一种数据处理方法及设备与流程
本发明涉及大数据
技术领域:
,具体而言,涉及一种数据处理方法及设备。
背景技术:
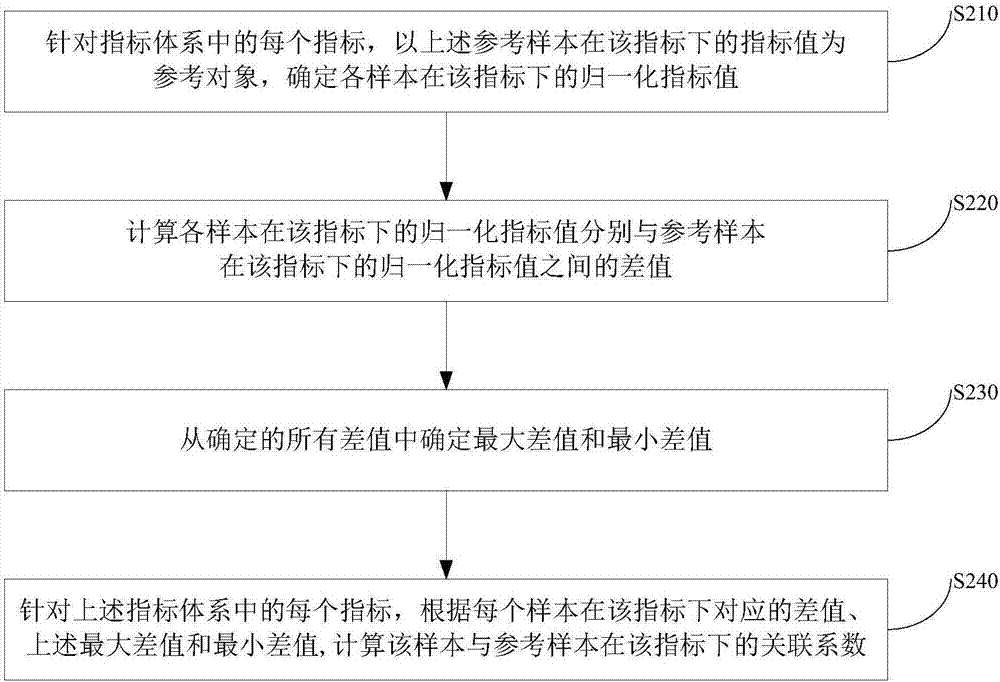
:人们在评价某些事物时,一般会制定一套用来评价该事物的指标体系,为了得到全面的指标体系,人们在制定指标体系时,往往需要考虑多方面的因素,因此,制定的指标体系中包括多个指标。在指标体系中的多个指标中,一般会存在至少一个关键指标,该关键指标能够反映指标体系的核心特征,对事物影响较大,因此,在根据指标体系评价事物时,需要找到该指标体系中的关键指标。现有技术中,一般都是根据人为经验通过人工的方式从指标体系中查找关键指标,但是,根据人为经验来查找关键指标,主观性较强,容易出现偏差,从而导致对事物的评价的准确性较低。技术实现要素:有鉴于此,本发明实施例的目的在于提供一种数据处理方法及设备,以解决现有技术中,根据人为经验查找关键指标,主观性较强,容易出现偏差,从而导致对事物的评价的准确性较低的问题。第一方面,本发明实施例提供了一种数据处理方法,其中,该方法包括:分别获取多个样本的指标数据,所述指标数据包括用于评价待评价内容的指标体系中各指标的指标值;针对所述指标体系中的每个指标,根据参考样本在该指标下的指标值与各样本在该指标下的指标值之间的数值关系,分别确定各样本与所述参考样本在该指标下的关联系数;以及根据各样本与所述参考样本在该指标下的关联系数,确定该指标与所述待评价内容之间的关联度;其中,所述参考样本为从所述多个样本中确定的一个样本;根据每个指标与所述待评价内容之间的关联度,确定所述指标体系中的关键指标。结合第一方面,本发明实施例提供了上述第一方面的第一种可能的实现方式,其中,所述针对所述指标体系中的每个指标,根据参考样本在该指标下的指标值与各样本在该指标下的指标值之间的数值关系,分别确定各样本与所述参考样本在该指标下的关联系数,包括:针对所述指标体系中的每个指标,以所述参考样本在该指标下的指标值为参考对象,确定各样本在该指标下的归一化指标值;以及计算各样本在该指标下的归一化指标值分别与所述参考样本在该指标下的归一化指标值之间的差值;从确定的所有差值中确定最大差值和最小差值;针对所述指标体系中的每个指标,根据每个样本在该指标下对应的差值、所述最大差值和所述最小差值,通过如下公式计算该样本与所述参考样本在该指标下的关联系数;其中,在上述公式中,γi(k)表示第k个样本与所述参考样本在第i个指标下的关联系数,m表示所述最小差值,m表示所述最大差值,ξ表示分辨系数,δi(k)表示的是第k个样本在第i个指标下对应的差值。结合第一方面的第一种可能的实现方式,本发明实施例提供了上述第一方面的第二种可能的实现方式,其中,所述针对所述指标体系中的每个指标,以所述参考样本在该指标下的指标值为参考对象,确定各样本在该指标下的归一化指标值,包括:针对所述指标体系中的每个指标,分别计算各样本在该指标下的指标值与所述参考样本在该指标下的指标值的比值,将所述比值确定为该样本在该指标下的归一化指标值。结合第一方面,本发明实施例提供了上述第一方面的第三种可能的实现方式,其中,所述根据各样本与所述参考样本在该指标下的关联系数,确定该指标与所述待评价内容之间的关联度,包括:针对所述指标体系中的每个指标,计算各样本在该指标下的关联系数的平均值;将每个指标对应的平均值确定为该指标与所述待评价内容之间的关联度。结合第一方面,本发明实施例提供了上述第一方面的第四种可能的实现方式,其中,所述根据每个指标与所述待评价内容之间的关联度,确定所述指标体系中的关键指标,包括:将每个指标对应的所述关联度与预设阈值进行比较;将对应关联度大于或等于所述预设阈值的指标确定为所述关键指标。