一种基于深度增强学习的人物图像搜索方法与流程
本发明涉及计算机视觉识别领域,具体涉及一种基于深度增强学习的人物图像搜索方法。
背景技术:
视频监控是提高公共安全管理水平的重要途径,随着图像采集技术成熟与存储技术成本的下降,越来越多的摄像机网络被部署在公共场所,如机场、火车站、商场、大学校园等。由此产生了海量的视频资源,采用人工筛查和处理,不仅效率低下,耗费大量的人力物力,还有可能引入一些人为因素,导致一些偏差。人是视频监控中最主要的目标之一,由此围绕人物的相关课题在计算机视觉领域得到广泛的关注。
人物图像搜索是的主要任务是:根据参考图像,在目标图像中判断是否包含目标人物并给出相应的位置。这同时考虑了计算机视觉研究中两个重要的领域——行人检测和人物重识别——的因素,不仅仅检测出目标人物,还需要识别判断是否参考人物及检测出来的结果是否是同一个人。人物重识别需要依赖于行人检测技术将行人从监控视频或者图像中提取出来。行人检测结果的好坏,直接影响着人物重识别的结果。人物图像搜索可以看做是对人物重识别的一种扩展。
目前对于人物图像搜索的研究主要存在以下问题:
1)目前的研究,将人物图像搜索简单分为两个独立的阶段:行人检测和人物重识别。
2)主流的行人检测算法,需要提供大量的候选框,存在大量的计算冗余。
技术实现要素:
本发明的目的在于,针对现有技术中存在的问题,提供一种基于深度增强学习的人物图像搜索方法,将目标人物搜索过程看作一个序列决策过程,同时考虑行人检测和人物识别两方面的因素,将其统一到一个框架中。其人物搜索过程无需通过额外的计算获取候选框,因而具有很好的时间效率。
为实现上述目的,本发明采用以下技术方案:
一种基于深度增强学习的人物图像搜索方法,用于从目标图像中搜索出参考图像中所包含的目标人物,包括以下步骤:
s1、定义多种对目标图像中的搜索区域进行调整的动作,其中包括一停止动作,即保持搜索区域不变的动作;
s2、构建可配置的深度模型,所述深度模型包括特征提取网络、策略选择网络和价值网络;
特征提取网络用于分别提取目标图像的搜索区域内的特征和参考图像的特征,并将两者的特征进行融合,形成融合特征;
策略选择网络用于根据融合特征,分别给出所有动作的概率;
价值网络用于根据融合特征计算出一状态值;
s3、采集训练样本,并使用训练样本对策略选择网络和价值网络进行训练;
s4、向深度模型输入参考图像及待测的目标图像,并初始化目标图像的搜索区域为全图;
s5、通过特征提取网络提取参考图像的特征;
s6、通过特征提取网络提取目标图像的搜索区域内的特征,并将其与参考图像的特征进行融合,形成融合特征;
s7、通过策略选择网络,根据s6中的融合特征,分别给出所有动作的概率,并采用贪心策略,选择概率最高的动作;
s8、若选择的动作不是停止动作,则对当前搜索区域执行该动作以更新目标图像中的搜索区域,并重复执行s6至s8,直至选择的动作为停止动作;
s9、当选择的动作为停止动作时,则价值网络根据当前的融合特征计算出一状态值;如果所述状态值大于一设定的阈值,则判定当前搜索区域为目标图像中包含目标人物的区域;否则判定目标图像中不包含目标人物。
进一步地,s1中定义的动作包括:
第一调整动作,从右下角向左上方缩小搜索区域,同时调整高度和宽度;
第二调整动作,从左下角向右上方缩小搜索区域,同时调整高度和宽度;
第三调整动作,从右上角向左下方缩小搜索区域,同时调整高度和宽度;
第四调整动作,从左上角向右下方缩小搜索区域,同时调整高度和宽度;
第五调整动作,从四个角向中心缩小搜索区域,同时调整高度和宽度;
第六调整动作,从右向左缩小搜索区域,仅调整宽度;
