一种基于索引关系的古文献统一逻辑检索方法与流程
本发明涉及一种基于索引关系的古文献统一逻辑检索方法,属于文献检索
技术领域:
。
背景技术:
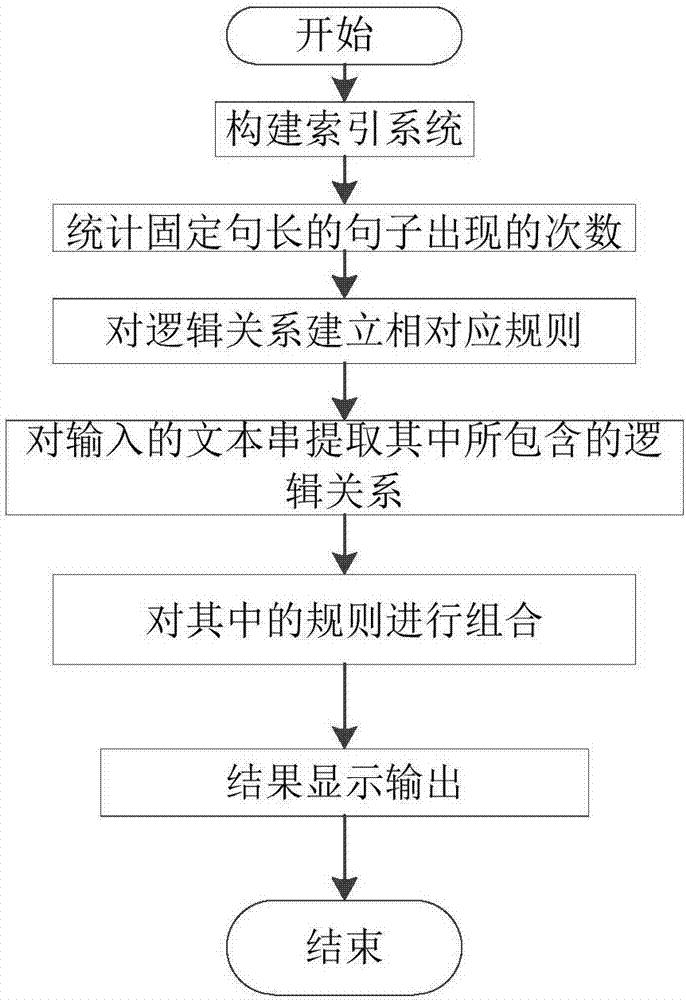
:古文献数据是一种海量信息的存储,如何能够通过合理的快速的检索获得满足用户需要的信息,并且通过使用计算机的方式自动的对古文献的不同对象进行研究,发现一些变化,进而获取一些有价值的知识。因为,相对于不同国家的不同文化,语言也存在很大的差异,因此,设置特定的针对中国的古文献的检索至关重要,为知识发现奠定基础。现有的有关检索方面的专利多集中针对互联网上的信息快速检索,而针对古文献的检索研究比较少;例如申请公布号:cn105989030a,申请者提出的一种文本检索检索方法和装置;在该专利中通过对用户输入的文本进行分词划分,显示各个关键词,然后再由用户去选择其中的关键词进行检索,仅实现对互联网上的信息进行快速检索,而不能针对古文献的快速检索以及对各种对象进行研究分析。例如申请公布号:cn105354325a,申请者提出的一种文献检索及分析系统,该专利通过设置基本检索模块,该检索模块是在结构化的数据库中进行检索;设置拓展检索模块,该检索模块是根据用户请求结合自然语言处理进行搜索;设置多源集成检索模块,该检索模块是对专利数据库的多数据源整合以及用户的跨库检索;虽然该专利通过多方面关联输出更符合用户要求的结果,但是设置不能针对古文献的各种对象进行统计分析研究。技术实现要素:本发明要解决的技术问题是提供一种基于索引关系的古文献统一逻辑检索方法,主要用于解决古文献的检索问题,为知识发现奠定了基础。本发明采用的技术方案是:一种基于索引关系的古文献统一逻辑检索方法,包括下述步骤:1)构建索引系统:读取文本;建立第一索引表,第一索引表包括文档编号及该文档编号对应的文档名称;建立第二索引表,第二索引表包括所有文档中不同的字符及该字符出现在哪些文档中;建立第三索引表,第三索引表包括每个文档中的所有不同的字符及该字符的位置;把第一索引表、第二索引表、第三索引表写入索引文件中进行保存;2)统计固定句长的句子出现的次数:读取第三索引表;因句号、问号、感叹号表示句末的停顿,通过读取第三索引表,能够得到每个文档中句号、问号、感叹号的索引信息,分别记为a、b、c,其中a、b、c中的对应关系为:a[a1,a2,a3······an]、b[b1,b2,b3······bn]、c[c1,c2,c3······cn],α:a1<a2<a3<······<an、b:b1<b2<b3<······<bn、c:c1<c2<c3<······<cn且(a1···an)、(b1···bn)、(c1···cn)互不相等,a、b、c分别代表着标点符号句号、问号、感叹号,a1-an表示句号在第三索引中出现的位置,b1-bn表示问号在第三索引表中出现的位置,c1-cn表示感叹号在第三索引表中出现的位置;将已经排好序的a、b、c进行合并,定义d、e集合:首先对a、b进行合并,每个序列都维护一个位置指针,并让两个指针同时在两个列表中后移,分别取两个序列的开头a1与b1进行比较,如果a1<b1,则d[a1,b1],指针分别向后移动一位,取a2与b2进行比较,如果b2<a2,则d[a1,b1,b2],将小的那个数组所对应的指针后移一位即b3与a2进行对比,按照从小到大的顺序进行排序,直到a、b两个序列中的数都取完,再将序列c中的数与序列d中的数,按照上述原则进行再次比较,存入集合e中,这样将a、b、c合并为一个按照大小顺序排列的集合e;集合e[e1,e2,e3······en]其中e:e1<e2<e3<······<en,定义集合f,f为:f[e2-e1,e3-e2,e4-e3,······,en-e(n-1)];统计集合f中相同数值出现的次数;3)对逻辑关系建立相对应规则:建立交集,对于字符x及字符y,其中x的区间集合:{x1∈{a1<x1<b1},x2∈{a2<x2<b2},x3∈{a3<x3<b3},······,xn∈{an<xn<bn}}其中y的区间集合:{y1∈{c1<y1<d1},y2∈{c2<y2<d2},y3∈{c3<y3<d3},······,yn∈{cn<yn<dn}}设a2=c