结合第一方面,本发明实施例提供了上述第一方面的第五种可能的实现方式,其中,在获取多个样本的指标数据之前,还包括:根据计算需求采集原始数据;对所述原始数据进行清洗;获取多个样本的指标数据,具体包括:从清洗后的数据中获取多个样本的指标数据。第二方面,本发明实施例提供了一种数据处理设备,其中,所述设备包括:获取模块,用于获取多个样本的指标数据,所述指标数据包括用于评价待评价内容的指标体系中各指标的指标值;第一确定模块,用于针对所述指标体系中的每个指标,根据参考样本在该指标下的指标值与各样本在该指标下的指标值之间的数值关系,分别确定各样本与所述参考样本在该指标下的关联系数;第二确定模块,用于根据各样本与所述参考样本在该指标下的关联系数,确定该指标与所述待评价内容之间的关联度;其中,所述参考样本为从所述多个样本中确定的一个样本;第三确定模块,用于根据每个指标与所述待评价内容之间的关联度,确定所述指标体系中的关键指标。结合第二方面,本发明实施例提供了上述第二方面的第一种可能的实现方式,其中,所述第一确定模块包括:第一确定单元,用于针对所述指标体系中的每个指标,以所述参考样本在该指标下的指标值为参照对象,确定各样本在该指标下的归一化指标值;第一计算单元,用于计算各样本在该指标下的归一化指标值分别与所述参考样本在该指标下的归一化指标值之间的差值;第二确定单元,用于从确定的所有差值中确定最大差值和最小差值;第二计算单元,用于针对所述指标体系中的每个指标,根据每个样本在该指标下对应的差值、所述最大差值和所述最小差值,通过如下公式计算该样本与所述参考样本在该指标下的关联系数:其中,在上述公式中,γi(k)表示第k个样本与所述参考样本在第i个指标下的关联系数,m表示所述最小差值,m表示所述最大差值,ξ表示分辨系数,δi(k)表示的是第k个样本在第i个指标下对应的差值。第三方面,本发明实施例还提供了一种数据处理设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述第一方面至第一方面的第五种可能的实现方式中任一项所述的方法的步骤。第四方面,本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器运行时执行上述第一方面至第一方面的第五种可能的实现方式中任一项所述的方法的步骤。在本发明实施例提供的数据处理方法及设备中,根据多个样本在指标体系下每个指标对应的指标值,计算每个指标与待评价内容之间的关联度,以此来查找关键指标,根据客观数据进行关键指标的查找,避免受到人为主观判断的影响,与现有技术相比,提高了查找到的关键指标的准确性,从而提高了对事物的评价的准确性。为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。附图说明为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。图1示出了本发明一实施例所提供的数据处理方法的流程图;图2示出了本发明一实施例所提供的数据处理方法中,确定关联系数的流程图;图3示出了本发明又一实施例所提供的数据处理设备之一的结构示意图;图4示出了本发明另一实施例所提供的数据处理设备之二的结构示意图;图5示出了本发明再一实施例所提供的数据处理设备之三的结构示意图。具体实施方式为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明一实施例提供了一种数据处理方法,该方法用于在对样本的某些内容进行评价时,从用于评价该内容的指标体系中查找到对该样本影响较大的关键指标。