一种数据分割方法与流程
本发明涉及通信技术领域,尤其涉及一种数据分割方法。
背景技术:
在交易系统中,每一笔的交易都会形成一交易记录,每个交易记录中均包含多个交易属性的数据,交易记录最终会形成一存储文件,为了方便管理者对存储文件中的每一交易记录进行查看保存,需要将存储文件中的交易记录等相关数据保存于一存储服务器中,现有的将存储文件保存于存储服务器中的做法通常是加载一完整的存储文件,进而对存储文件中交易记录逐个进行写入保存,这样操作会使存储服务器占用较大的内存,严重影响存储服务器的性能,更有甚者由于存储文件过大,会导致存储服务器出现死机等问题。
技术实现要素:
针对现有技术中存储服务器保存存储文件中的数据存在的上述问题,现提供一种旨在实现较少占用存储服务器的内存,将带待存储文件中的数据进行存储的数据分割方法。
具体技术方案如下:
一种数据分割方法,应用于存储服务器中,所述存储服务器用以对待存储文件中的数据进行存储,其特征在于,所述数据分割方法具体包括以下步骤:
步骤s1、判断所述待存储文件是否满足一预设分割条件;
若是,执行步骤s2;
若否,直接对所述待存储文件中的数据进行保存并退出;
步骤s2、按照一预设的分割规则对所述待存储文件进行分割以形成多个处理子文件,并对应生成每个所述处理子文件的分割状态信息;
步骤s3、根据所有的所述处理子文件对应的所述分割状态信息,判断所有的所述处理子文件是否均分割失败;
若是,返回所述步骤s1;
若否,执行步骤s4;
步骤s4,在分割成功的所有所述处理子文件中,以n个所述处理子文件为一处理周期,依次将所述处理文件中的数据进行保存。
优选的,所述预设分割规则为按照一预设大小对所述存储文件进行分割以形成大小相等的所述处理子文件。
优选的,所述预设分割规则为按照一预设行数对所述存储文件进行分割以形成行数相等的所述处理子文件。
优选的,所述步骤s2中,每个所述处理子文件的所述分割状态信息包括,文件名、分割成功或者分割失败对应的标识、数据起止行数。
优选的,所述存储服务器提供一数据库,所述数据库用以保存每个所述处理子文件的所述分割状态信息。
优选的,所述步骤s4中执行完成后还包括:
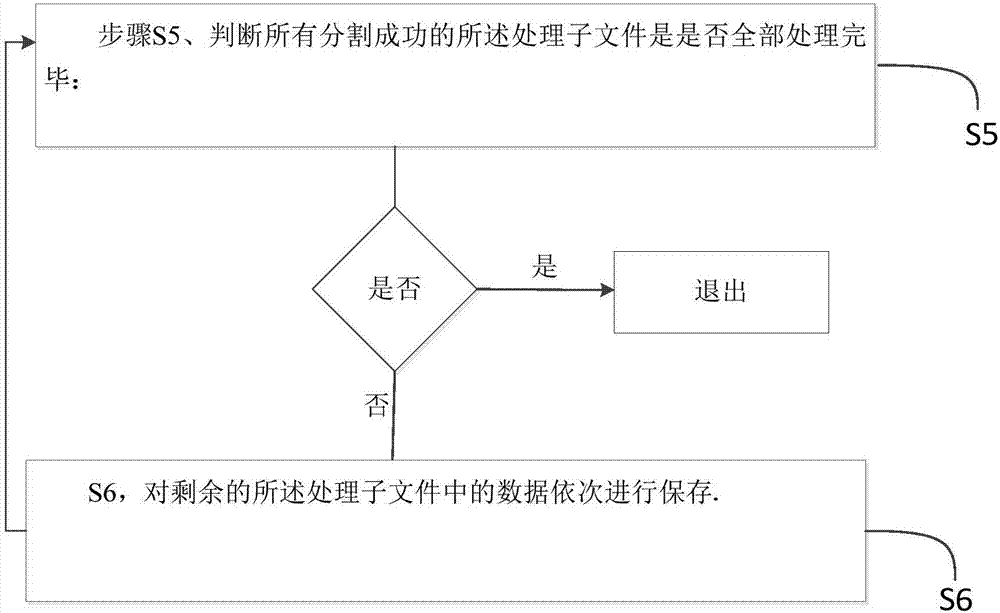
步骤s5、判断所有分割成功的所述处理子文件是是否全部处理完毕:
如是,退出;
如否,执行步骤s6;
s6,对剩余的所述处理子文件中的数据依次进行保存,并返回步骤s5。
优选的,提供一监听程序,所述监听程序用以判断每一个所述处理周期执行的时间是否超过一第三预设阈值;
并在超过所述第三预设阈值时退出结束对当前的所述处理子文件的数据的保存。
优选的,所述n为3或4或5。
优选的,所述步骤s4中,对所述处理子文件中的数据进行保存的方法包括:
步骤a,对所述处理子文件进行解析,以获取解析出的数据;
步骤b,将当前的所述处理子文件中解析出的数据,保存至所述数据库中;
步骤c,在当前的所述处理子文件中的所有数据保存完成后,形成一录入状态标识并保存于所述数据库中,所述录入状态表示当前的所述处理子文件中的所有数据保存完整。
在一种较优的实施方式中,所述待存储文件为excel格式的文件。
上述技术方案具有如下优点或有益效果:可对待存储文件进行分割进行形成处理子文件,存储服务器可将分割成功的所有处理子文件中,以n个所述处理子文件为一处理周期,依次将处理文件中的数据进行保存,克服了现有技术中将整个存储文件中的数据进行保存带来的存储服务器内存占用较大,影响存储服务器性能,更有甚者由于存储文件过大,会导致存储服务器出现死机等缺陷。
附图说明
参考所附附图,以更加充分的描述本发明的实施例。然而,所附附图仅用于说明和阐述,并不构成对本发明范围的限制。
图1为本发明一种数据分割方法的实施例的流程图;
图2为本发明一种数据分割方法的实施例中,关于判断处理子文件是否处理完毕的方法的流程图;
图3为本发明一种数据分割方法的实施例中,关于对处理子文件中的数据进行保存的方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
本发明的技术方案中包括一种数据分割方法。
一种数据分割方法的实施例,应用于存储服务器中,所述存储服务器用以对待存储文件中的数据进行存储,其中,如图1所示,数据分割方法具体包括以下步骤:
步骤s1、判断待存储文件是否满足一预设分割条件;
若是,执行步骤s2;
若否,直接对所述待存储文件中的数据进行保存并退出;
步骤s2、按照一预设的分割规则对待处理文件进行分割以形成多个处理子文件,并对应生成每个处理子文件的分割状态信息;
