可由前至后划分为若干二字词和最后一个单字的组合,所以可由字母“lqbj”分别表示奇数词组中最后一个单字的拼读声调为1、2、3、4声;将二字词组中两个单字的声调组合用其余21个英文字母(不含v)表示,字母不区分大小写;其中数字“0”表示单字在词组中发音为轻声,数字“1、2、3、4”分别表示单字在词组中发音为1、2、3、4声;其中字母“ircs”表示二字词组中第二字声调为轻声,字母“o”表示二字词组中两个字声调均为轻声,字母“kgzmdfyupenhwaxt”分别表示前后字的1234声形成的16种情况;具体可见下表:
多字词组可由二字词与单字叠加组合而成,故声调识别码可准确标记词组的读音,叠加形式为“第一声调识别码+数字0+第二声调识别码+…+第n声调识别码”。如:三字词“巴格达”的编码为vbagedag0q,其中声调识别码为“g0q”。
二、相码拼字法的核心规则
(2.1)主备韵原则
根据汉语拼音的音节规律,普通话方案中的汉字读音约420个,而双拼编码时,声母位和韵母位均可使用26个英文字母表示,音节编码空间为676个,所以编码空间存在浪费。对汉字双拼音节进行分析,可发现声母“bpmf”、“dtnl”、“gkh”、“jqx”、“eaurzcs”(zh、ch、sh分别用e、a、u代替)、“yw”所对应的韵母有一定的互补性,所以在编码时,可以利用这种互补特性充分利用双拼编码的空间;
例如:对声母“e(zh)a(ch)u(sh)rzcsy”,其组成音节时不能出现与韵母“p(ie)、d(ian)、l(iao)、j(in)、n(ing)”相拼的形式,可以出现与韵母“e(e)、f(an)、k(ao)、m(en)、h(eng)”相拼的形式;
再例如:对声母“jqx”,其组成音节时不能出现与韵母“e(e)、f(an)、k(ao)、m(en)、h(eng)”相拼的形式,可以出现与韵母“p(ie)、d(ian)、l(iao)、j(in)、n(ing)”相拼的形式;
所以,在相码拼字法中,将ep、fd等这种韵母成对出现、一个可与声母组成音节而另一个不可与声母组成音节的关系称为主备韵关系;其中可与声母组成音节的韵母称为主韵,二者组成的音节称为主韵音节;不可与声母组成音节的韵母称为备韵,二者组成的音节称为备韵音节;
可以看出,efkmh与pdljn之间有一定的对应关系;对声母“e(zh)a(ch)u(sh)rzcsy”,将efkmh称为主韵,pdljn称为备韵,ee等称为主韵音节,ep等称为备韵音节;对声母“jqx”,将pdljn称为主韵,efkmh称为备韵,jp等称为主韵音节,je等称为备韵音节;
在对单字编码时,对具有主备韵关系的声母,可以通过主韵、备韵,扩大编码容量;特别对于韵母为i或u的音节,同音字个数最多,所以在单字编码时,规定以i为韵母的汉字均存在主备韵关系,其主韵音节为“声母+i”,备韵音节为“i+声母”,即码元互换;其中主韵汉字以“点横叉”为起笔(衍生字为去掉偏旁后的起笔),备韵汉字以“撇竖折”为起笔(衍生字为去掉偏旁后的起笔);以li为例,其主韵音节为“li”,备韵音节为“il”;
汉字主备韵音节的情形如下表所示:
(2.2)数字替代原则
数字替代原则仅在词组编码时生效;
对4码元表示的二字词,编码时,先将每一单字的双拼编码按先后顺序拼写后得到该二字词的编码;若词组中单字发音韵母为i或u,且该字在词组中的发音不为轻声时,还需将该字双拼码中的韵母根据其读音声调用数字替代,当韵母为i时,“1、2、3、4”分别表示1、2、3、4声,当韵母为u时,“6、7、8、9”分别表示1、2、3、4声;若二字词仅有第二字进行了数字替代,为了与单字的编码区分,需将替代后的第二字编码声韵码元互换位置;