参考图1所示,该方法包括步骤s110-s140,具体如下:s110,分别获取多个样本的指标数据,该指标数据包括用于评价待评价内容的指标体系中各指标的指标值。上述待评价内容指的是样本的某一方面的内容,比如说,当上述样本为葡萄酒时,上述待评价内容可以是葡萄酒的质量,还可以是葡萄酒的口感等内容;还比如说,当上述样本为汽车时,上述待评价内容可以是汽车的舒适感、汽车的制动性能或者是汽车的车身质量等内容。针对不同的待评价内容,制定的指标体系有所不同。具体的,若上述待评价内容为葡萄酒的质量,则用于评价葡萄酒的质量的一种可能的指标体系如下所示:香气浓度、香气质量、口感浓度和整体评价。进一步的,为了减少获取到的样本的指标数据中出现不完整的数据、错误的数据、重复的数据等数据,在获取多个样本的指标数据之前,本发明实施例提供的方法还包括:根据计算需求采集原始数据;对上述原始数据进行清洗。具体的,上述对原始数据进行清洗,指的是将采集的原始数据中不符合要求的数据过滤掉,不符合要求的数据包括不完整的数据、错误的数据及重复的数据等。在该种实施方式中,上述获取多个样本的指标数据,则具体包括:从清洗后的数据中获取多个样本的指标数据。s120,针对上述指标体系中的每个指标,根据参考样本在该指标下的指标值与各样本在该指标下的指标值之间的数值关系,分别确定各样本与参考样本在该指标下的关联系数。其中,上述参考样本为从上述多个样本中确定的一个样本,可以是多个样本中的任意一个样本。在本发明实施例中,参考图2所示,上述确定各样本与参考样本在某个指标下的关联系数,是通过步骤s210-s240实现的,具体包括:s210,针对上述指标体系中的每个指标,以上述参考样本在该指标下的指标值为参考对象,确定各样本在该指标下的归一化指标值;s220,计算各样本在该指标下的归一化指标值分别与参考样本在该指标下的归一化指标值之间的差值;s230,从确定的所有差值中确定最大差值和最小差值;s240,针对上述指标体系中的每个指标,根据每个样本在该指标下对应的差值、上述最大差值和最小差值,计算该样本与参考样本在该指标下的关联系数;具体的,通过如下公式计算关联系数:其中,在上述公式中,γi(k)表示第k个样本与参考样本在第i个指标下的关联系数,m表示上述最小差值,m表示上述最大差值,ξ表示分辨系数,δi(k)表示的是第k个样本在第i个指标下对应的差值。上述ξ的取值大于零且小于1,在一种具体实现方式中,可以取ξ等于0.5。上述步骤s210中,计算各个样本在某个指标下的归一化指标值,是为了消除不同指标之间的不同量纲对整个计算结果的影响,以增加不同指标之间的可比性。在一种具体实施方式中,上述步骤s210,计算各个样本在某个指标下的归一化指标值,具体可以通过如下方式实现:针对上述指标体系中的每个指标,分别计算各样本在该指标下的指标值与参考样本在该指标下的指标值的比值,将上述比值确定为该样本下该指标下的归一化指标值。进一步的,可以通过如下公式计算上述归一化指标值:其中,在上述公式中,x′i(k)表示的是第k个样本的第i个指标的归一化指标值,xi(k)表示的是第k个样品的第i个指标在归一化之前的指标值,xi(s)指的是参考样本的指标值,将第s个样本确定为参考样本。s130,根据各样本与参考样本在该指标下的关联系数,确定该指标与上述待评价内容之间的关联度。在本发明实施例中,确定指标与待评价内容之间的关联度,是通过如下步骤实现的:针对指标体系中的每个指标,计算各样本在该指标下的关联系数的平均值;将每个指标对应的平均值确定为该指标与待评价内容之间的关联度。