一种基于广告网络拓扑的恶意网页广告检测方法与流程
本发明涉及互联网安全技术领域,具体涉及一种基于广告网络拓扑的恶意网页广告检测方法。
背景技术:
如今,互联网已经成为市场营销和推广的主导渠道,在浏览网页的时候我们很少不碰到广告;相比传统媒体,在线广告更方便和经济,但是在线广告也越来越多地被攻击者用于非法用途,如传播恶意软件,发布虚假信息,点击欺诈等。在线广告主要包括三个角色:出版商,代表广告商在他们的网页展示广告;广告主,创建广告,是网络广告的收入来源,在广告发布的过程中,广告网络把出版商和广告主联系起来,大型广告网络经常提供平台(如googledisplaynetwork),广告主可以选择出版商和指定目标观众;用户(观众),访问出版商页面和接受广告内容。在广告的发布过程中,出版商首先为广告网络在其网页嵌入广告标签,这是一个html或javascript代码。当一个用户访问出版商页面时,页面上的标签将生成对一个广告网络的广告内容的一个请求,包括代码、图片等,广告网络返回广告内容。我们把在线广告相关的恶意活动叫做恶意网页广告,恶意网页广告可以发生在广告发布链中的任何一个环节。主要的恶意网页广告攻击可以分为三种:路过式下载,利用浏览器或插件的漏洞,在未经用户同意或用户未知的情况下自动下载程序;诈骗和网络钓鱼,诱骗获取用户隐私敏感信息;点击欺诈:攻击者设置恶意的出版商网站,在用户不经意的时候自动的重定向用户流量(如通过隐藏iframes)到广告商页面。恶意网页广告不仅对互联网用户的隐私构成严重的威胁,而且可能给用户和广告商带来重大经济损失,同时也会影响一些著名的广告网络公司的声誉。针对上述情况,找到一种可以有效检测恶意网页广告攻击的方案具有重要的现实意义。
目前检测恶意网页广告通常是通过检查广告内容来检测他们是否是恶意网页广告。然而,恶意网页广告发布者经常使用混淆和代码加壳技术增加检测恶意网页广告的难度。更复杂的情况是目前非常普遍的广告联盟,它是一个商业模式,一个广告网络出售和转售它从出版商获得的投放广告的版面空间给其他广告网络和广告商,在层层外包的过程中显著增加了发布恶意网页广告的机会。它允许恶意网页广告网络直接提供广告给用户的浏览器,而不需要提交广告给更有信誉的广告网络和出版商从他们那里获得广告空间。此外,攻击者发明新的隐形策略,来利用广告发布渠道逃避检测。
技术实现要素:
针对上述现有技术中存在的问题,本发明的目的在于,利用恶意网页广告网络拓扑的特征,沿着广告发布链的每一个实体的角色、特征和他们之间的相互关系,提供一种基于广告网络拓扑的恶意网页广告检测方法。
为了实现上述任务,本发明采用以下技术方案:
一种基于广告网络拓扑的恶意网页广告检测方法,包括以下步骤:
步骤一,提取待测网站中的所有url;
步骤二,利用广告检测插件提取所述的url中所有广告的url;
步骤三,根据url之间的请求响应关系,结合步骤一得到的所有url和步骤二提取的广告相关的url,重新构造广告重定向链;
步骤四,对所述的广告重定向链上的每一个url节点,注释其角色属性、域的生命周期、url属性、重定向链的长度、节点的频率这些特征;
步骤五,对url节点注释特征后,提取每一个url节点所有的3-节点短路径段;所述的3-节点短路径段是指广告重定向链上,每相邻的三个url节点构成的路径段;