如:“小心”的双拼码为xlxj,“小”、“心”二字的发音韵母不含i或u,故“xlxj”就为其相码编码;
又如:“比例”的双拼码为bili,“比”、“例”均为以i为韵母的汉字,“比”的声调为3声、“例”的声调为4声,将“bili”中的i分别替换为3、4,得到“b3l4”,即为“比例”的相码编码;
又如:“鼓励”的双拼码为guli,“鼓”为以u为韵母的字,“励”为以i为韵母的字,“鼓”的声调为3声、“励”的声调为4声,将“guli”中的韵母u、i分别替换为8、4,得到“g8l4”,即为“鼓励”的相码编码;
又如:“替代”的双拼码为tidw,“替”字为以i为韵母的汉字,“替”的声调为4声,将“tidw”中的韵母i替换为4,得到“t4dw”,即为“替代”的相码编码;
又如:“原理”的双拼码为yrli,“理”字为以i为韵母的汉字,“理”的声调为3声,将“yrli”中的韵母i替换为3,得到“yrl3”,为了与单字的编码区分,需将替代后的第二字编码声韵码元“l3”互换位置得到“3l”,最终得到的编码“yr3l”即为“原理”的相码编码;
类似地,对以字母“v”开头的编码表示的词组,若词组中单字发音韵母为i或u,且该字在在词组中的发音不为轻声时,将该字双拼码中的韵母根据其读音声调用相应的数字进行替代,当韵母为i时,“1、2、3、4”分别表示1、2、3、4声,当韵母为u时,“6、7、8、9”分别表示1、2、3、4声;因v开头的编码表示词组时码长至少为5,不与单字编码产生歧义,此时无需考虑二字词编码时的码元互换;
(2.3)备韵替代原则
为提高4码长相码的编码容量,二字词中第一个字的读音编码可以出现备韵,得到的新编码可表示读音相同的另一个二字词;
如:“北京”与“背景”,“北京”的编码为bbjn,“背景”的编码为bzjn;
二字词中第二字的读音编码一般不允许出现备韵,但第一个字的编码使用数字替代时,第二字的读音编码可以出现备韵;
如:“比肩”和“笔尖”,“比肩”的编码为b3jd,“笔尖”的编码为b3jf;
需要注意的是,在组词时,声母为n、l的字无主备韵关系,韵母为i、u的字无主备韵关系;
(2.4)换位替代原则
为提高4码长相码的编码容量,二字词中的第一字和第二字均使用数字替代规则时,可允许将第三码元和第四码元位置进行互换,得到的新编码,可表示读音相同的另一个二字词;
如“只是”和“指示”,“只是”的编码为e3u4,“指示”的编码为e34u;
(2.5)字词分离原则
为保证编码的易识别性,通过合理设定,相码拼字法单字编码和词组编码作显性区分,用户在拼读时不会产生歧义;
汉字词组至少为4码,其中常用二字词为4码,按组成该词的单字双拼码顺序拼写而成,典型的拼写形式为“声码+韵码+声码+韵码”,其中声码一般为双拼声母,韵码一般为双拼韵母;其余词均以字母“v”开头,码长在5码及以上,拼写时由字母“v”开头,然后将组成该词的单字双拼码顺序拼写,然后加声调识别码,典型的三字词拼写形式为“v+声码+韵码+声码+韵码+声码+韵码+第一声调识别码+0+第二声调识别码”;
按数字替代原则,在词组拼写时,韵码位置一可出现“12346789”这八个数字形式的码元;
对gb2312中的汉字,单字拼写编码最多为4码元(大部分为3码元以内,4码元的字不足1200个),且前三码元均为字母,不能出现数字,而第四码元位置仅能出现“01234vui”这几个码元;完整的4码元表示的汉字单字拼写规则一般为:拼写时前两码为汉字的读音,第三码为汉字的偏旁分类码,第四码为该汉字的笔画识别码,识别码用数字0、1、2、3、4表示,有些汉字的编码较为特殊,可能会在第四码元位置出现vui这些编码码元,但此时4个码元无法拼读为二字词,不会产生歧义;