具体的,可以通过如下公式计算各个样本在某个指标下的关联系数的平均值:其中,在上述公式中,γi表示的是各个样本在第i个指标下的关联系数的平均值,n表示的是样本的个数,γi(k)表示的是第k个样本与参考样本在第i个指标下的关联系数。s140,根据每个指标与待评价内容之间的关联度,确定上述指标体系中的关键指标。将每个指标对应的关联度与预设阈值进行比较;将对应关联度大于或等于预设阈值的指标确定为关键指标。其中,上述预设阈值可以根据实际应用场景进行设置,本发明实施例并不对上述预设阈值的具体取值进行限定。在另外一种具体实施方式中,可以将计算出来的各个指标对应的关联度按照从大到小的顺序进行排序,根据实际需要从排序后的关联度后,截取排在前面的预设数量个关联度,将该预设数量个关联度分别对应的指标确定为关键指标。表1香气浓度香气质量口感浓度整体评价样酒15.510.84.511.8样酒26.512616.6样酒36.213.26.116.3样酒46.112.25.315.1样酒55.411.45.615.7样酒6611.25.214.2样酒75.211.25.414.5样酒86.410.45.813.9样酒97.314.46.416样酒106.211.85.714.2为了详细介绍上述数据处理方法,下面将以评价葡萄酒的质量为例进行说明。在对葡萄酒的质量进行评价时,为了确定葡萄酒的质量,通过聘请一些有资质经验的评酒员进行品评,评酒员可以从香气浓度、香气质量、口感浓度和整体评价四个指标对品评的各个样酒进行打分,每个指标的打分则为该指标的指标值,各个指标对应的打分如表1所示。将上述样酒1确定为参考样酒,为了消除不同指标之间的量纲影响,对上述各个样酒的指标对应的指标值进行归一化处理,计算各个指标的归一化指标值。具体过程包括:分别计算各个样酒在某个指标下的指标值与参考样酒在该指标下的指标值的比值,在本发明实施例中,以样酒1作为参考样酒,则需要计算各个样酒在各个指标下的指标值与样酒1在该指标下的指标值的比值。即每个样酒的香气浓度的指标值均需要除以样酒1的香气浓度的指标值,每个样酒的香气质量的指标值均需要除以样酒1的香气质量的指标值,每个样酒的口感浓度的指标值均需要除以样酒1的口感浓度的指标值,每个样酒的整体评价的指标值均需要除以样酒1的整体评价的指标值。归一化后的各个样酒的指标对应的归一化指标值,如表2所示。当确定出各个样酒的指标对应的归一化指标值后,则需要通过如下公式计算各个样酒的各个指标对应的归一化值分别与样酒1在该指标下的归一化指标值之间的差值:δi(k)=|xi′(k)-xi′(1)|其中,在上述公式中,δi(k)表示的是样酒k的第i个指标的归一化指标值与样酒1的第i个指标的归一化指标值的差值的绝对值,xi′(k)表示的是样酒k的第i个指标的归一化指标值,xi′(1)表示的是样酒1的第i个指标的归一化指标值。计算出的各个样酒的各个指标的归一化指标值与样酒1的该指标的归一化指标值之间的差值如表3所示。表2香气浓度香气质量口感质量整体评价样酒11111样酒21.1821.1111.1531.407样酒31.1271.2221.1731.381样酒41.1091.1291.0961.279样酒50.9821.0561.1731.33样酒61.0911.0371.1531.203样酒70.9451.0371.0961.229样酒81.1630.96231.1151.177样酒91.3271.3331.1541.356样酒101.1271.0921.0961.203找出表3中的所有差值中的最大差值m和最小差值m,可以确定出:m=0m=0.407之后,根据确定出的最大差值m、最小差值m、表3中各个样酒在每个指标下的差值及分辨系数,通过如下公式计算各个样酒与样酒1在各个指标下的关联系数:其中,ξ取值为0.5。