步骤六,将已知的恶意网页广告路径和从步骤五中得到的3-节点短路径段中选取每个节点的域的生命周期都超过一年的路径段作为训练数据,构建一颗完整的决策树,并对决策树进行剪枝,生成一组精简的检测规则来检测恶意网页广告。
进一步地,所述的步骤五的具体步骤包括:
步骤5.1,对广告重定向链进行预处理
删除广告重定向链上所有已知的出版商节点;如果一组连续的节点来自相同的域共享相同的属性,则将这些节点合并为一个节点;
步骤5.2,预处理之后,对广告重定向链提取所有可能的3-节点短路径段;如对于广告重定向链a–>b–>c–>d–>e,提取3-节点短路径段,可以得到a–>b–>c,b–>c–>d,c–>d–>e;如果一条路径短于3个节点,则用空节点来补全。
进一步地,所述的步骤六中,构建决策树的步骤包括:
1)以步骤六中所述的训练数据为样本,作为一个节点开始;
2)如果样本都在同一个类中,即样本的属性取值都相同,则该结点成为决策树的叶子结点,不再对其划分;否则,选择一个最具有分类能力的属性,根据样本对于该属性取值的不同,将样本划分为若干个子样本,每个取值形成一个决策树的分枝,有几个取值则形成几个分枝;
3)针对上一步得到的一个子样本,重复进行先前步骤,递归形成每个子样本上的决策树;
4)递归的过程当且仅当下列条件之一成立时停止:
①每一个子样本都属于同一类,为决策树的叶子结点;
②没有剩余的属性可以用来进一步划分样本;在这种情况下,就认为这些样本都属于同一类,把它们作为决策树的叶子结点;
5)决策树中每一条到叶子结点的分支即为一条检测规则。
进一步地,所述的“最具有分类能力的属性”是指具有最大信息增益的属性,所述的信息增益的计算公式为:
上式中,a表示样本s的一个属性,value(a)是属性a所有的取值集合,v是a的其中一个取值,sv是样本s中a的取值为v的子样本集合,所述的样本的属性指步骤四所述的特征;entropy(s)表示信息熵,其计算公式为:
其中,m为样本的类别数,
本发明具有以下技术特点:
1.无需出版商对其网站有任何修改,容易实施,适用性更强。
2.不依赖于广告网页的内容,所以对代码混淆、加壳具有鲁棒性。
3.攻击者难以改变广告网络拓扑中实体的多种特点和相互连接关系,尤其是有些实体是由合法域所控制的。对于检测利用广告联盟的恶意网页广告,仍然具有有效性。
4.相比单一的恶意网页广告检测技术,本方法可检测多种类型的恶意网页广告攻击如网络钓鱼和点击欺诈,具有广泛性。
5.能够捕捉大量的恶意网页广告案例,误报率低。
附图说明
图1为本发明方法流程图;
图2为url提取原理图;
图3为恶意网页广告检测过程示意图;
图4为提取3-节点短路径段过程示意图;
图5为生成决策树的基本流程图;
图6为本方法的训练和测试数据;
图7为本方法检测恶意网页广告的误报率;
图8为本方法对“未知-1”数据集的检测结果;
图9为本方法对“未知-2”数据集的检测结果;
具体实施方式
本发明提供了一种基于广告网络拓扑的恶意网页广告检测方法,包括以下步骤:
步骤一,提取待测网站中的所有url;
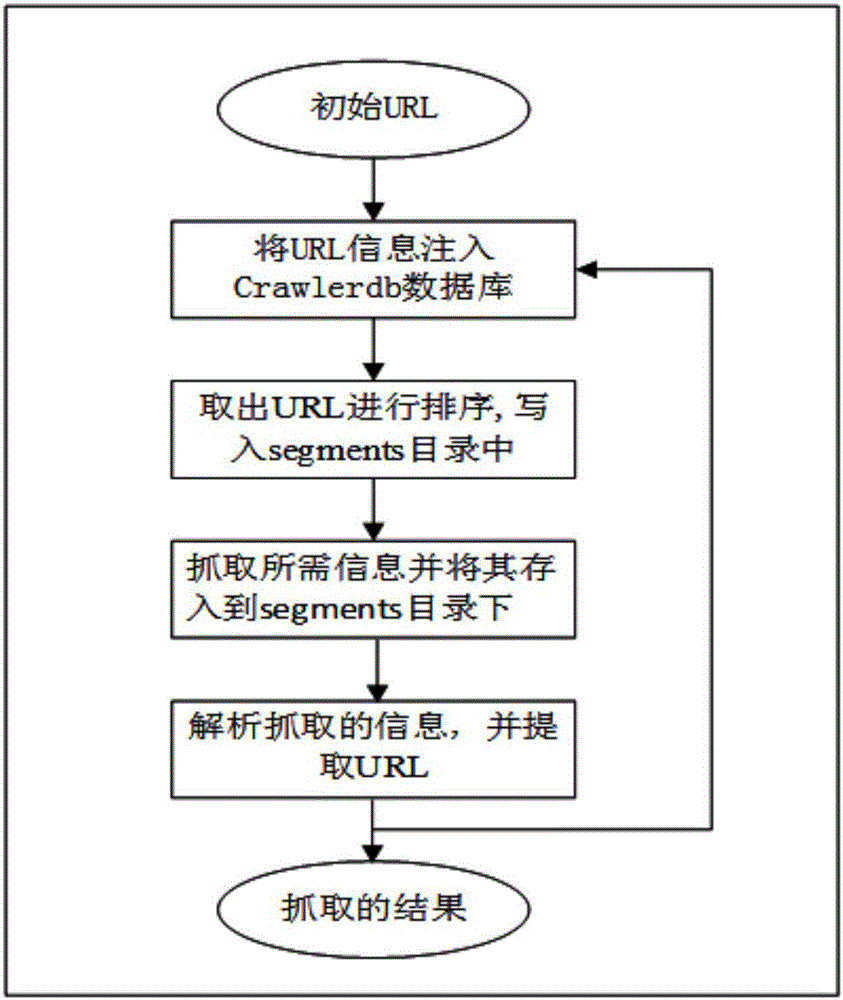
该步骤提取待测网站中的url信息,可利用url抓取软件,例如开源网络爬虫nutch来得到待测网站中所有的url。url提取原理如图2所示。