对gb2312中的汉字单字,按使用频率的高低可依次用1码元、2码元、3码元、4码元拼写;可用1码元表示的26个字为特高频字,一般取该字的声母;可用2码元表示的字为高频字,一般取该字的读音;可用3码元表示的为常用字,拼写时前两码表示该字的读音,第三码为该字的偏旁分类码;4码元表示gb2312中的其余汉字;
(2.6)分类与优先策略
为保证实用性,相码拼字法对汉字单字和汉语词组进行了分类;
词组分为核心词组与扩展词组,核心词组以二字词为主,用前后字的双拼编码共4码元表示,其余词为扩展词组,以“v+各字双拼码+声调识别码”的形式表示;在按前述拼写规则产生重码时,使用频度高的二字词优先编码,将其余二字词归入扩展词组,用以字母“v”开头的编码表示;如“变量”和“汴梁”的编码同为bdlq,将常用词“变量”优先编码为bdlq,另一词“汴梁”用vbdlqa表示;
扩展词组中二字词声调识别码可用一个字母表示;如vbdlqa表示“汴梁”,vbdlqt表示“变亮”;当仍有重码出现时,在声调识别码后加数字0,然后加重码序号,重码序号用字母“i、r、c、s、v、l、q、b、j”分别表示第1、2、3、4、5、6、7、8、9个重码的二字词;如vbdlqa0i表示“变凉”;
扩展词组中三字词以上的词组声调识别码用多个字母顺序表示;三字词、四字词的声调识别码为两个字母,五字词、六字词的声调识别码为三个字母,以此类推;为便于拼读,两个字母以上的声调识别码组合使用时,在第一个声调识别码字母与第二个声调识别码字母之间插入数字0;如“叶公好龙”的编码为vyegshklsw0a,“掩耳盗铃”的编码为vyfordklnn0a;
对gb2312中的汉字,可分为基本字与衍生字;衍生字由“音节编码+偏旁分类码”的3码元形式表示,若产生重码,使用频度高的字优先编码,其余字由“音节编码+偏旁分类码+笔画识别码”的4码元形式表示;
基本字又可分为音节字、声调字、偏旁字、形旁字、特殊字;
音节字一般为该音节的代表字,用两位双拼码表示,根据字的起笔按主备韵原则拼写;如:“无”为发音为wu的汉字音节的代表字,其起笔为横,故编码为wu;“吴”也为发音为wu的汉字音节的代表字,因其起笔为竖,故按主备韵原则,其编码为iw;
声调字一般为带声调(1、2、3、4声)音节中的典型汉字,1、2、3声的声调字用v与该字的双拼编码组合表示,v出现在第几码元位置,则表示该字声调为几声;4声的声调字用双拼编码加字母“o”表示;如:vwu、wvu、wuv、wuo分别表示巫、毋、武、戊;与音节字类似,声调字也适用主备韵原则;
声调字若有重码,使用频度高的字优先编码,其余字中声调为1、2声的可用“双拼声母+v+双拼韵母+笔画识别码”的形式表示,声调为3、4声的可用“双拼声母+双拼韵母+v+笔画识别码”的形式表示。如:“吾”为声调字,与声调字“毋”的编码均为wvu,发生重码,因“毋”比“吾”使用频度更高,故“毋”优先使用编码wvu,“吾”的编码为wvu4;
偏旁字为偏旁分类码的类别名,其拼写形式为“v+偏旁分类码”,如“金”的编码为“vj”,“变”的编码为“vb”;
形旁字为偏旁部首表中列出的非完整字型的偏旁,用“vv+偏旁分类码”的形式拼写,重码时用笔画识别码区分;如“钅”,其偏旁分类码为j,故其编码为vvj;
特殊字包括26个特高频字,24个次高频字和17个方位数量字,拼写形式如下表:
根据分类与优先策略,用户可很容易地对相码进行拼读,以下是相码的常见编码形式:
(2.7)例外与次优编码策略:由于汉字的复杂性,同时出于码长控制、易拼读性等方面的考虑,相码拼字法允许例外的存在,即在对某些字、词编码时可不严格遵守相码拼字法所有规则,而是根据编码的整体情况单独制定规则进行编码,这些例外的存在虽然破坏了编码的严谨性,但保证了整体编码的实用性,这一策略可能不是最优策略,但应该是最有效的策略,本方案中称此为次优编码策略;