第七调整动作,从左向右缩小搜索区域,仅调整宽度;
第八调整动作,从左右两侧同时向中间缩小搜索区域,仅调整宽度;
第九调整动作,从下向上缩小搜索区域,仅调整高度;
第十调整动作,从上向下缩小搜索区域,仅调整高度;
第十一调整动作,从上下两侧同时向中间缩小搜索区域,仅调整高度;
停止动作,保持搜索区域不变。
进一步地,各动作中,宽度的调整变化幅度为|δx|=δx·wbbox,高度的调整变化幅度为|δy|=δy·hbbox;
其中wbbox和hbbox分别表示为当前搜索区域的宽度和高度,δx和δy分别表示变化幅度比率,δx=0.3,δy=0.2。
进一步地,所述特征提取网络中,将目标图像的搜索区域内的特征和参考图像的特征进行融合的方法为:
将两个特征每个维度上差的绝对值和乘积串接在一起,得到融合特征;目标图像的当前搜索区域内的特征表示为xc,参考图像的特征表示为xr,则融合特征表示为:
进一步地,所述特征提取网络采用残网络resnet-18的conv1到conv4的网络结构,利用在imagenet数据集上训练好的网络参数作为初始化。
进一步地,在s3中,每组训练样本包含的数据有:参考图像、目标图像、参考图像中对应的人物是否在目标图像中,以及目标框的位置信息;所述目标框为在目标图像中将目标人物框选在内的一矩形框。
进一步地,使用训练样本对策略选择网络和价值网络进行训练的方法为:
s301、向深度模型输入训练样本数据中包含的参考图像、目标图像以及目标框的位置信息,并初始化目标图像的搜索区域为全图;其中,策略选择网络和价值网络的参数采用随机初始化;
s302、通过特征提取网络提取参考图像的特征;
s303、通过特征提取网络提取目标图像的搜索区域内的特征,并将其与参考图像的特征进行融合,形成融合特征;
s304、将当前状态下的融合特征分别输入给策略选择网络和价值网络;通过策略选择网络,根据当前状态下的融合特征,分别给出所有动作的概率,并采用贪心策略,选择概率最高的动作;通过价值网络,根据当前状态下的融合特征,计算出当前状态下的状态值;
s305、对当前搜索区域执行s304所选择的动作以更新搜索区域,根据执行动作前及执行动作后搜索区域与目标框的交并比的变化情况,生成奖励信号,对策略选择网络的参数进行调整训练;
s306、若选择的动作不是停止动作,则在执行所选择的动作后,以更新后的搜索区域为基础,重复执行s303至s306,直至选择的动作为停止动作或达到设定的最大执行次数;
s307、将每一次重复执行s303至s306过程中产生的相关信息存入一记忆池中,所述相关信息包括当前状态下的融合特征、根据当前状态选择的动作、当前状态下的奖励信号、对当前搜索区域执行动作后的下一个状态下的融合特征;
s308、从记忆池中随机选取样本,用于训练策略选择网络和价值网络,并将相应的梯度回传到特征提取网络,更新所有的网络参数。
进一步地,采用增强学习的方法对策略选择网络的参数进行训练的方法为:
执行某个调整搜索区域的动作之后,如果搜索区域与目标框的交并比变大,则给予正向奖励,否则给予负向奖励;对于停止动作,如果最后的交并比大于一设定的阈值,那么给予正向奖励,否则给予负向奖励。
与现有的技术相比,本发明的有益效果是:
第一,本发明所提出的方法是对人物重识别的一种扩展,不需要事先将视频图像中的人物分割出来,而是将两个任务结合起来做。在搜索过程中不需要额外的候选框,只需要若干次动作选择就可以判断是否找到目标人物,具有很高的时间效率。
第二,本发明利用增强学习的方法,通过与环境交互的方式,不断地执行动作,并根据获得的奖励来学习网络参数,整个搜索过程具有较强的可解释性。