本实施例中通过改进开源网络爬虫nutch抓取网站中所有的url。一次抓取过程如下,不断重复即可获得网站中的所有url。把抓取的每个url称为节点。
1)注入操作,提供爬虫运行的初始数据,提交初始url信息到crawlerdb数据库中。
2)生成操作,创建抓取列表。从数据库中取出url并进行排序,排序之后的url写入segments目录中。
3)获取内容,这个步骤主要是抓取信息,包括所访问页面的所有网络请求、响应、浏览器事件并将其存入到segments目录下。
4)解析内容,将抓取的信息解析为具体的数据,并提取url。
5)更新url库,一个网页中通常会包含多个二级链接,为了提取整个网站的信息,将上一步中提取的url添加到crawlerdb数据库中,以替换旧的url并进行下一轮抓取操作。
步骤二,利用广告检测插件提取所述的url中所有广告的url
为了实现对恶意网页广告的检测,只需要提取广告相关的url即可。本方法使用adblockpluschinalist+easylist+easyprivacy这三个著名的列表检查步骤一中得到的所有url,如果一个url可以匹配这三个列表给出的任一规则,则该url为广告相关的url,并标记为广告节点,因此可以提取出所有广告相关的url。chinalist和easylist是两个广告的过滤列表,通过匹配规则,可以删除绝大多数的网页广告,包括不需要的框架,图像和对象。目前主流的浏览器如谷歌、火狐、360安全浏览器等都是利用chinalist和easylist来屏蔽广告。easyprivacy是对easylist的补充,用于识别网站的用户跟踪脚本,以减少用户浏览历史被记录。这样的脚本一般被用于广告商的广告精确投放。
步骤三,根据url之间的请求响应关系,结合步骤一得到的所有url和步骤二提取的广告相关的url,重新构造广告重定向链;
在广告发布的过程中,出版商的网页将观众的浏览器重定向到一个广告网络,这个广告网络直接返回一个广告或者执行进一步重定向。重定向的实现通常是通过html代码,或http重定向(如通过在响应状态码302)。假设a、b、c、d、e为五个url,a被重定向到b,b被重定向到c,c被重定向到d,d被重定向到e,如果a、b、c、d、e中至少有一个节点在步骤二中被标记为广告节点,则重新构造广告重定向链,将该广告重定向链表示为a->b->c->d->e。
步骤四,对所述的广告重定向链上的每一个url节点,注释其角色属性、域的生命周期、url属性、重定向链的长度、节点的频率这些特征;
任何节点在一个广告发布过程中执行恶意活动,如果提供恶意内容,非法重定向用户点击流量等等,就称这个节点为恶意节点。相应地,任何路径包含恶意节点称为恶意网页广告路径。节点的特征如角色属性等可以用来区分恶意节点和正常节点,但是单独使用这些特征是不可靠的,另一方面,广告的重定向不同于普通的网页重定向,具有独特的特点,因此,研究广告的网络拓扑结合单个节点的特征,能够更好的用来检测恶意网页广告。步骤四的具体过程如下:
步骤4.1,注释角色属性。url节点可以分为三类,分别为出版商节点、广告节点和未知节点,恶意节点一般都是未知节点。把来自出版商域的节点注释为publisher,出版商节点通常为重定向链的第一个节点。广告节点即为步骤二中所标记的广告节点注释为ad。如果一个节点不是一个出版商和广告节点,则为未知节点,注释为unknown。
步骤4.2,注释域的生命周期。通常攻击者不太可能注册长期的域名,因为恶意域名被发现会迅速地列入黑名单。对于每个节点,查询whois服务器获得域名的生命周期,即其注册日期和到期日期之间的时间。我们标记域的生命周期是否超过一年,超过一年注释为life-long,否则注释为life-short。
步骤4.3,注释url属性。首先,确定是否使用免费域名提供商(如as.co.cc),来自这些域的所有节点注释为domain-suspicious,恶意节点通常来自这些域,其他的注释为domain-normal。第二,攻击者通常使用模板或脚本生成的url,因此对360安全浏览器已经检测到恶意网页广告的url中提取词汇特征,词汇特性包括子目录名、文件名和参数名。然后使用正则表达式自动生成工具autore,生成37个url正则表达式。如果一个节点匹配37个正则表达式的任何一个,注释为url-suspicious,其他的为url-normal。
步骤4.4,注释重定向链的长度。重定向链的长度是广告重定向链上经过的节点的个数。恶意的广告重定向链中由于存在多个实体(例如利用服务器和转向器)和广告联盟的使用,导致其平均长度较长。根据360安全浏览器已经检测到恶意网页广告,其重定向链的平均路径长度是8.11节点,因此把重定向链的长度大于8的注释为path-long,其余的注释path-short。比如,广告重定向链a->b->c->d->e,该重定向链的长度为5,因此对a、b、c、d、e注释path-short。
步骤4.5,注释节点的频率。这个指标衡量节点的受欢迎程度和稳定性。对于每个节点,计算与这个节点联系的不同出版商的数量即为节点的频率,当频率大于10则注释为popular,否则unpopular。
步骤五,对url节点注释特征后,提取每一个url节点所有的3-节点短路径段;所述的3-节点短路径段是指广告重定向链上,每相邻的三个url节点构成的路径段;
对广告重定向链上的每个节点注释步骤四所述的特征之后,提取所有的3-节点短路径段,如图4所示。由于直接依赖广告重定向链检测恶意网页广告有两个问题,第一,一个恶意的广告路径通常混合着恶意节点和合法节点;第二,恶意节点在广告路径上的位置通常都不是固定的。因此采用3-节点短路径段来检测恶意网页广告。采用3-节点短路径段表示广告网络拓扑的好处在于,第一,减轻了合法节点的存在引入的噪声;第二,可以更精确的识别恶意节点的位置。
进一步地,所述的步骤五的具体步骤包括:
步骤5.1,对广告重定向链进行预处理
由于本方法重点在研究广告网络拓扑而不是特定的出版商,因此删除广告重定向链上所有已知的出版商节点;如果一组连续的节点来自相同的域共享相同的属性,则将这些节点合并为一个节点;
步骤5.2,预处理之后,对广告重定向链提取所有可能的3-节点短路径段;例如对于广告重定向链a–>b–>c–>d–>e,提取3-节点短路径段,可以得到a–>b–>c,b–>c–>d,c–>d–>e;如果一条广告重定向链少于3个节点,则使用空间点(null)来补全,构成一条3-节点短路径段。