本编码的例外有:音节编码时,为提高实用性,将个别发音特殊的非常用字单独编码,编码的后两位以“ov”结尾,其原先双拼音节则表示其它常用汉字音节;这些例外字包括:嗲(发音为dia)、俩(发音为lia)、诶(发音为ei)、呒(发音为m)、嗯(发音为n)、哦(发音为o),编码分别为“dxov,lxov,obov,omov,onov,ooov”;
本编码的例外还包括:为方便记忆,对表示数量的“一二三四五六七八九十”及其大写形式单独编码,具体见下表:
本编码的例外还包括:为方便记忆,对非确定性偏旁中非完整字偏旁单独编码,“丶、丿、丨”的编码分别为“oid、oip、oiu”,其余偏旁拼写形式一般为“o+笔画数+该偏旁代表字声母”,其中笔画数以“o、i、r、c、s、v、l、q、b、j、io”分别表示0、1、2、3、4、5、6、7、8、9、10,当偏旁笔画数为2时,因编码与“而”字的发音相同,为避免歧义,在第4码元位置加字母v,以示区别;具体编码见下表:
本编码的例外还包括:本方案中双拼韵母为t时,表示韵母为ou、iu,当声母为lmnd时,会出现音节表示的歧义,例如对声母l,lt的拼写形式会出现“楼”与“留”的歧义,对声母m,会出现“某”与“谬”的歧义,该情况下,可将“留”的音节用lx来表示;具体见下表:
三、相码拼字法的扩展规则
(3.1)对gb2312字库以外汉字的拼写策略
对常用简化字的繁体字,可在其编码的基础上在第二码元位置插入“0”;如“无”的繁体字为“無”,“无”的编码为wu,故“無”的编码为w0u;据统计,大部分简化汉字可用3码元表示,所以其对应的繁体字多数为4码元编码;对简化字编码为4码的字,在其原编码第二码元位置插入0后,可在不造成歧义的情况下省略笔画识别码,将码长控制在4码,省略时常用字优先;
对有确定读音的的字,按前述基本规则编码,但笔画识别码的范围扩大到01234v6789,其中“01234”优先使用,“v6789”分别为“01234”的候补识别码;
如:“巓”的编码为ddu9,因ddu4为“滇”字的编码,所以笔画识别码需要用4对应的候补识别码9来替补,最后确定“巓”的编码为ddu9;
特别地,对韵母为i或u的字,因4码长的二字词编码中韵母i或u均被“12346789”等数字码元替代,故gb2312字库以外的字编码时,在第4码元位置上可使用除“5”外的所有35个码元,不会产生歧义,这些码元的使用次序如下表所示:
如:“矖”的编码为lim2,“棙”的编码为lim7,“櫔”的编码为limq;
若仍有重码,在第三码元位置插入“0”,笔画识别码依次可使用所有35个码元;
如:“㹯”的编码为xt0q,“䝗”的编码为xt0q4,“䮌”的编码为xt0q3;
(3.2)特殊发音的字
在gb2312字库之外的汉字中,有些字《汉语拼音方案》中的标准拼音无法拼读,为保证兼容性,将这些字用以“fi”或“fi+数字0”开头的编码表示;其中“fi”开头的字为4码长编码,“fi+数字0”开头的字码长最短为5;
如:“噷”的编码为fihm,“瓸”的编码为fi0bwwa,“瓰”的编码为fi0fmwa;
(3.3)数字5的使用
在拼写多字词时,可将数字5作为连接符号使用;通过数字5连接若干个单字、词组相码后形成的新编码,可作为一个整体使用;如:“中华人民共和国”,可分别拼写为“eshxrmmjgshegv”,中间以空格隔开,也可用数字5将各个相码连接后拼写为“eshx5rmmj5gshe5gv”,既便于识别,也能作为一个整体使用;该拼写方式可用在某些特殊场景下,也可用于手工拼写。