附图说明
图1是本发明提供的一种基于深度增强学习的人物图像搜索方法的流程示意图。
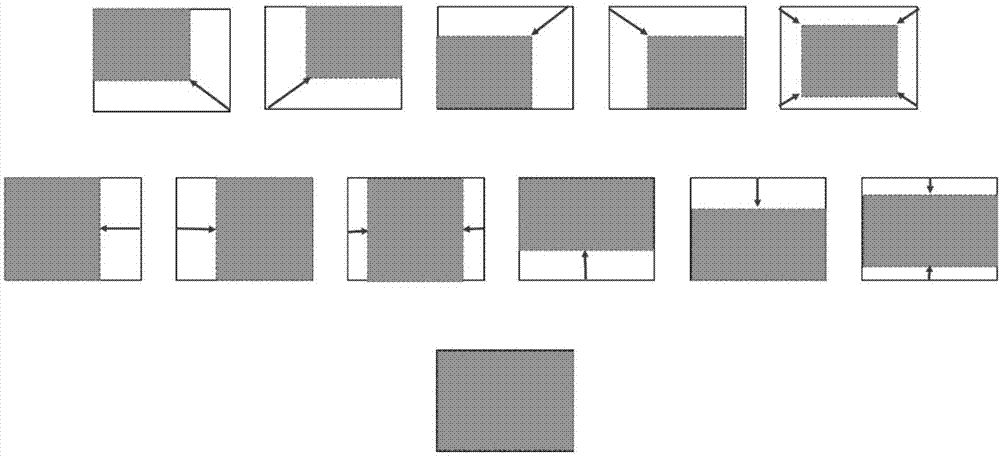
图2是本发明实施例中定义的12种动作的示意图。
图3是本发明实施例中深度模型的数据流向图。
具体实施方式
下面将结合附图和具体的实施例对本发明的技术方案进行详细说明。
如图1所示,本发明提供的一种基于深度增强学习的人物图像搜索方法,用于从目标图像中搜索出参考图像中所包含的目标人物,其具体包括以下步骤:
s1、定义多种对目标图像中的搜索区域进行调整的动作,其中包括一停止动作,即保持搜索区域不变的动作;
s2、构建可配置的深度模型,所述深度模型包括特征提取网络、策略选择网络和价值网络;
特征提取网络用于分别提取目标图像的搜索区域内的特征和参考图像的特征,并将两者的特征进行融合,形成融合特征;
策略选择网络用于根据融合特征,分别给出所有动作的概率;
价值网络用于根据融合特征计算出一状态值;
s3、采集训练样本,并使用训练样本对策略选择网络和价值网络进行训练;
s4、向深度模型输入参考图像及待测的目标图像,并初始化目标图像的搜索区域为全图;
s5、通过特征提取网络提取参考图像的特征;
s6、通过特征提取网络提取目标图像的搜索区域内的特征,并将其与参考图像的特征进行融合,形成融合特征;
s7、通过策略选择网络,根据s6中的融合特征,分别给出所有动作的概率,并采用贪心策略,选择概率最高的动作;
s8、若选择的动作不是停止动作,则对当前搜索区域执行该动作以更新目标图像中的搜索区域,并重复执行s6至s8,直至选择的动作为停止动作;
s9、当选择的动作为停止动作时,则价值网络根据当前的融合特征计算出一状态值;如果所述状态值大于一设定的阈值,则判定当前搜索区域为目标图像中包含目标人物的区域;否则判定目标图像中不包含目标人物。
具体地,如图2所示,在本发明实施例中共定义了12种动作,包括:
第一调整动作,从右下角向左上方缩小搜索区域,同时调整高度和宽度;
第二调整动作,从左下角向右上方缩小搜索区域,同时调整高度和宽度;
第三调整动作,从右上角向左下方缩小搜索区域,同时调整高度和宽度;
第四调整动作,从左上角向右下方缩小搜索区域,同时调整高度和宽度;
第五调整动作,从四个角向中心缩小搜索区域,同时调整高度和宽度;
第六调整动作,从右向左缩小搜索区域,仅调整宽度;
第七调整动作,从左向右缩小搜索区域,仅调整宽度;
第八调整动作,从左右两侧同时向中间缩小搜索区域,仅调整宽度;
第九调整动作,从下向上缩小搜索区域,仅调整高度;
第十调整动作,从上向下缩小搜索区域,仅调整高度;
第十一调整动作,从上下两侧同时向中间缩小搜索区域,仅调整高度;
停止动作,保持搜索区域不变。
假定当前搜索框用四元组表示{x1,y1,x2,y2},其中x1,y1分别表示左上角的横纵坐标位置,x1,y1分别表示左上角的横纵坐标位置,各动作中,对图像搜索区域进行调整动作的变化幅度为|δx|=δx·wbbox和|δy|=δy·hbbox,其中wbbox和hbbox分别表示为当前搜索区域的宽度和高度,δx和δy分别表示变化幅度比率。本实施例中,δx=0.3,δy=0.2。
进一步地,如图3所示,在本发明实施例中,所述特征提取网络将目标图像的搜索区域内的特征和参考图像的特征进行融合的方法为:将两个特征每个维度上差的绝对值和乘积串接在一起,得到融合特征;目标图像的当前搜索区域内的特征表示为xc,参考图像的特征表示为xr,则融合特征表示为:
具体地,所述特征提取网络采用残网络resnet-18的conv1到conv4的网络结构,利用在imagenet数据集上训练好的网络参数作为初始化。在深度学习框架中,通常卷积层conv和批量归一化层batchnorm和修正线性单元relu构成一个卷积运算结构单元。残差网络引入了一种残差块的结构,该结构将输入同时输入两个分支,其中一个分支经过多层卷积运算结构单元;另一个分支通过一层卷积运算结构单元或者不做处理,然后将两个分支的结果累加。在特征提取网络中,残差块的第一个分支,通过两层卷积运算单元,第二个分支不做运算,然后将两个分支相加。其中resnet-18的,conv1包含一个卷积运算结构单元,conv2、conv3和conv4,都包含两个残差块。通过特征提取网络,可以将特征缩小为原图大小的
策略选择网络中,将融合特征通过两层全连接层,再接一个softmax层,以输出每个动作的概率,用于指导动作的选择。通过动作的选择,调整当前搜索区域的位置与大小,进而达到搜索的目的。
价值网络中,将融合特征输入一层全连接层,以输出单个状态值,用于评价当前状态的好坏。状态值越大,意味着当前搜索区域中包含目标人物的可能性越大。
本发明主要包括两个阶段:s3中的训练过程和s4至s9的测试(实际使用)过程。两个阶段在数据输入和结果输出方面有所不同。在训练阶段中,需要提供目标图像中是否包含目标人物的判断结果;如果包含,还需要提供目标人物在目标图像中所处位置。测试阶段则只需要提供目标图像以及包含目标人物的参考图像。
下面将详细介绍本发明s3中对对策略选择网络和价值网络进行训练的过程:
在s3中,每组训练样本包含的数据有:参考图像、目标图像、参考图像中对应的人物是否在目标图像中,以及目标框的位置信息;所述目标框为在目标图像中将目标人物框选在内的一矩形框。
具体训练方法如下:
s301、向深度模型输入训练样本数据中包含的参考图像、目标图像以及目标框的位置信息,并初始化目标图像的搜索区域为全图;其中,策略选择网络和价值网络的参数采用随机初始化,本实施例中,具体采用高斯初始化;
s302、通过特征提取网络提取参考图像的特征;
s303、通过特征提取网络提取目标图像的搜索区域内的特征,并将其与参考图像的特征进行融合,形成融合特征;
s304、将当前状态下的融合特征分别输入给策略选择网络和价值网络;通过策略选择网络,根据当前状态下的融合特征,分别给出所有动作的概率,并采用贪心策略,选择概率最高的动作;通过价值网络,根据当前状态下的融合特征,计算出当前状态下的状态值;
s305、对当前搜索区域执行s304所选择的动作以更新搜索区域,根据执行动作前及执行动作后搜索区域与目标框的交并比的变化情况,生成奖励信号,对策略选择网络的参数进行调整训练;
s306、若选择的动作不是停止动作,则在执行所选择的动作后,以更新后的搜索区域为基础,重复执行s303至s306,直至选择的动作为停止动作或达到设定的最大执行次数;
s307、将每一次重复执行s303至s306过程中产生的相关信息存入一记忆池中,所述相关信息包括当前状态下的融合特征、根据当前状态选择的动作、当前状态下的奖励信号、对当前搜索区域执行动作后的下一个状态下的融合特征;
s308、从记忆池中随机选取样本,用于训练策略选择网络和价值网络,并将相应的梯度回传到特征提取网络,更新所有的网络参数。
需要说明的而是,当前状态指的是基于当前搜索区域进行计算的状态,下一状态指的是基于对当前搜索区域进行调整动作后形成的新搜索区域进行计算的状态。
进一步地,在s305中,采用增强学习的方法对策略选择网络的参数进行训练的方法为:
执行某个调整搜索区域的动作之后,如果搜索区域与目标框的交并比(iou)变大,则给予正向奖励,否则给予负向奖励;对于停止动作,如果最后的交并比大于一设定的阈值,那么给予正向奖励,否则给予负向奖励。
具体地,本发明是通过一种自顶向下的搜索方法,进行目标人物的搜索,执行某个动作之后,基于当前搜索区域与目标框的交并比的变化值来给出相应的奖励。假定状态为s,动作为a,当前搜索区域与目标框的交并比为iou(s),阈值为τ。对于t时刻下,状态st下执行动作at获得的奖励为r(st,at)。如果at为调整动作,那么:
如果at为停止动作,那么:
在本发明实施例中,设置:η=3,τ=0.5。
训练过程中,网络参数的更新过程如下:
假设在具体的训练阶段,每次迭代共输入n个训练样本{(r1,i1,a1),…,(rn,in,an)},其中ri表示第i个参考图像,ii表示第i个目标图像,ai表示目标图像ii中是否包含参考图像ri对应的目标人物,以及目标框的位置信息。参考图像的大小归一化为3x160x80,目标图像的最长边归一化为800。通过特征提取网络之后,参考图像的特征大小为256x10x5,目标图像的特征变成256x50x50。初始化当前搜索区域,将当前搜索区域对应的目标图像的特征,划分成10x5的网格,用每个网格中的最大值作为特征,最后提取到当前搜索区域对应的roi特征,其大小为256x10x5。将参考图像的特征和当前搜索区域的roi特征通过一个5x3的均值池化层,最后分别得到一个256x8x1特征,将两个特征看作是一个2048维的向量。将两者的特征求差值然后取绝对值的结果,与两个特征每个维度相乘的结果拼接在一起得到一个4096维的融合特征。融合特征用来表达,当前状态的信息。
在s304中,将融合特征分别输入给策略选择网络和价值网路,得到12个动作执行的概率值及当前状态的状态值。用ε贪心策略,选择概率最高的动作执行,获取相应的奖励。ε初始化为1,表示完全随机选择下一个执行的动作,随着迭代次数的增加,逐渐缩小ε,最小ε为0.05。执行选择的动作后,会立即给出一个奖励信号。
策略选择网络和价值网络的训练样本是通过不断与环境交互产生,因而需要记录与环境交互过程的相关数据。假定某个时刻t下,状态st下执行动作at获得的奖励为r(st,at),下一个时刻的状态为状态st+1。按照s307,需要将{st,at,r(st,at),st+1}存入记忆池中。
按照s308,从记忆池中选取m个记忆单元样本,用于更新策略选择网络和价值网络的参数。令策略选择网络和价值网络的参数分别表示为θπ、θv,折扣系数为γ。对于单个记忆单元{st,at,r(st,at),st+1},其价值v(st)的目标值为:
那么,价值网络的参数更新方式为:
策略选择网络的参数更新方式为:
其中α为学习率。在本发明中设置α=10-4,γ=0.9。
策略选择网络参数θπ和价值网络参数θv,通过深度神经网络的反向传播实现,在融合特征处,收集策略选择网络和价值网络得到的梯度,然后将其回传到特征提取网络,进而更新特征提取网络的参数。
本发明提出的人物图像搜索方法,融合了行人检测和人物重识别两个方面的因素,这里分别借鉴这两方面的评价指标:平均查准率map和目标排在第一位准确率top-1。map用于评价最后搜索区域与目标框的交并比的情况,在不同交并比下查准率的平均值。top-1用于评价在测试图像集gallery中,识别出目标人物的性能。
本发明所提出的方法将行人检测和人物重识别结合看做是一个任务,不需要额外的候选框,只需要若干次动作选择就可以判断是否找到目标人物,具有很高的时间效率。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!