步骤六,机器学习生成检测规则
将已知的恶意网页广告路径和从步骤五中得到的3-节点短路径段中选取每个节点的域的生命周期都超过一年的路径段作为训练数据,构建一颗完整的决策树,并对决策树进行剪枝,生成一组精简的检测规则来检测恶意网页广告。具体步骤如下:
步骤6.1,选择训练数据。本方法使用“已知坏”的数据集和“可能好”的数据集作为训练数据。首先,把360安全浏览器已经检测到的恶意网页广告路径(即已知的恶意网页广告路径)作为“已知坏”的数据集。其次,从步骤五中得到的3-节点短路径段中选取每个节点的域的生命周期都超过一年的路径段,作为“可能好”的数据集。因为恶意网页广告节点的域的平均生命周期通常是非常短暂的,如果有很长的生命周期,则说明该节点有合法的、稳定的业务合作关系,所以把每个节点的域的生命周期都超过一年的路径段作为“可能好”的数据集。
步骤6.2,构建决策树。
本方案的构建算法是以信息熵和信息增益作为衡量标准的一种决策树算法。信息熵是指信息的混乱程度,信息熵的计算公式为:
其中,m为样本的类别数,
信息增益是指划分前后信息熵的变化,是针对单个属性而言的,计算公式:
其中,a表示样本s的一个属性,value(a)是属性a所有的取值集合,v是a的其中一个取值,sv是样本s中a的取值为v的子样本集合。把步骤四中注释的节点的特征即角色属性、域的生命周期、url属性、重定向链的长度、节点的频率等特征作为样本的属性。例如对于样本的一个属性,域的生命周期,该属性的取值集合即为{life-short,life-long}。对于一个属性,其信息增益越大,表示它划分样本的能力就越强,越具有代表性。最具有分类能力的属性即为最大信息增益的属性,对样本每一次划分之前,需要先计算每一个属性所带来的信息增益,选择最大信息增益的属性来划分样本。
构建决策树的步骤包括:
1)以步骤6.1中所述的训练数据为样本,作为一个节点开始;
2)如果样本都在同一个类中,即样本的属性取值都相同,则该结点成为决策树的叶子结点,不再对其划分;否则,选择一个最具有分类能力的属性,根据样本对于该属性取值的不同,将样本划分为若干个子样本,每个取值形成一个决策树的分枝,有几个取值则形成几个分枝;
3)针对上一步得到的一个子样本,重复进行先前步骤,递归形成每个子样本上的决策树;这里的先前步骤是指将所述的子样本当做步骤6.1中所述的节点,然后重复步骤2);
4)递归的过程当且仅当下列条件之一成立时停止:
①每一个子样本都属于同一类,为决策树的叶子结点;
②没有剩余的属性可以用来进一步划分样本;在这种情况下,就认为这些样本都属于同一类,把它们作为决策树的叶子结点;
5)决策树中每一条到叶子结点的分支即为一条检测规则。比如unknown->life-short->domain-suspicious->url-suspicious->path-short->unpopular。
步骤6.3,对决策树进行剪技。决策树的剪枝是对上一步骤生成的决策树产生的初步规则进行检验、校正的过程,将影响准确性的分枝剪除,从而得到精简的检测规则。本方法采用的是后剪枝,即先构造树,再对其进行剪枝。