四、相码输入法的使用规则
(4.1)相码输入法的整体特征
编码需以字母开头,若为数字,则不为相码编码;
编码码元为“abcdefghijklmnopqrstuvwxyz012346789”,共计35码元;
输入法不支持5作为连接符的词;
输入法支持单字、二字词、三字词、四字词输入,词库中未收录的词,可按照单字形式逐字输入,也可由用户合理拆分为词与字的组合后分别输入;
以v开头的编码,可能为单字,也可能为词组,但均需以空格键上屏;
第二码元或第三码元位置为数字0的编码,肯定为单字,需以空格键上屏;
gb2312字库内的汉字,编码码长均在4码以内;
码长为4的编码,若第二或第三码元为0,则为单字,若前三码元均为字母,第四码元为“012346789v”,则为单字;其余情况一般为二字词;
输入法平台提供候选字或候选词提示,用户可按提示依次键入相应的编码,得到想要的结果;当熟练后,可盲打输入;
(4.2)gb2312字库内的单字输入
码长均为4码以内,4码时自动上屏,不足4码时敲击空格键上屏;
(4.3)gb2312字库以外的单字输入
当第二或第三码元为0时,无论码长为多少,需敲击空格键上屏;
其余编码,4码时自动上屏,不足4码时敲击空格键上屏;
(4.4)词组输入
码长为4码的为常用二字词,自动上屏;
以v开头的码长大于4的为其余词组,可键入全部相码编码,然后以空格键上屏;
当在输入词组一部分编码后,无其他编码与当前键入的编码重复时,可直接敲击空格键上屏,无需键入剩余的编码;
(4.5)简码输入规则
据统计,在gb2312字库中,一级字库为3755字,二级字库为3008字,其中一级字库中的汉字占用户日常用字的99%以上,但本方案中并未将此3755字的相码编码完全压缩在3码长以内,编码为4码的字有300字左右;为提高输入效率,对一级字库中码长为4的字,在相码编码之外,增加了简码编码,编码码元仍为35码元,码长控制为3码,个别字为2码;输入时需要使用用空格键上屏;编码形式有:
对点横叉开头的字,简码为“双拼声母+双拼韵母+汉字声调”,其中声调优先使用“1、2、3、4”表示1、2、3、4声,若有重码,分别用“6、7、8、9”作为替补编码;简码编码时主备韵原则可以使用;
若仍有重码,将其中一个汉字优先编码,其它字用采用换位法策略,即表示汉字声调的码元(数字12346789)与韵母交换位置得到新的编码;
若仍有重码,对韵母为i的字,选其中一个汉字优先编码,其它字可用双拼声母加声调编码表示。
附图说明
图1是本发明的一种输入法的双拼键位及助记汉字分布图;
图2是本发明的一种声调识别码助记键位分布图;
图3是本发明的一种笔画识别码替补码元键位图;
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
本发明实施例提出了一种综合利用汉字音、形特征描述汉字的相码编码和相应的输入法方案,该方案以汉字使用频度、汉字起笔、汉字偏旁、汉字笔画中点横叉的数量等特征作为同一读音汉字的编码区分特征,通过适当的规则和合理的策略,尽可能合理地实现“易辨识、易学习、易拼读、易输入”的汉字无重码编码;由于上述考虑,用户将会很容易使用本方案提供的输入法进行汉字高效录入,在经过一段时间的学习后,还能根据本方案实现简单的手工拼写,随着用户输入次数的积累,本发明实施例提供的编码方案将逐步转换为用户的拼读习惯,对输入平台的熟练程度将会进一步提高用户的输入效率。
方法实施例一
如词组“清华大学”,用户可按单字输入,也可按两个二字词输入,也可按四字词整体输入;