步骤s3、根据所有的处理子文件对应的分割状态信息,判断所有的处理子文件是否均分割失败;
若是,返回步骤s1;
若否,执行步骤s4;
步骤s4,在分割成功的所有处理子文件中,以n个处理子文件为一处理周期,依次将处理文件中的数据进行保存。
针对现有技术中,对存储文件中的交易记录的数据进行存储时,不管存储文件的大小,对整个存储文件进行逐个处理保存,进而带来存储服务器内存占用过大,严重影响存储服务器性能的缺陷。
本发明中通过用户将上传并保存在存储服务器中目录下的待存储文件进行判断,其可通过存储服务器启用一文件处理主线程,通过文件处理主线程判断待存储文件是否满足预设分割条件,若不满足分割条件,则表示当前的待存储文件并不大,可直接对待存储文件中的数据进行保存操作;在满足预设分割条件后,开启文件分割线程按照预设分割规则对待存储文件进行分割以形成多个处理子文件,在分割的处理过程中,对分割的每个处理子文件对应形成一分割状态信息,其中不管处理子文件是否分割成功,每个处理子文件的分割状态信息都会保存对应的分割状态信息,当所有的处理子文件都分割失败则重新启动文件处理主线程重新执行上述处理,对于分割成功的处理子文件开启子文件处理线程,将所有的分割成功的处理子文件并行输出,启动m个文件处理入库线程,对应处理n个处理子文件,其中m=n,每个文件处理入库线程以n个处理子文件为一处理周期,依次将处理文件中的数据进行保存。
在一种较优的实施方式中,预设分割规则为按照一预设大小对存储文件进行分割以形成大小相等的处理子文件。
上述技术方案中,当存储文件中的列数较少,即表示每一行的数据的属性较少,此时可通过一预设大小对存储文件进行分割,需要说明的是预设大小可根据使用者的自定义设置,使用者具体可根据待存储文件进行设置。
在一种较优的实施方式中,预设分割规则为按照一预设行数对存储文件进行分割以形成行数相等的处理子文件。
上述技术方案中,当存储文件中的列数较多,则表示每一行数据的属性较多,每一行的数据较大,此时可通过一预设行数对存储文件进行分割,预设行数可根据使用者的自行定义。
在一种较优的实施方式中,步骤s2中,每个处理子文件的分割状态信息包括,文件名、分割成功或者分割失败对应的标识、数据起止行数。
上述技术方案中,分割状态信息还包括每个处理子文件对应的存储路径,其中起止行数,标识分割的处理子文件是从哪一行开始,到多少行结束,还可包括处理子文件的大小,为了避免文件分割出现数据重复和丢失对处理子文件中的数据可采用对应的行号作为唯一身份标识。
在一种较优的实施方式中,存储服务器提供一数据库,数据库用以保存每个处理子文件的分割状态信息。
上述技术方案中,对待存储文件进行分割时,不管处理子文件是否分割成功,每个处理子文件的分割状态信息都会保存于数据库中。
在一种较优的实施方式中,如图2所示,步骤s4中执行完成后还包括:
步骤s5、判断所有分割成功的处理子文件是是否全部处理完毕:
如是,退出;
如否,执行步骤s6;
s6,对剩余的处理子文件中的数据依次进行保存,并返回步骤s5。
上述技术方案中,通过对分割完成的处理子文件进行实时判断其是否处理完毕,可以有效避免遗漏对处理子文件的处理。
在一种较优的实施方式中,提供一监听程序,监听程序用以判断每一个处理周期执行的时间是否超过一第三预设阈值;
并在超过第三预设阈值时退出结束对当前的处理子文件的数据的保存。
上述技术方案中,第三预设阈值可根据实际的运行状态进行配置。
在一种较优的实施方式中,n为3或4或5。
上述技术方案中,文件入库线程可开启3到5个,因此在每一处理周期内可对应处理3-5个处理子文件。
在一种较优的实施方式中,如图3所示,步骤s4中,对处理子文件中的数据进行保存的方法包括:
步骤a,对处理子文件进行解析,以获取解析出的数据;
步骤b,将当前的处理子文件中解析出的数据,保存至数据库中;
步骤c,在当前的处理子文件中的所有数据保存完成后,形成一录入状态标识并保存于数据库中,录入状态用以表示当前的处理子文件中的所有数据保存完整。
在一种较优的实施方式中,所述待存储文件为excel格式的文件。
上述技术方案中,可采用poi用户模式解析处理子文件,以获取处理子文件中的数据,在待存储文件为excel格式的文件的实施例下,将解析的数据如每一行中的数据写入数据库中,并在当前的处理子文件中的所有数据保存完成后形成一录入状态标识,以表示当前的处理子文件中的数据保存完成,进一步的可以对下一处理子文件进行解析。
以上所述仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!