由于每个节点都注释了6种不同特征,则整个决策树有大量的叶子节点。因此需要利用相对较小的“已知坏”的数据集对其进行剪枝。首先选择叶子节点的一个子集,该子集从训练数据可以检测至少一个恶意节点。接着,根据对“可能好”的训练数据集的误报率对叶子结点进行升序排序,仅保留致使误报率不高于一个预定义的阈值(本方法中设为0.02%)的叶子结点。根据最后需要保留的叶子结点,沿着树结构进行剪枝,从而获得更精简的检测规则。
步骤6.4,如果一条路径能够匹配任何一条已经学习的规则,则报告这条路径为恶意网页广告,并标记相应的出版商为被感染的出版商。同时,新发现的恶意网页广告路径作为新的学习数据,不断更新检测规则。
之所以使用决策树算法的原因如下:
决策树(decisiontree)是一种非常成熟的、普遍采用的数据挖掘技术。之所以称为树,是因为其建模过程类似一棵树的成长过程,即从根部开始,到树干,到分枝,再到细枝末节的分叉,最终生长出一片片的树叶。在决策树里,所分析的数据样本先是集成为一个树根,然后经过层层分枝,最终形成若干个结点,每个结点代表一个结论。
决策树算法适用于数值型和标称型(离散型数据,变量的结果只在有限目标集中取值),能够读取数据集合,提取一系列数据中蕴含的规则。使用决策树算法有很多的优点,其计算复杂度不高、便于使用、而且高效,决策树可处理具有不相关特征的数据、可很容易地构造出易于理解的规则,而规则通常易于解释和理解。
仿真实验
实验环境:
windows10操作系统,3.30ghz处理器,8gb内存,myeclipse10开发环境。
实验数据:
通过网络爬虫提取alexa排名前100,000的网站主页的url信息,为了获得不同的广告,爬虫每隔两天访问一次每个网页,每个网页刷新3次。实验数据主要分为两部分,分别为训练数据和测试数据。
训练数据来自2017年1月1日至3月31日之间,网络爬虫共收集到21,944,174个url,其中736,475为广告相关的url,重新构造广告重定向链53,100条。首先,收集到的数据分为三类,分别标记为“可能好”的数据集、“已知坏”的数据集,把既不是“可能好”又不是“已知坏”的数据标记为“未知-1”。然后,把“可能好”的数据集等分为两个子集,将其中一个子集“可能好-1”和“已知坏”的数据集用于训练,另一个子集“可能好-2”用于评估误报率(fp)。
测试数据为2017年1月1日至3月31日标记为“未知-1”的数据集和2017年4月1日至4月30日之间所有收集的数据标记为“未知-2”。图6总结了这些数据。
训练与检测结果:
从训练数据共产生82条规则。使用“可能好-2”子集检查这些规则造成的误报,并计算误报率。这里的误报率定义为nfp/(nfp+ntn),nfp表示假阳性的数量,ntn表示真阴性的数量。本方法对0.11%网页和0.098%广告路径段是错误警告的,这表明,由本方法检测恶意网页广告引入误报率非常低,如图7所示。
采用错误检测率评估本方法的性能。这里的错误检测率定义为nfp/(nfp+ntp),nfp表示假阳性的数量,ntp表示真阳性的数量。对“未知-1”和“未知-2”数据集进行检测,总共检测到617个被感染的出版商网页和9568条恶意网页广告路径,错误检测率在5%左右,图8、图9详细展示了检测结果并与国内主流的浏览器360安全浏览器进行对比,可以看出本方法具有更高的检测性能。
- 还没有人留言评论。精彩留言会获得点赞!