按单字输入时,“清”字的编码为qnu,其相码编码原理为:“清”为衍生字,偏旁分类码为u,使用频度高,优先编码,故不需增加笔画识别码;“清”字去掉偏旁后起笔为叉,按照主备韵原则,发音用主韵编码qn表示,综合考虑,其编码为qnu;输入时,不足4码,键入编码后,用空格键上屏;“华”字的编码为hx,其相码编码原理为:“华”为音节代表字,以撇起笔,hx的无主韵码与备韵码的区分,故其最终编码为hx;输入时不足4码,键入hx后,敲空格键上屏;“大”字的编码为da,与“华”字的编码原理相同,输入过程相同;“学”字编码为x,其相码编码原理为:“学”为特殊字中的高频字,用双拼声母x表示,输入时不足4码,键入x后,敲空格键上屏;
按两个二字词输入时,“清华”编码为qnhx,其相码编码原理为:“清华”为常用二字词,码长为4,按“清”、“华”二字各自的双拼编码依次排列,因“清”、“华”二字韵母均非i或u,不涉及数字替代原则,同时也不涉及备韵替代原则,故编码为qnhx,码长为4,编码中第二或第三码元不为0,第一码元不为v,故系统自动上屏;“大学”编码为daxz,编码原理与“清华”相同,输入过程与“清华”相同;
按四字词输入时,“清华大学”编码为vqnhxdaxzg0a,其相码编码原理为:四字词以v开头,参照图1,“清”、“华”、“大”、“学”各字的双拼编码依次排列,参照图2,依次添加“清华”与“大学”的声调识别码,按照分类与优先策略,多个声调识别码连接方式为在第一声调识别码后插入数字0,故声调识别码为g0a,对编码整体分析,各字韵母均非i或u,不涉及数字替代原则,此外,四字词不适用备韵替代原则,综合考虑,其最终编码为vqnhxdaxzg0a;输入时,v开头的编码以空格键上屏;当键入vqnhxd时,无相应的编码与当前编码相同,故可直接敲击空格键上屏,无需继续输入剩余编码。
方法实施例二
如词组“输入法”,用户可按单字输入,也可先输入二字词“输入”,然后输入单字“法”;
按单字输入时,“输”字的编码为ubz,其相码编码原理为:“输”为衍生字,偏旁分类码为z,使用频度高,优先编码,故不需增加笔画识别码;“输”字去掉偏旁后起笔为撇,按照主备韵原则,发音用备韵编码ub表示,综合考虑,其编码为ubz;输入时,不足4码,键入编码ubz后,用空格键上屏;“入”字的编码为rv,其相码编码原理为:“入”为特殊字中的次高频字,其编码为rv;输入时不足4码,键入rv后,敲空格键上屏;“法”字的编码为fav,其相码编码原理为:“法”为基本字中的声调字,“法”字起笔为点,无主韵与备韵的区分,其双拼编码为fa,读音为3声,故用fav表示,输入时不足4码,键入fav后,敲空格键上屏;
按二字词+单字方式输入时,二字词“输入”编码为u6r9,其相码编码原理为:“输入”为常用二字词,码长为4,按“输”、“入”二字各自的双拼编码依次排列,因“输”、“入”二字韵母均为u,声调分别为1声和4声,按照数字替代原则,当韵母为u时,用6表示1声,9表示4声,故编码为u6r9,在输入该词组时,考虑到其码长为4,编码中第二或第三码元不为0,第一码元不为v,故系统自动上屏;然后按单字方式输入“法”字。
方法实施例三
如单字“將”,“將”字的编码为j0q,其相码编码原理为:“將”为gb2312字库以外的汉字,且为简化字“将”的繁体字形式;按相码拼字法的单字扩展规则,在简化字“将”的相码编码jq的基础上,在第二码元位置插入数字0,其最终编码为j0q,输入该字时,因其编码第二码元为0,故在键入编码j0q后,用空格键上屏。
方法实施例四
如汉字“槶”,“槶”字的编码为“gz0m2”,其相码编码原理为:“槶”为gb2312字库以外的汉字,读音为gui,声调为4声,其双拼声母为g,双拼韵母为z,偏旁分类码为m,笔画识别码为2,按相码拼字法的单字扩展规则,因gzm、gzm2、gzm7的编码已表示其他汉字,且其韵母不为i或u,故在第三码元位置插入数字0,参照图3,在笔画识别码表中最上层选取笔画识别码2,得到最终编码为gz0m2,输入该字时,因其编码第三码元为0,故在键入编码gz0m2后,用空格键上屏。
