一种半结构化数据查询的方法和分布式NewSQL数据库系统与流程
本发明涉及大数据技术领域,尤其涉及一种半结构化数据查询的方法和分布式newsql数据库系统。
背景技术:
目前hbase单元是hadoop生态体系中最著名的分布式nosql数据库之一。hbase单元主要组件包括hmaster和hregionsever,为用户提供表格类型的数据模型,按主键范围划分为多个region,hmaster负责管理和分配region,hregionserver负责region数据的读写。现有的hbase单元存储的数据没有数据类型之分,均为byte数组,因此如若要存储json这种半结构化数据即在查询方面会存在一些问题。在hbase单元要存储json格式数据,则常规会将整个json对象当作字符串存储。该方式存在如下缺陷:
要过滤记录的时候,需要将所有的记录都读取出来然后在客户端进行过滤,在数据量较大的情况下该性能不能被接受。
要更新记录的时候,需要将记录读取出来再针对具体的字段进行更新后重写入到hbase单元进行覆盖。
技术实现要素:
本发明实施例的目的是提供一种半结构化数据查询的方法和分布式newsql数据库系统,能实现json格式的数据查询,解决处理半结构化数据时效果以及性能不佳的问题。
为实现上述目的,本发明实施例提供了一种半结构化数据查询的方法,适用于分布式newsql数据库系统,包括:
以jdcb/odbc的接口方式接入用户请求,其中,所述用户请求包括需要查询的json数据的查询条件,所述查询结果为根据所述查询条件所获得的json数据;
解析所述用户请求,编译以及生成对应的执行计划;
根据执行计划,获取与所述用户请求的所述查询条件相对应的索引数据;其中,所述索引表中已储存由所述json数据作为一个嵌套的类型所生成的倒排索引形式的索引数据;
根据获取的所述索引数据查询数据表,从而获得对应的所述查询结果;其中,所述json数据作为整体进行存储;
返回所述查询结果给用户。
进一步的,所述解析所述用户请求,编译以及生成对应的执行计划包括:
判断共享缓存池中是否存在与所述sql请求相对应的预存sql语句,若是,则输出相对应的所述预存sql语句对应的执行计划,若否,则,
对所述sql请求进行语法检查,若语法错误返回错误信息给用户,否则,
对所述sql请求进行语义检查,若语义错误返回错误信息给用户,否则,
对所述sql请求进行视图以及表达式转换,获得对应的转化结果;
根据所述转换结果选择优化器,获得对应的优化器选择结果;
根据所述优化器选择结果选择对应的数据连接方式以及连接顺序;
根据连接方式和连接顺序选择搜索的路径;
根据搜索路径生成执行计划,并输出执行计划。
相应,本发明实施例还提供一种分布式newsql数据库系统,包括:
jdcb/odbc接口单元,用于与用户进行交互操作,包括接收用户请求,返回查询结果给用户;其中,所述用户请求包括需要查询的json数据的查询条件,所述查询结果为根据所述查询条件所获得的json数据;
master单元,用于接入jdcb/odbc接口单元所接入的用户请求,并协调多个处理器之间的数据通讯以及管理整体流程,并将所述用户请求优先发送给sqlplaner单元;master单元还用于所述查询结果返回jdcb/odbc接口单元;
sqlplaner单元,用于解析所述用户请求,根据所述用户请求编译以及定制执行计划;
worker单元,用于并行地执行所述计划,包括:根据执行计划,启动coprocessor模块获取与所述用户请求的所述查询条件相对应的索引数据,并,根据获取的所述索引数据查询数据表,从而获得对应的所述查询结果;还用于将所述hbase单元的查询结果返回至所述master单元;
hbase单元,用于储存所述数据表和索引表;所述hbase单元还包括所述coprocessor模块,其中,hbase单元的底层增加json类型数据,所述json数据整体存储在底层hfile中;
分布式事务管理器,用于当所述worker单元执行计划涉及事务时,协调多方完成分布式事务管理。
