基于分布式消息队列中间件的处理方法和处理系统与流程
本发明涉及消息处理技术领域,尤其涉及一种基于分布式消息队列中间件的处理方法和处理系统。
背景技术:
分布式消息队列中间件是一种广泛运用在分布式系统中的用于节点间通信的软件,是分布式系统中的一个重要组件,主要用来解决发布消息,应用耦合,流量削峰等问题。kafka,是由linkedin公司开发并开源的分布式消息队列中间件,作为一个分布式流媒体平台,是分布式消息队列的一个主流开源系统,非常适合于大数据系统的各个组件之间实时或者准实时通讯。
kafka消息队列中间件包括生产者、管理者以及消费者;当产生一个新的产品业务时,需要首先制定一个消息模式,而生产者会按照这个消息模式进行编码然后再通过kafka传输数据流。在kafka另一端的服务需要消费这个数据流的时候,也需要拿到这个消息模式才能知道怎么解码还原数据流。
目前,生产者将消息模式上传并注册到消息模式服务管理者,并将结果线下告诉消息消费者。消费者再将这些信息提供给消息模式管理者,并下载消息模式,完成线上和线下相结合的“握手”过程。在实际运用中,随着业务的不断推进,消息模式经常升级变化,而所有的这些变动都需要双方再次“握手”才能正确处理传输的数据流。当生产者由于需求或者其他原因导致信息模式需要变更,如果没有通知到消费者时,会导致消费者出现异常,即使生产者生成的消息变更线下通知到了,消费者还需要将这些信息提供给消息模式管理者,并下载消息模式。这不仅给产品的日常维护和运营带来非常大的负担,而且造成资源的浪费。
技术实现要素:
本发明的目的是提供一种基于分布式消息队列中间件的处理方法和处理系统,避免了线下“握手”过程,当生产者由于需求或者其他原因导致信息模式需要变更时,不需要线下通知消费者,便可以自动完成消息模式的升级,减轻日常维护和运营成本。
本发明提供了一种基于分布式消息队列中间件的处理方法,包括以下步骤:
获取外部消息流中的上传消息,根据上传消息建立消息信息;所述消息信息包括消息模式;
对所述消息模式进行处理,得到查询信息;
根据所述查询信息进行查询,根据查询结果提取第一高速缓存器中的所述消息模式,再根据所述消息模式对所述消息信息进行编码,得到编码信息,并将所述编码信息发送至分布式消息队列集群储存;
根据所述查询信息进行查询,根据查询结果提取第二高速缓存器中的所述消息模式,再根据所述消息模式从所述分布式消息队列集群中得到对应的所述编码信息进行解码,并根据解码结果进行消费。
作为一种可实施方式,所述根据所述查询信息进行查询,根据查询结果提取第一高速缓存器中的所述消息模式,包括以下步骤:
根据所述查询信息进行查询,判断当前的消息模式是否存储于第一高速缓存器中;
若当前的消息模式已经存储于第一高速缓存器中,则提取第一高速缓存器中的所述消息模式;
若当前的消息模式没有存储于第一高速缓存器中,则根据所述消息信息中的注册信息将所述消息模式进行上传,并将所述消息模式储存于模式数据库中;同时,将所述消息模式存储于第一高速缓存器中。
作为一种可实施方式,所述根据所述查询信息,提取第二高速缓存器中的所述消息模式,包括以下步骤:
根据所述查询信息进行查询,判断当前的消息模式是否存储于所述第二高速缓存器中;
若当前的消息模式已经存储于第二高速缓存器中,则提取第二高速缓存器中的所述消息模式;
若当前的消息模式没有存储于第二高速缓存器中,则根据所述查询信息与所述模式数据库对比,根据结果得到对应的所述消息模式,同时,将所述存储于第二高速缓存器中。
作为一种可实施方式,所述对所述消息模式进行处理,得到查询信息,包括以下步骤:
对所述消息模式进行散列算法,得到哈希值;
对所述消息模式进行分类处理,得到分类数据;
将所述哈希值和所述分类数据合并得到所述查询信息。
