一种基于语义推理和时空记忆更新的车辆检测方法与流程
本发明属于计算机视觉领域,具体涉及一种基于语义推理和时空记忆更新的车辆检测方法。
背景技术:
车辆检测是完成车辆无人驾驶及辅助驾驶的关键技术。相机、激光雷达、毫米波雷达等是常见的车辆检测传感器。相比而言,相机成本低、图像信息丰富、深度学习等图像处理技术日益成熟,基于视觉技术的车辆检测成为当前研究及开发热点。
纵观车辆检测方法的研究历程,传统模式“训练+分类”如hog+svm、haar-like+adaboost,dpm+lsvm等在一定程度上达到了良好的检测率。但是,n.dalal2005提出的hog+svm方法通常会产生大量的误检;j.m.park2010提出的haar-like+adaboost方法用15个haar-like特征训练了一个adaboost分类器,该方法对动态变化的场景及光照变化适应性差;p.f.felzenszwalb2010提出的dpm+lsvm方法把一个物体建模为几个相互关联的子模块,该检测方法虽效果很好,但耗时较大,难以做到实时检测;并且,由于图像中远处的车辆所占据的像素较少,模块化结构不明显,dpm+lsvm方法对远处车辆的检测效果不佳。
传统的“训练+分类”方法仅利用了2d图像平面信息,没有将丰富的3d交通场景信息应用到车辆检测中;另外,基于滑动窗搜索的策略将候选车辆看作孤立的像素块,缺乏语义推理。因此,充分利用3d交通场景信息进行车辆检测的方法不断涌现。d.hoiem2008提出建立一个3d交通场景模型,充分利用相机视角、车辆、路面之间的依赖关系,提高车辆检测的精度。c.wojek2013把车辆检测与3d几何推理结合起来,极大提高了检测效果。j.pan2013生成并估计了一个最佳3d场景模型,并利用该模型提高车辆检测精度。然而,以上方法对3d交通场景的描述要么过于简单,要么对模型的推理过程过于复杂。
技术实现要素:
本发明的目的在于克服上述不足,提供一种基于语义推理和时空记忆更新的车辆检测方法,能够适应复杂且动态变化的交通场景,对图像中不同类型、不同尺寸的车辆均可进行实时在线检测。
为了达到上述目的,本发明包括以下步骤:
步骤一,根据路面模型r、车辆模型v和相机模型c,建立3d交通场景模型;
步骤二,根据路面模型r并结合相机模型c,在3d空间中确定候选车辆搜索区域;
步骤三,根据自适应多阈值二值化方法,确定二值化候选车辆搜索区域;
步骤四,利用快速扫描线的方法在二值化候选车辆搜索区域上搜索并生成候选车辆;
步骤五,分析车辆之间的语义关系确认候选车辆,将候选车辆投影到2d图像上,利用候选车辆的外观特征对候选车辆进行进一步滤波处理;
步骤六,根据视频中检测框连续稳定出现的帧数确定车辆的置信度,并依据车辆的高置信度及时空记忆法降低车辆检测的漏检率;
步骤七,输出结果。
所述步骤一中,3d交通场景模型定义为:
m={r,v,c}
所有参数定义在自车坐标系vc={ov,xv,yv,zv}下,该模型由三个子模型组成:
r={rl,rr,rh}
v={dx,dy,ux,uy,ax,ay,β,pl}
其中,路面模型r={rl,rr,rh}是一个长方形区域,rl是区域左边界,rr是区域右边界,rr是xv方向的范围,车辆模v={dx,dy,ux,uy,ax,ay,β,pl}中,dx、ux、ax分别表示前方车辆相对于自车在xv方向的距离、速度、加速度,dy、uy、ay分别表示前方车辆相对于自车在yv方向的距离、速度、加速度,β表示前方车辆车身相对于xv方向的角度,pl={l_lane、c_lane、r_lane}代表前方车辆的车道信息,相机模型
所述步骤二中,定义路面模型r={rl,rr,rh}为候选车辆搜索区域,然后将图像投影到该区域,假设车辆坐标系下一个点pv=(xv,yv,zv)和相机坐标系下一个点pc=(xc,yc,zc),pv和pc通过以下公式建立关联:
pv=rpc+t
其中,r和t由相机模型c确定;
假设图像坐标系下一个点pi=(u,v),pi和pc可通过以下公式建立关联:
其中,α、β、u0、v0通过相机内参标定方法而获得,根据以上公式推导,能够获得pv和pi的关联关系,进而将图像信息投影到3d空间下的,最终获得候选车辆搜索区域。
所述步骤三中,候选车辆搜索区域用一张灰度图像表示,首先将该灰度图像二值化,将灰度图像均匀的分割为“左”、“自”、“右”三个车道,定义三个阈值tl、te、tr,分别用于三个车道的二值化,三个阈值计算公式如下所示:
其中k是一个自定义的权值,il、ie、ir分别是“左”车道、“自”车道、“右”车道区域内所取像素块的平均灰度值,利用计算得到的三个阈值,对三个车道分别进行二值化处理,最终确定二值化候选车辆搜索区域。
所述步骤四中,逐列对图像进行搜索,对每一列像素,计算连续的灰度值为“0”的像素个数l,每一列像素计算出多个l,根据车辆宽度先验知识进行定义一个区间i=[il,ih],若某个l属于区间i=[il,ih],把这个l认为是一个候选车辆。
所述步骤五中,语义关系如下:
第一,同一车道的车辆在行驶的过程中会保持一个纵向安全距离dh,若位于第x像素列上的某个候选车辆被检测到,则该候选车辆所在车道上[x,x+dh]像素列范围内的后续车辆被滤除;
第二,相邻车道,纵向距离相近的车辆会保持一个横向安全距离dv,若某两个车辆纵向距离相近且其横向小于dv,则位于“自”车道上的候选车辆被保留,另一个候选车辆被滤除。
所述步骤六中,用nn表示视频第n帧中的检测框bn连续稳定出现的帧数,为了判断bn是否稳定,定义一个漂移系数cn:
其中wn-1和wn分别表示视频第n-1和n帧中检测框bn-1和bn的宽度,dc表示bn-1和bn的中心点之间的距离,若cn<0.5,bn是一个稳定的检测框,nn→nn+1,若cn>0.5,nn→nn/5,如果nn>10,bn是一个置信度高的检测框,若当前帧检测框突然消失,利用前10帧的检测结果插值,预测一个检测框作为当前帧的检测结果。
与现有技术相比,本发明首先建立3d交通场景模型,将输入图像与3d空间关联,确定3d候选车辆搜索区域;二值化车辆搜索区域,采用快速扫描线算法产生候选车辆;在2d图像和3d空间之间进行语义推理、交互验证,充分利用先验知识、车辆之间的约束关系、事物之间的依赖关系、车辆外观信息,对候选车辆进行滤波处理;利用时空一致性提高车辆检准率和鲁棒性。本发明的候选车辆生成过程在3d空间中进行,这个操作能放大距离较远的车辆,有效提高对远距离小尺寸车辆的检测率,时空记忆更新机制能减少置信度较高车辆偶尔出现的漏检,这也对提高检测率很有帮助,语义推理机制使本发明的误检率降低。
附图说明
图1为本发明的流程图;
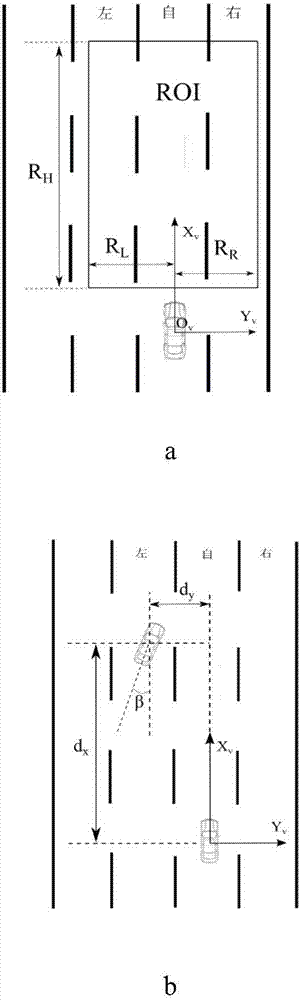
图2为本发明中3d交通场景模型示意图;其中,a为路面模型;b为车辆模型;c为相机模型;
图3为本发明中候选车辆生成过程示意图。
具体实施方式
下面结合附图对本发明做进一步说明。
参见图1,本发明包括以下步骤
1、建立3d交通场景模型,参考图2,
3d交通场景模型定义为:
m={r,v,c}(1)
所有参数定义在自车坐标系vc={ov,xv,yv,zv}下,该模型由三个子模型组成:
r={rl,rr,rh}(2)
v={dx,dy,ux,uy,ax,ay,β,pl}(3)
其中,路面模型r={rl,rr,rh}是一个长方形区域,如图2(a)中标记为红色的区域所示。rl是区域左边界,rr是区域右边界,rr是xv方向的范围。基于车道宽度3.75m的先验知识,定义rl=-5.625m,rr=5.625m。根据实际需求,定义rh=50m。车辆模型v={dx,dy,ux,uy,ax,ay,β,pl}部分参数的物理含义如图2(b)所示。dx、ux、ax分别表示前方车辆相对于自车在xv方向的距离、速度、加速度,dy、uy、ay分别表示前方车辆相对于自车在yv方向的距离、速度、加速度,β表示前方车辆车身相对于xv方向的角度,pl={l_lane、c_lane、r_lane}代表前方车辆的车道信息,如左车道、自车道、右车道。相机模型