2,b2=d2;a3=c3,b3=d3;a5=c5,b5=d5则x∩y={{a2<x<b2},{a3<x<b3},{a5<x<b5}}或者x∩y={{c2<y<d2},{c3<y<d3},{c5<y<d5}};交集的交集:已知建立的交集,z∈{y2-x2,y3-x3,y5-x5}且y2-x2=y5-x5=c,其中z表示字符在同一区间的差值的一个集合,x∩y={{a2<x<b2},{a3<x<b3},{a5<x<b5}}∩{z∈{y2-x2,y5-x5}},x∈{a<x<b}∩y∈{c<y<d}∩{b-a=c};差集1:已知建立的交集,则{x1∈{a1<x1<b1},x2∈{a2<x2<b2},x3∈{a3<x3<b3},······,xn∈{an<xn<bn}}-x∩y={{a2<x2<b2},{a3<x3<b3},{a5<x5<b5}}={x1∈{a1<x1<b1},x4∈{a4<x4<b4},x6∈{a6<x6<b6},······,xn∈{an<xn<bn}};差集2:已知建立的交集,则{y1∈{c1<y1<d1},y2∈{c2<y2<d2},x3∈{c3<y3<d3},······,yn∈{cn<yn<dn}}-x∩y={{c2<y2<d2},{a3<y3<d3},{c5<y5<d5}}={y1∈{c1<y1<d1},y4∈{c4<y4<d4},y6∈{c6<y6<d6},······,yn∈{cn<yn<dn}};4)对输入的文本串提取其中所包含的逻辑关系:由步骤2)、3)知:x∧y,表示在同一个句子内既有x又有y;表示在同一个句子内有x无y;表示在同一个句子内有y无x;yi-xi=p,表示在同一个句子内y与x之间的差值为一个常数p;yi-xi>p,表示在同一个句子内y与x之间的差值大于一个常数p;yi-xi<p,表示在同一个句子内y与x之间的差值小于一个常数p;bi-ai=q,表示一个句子长度等于一个常数q;bi-ai>q,表示一个句子长度大于一个常数q;bi-ai<q,表示一个句子长度小于一个常数q;5)对其中的规则进行组合:表示在同一句话内既有x又有y而没有z;(yi-xi)=p∧(bi-ai)=q,表示在同一个句子内y与x之间的差值为p,句子长度为q;(yi-xi)=p∧(bi-ai)>q,表示在同一个句子内,y与x之间的差值为p,句子长度大于q;(yi-xi)=p∧(bi-ai)<q,表示在同一个句子内,y与x之间的差值为p,句子长度小于q;(yi-xi)>p∧(bi-ai)=q,表示在同一个句子内,y与x之间的差值大于p,句子长度为q;(yi-xi)>p∧(bi-ai)>q,表示在同一个句子内,y与x之间的差值大于p,句子长度大于q;(yi-xi)>p∧(bi-ai)<q,表示在同一个句子内,y与x之间的差值大于p,句子长度小于q;(yi-xi)<p∧(bi-ai)=q,表示在同一个句子内,y与x之间的差值小于p,句子长度为q;(yi-xi)<p∧(bi-ai)>q,表示在同一个句子内,y与x之间的差值小于p,句子长度大于q;(yi-xi)<p∧(bi-ai)<q,表示在同一个句子内,y与x之间的差值小于p,句子长度小于q;6)结果显示输出:根据步骤4)提取出所具有的逻辑关系,根据步骤5)对逻辑关系进行组合,根据步骤1),在索引表中进行查询,把查询结果进行显示。本发明的有益效果是:本发明专利针对古文献的检索问题,提出了一种高效、合理的计算方法,不仅实现了一种针对中国古文献检索的问题,且能够自动的统计一些信息,通过对逻辑关系定义一些规则,并把这些规则进行组合,为知识发现奠定了基础。附图说明图1是本发明专利构建索引系统的流程图;图2是本发明专利中的总体流程图。具体实施方式下面结合附图和具体实施方式,对本发明做进一步的说明。