作为一种可实施方式,本发明提供的基于分布式消息队列中间件的处理方法,还包括以下步骤:
在根据所述查询信息进行查询之前,将版本信息和时间戳封装到所述消息数据中。
相应的,本发明还提供一种基于分布式消息队列中间件的处理系统,包括获取模块、操作模块、提取编码模块以及提取解码模块;
所述获取模块,用于获取外部消息流中的上传消息,根据上传消息建立消息信息;所述消息信息包括消息模式;
所述操作模块,用于对所述消息模式进行处理,得到查询信息;
所述提取编码模块,用于根据所述查询信息进行查询,根据查询结果提取第一高速缓存器中的所述消息模式,再根据所述消息模式对所述消息信息进行编码,得到编码信息,并将所述编码信息发送至分布式消息队列集群储存;
所述提取解码模块,用于根据所述查询信息进行查询,根据查询结果提取第二高速缓存器中的所述消息模式,再根据所述消息模式从所述分布式消息队列集群中得到对应的所述编码信息进行解码,并根据解码结果进行消费。
作为一种可实施方式,所述提取编码模块,包括第一判断单元、第一提取单元以及注册存储单元;
所述第一判断单元,用于根据所述查询信息进行查询,判断当前的消息模式是否存储于第一高速缓存器中;
所述第一提取单元,用于若当前的消息模式已经存储于第一高速缓存器中,则提取第一高速缓存器中的所述消息模式;
所述注册存储单元,用于若当前的消息模式没有存储于第一高速缓存器中,则根据所述消息信息中的注册信息将所述消息模式进行上传,并将所述消息模式储存于模式数据库中;同时,将所述消息模式存储于第一高速缓存器中。
作为一种可实施方式,所述提取解码模块,包括第二判断单元、第二提取单元以及对比存储单元;
所述第二判断单元,用于根据所述查询信息进行查询,判断当前的消息模式是否存储于所述第二高速缓存器中;
所述第二提取单元,用于若当前的消息模式已经存储于第二高速缓存器中,则提取第二高速缓存器中的所述消息模式;
所述对比存储单元,用于若当前的消息模式没有存储于第二高速缓存器中,则根据所述查询信息与所述模式数据库对比,根据结果得到对应的所述消息模式,同时,将所述存储于第二高速缓存器中。
作为一种可实施方式,所述操作模块,包括散列算法单元、分类处理单元以及合并单元;
所述散列算法单元,用于对所述消息模式进行散列算法,得到哈希值;
所述分类处理单元,用于对所述消息模式进行分类处理,得到分类数据;
所述合并单元,用于将所述哈希值和所述分类数据合并得到所述查询信息。
作为一种可实施方式,本发明提供的基于分布式消息队列中间件的处理系统,还包括封装模块;
所述封装模块,用于在根据所述查询信息进行查询之前,将版本信息和时间戳封装到所述消息数据中。
与现有技术相比,本技术方案具有以下优点:
本发明提供的基于分布式消息队列中间件的处理方法和处理系统,通过根据查询信息提取第一高速缓存器和第二高速缓冲器中存储的消息模式,而根据第一高速缓存器中的消息模式对消息信息进行编码,将得到的编码信息发送至分布式消息队列集群储存;根据第二高速缓存器中的消息模式从分布式消息队列集群中得到对应的编码信息进行解码,并根据解码结果进行消费。本发明避免了线下“握手”过程,当生产者由于需求或者其他原因导致信息模式需要变更时,不需要线下通知消费者,便可以自动完成消息模式的升级,减轻日常维护和运营成本。
附图说明
图1为本发明实施例一提供的基于分布式消息队列中间件的处理方法的流程示意图;
图2为本发明实施例二提供的基于分布式消息队列中间件的处理系统的结构示意图;
图3为图2中操作模块的结构示意图;
图4为图2中提取编码模块的结构示意图;
图5为图2中提取解码模块的结构示意图。
图中:100、获取模块;200、操作模块;210、散列算法单元;220、分类处理单元;230、合并单元;300、提取编码模块;310、第一判断单元;320、第一提取单元;330、注册存储单元;400、提取解码模块;410、第二判断单元;420、第二提取单元;430、对比存储单元;500、封装模块。