2、候选车辆搜索区域,参考图3;
传统方法的候选车辆搜索区域通常局限在2d图像平面内。本发明提出在3d空间中确定候选车辆搜索区域,定义路面模型r={rl,rr,rh}为候选车辆搜索区域,然后将图像投影到该区域。假设自车坐标系下一个点pv=(xv,yv,zv)和相机坐标系下一个点pc=(xc,yc,zc),pv和pc通过以下公式建立关联:
pv=rpc+t(5)
其中,r和t由相机模型c确定。
假设图像坐标系下一个点pi=(u,v),pi和pc可通过以下公式建立关联:
其中,α、β、u0、v0通过相机内参标定方法而获得。根据以上公式推导,获得pv和pi的关联关系,进而将图像信息投影到3d空间下的,最终获得候选车辆搜索区域。
3、自适应多阈值二值化方法,参考图3;
候选车辆搜索区域用一张灰度图像表示,为了搜索候选车辆首先将该灰度图像二值化。将灰度图像均匀的分割为“左”、“自”、“右”三个车道。定义三个阈值tl、te、tr,分别用于三个车道的二值化。三个阈值计算公式如下所示:
其中k是一个自定义的权值,il、ie、ir分别是“左”车道、“自”车道、“右”车道区域内所取像素块的平均灰度值。利用计算得到的三个阈值,对三个车道分别进行二值化处理,最终确定二值化候选车辆搜索区域。
4、生成候选车辆,参考图3;
采用一种快速扫描线的方法在二值化候选车辆搜索区域上搜索候选车辆。逐列对图像进行搜索,对每一列像素,计算连续的灰度值为“0”的像素个数l,每一列像素可能计算出多个l。根据车辆宽度先验知识进行定义一个区间i=[il,ih],若某个l属于区间i=[il,ih],把这个l认为是一个候选车辆。本发明中假设车辆宽度为1.5m-3m,所以il=1.5f,ih=3f,f为单位换算系数。
5、场景语义推理;
以上所述候选车辆生成方法会对同一个目标产生多个候选车辆,原因是同一个目标通常占据多个像素列。本发明通过分析车辆之间的语义关联确认候选车辆。本发明考虑两个车辆之间的语义关系:第一,同一车道的车辆在行驶的过程中会保持一个纵向安全距离dh,若位于第x像素列上的某个候选车辆被检测到,则该候选车辆所在车道上[x,x+dh]像素列范围内的后续车辆被滤除;第二,相邻车道,纵向距离相近的车辆会保持一个横向安全距离dv,若某两个车辆纵向距离相近且其横向小于dv,则位于“自”车道上的候选车辆被保留,另一个候选车辆被滤除。
为了进一步滤除不合理的候选车辆,本发明考虑了三种车辆与其它事物之间的语义关系:1)车辆和路面的依赖关系;2)车辆和天空的依赖关系;3)车辆和道路边界的依赖关系。正常车辆应行驶在路面上,而不能悬浮于空中。本发明提出在3d空间中确定候选车辆搜索区域,即保证了候选车辆满足前两个语义关系约束。车辆与道路边界的依赖关系至关重要,在实验中发现,当自车行驶在最左车道或最右车道时,部分候选车辆易出现在道路边界之外。本发明提出一种简单的方法对道路边界进行粗略的判断。首先利用步骤3中计算的阈值te对整个搜索区域进行二值化处理,然后在二值化图像中“左”车道和“右”车道区域内,每隔5个像素采样一行像素,对每一行像素进行分析,若某一行80%以上像素的灰度值是“0”,则该行像素所在车道被认为处在道路边界以外,该车道上的候选车辆被滤除。
以上语义推理基于3d场景信息,为了在2d图像中进行语义推理再次确认候选车辆,将候选车辆投影到2d图像上,利用候选车辆的外观特征对候选车辆进行进一步滤波处理。本发明通过检测2d图像平面中候选车辆的水平线段特征滤除一部分不合理的候选车辆。一个车最少拥有一条显著的水平线段(比如,保险杠、尾部边沿、车窗边沿等),因此水平线段特征是一个较鲁棒的特征。若某个候选车辆不存在水平线段,该候选车辆被滤除。
6、时空记忆更新;