实施例1:如图1、2所示,一种基于索引关系的古文献统一逻辑检索方法,包括下述步骤:1)构建索引系统:读取文本;建立第一索引表,第一索引表包括文档编号及该文档编号对应的文档名称;建立第二索引表,第二索引表包括所有文档中不同的字符及该字符出现在哪些文档中;建立第三索引表,第三索引表包括每个文档中的所有不同的字符及该字符的位置;把第一索引表、第二索引表、第三索引表写入索引文件中进行保存;2)统计固定句长的句子出现的次数:读取第三索引表;因句号、问号、感叹号表示句末的停顿,通过读取第三索引表,能够得到每个文档中句号、问号、感叹号的索引信息,分别记为a、b、c,其中a、b、c中的对应关系为:a[a1,a2,a3······an]、b[b1,b2,b3······bn]、c[c1,c2,c3······cn],α:a1<a2<a3<······<an、b:b1<b2<b3<······<bn、c:c1<c2<c3<······<cn且(a1···an)、(b1···bn)、(c1···cn)互不相等(即:这些字母代表的数值都是不相等的),a、b、c分别代表着标点符号句号、问号、感叹号,a1-an表示句号在第三索引中出现的位置,b1-bn表示问号在第三索引表中出现的位置,c1-cn表示感叹号在第三索引表中出现的位置;将已经排好序的a、b、c进行合并,定义d、e集合:首先对a、b进行合并,每个序列都维护一个位置指针,并让两个指针同时在两个列表中后移,分别取两个序列的开头a1与b1进行比较,如果a1<b1,则d[a1,b1],指针分别向后移动一位,取a2与b2进行比较,如果b2<a2,则d[a1,b1,b2],将小的那个数组所对应的指针后移一位即b3与a2进行对比,按照从小到大的顺序进行排序,直到a、b两个序列中的数都取完,再将序列c中的数与序列d中的数,按照上述原则进行再次比较,存入集合e中,这样将a、b、c合并为一个按照大小顺序排列的集合e;集合e[e1,e2,e3······en]其中e:e1<e2<e3<······<en,定义集合f,f为:f[e2-e1,e3-e2,e4-e3,······,en-e(n-1)];统计集合f中相同数值出现的次数;3)对逻辑关系建立相对应规则:建立交集,对于字符x及字符y,其中x的区间集合:{x1∈{a1<x1<b1},x2∈{a2<x2<b2},x3∈{a3<x3<b3},······,xn∈{an<xn<bn}}其中y的区间集合:{y1∈{c1<y1<d1},y2∈{c2<y2<d2},y3∈{c3<y3<d3},······,yn∈{cn<yn<dn}}设a2=c2,b2=d2;a3=c3,b3=d3;a5=c5,b5=d5则x∩y={{a2<x<b2},{a3<x<b3},{a5<x<b5}}或者x∩y={{c2<y<d2},{c3<y<d3},{c5<y<d5}};交集的交集:已知建立的交集,z∈{y2-x2,y3-x3,y5-x5}且y2-x2=y5-x5=c,其中z表示字符在同一区间的差值的一个集合,x∩y={{a2<x<b2},{a3<x<b3},{a5<x<b5}}∩{z∈{y2-x2,y5-x5}},x∈{a<x<b}∩y∈{c<y<d}∩{b-a=c};差集1:已知建立的交集,则{x1∈{a1<x1<b1},x2∈{a2<x2<b2},x3∈{a3<x3<b3},······,xn∈{an<xn<bn}}-x∩y={{a2<x2<b2},{a3<x3<b3},{a5<x5<b5}}={x1∈{a1<x1<b1},x4∈{a4<x4<b4},x6∈{a6<x6<b6},······,xn∈{an<xn<bn}};差集2:已知建立的交集,则{y1∈{c1<y1<d1},y2∈{c2<y2<d2},x3∈{c3<y3<d3},······,yn∈{cn<yn<dn}}-x∩y={{c2<y2<d2},{a3<y3<d3},{c5<y5<d5}}={y1∈{c1<y1<d1},y4∈{c4<y4<d4},y6∈{c6<y6<d6},······,yn∈{cn<yn<dn}};4)对输入的文本串提取其中所包含的逻辑关系:由步骤2)、3)知:x∧y,表示在同一个句子内既有x又有y;表示在同一个句子内有x无y;表示在同一个句子内有y无x;yi-xi=p,表示在同一个句子内y与x之间的差值为一个常数p;yi-xi>p,表示在同一个句子内y与x之间的差值大于一个常数p;yi-xi<p,表示在同一个句子内y与x之间的差值小于一个常数p;bi-ai=q,表示一个句子长度等于一个常数q;bi-ai>q,表示一个句子长度大于一个常数q;bi-ai<q,表示一个句子长度小于一个常数q;5)对其中的规则进行组合:表示在同一句话内既有x又