进一步的,jdcb/odbc接口单元还用于将所述用户请求转化sql语句形式的sql请求。
进一步的,所述sqlplaner单元用于:
判断共享缓存池中是否存在与所述sql请求相对应的预存sql语句,若是,则输出相对应的所述预存sql语句对应的执行计划,若否,则,
对所述sql请求进行语法检查,若语法错误返回错误信息给用户,否则,
对所述sql请求进行语义检查,若语义错误返回错误信息给用户,否则,
对所述sql请求进行视图以及表达式转换,获得对应的转化结果;
根据所述转换结果选择优化器,获得对应的优化器选择结果;
根据所述优化器选择结果选择对应的数据连接方式以及连接顺序;
根据连接方式和连接顺序选择搜索的路径;
根据搜索路径生成执行计划,并输出执行计划。
进一步的,还包括:
监视器,用于负责元数据管理,监控所述hbase单元的region的负载,以及通过所述hbase单元的coprocessor模块重新分配region;所述监视器与所述master单元连接。
进一步的,所述监控所述hbase单元的region的负载,以及通过所述hbase单元的coprocessor模块重新分配region包括:
接收所述hbase单元的数据分布信息,接收所述master单元中的所述worker单元的负载信息,其中,所述负载信息包括所述worker单元的负载偏差值;
将所述worker单元的负载偏差值与预设负载偏差阈值进行比较,若判定所述负载偏差值超过阀值,触发所述hbase单元将命中率较高服务器上的region和命中率较低服务器上的region进行从新分配;
获取每一region的数据量,将每一所述region的数据量与预设数据量阈值进行判断,若判定所述region的数据量超过阀值,触发所述hbase单元将超过预设数据量阈值的所述region切分成两个。
进一步的,所述jdcb/odbc接口单元包括:
jdbc应用程序模块,用于接收用户请求,以及调用jdbc对象方法以给出sql语句,并用于提取结果返回用户;
jdbc驱动程序管理器模块,用于为所述jdbc应用程序模块加载和调用jdbc驱动程序模块;
jdbc驱动程序模块,用于执行所述jdbc对象方法的调用,发送用户请求所对应的sql语句给底层的数据库,并将从所述底层的数据库获得的结果返回给jdbc应用程序模块。
与现有技术相比,本发明提供的一种半结构化数据查询的方法和分布式newsql数据库系统,通过首先以jdcb/odbc的接口方式接入用户请求,其中,所述用户请求包括需要查询的json数据的查询条件,所述查询结果为根据所述查询条件所获得的json数据;解析所述用户请求,编译以及生成对应的执行计划;根据执行计划,获取与所述用户请求的所述查询条件相对应的索引数据;其中,所述索引表中已储存由所述json数据作为一个嵌套的类型所生成的倒排索引形式的索引数据;根据获取的所述索引数据查询数据表,从而获得对应的所述查询结果;其中,所述json数据作为整体进行存储;返回所述查询结果给用户的技术方案,能实现json格式的数据查询,解决处理半结构化数据时效果以及性能不佳的问题。
附图说明
图1是本发明实施例1提供的一种半结构化数据查询的方法的流程示意图;
图2是本发明实施例2提供的一种分布式newsql数据库的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参见图1,图1是本发明实施例1提供的一种半结构化数据查询的方法的流程示意图;适用于分布式newsql数据库系统,实施例1包括步骤:
s1、以jdcb/odbc的接口方式接入用户请求,其中,所述用户请求包括需要查询的json数据的查询条件,所述查询结果为根据所述查询条件所获得的json数据;
s2、解析所述用户请求,编译以及生成对应的执行计划;
s3、根据执行计划,获取与所述用户请求的所述查询条件相对应的索引数据;其中,所述索引表中已储存由所述json数据作为一个嵌套的类型所生成的倒排索引形式的索引数据;