具体实施方式
以下结合附图,对本发明上述的和另外的技术特征和优点进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的部分实施例,而不是全部实施例。
请参阅图1,本发明实施例一提供的基于分布式消息队列中间件的处理方法,包括以下步骤:
s100、获取外部消息流中的上传消息,根据上传消息建立消息信息;消息信息包括消息模式;
s200、对消息模式进行处理,得到查询信息;
s300、根据查询信息进行查询,根据查询结果提取第一高速缓存器中的消息模式,再根据消息模式对消息信息进行编码,得到编码信息,并将编码信息发送至分布式消息队列集群储存;
s400、根据查询信息进行查询,根据查询结果提取第二高速缓存器中的消息模式,再根据消息模式从分布式消息队列集群中得到对应的编码信息进行解码,并根据解码结果进行消费。
需要说明的是,上传消息是外部消息流中需要进行变更或者新产生的一个产品业务包含的信息流;而外部消息流中存在无数个这样的上传消息,上传消息是根据实际需求产生的,所以于本实施例中,是实时获取外部消息流中的上传消息。于其他实施例中,也可以是根据其他方式判断再获取上传消息。
查询信息是用来查询消息模式的,会对每个消息模式进行分类,再将每个消息模式在存储的时候将其相应的查询信息、元数据信息都会存储在一个消息模式中,也就是说一类的第一高速缓存器和第二高速缓存器中存储着各种不同的消息模式,在用到与当前相应的消息模式时,会被提取出来使用。
本发明提供的基于分布式消息队列中间件的处理方法,通过根据查询信息提取第一高速缓存器和第二高速缓冲器中存储的消息模式,而根据第一高速缓存器中的消息模式对消息信息进行编码,将得到的编码信息发送至分布式消息队列集群储存;根据第二高速缓存器中的消息模式从分布式消息队列集群中得到对应的编码信息进行解码,并根据解码结果进行消费。本发明避免了线下“握手”过程,当生产者由于需求或者其他原因导致信息模式需要变更时,不需要线下通知消费者,便可以自动完成消息模式的升级,减轻日常维护和运营成本。
进一步的,根据查询信息进行查询,根据查询结果提取第一高速缓存器中的消息模式,包括以下步骤:
s310、根据查询信息进行查询,判断当前的消息模式是否存储于第一高速缓存器中;
s320、若当前的消息模式已经存储于第一高速缓存器中,则提取第一高速缓存器中的消息模式;
s330、若当前的消息模式没有存储于第一高速缓存器中,则根据消息信息中的注册信息将消息模式进行上传,并将消息模式储存于模式数据库中;同时,将消息模式存储于第一高速缓存器中。
于本实施例中,在步骤s330之中同时,将消息模式存储于第一高速缓存器中。也是将存储于第一高速缓存器中的消息模式提前出来;而每进行一次查询,不管当前第一高速缓存器是否存在与查询信息对应消息模式,最终都会将与查询信息对应消息模式生产再存储于第一高速缓存器中,而该消息模式也会存储于模式数据库中,一般来说模式数据库中的消息模式最终都会存储于第一高速缓存器中,每一次查询也是对当前消息模式的一个过滤的过程,避免了在第一高速缓存器中重复储存一样的消息模式;这样可以减少网络访问次数,减轻系统运行负担,提高运行效率。直接根据注册信息将消息模式进行上传实现消息模式的自动注册,无需额外程序支持。这里需要说明的是一个消息模式中也可能嵌套还可以有别的消息模式。
进一步的,根据查询信息,提取第二高速缓存器中的消息模式,包括以下步骤:
s410、根据查询信息进行查询,判断当前的消息模式是否存储于第二高速缓存器中;
s420、若当前的消息模式已经存储于第二高速缓存器中,则提取第二高速缓存器中的消息模式;