方法实施例五
如汉字“璯”,“璯”字的编码为“hz0g9”,其相码编码原理为:“璯”为gb2312字库以外的汉字,读音为hui,声调为4声,其双拼声母为h,双拼韵母为z,其偏旁为“王”,偏旁分类码为g,笔画识别码为4,按相码拼字法的单字扩展规则,因hzg、hzg4、hzg9、hz0g4的编码已表示其他汉字,且其韵母不为i或u,故在第三码元位置插入数字0,参照图3,在笔画识别码表中第二层选取笔画识别码4的替补码元9,得到最终编码为hz0g9,输入该字时,因其编码第三码元为0,故在键入编码hz0g9后,用空格键上屏。
方法实施例六
如汉字“瓸”,“瓸”字的编码为“fi0bwwa”,其相码编码原理为:“瓸”为gb2312字库以外的汉字,读音为baiwa,属于特殊发音的字,故以fa0开头,然后添加其双拼编码bwwa,,得到最终编码为fi0bwwa,输入该字时,因其编码第三码元为0,故在键入编码fi0bwwa后,用空格键上屏。
方法实施例七
如汉字“韵”,可用相码标准编码和其相码简码编码两种方式输入;
相码标准编码输入方式下,“韵”字的相码编码为“yyw3”,其相码编码原理为:“韵”为gb2312字库中的汉字,为衍生字,偏旁分类码为w,因同一发音和同一偏旁分类码的衍生字中存在重码,其中“运”字使用频度高,优先编码,故编码yyw表示“运”字,“韵”字编码时需增加笔画识别码3;“韵”字去掉偏旁后起笔为撇,但“韵”字的发音不区分主备韵,其音节编码为yy,综合考虑,其最终编码为yyw3;输入时,4码直接上屏;
另一种简码输入方式下,“韵”字的简码编码为“yy9”,其相码简码编码原理为:“韵”为gb2312字库一级字库(3755常用字)中的汉字,为提高输入效率,在保留标准编码的同时,增加简码编码,采用“双拼声母+双拼韵母+汉字声调”的方式表示,因其不区分主备韵,故读音部分双拼编码为yy,汉字声调为4,但简码yy4已被用来表示“酝”字,所以声调部分使用4的替补编码9,最终得到编码为yy9;输入时,以空格键上屏。
方法实施例八
如汉字“毙”,可用相码标准编码和其相码简码编码两种方式输入;
相码标准编码输入方式下,“毙”字的相码编码为“biw3”,其相码编码原理为:“毙”为gb2312字库中的汉字,为衍生字,去掉偏旁后起笔为横,按照主备韵原则,发音用主韵编码bi表示,偏旁分类码为w,笔画识别码为3,因同一发音和同一偏旁分类码的衍生字中存在重码,其中“毕”字使用频度高,优先编码,故编码biw表示“毕”字,“毙”字编码时需增加笔画识别码3;综合考虑,其最终编码biw3;输入时,4码直接上屏;
另一种简码输入方式下,“毙”字的简码编码为“b4”,其相码简码编码原理为:“毙”为gb2312字库一级字库(3755常用字)中的汉字,为提高输入效率,在保留标准编码的同时,增加简码编码,采用“双拼声母+双拼韵母+汉字声调”的方式表示,其去掉偏旁后起笔为横,按主备韵原则,读音部分双拼编码为bi,汉字声调为4,按简码编码规则,依次选用简码bi4、bi9、b4i、b9i进行编码,但“bi4、bi9、b4i、b9i”均已被用来表示同一发音的其它汉字,然后考虑“毙”字韵母为i,所以可用“双拼声母+声调”的方式表示,最终得到编码为b4;输入时,以空格键上屏。
以上对本发明所提供利用音形特征描述汉字的相码拼字法及以其为基础的相码输入法,进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!