计算出的各个样酒的各个指标与样酒1的该指标的关联系数如表4所示。表3香气浓度香气质量口感质量整体评价样酒10000样酒20.1820.1110.1530.407样酒30.1270.2220.1730.318样酒40.1090.1290.0960.279样酒50.0180.0560.1730.33样酒60.0910.0370.1530.203样酒70.0550.0370.0960.229样酒80.1630.0380.1150.177样酒90.3270.3330.1540.356样酒100.1270.0920.0960.203由于计算出的各个样酒的指标与样酒1的该指标之间的关联系数为多个,过于分散不便于进行整体性的比较,因此,需要将上述多个关联系数集中为一个值,具体的,可以计算每个指标对应的关联系数的平均值,即该指标与葡萄酒质量的关联度。计算出的香气浓度与葡萄酒质量的关联度为0.674,香气质量与葡萄酒质量的关联度为0.715,口感质量与葡萄酒质量的关联度为0.647,整体评价与葡萄酒质量的关联度为0.49。表4香气浓度香气质量口感质量整体评价样酒11111样酒20.5270.6470.5710.333样酒30.6150.4780.5410.390样酒40.6510.6120.6790.422样酒50.9180.7840.5410.381样酒60.6910.8460.5710.501样酒70.7870.8460.6790.471样酒80.5550.8430.6390.535样酒90.3840.3790.5690.364样酒100.6160.6890.6790.501一般,上述关联度的取值越大,则说明该指标与葡萄酒质量的关联度也越大,所述将上述各个关联度与预设阈值进行比较,将对应关联度大于或等于预设阈值的指标确定为葡萄酒质量的关键指标。本发明实施例提供的数据处理方法,根据多个样本在指标体系下每个指标对应的指标值,计算每个指标与待评价内容之间的关联度,以此来查找关键指标,根据客观数据进行关键指标的查找,避免受到人为主观判断的影响,与现有技术相比,提高了查找到的关键指标的准确性,从而提高了对事物的评价的准确性。基于与上述数据处理方法相同的原理,本发明又一实施例还提供了一种数据处理设备之一,参考图3所示,该设备包括获取模块310、第一确定模块320、第二确定模块330和第三确定模块340,其中,上述获取模块310,用于获取多个样本的指标数据,该指标数据包括用于评价待评价内容的指标体系中各指标的指标值;上述第一确定模块320,用于针对上述指标体系中的每个指标,根据参考样本在该指标下的指标值与各样本在该指标下的指标值之间的数值关系,分别确定各样本与参考样本在该指标下的关联系数;上述第二确定模块330,用于根据各样本与上述参考样本在该指标下的关联系数,确定该指标与待评价内容之间的关联度;其中,参考样本为从上述多个样本中确定的一个样本;上述第三确定模块340,用于根据每个指标与待评价内容之间的关联度,确定上述指标体系中的关键指标。