s430、若当前的消息模式没有存储于第二高速缓存器中,则根据查询信息与模式数据库对比,根据结果得到对应的消息模式,同时,将存储于第二高速缓存器中。
于本实施例中,在步骤s430之中同时,将消息模式存储于第一高速缓存器中。也是将存储于第一高速缓存器中的消息模式提前出来;第二高速缓存器和第一高速缓存器一样,本身存储有各类消息模式,在进行查询时,如果当前第二高速缓存器中不存在对应的消息模式,则根据查询信息与模式数据库对比,根据结果得到对应的消息模式,同时,将存储于第二高速缓存器中,也就是说模式数据库中的消息模式最终都会存储于第一高速缓存器中,每一次查询也是对当前消息模式的一个过滤的过程,避免了在第一高速缓存器中重复储存一样的消息模式;这样可以减少网络访问次数,减轻系统运行负担,消息处理能力上升,系统稳定性及服务有效性提高。
进一步的,步骤s200包括以下步骤:
s210、对消息模式进行散列算法,得到哈希值;
s220、对消息模式进行分类处理,得到分类数据;
s230、将哈希值和分类数据合并得到查询信息。
这里的散列算法可以是通过md5进行,得到一个128位的哈希值,而分类数据是对消息模式进行分类处理得到的。于本实施例中,并不对哈希值和分类数据的算法过程进行限定。
进一步的,本发明实施例一提供的基于分布式消息队列中间件的处理方法还包括以下步骤:
在根据查询信息进行查询之前,将版本信息和时间戳封装到消息数据中。
版本信息和时间戳对消息模式存储于第一高速缓存器和第二高速缓存器的时候起到辅助作用。
下面以avro和kafka为例对本发明的具体原理进行详细说明:
kafka消息队列中间件包括生产者、管理者以及消费者;
产生者发送带消息模式的消息信息给avro编码器;
编码器主要负责对消息信息通过avro进行编码,avro编码器内嵌一个消息模式的高速缓存器。高速缓存器保存所有已经使用过的avro消息模式;在编码之前,它会将当前消息信息所用的消息模式进行md5(散列)操作,拿到一个128位的哈希值。然后,编码器会拿kafkatopic(分类数据)和哈希值联合查询本地高速缓存器,看消息模式是否已经在本地高速缓存器里面存在。如果已经存在,编码器会使用拿到的消息模式对消息信息进行编码,并将得到的解码信息发送到kafka集群。如果不存在,它会通过httppost自动调用消息模式注册服务器,上传该消息模式。消息模式注册服务器收到注册信息之后,会将这一消息模式及其相关元数据信息写入消息模式数据库。与此同时,这个新的消息模式被载入编码器的高速缓存器,使得编码器会使用拿到的消息模式对消息信息进行编码。
消费者接收到该消息信息之后,会通过解码器通过avro进行解码。avro解码器里面内嵌一个高速缓存器,保存所有解码器已经使用过的消息模式。解码时,解码器会得到消息模式的哈希值,然后通过kafkatopic和哈希值查询本地高速缓存器中的消息模式,检查当前消息模式是否已经存在解码器的高速缓存器里。如果存在,编码器会使用拿到的该消息模式对消息信息进行解码,消费当前的消息信息。如果不存在,编码器会自动用该kafkatopic和哈希值并通过httpget去消息模式注册服务器上取得这个新的消息信息。消息模式注册服务器负责将对应的消息模式从消息模式数据库里面取出并返回给编码器。与此同时,解码器会将此消息模式装入本地高速缓存器中,供消费同样消息模式的消息信息使用。
需要知道的是,消息信息在经过消息模式进行编码后,在消费这个消息信息时,也必须要通过这个消息模式进行解码。而在解码的过程中,使用以下算法解码:
其中,getschemabytopicandschema(topica,md5)的实现如下:
需要指出的是,这里的list所对应的每一个元素都可能是一个不同类型的子信息,具有不同的子消息模式。虽然这个方案是基于avro和kafka来阐述,使用别的消息队列和别的消息模式方式,本发明也同样适用。
基于同一发明构思,本发明实施例还提供一种基于分布式消息队列中间件的处理系统,该系统的实施可参照上述方法的过程实现,重复之处不再冗述。
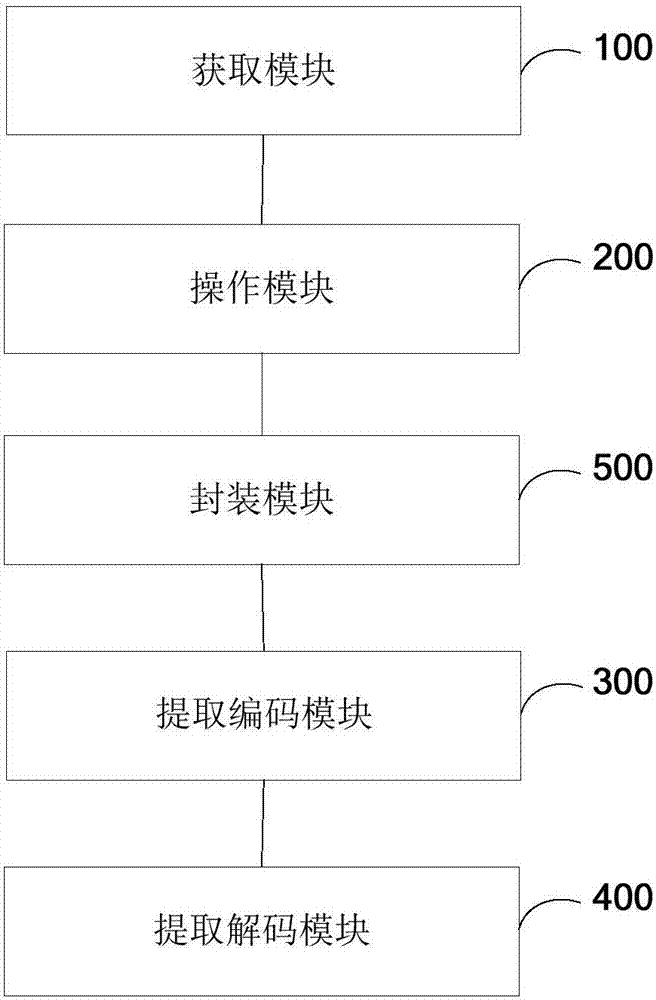
如图2所示,是本发明实施例二提供的基于分布式消息队列中间件的处理系统的结构示意图,包括获取模块100、操作模块200、提取编码模块300以及提取解码模块400;
获取模块100用于获取外部消息流中的上传消息,根据上传消息建立消息信息;消息信息包括消息模式;
操作模块200用于对消息模式进行处理,得到查询信息;
提取编码模块300用于根据查询信息进行查询,根据查询结果提取第一高速缓存器中的消息模式,再根据消息模式对消息信息进行编码,得到编码信息,并将编码信息发送至分布式消息队列集群储存;
提取解码模块400用于根据查询信息进行查询,根据查询结果提取第二高速缓存器中的消息模式,再根据消息模式从分布式消息队列集群中得到对应的编码信息进行解码,并根据解码结果进行消费。
如图4所示,是提取编码模块的结构示意图,包括第一判断单元310、第一提取单元320以及注册存储单元330;
第一判断单元310用于根据查询信息进行查询,判断当前的消息模式是否存储于第一高速缓存器中;
第一提取单元320用于若当前的消息模式已经存储于第一高速缓存器中,则提取第一高速缓存器中的消息模式;
注册存储单元330用于若当前的消息模式没有存储于第一高速缓存器中,则根据消息信息中的注册信息将消息模式进行上传,并将消息模式储存于模式数据库中;同时,将消息模式存储于第一高速缓存器中。
如图5所示,是提取解码模块的结构示意图,包括第二判断单元410、第二提取单元420以及对比存储单元430;
第二判断单元410用于根据查询信息进行查询,判断当前的消息模式是否存储于第二高速缓存器中;
第二提取单元420用于若当前的消息模式已经存储于第二高速缓存器中,则提取第二高速缓存器中的消息模式;
对比存储单元430用于若当前的消息模式没有存储于第二高速缓存器中,则根据查询信息与模式数据库对比,根据结果得到对应的消息模式,同时,将存储于第二高速缓存器中。
如图3所示,是操作模块的结构示意图,包括散列算法单元210、分类处理单元220以及合并单元230;
散列算法单元210用于对消息模式进行散列算法,得到哈希值;
分类处理单元220用于对消息模式进行分类处理,得到分类数据;
合并单元230用于将哈希值和分类数据合并得到查询信息。
进一步的,如图1所示,本发明实施例一提供的基于分布式消息队列中间件的处理系统还包括封装模块500;
封装模块500用于在根据查询信息进行查询之前,将版本信息和时间戳封装到消息数据中。
本发明提供的基于分布式消息队列中间件的处理系统,通过根据查询信息提取第一高速缓存器和第二高速缓冲器中存储的消息模式,而根据第一高速缓存器中的消息模式对消息信息进行编码,将得到的编码信息发送至分布式消息队列集群储存;根据第二高速缓存器中的消息模式从分布式消息队列集群中得到对应的编码信息进行解码,并根据解码结果进行消费。本发明避免了线下“握手”过程,当生产者由于需求或者其他原因导致信息模式需要变更时,不需要线下通知消费者,便可以自动完成消息模式的升级,减轻日常维护和运营成本。
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明,任何本领域技术人员在不脱离本发明的精神和范围内,都可以利用上述揭示的方法和技术内容对本发明技术方案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!