针对具有高置信度的车辆,若偶尔某一帧或者几帧出现漏检,根据时空记忆预测这些帧的检测结果。为实现这个目的,首先估计车辆的置信度,估计的主要依据是某个检测框连续稳定地出现在一个视频中的帧数。用nn表示视频第n帧中的检测框bn连续稳定出现的帧数。为了判断bn是否稳定,定义一个漂移系数cn:
其中wn-1和wn分别表示视频第n-1和n帧中检测框bn-1和bn的宽度,dc表示bn-1和bn的中心点之间的距离。若cn<0.5,bn是一个稳定的检测框,nn→nn+1。若cn>0.5,nn→nn/5。如果nn>10,bn是一个置信度高的检测框,若当前帧检测框突然消失,利用前10帧的检测结果插值,预测一个检测框作为当前帧的检测结果。
7、结果输出;
本发明提出的车辆检测方法的检测结果不仅包括2d图像中的信息,也包含了丰富的3d空间信息。在2d图像中,检测结果表示为一个矩形检测框:
b={xtl,ytl,w,h}(9)
其中(xtl,ytl)表示检测框左上角的点,w和h分别表示检测框的宽和高。
在3d空间中,检测结果用步骤1中的车辆模型v={dx,dy,ux,uy,ax,ay,β,pl}表示。dx和dy通过把b逆投影到自车坐标系vc={ov,xv,yv,zv}下得到,
8、验证性实验;
本发明提出的车辆检测方法在在两个真实交通场景、覆盖不同车辆大小、形状、颜色、朝向、距离,天气状况,光照条件的数据集上进行了算法验证。数据集视频信息见表1。
表1车辆检测方法验证数据集
本发明采用3种评价指标,检测率(dr)、平均误检数(fppi)、平均每帧耗时(tcpi):
其中ntp表示正检数,ng表示真值数,nfp表示误检数,nf表示视频帧数,tf表示总时间消耗。
对每个检测框bd,通过如下公式计算它与真值bg的重叠率or:
一帧图像中可能有多个真值,若存在某个真值,它与bd的重叠率or大于阈值ttp,则检测框bd被认为是一个正检。若不存在任何一个真值与bd的重叠率or大于阈值ttp,则检测框bd被认为是一个误检,本发明中取ttp=0.5。
本发明提出的方法与三种经典的车辆检测方法进行了对比:hog-svm、dpm-lsvm、fasterr-cnn。定量结果见表2。
表2车辆检测方法性能对比
与fasterr-cnn的对比实验,本发明使用了zf模型,表2中originalzf表示中训练好的zf模型,customizedzf表示自己训练的zf模型。三种对比方法都是基于“训练+分类”模式的方法,因此训练样本对方法的性能密切相关。为了对比的公平,三种方法的训练样本都来自与测试数据相似的交通场景,尤其是customizedzf,其训练样本数据与no.1视频高度一致。
本发明提出的方法在三个评价指标上均显示出较大优势。在城区和高速测试数据上,包含一些外观奇特的车辆。对于这些车辆,若在训练样本中没有包含类似的样本,基于“训练+分类”模式的方法通常产生漏检,导致低检测率。本发明提出的方法无需训练样本,对不同外观的车辆表现出较强的鲁棒性,这也是本发明方法取得较高检测率的主要原因之一。本发明提出的候选车辆生成过程在3d空间中进行,这个操作能放大距离较远的车辆,有效提高对远距离小尺寸车辆的检测率。本发明的时空记忆更新机制能减少置信度较高车辆偶尔出现的漏检,这也对提高检测率很有帮助。本发明提出的方法误检率较低,这主要得益于语义推理机制。通过利用3d空间中的几何结构信息、先验知识、车辆之间的相互约束关系、车辆与路面的依赖关系、车辆与道路边界的约束关系,以及2d图像中车辆的外观特征,滤除了大量的具有不合理尺寸的候选车辆,也滤除了大量的位置不合理(比如天空、绿化带)的候选车辆。hog-svm方法通常会产生大量的误检。dpm-lsvm是一种很鲁棒的方法,误检率很低,然而对外观奇特的车辆和小尺寸的车辆漏检较多,导致检测率较低。与originalzf相比,customizedzf是利用与no.1视频高度一致的数据训练而得的,因此在no.1测试视频上的检测率提高了很多,但是在no.2测试视频上的检测率却降低了。另外,customizedzf在两个测试视频上的误检率都大大降低。
- 还没有人留言评论。精彩留言会获得点赞!