s4、根据获取的所述索引数据查询数据表,从而获得对应的所述查询结果;其中,所述json数据作为整体进行存储;
s5、返回所述查询结果给用户。
现有技术中hbase存储的数据没有数据类型之分,均为byte数组,因此如若要存储json这种半结构化数据即在查询方面会存在一些问题。在hbase要存储json格式数据,则常规会将整个json对象当作字符串存储。该方式存在如下缺陷:要过滤记录的时候,需要将所有的记录都读取出来然后在客户端进行过滤,在数据量较大的情况下该性能不能被接受。要更新记录的时候,需要将记录读取出来再针对具体的字段进行更新后重写入到hbase进行覆盖。特别是针对半结构化的数据,本实施例可以支持半结构化数据,用户可以直接存储json格式的数据,并对json的任意字段进行查询,创建索引以及删改。解决现有技术中hbase处理半结构化数据时效果以及性能不佳的问题。
进一步的,步骤s1还包括:将所述用户请求转化sql语句形式的sql请求。
进一步的,步骤s2所述解析所述用户请求,编译以及生成对应的执行计划包括:
s21、判断共享缓存池中是否存在与所述sql请求相对应的预存sql语句,若是,则输出相对应的所述预存sql语句对应的执行计划,若否,则,
s22、对所述sql请求进行语法检查,若语法错误返回错误信息给用户,否则,
s23、对所述sql请求进行语义检查,若语义错误返回错误信息给用户,否则,
s24、对所述sql请求进行视图以及表达式转换,获得对应的转化结果;
s25、根据所述转换结果选择优化器,获得对应的优化器选择结果;
s26、根据所述优化器选择结果选择对应的数据连接方式以及连接顺序;
s27、根据连接方式和连接顺序选择搜索的路径;
s28、根据搜索路径生成执行计划,并输出执行计划。
具体实施时,首先以jdcb/odbc的接口方式接入用户请求,接着,解析所述用户请求,编译以及生成对应的执行计划;然后,根据执行计划,获取与所述用户请求的所述查询条件相对应的索引数据;其中,所述索引表中已储存由所述json数据作为一个嵌套的类型所生成的倒排索引形式的索引数据;并,根据获取的所述索引数据查询数据表,从而获得对应的所述查询结果;其中,所述json数据作为整体进行存储;最后,返回所述查询结果给用户。
本实施例能实现json格式的数据查询,解决处理半结构化数据时效果以及性能不佳的问题。
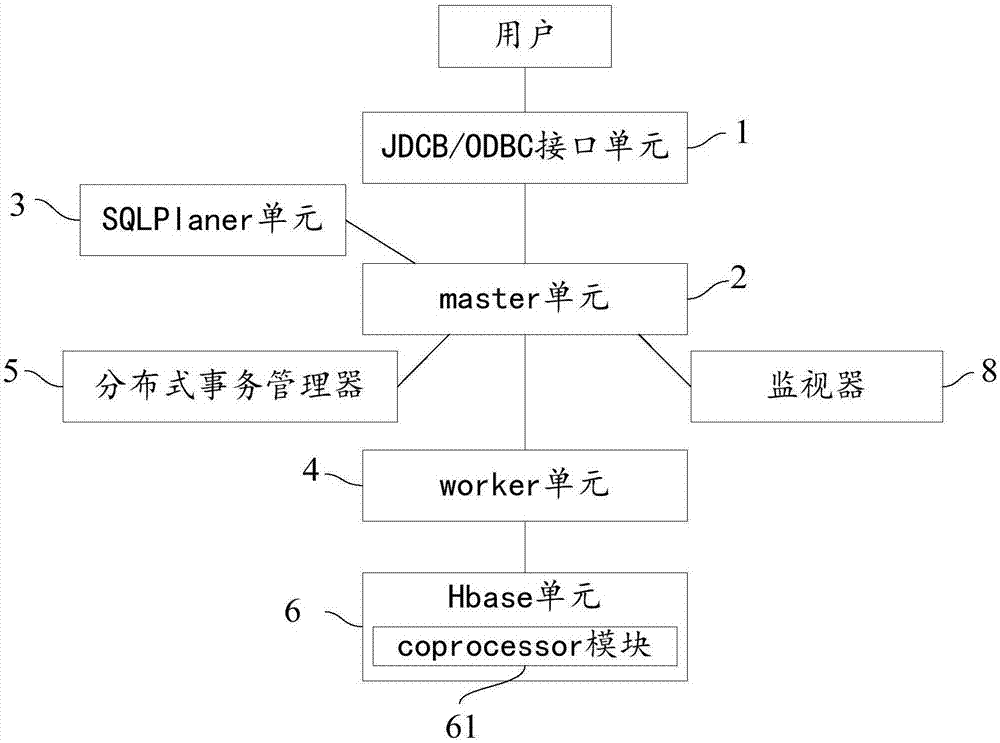
参见图2,图2是本发明实施例2还提供的一种分布式newsql数据库系统的结构示意图,本实施例包括:
jdcb/odbc接口单元1,用于与用户进行交互操作,包括接收用户请求,返回查询结果给用户;其中,所述用户请求包括需要查询的json数据的查询条件,所述查询结果为根据所述查询条件所获得的json数据;
master单元2,用于接入jdcb/odbc接口单元1所接入的用户请求,并协调多个处理器之间的数据通讯以及管理整体流程,并将所述用户请求优先发送给sqlplaner单元3;master单元2还用于所述查询结果返回jdcb/odbc接口单元;
sqlplaner单元3,用于解析所述用户请求,根据所述用户请求编译以及定制执行计划;
worker单元4,用于并行地执行所述计划,包括:根据执行计划,启动coprocessor模块获取与所述用户请求的所述查询条件相对应的索引数据,并,根据获取的所述索引数据查询数据表,从而获得对应的所述查询结果;还用于将所述hbase单元的查询结果返回至所述master单元2;
hbase单元6,用于储存所述数据表和索引表;所述hbase单元6还包括所述coprocessor模块61,其中,hbase单元6的底层增加json类型数据,所述json数据整体存储在底层hfile中;