具体的,上述第一确定模块320,确定各样本与参考样本在各个指标下的关联系数,是通过第一确定单元、第一计算单元、第二确定单元和第二计算单元实现的,具体包括:上述第一确定单元,用于针对上述指标体系中的每个指标,以上述参考样本在该指标下的指标值为参考对象,确定各样本在该指标下的归一化指标值;上述第一计算单元,用于计算各样本在该指标下的归一化指标值分别与上述参考样本在该指标下的归一化指标值之间的差值;上述第二确定单元,用于从确定的所有差值中确定最大差值和最小差值;上述第二计算单元,用于针对上述指标体系中的每个指标,根据每个样本在该指标下对应的差值、上述最大差值和上述最小差值,通过如下公式计算该样本与参考样本在该指标下的关联系数:其中,在上述公式中,γi(k)表示第k个样本与所述参考样本在第i个指标下的关联系数,m表示所述最小差值,m表示所述最大差值,ξ表示分辨系数,δi(k)表示的是第k个样本在第i个指标下对应的差值。上述第一确定单元具体用于,针对上述指标体系中的每个指标,分别计算各样本在该指标下的指标值与参考样本在该指标下的指标值的比值,将上述比值确定为该样本在该指标下的归一化指标值。进一步的,上述第二确定模块330,确定各指标与待评价内容之间的关联度,是通过第三计算单元和第四计算单元实现的,具体包括:上述第三计算单元,用于针对指标体系中的每个指标,计算各样本在该指标下的关联系数的平均值;上述第四计算单元,用于将每个指标对应的平均值确定为该指标与待评价内容之间的关联度。进一步的,上述第三确定模块340,根据每个指标与待评价内容之间的关联度,确定上述指标体系中的关键指标,是通过比较单元和第三确定单元实现的,具体包括:上述比较单元,用于将每个指标对应的关联度与预设阈值进行比较;上述第三确定单元,用于将对应关联度大于或等于预设阈值的指标确定为关键指标。本发明另一实施例还提供了一种数据处理设备之二,如图4所述,该设备包括采集模块350和清洗模块360,具体的,上述采集模块350,用于根据计算需求采集原始数据;上述清洗模块360,用于对上述原始数据进行清洗。在该种实施例中,上述获取模块310则从经过清洗模块清洗后的数据中获取多个样本的指标数据。本发明实施例提供的数据处理设备,根据多个样本在指标体系下每个指标对应的指标值,计算每个指标与待评价内容之间的关联度,以此来查找关键指标,根据客观数据进行关键指标的查找,避免受到人为主观判断的影响,与现有技术相比,提高了查找到的关键指标的准确性,从而提高了对事物的评价的准确性。上述各单元的功能可对应于图1至图2所示流程中的相应处理步骤,在此不再赘述。对应于图1中的数据处理方法,本发明再一实施例还提供了一种数据处理设备之三,如图5所示,该设备包括存储器1000、处理器2000及存储在该存储器1000上并可在该处理器2000上运行的计算机程序,其中,上述处理器2000执行上述计算机程序时实现上述数据处理方法的步骤。具体地,上述存储器1000和处理器2000能够为通用的存储器和处理器,这里不做具体限定,当处理器2000运行存储器1000存储的计算机程序时,能够执行上述数据处理方法,从而解决传统的数据处理方法对大数据的处理能力不足,无法确保数据的安全性和可靠性的问题,进而实现对敏感数据进行精准定位和保护,从而保证数据的安全性和可靠性。对应于图1中的数据处理方法,本发明实施例还提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行上述数据处理方法的步骤。具体地,该存储介质能够为通用的存储介质,如移动磁盘、硬盘等,该存储介质上的计算机程序被运行时,能够执行上述数据处理方法,从而解决传统的数据处理方法对大数据的处理能力不足,无法确保数据的安全性和可靠性的问题,进而实现对敏感数据进行精准定位和保护,从而保证数据的安全性和可靠性。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1