有y而没有z;(yi-xi)=p∧(bi-ai)=q,表示在同一个句子内y与x之间的差值为p,句子长度为q;(yi-xi)=p∧(bi-ai)>q,表示在同一个句子内,y与x之间的差值为p,句子长度大于q;(yi-xi)=p∧(bi-ai)<q,表示在同一个句子内,y与x之间的差值为p,句子长度小于q;(yi-xi)>p∧(bi-ai)=q,表示在同一个句子内,y与x之间的差值大于p,句子长度为q;(yi-xi)>p∧(bi-ai)>q,表示在同一个句子内,y与x之间的差值大于p,句子长度大于q;(yi-xi)>p∧(bi-ai)<q,表示在同一个句子内,y与x之间的差值大于p,句子长度小于q;(yi-xi)<p∧(bi-ai)=q,表示在同一个句子内,y与x之间的差值小于p,句子长度为q;(yi-xi)<p∧(bi-ai)>q,表示在同一个句子内,y与x之间的差值小于p,句子长度大于q;(yi-xi)<p∧(bi-ai)<q,表示在同一个句子内,y与x之间的差值小于p,句子长度小于q;6)结果显示输出:根据步骤4)提取出所具有的逻辑关系,根据步骤5)对逻辑关系进行组合,根据步骤1),在索引表中进行查询,把查询结果进行显示。举例说明:如图1所示,以四大名著为例,构建索引系统,读取文本,建立第一索引表,第一索引表包括文档编号及该文档编号对应的文档名称;第一索引表如表1:表1:文档编号文档名称docid_0三国演义.txtdocid_1水浒传.txtdocid_2红楼梦.txtdocid_3西游记.txt…….……针对上述第一索引表信息,采用实施例1中的方法建立第二索引表,第二索引表包括所有文档中不同的字及该字出现在那些文档中,还能统计该字出现了多少次;取其中的一部分字,第二索引表如表2:表2:针对上述第二索引表,采用实施例1中的方法建立第三索引表,第三索引表包括该针对红楼梦文档中的所有不同的字符及该字符的位置,第三索引表如表3所示:表3:采用实施例1中的方法统计固定句长的句子出现的次数,通过读取索引表三获取句号、问号、感叹号的索引信息,如表4:表4:采用实施例1中的方法把标点符号的位置按照大小顺序进行排序,总共有34390位置,将位置进行排序,得到表5:表5:采用实施例1中的方法统计句子的长度,如表6所示:表6:采用实施例1中的方法统计固定句子长度出现的次数,如表7所示:表7:采用实施例1中的方法对逻辑关系建立相对应的规则,建立交集,交集的交集,差集1,差集2,字符“因为”的区间集合为表8所示,字符“所以”区间集合为表9所示,在同一个句子内既有字符“因为”又有字符“所以”的区间集合为表10所示:表8:区间“因为”位置[122314,122338][122317][123276,123335][123307][253308,253339][253331][255769,255802][255784]…………[91142,91171][91158]表9区间“所以”位置[101437,101480][101471][108878,108926][108918][111389,111416][111372][255769,255802][255794]…………[99754,99836][99829]表10交集区间“因为”位置“所以”位置[255769,255802][255784][255794][398953,399003][398956][398996][459956,460018][459964][459988][515751,515794][515755][515780][66039,66085][66001][66028][749675,749746][749685][749697][91142,91171][91158][91166]采用实施例1中的,对输入的文本串提取其中所包含的逻辑关系,如表11所示:表11:采用实施例1中的,对其中的规则进行组合,如表12:表12:采用实施例1中,对查询的结果进行显示输出,根据表13,把查询符合结果的进行显示。表13:结合表13,把输入的字符串拆分成符合规则的子串,最后把满足条件的结果进行显示输出。以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1