通常,本实施例的分布式newsql数据库系统允许用户根据具体的业务逻辑灵活的建立二级索引,在实际应用中用户往往会建立多个二级索引,在使用时根据查询条件动态计算使用索引的代价,自动选择最合适的索引。针对rowkey的查询极为高效,因此二级索引的实现方式为利用hbase单元6的coprocessor模块61和filter模块62生成针对数据的索引表。
分布式事务管理器5,用于当所述worker单元4执行计划涉及事务时,协调多方完成分布式事务管理。
进一步的,jdcb/odbc接口单元1还用于将所述用户请求转化sql语句形式的sql请求。
进一步的,所述sqlplaner单元3用于:
判断共享缓存池中是否存在与所述sql请求相对应的预存sql语句,若是,则输出相对应的所述预存sql语句对应的执行计划,若否,则,
对所述sql请求进行语法检查,若语法错误返回错误信息给用户,否则,
对所述sql请求进行语义检查,若语义错误返回错误信息给用户,否则,
对所述sql请求进行视图以及表达式转换,获得对应的转化结果;
根据所述转换结果选择优化器,获得对应的优化器选择结果;
根据所述优化器选择结果选择对应的数据连接方式以及连接顺序;
根据连接方式和连接顺序选择搜索的路径;
根据搜索路径生成执行计划,并输出执行计划。
进一步的,本实施例还包括:
监视器8,用于负责元数据管理,监控所述hbase单元的region的负载,以及通过所述hbase单元6的coprocessor模块61重新分配region;所述监视器与所述master单元连接。
进一步的,所述监控所述hbase单元6的region的负载,以及通过所述hbase单元6的coprocessor模块重新分配region包括:
接收所述hbase单元6的数据分布信息,接收所述master单元2中的所述worker单元4的负载信息,其中,所述负载信息包括所述worker单元4的负载偏差值;
将所述worker单元4的负载偏差值与预设负载偏差阈值进行比较,若判定所述负载偏差值超过阀值,触发所述hbase单元6将命中率较高服务器上的region和命中率较低服务器上的region进行从新分配;
获取每一region的数据量,将每一所述region的数据量与预设数据量阈值进行判断,若判定所述region的数据量超过阀值,触发所述hbase单元6将超过预设数据量阈值的所述region切分成两个。
进一步的,所述jdcb/odbc接口单元1包括:
jdbc应用程序模块11,用于接收用户请求,以及调用jdbc对象方法以给出sql语句,并用于提取结果返回用户;
jdbc驱动程序管理器模块12,用于为所述jdbc应用程序模块11加载和调用jdbc驱动程序模块13;
jdbc驱动程序模块13,用于执行所述jdbc对象方法的调用,发送用户请求所对应的sql语句给底层的数据库,并将从所述底层的数据库获得的结果返回给jdbc应用程序模块11。
具体实施时,首先,通过jdcb/odbc接口单元1接收用户请求;然后,master单元2接入jdcb/odbc接口单元1所接入的用户请求,并协调多个处理器之间的数据通讯以及管理整体流程,并将所述用户请求优先发送给sqlplaner单元;接着,通过sqlplaner单元3解析所述用户请求,根据所述用户请求编译以及定制执行计划;接着,通过worker单元4并行地执行所述计划,启动hbase单元6的coprocessor模块61获取与所述用户请求的所述查询条件相对应的索引数据,并,根据获取的所述索引数据查询数据表,从而获得对应的所述查询结果;其中,hbase单元6的底层增加json类型数据,所述json数据整体存储在底层hfile中;最后,hbase单元6的查询结果返回至所述master单元,并通过master单元2将json数据已写入的查询结果返回jdcb/odbc接口单元以返回用户。
本实施例的分布式newsql数据库系统能实现json格式的数据查询,解决处理半结构化数据时效果以及性能不佳的问题。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!