基于最小哈希的时间序列相似性查询方法及装置与流程
本发明涉及大数据异常状态检测技术,尤其涉及一种基于最小哈希的时间序列相似性查询方法及装置。
背景技术:
时间序列是指在不同时间点重复测量得到的数值序列,通常测量时间点为等间隔。时间序列出现在多种领域中,如科学计量、财务数据、传感网络、音频、气温等。其中时间序列的相似性查询是时间序列研究领域中的一个热门分支,具体是指给定某个查询序列,从数据集中找出所有与查询序列相似的序列。时间序列相似性查询可用于股市分析、气象预报、心电图分析等多种与我们生活息息相关的领域。现有技术中提出了一种基于集合的时间序列分析法,该方法将时间序列转化为集合,再利用杰拉德(jaccard)系数衡量查询序列与标准序列间的相似性。其中计算杰拉德系数需要遍历查询序列和标准序列所有的集合id,耗费时间较长,影响了算法的整体效率,尤其是将之应用于大规模时间序列中时,庞大的数据量将会进一步使其性能显著恶化。
技术实现要素:
本发明要解决的技术问题在于,针对现有方法计算杰拉德系数需要遍历查询序列和标准序列所有的集合id影响算法整体效率的缺陷,提供了一种基于最小哈希的时间序列相似性查询方法及装置,利用最小哈希的方法进一步对数据进行降维,减少运算数据量,使算法更适用于规模时间序列。
本发明第一方面,提供了一种基于最小哈希的时间序列相似性查询方法,包括以下步骤:
a、根据待测时间序列的数据范围以及预设的分割系数将所述待测时间序列划分到多个集合中,并采用数据点所在的集合编号组成的一维待测序列表示所述待测时间序列;
b、根据标准时间序列的数据范围以及所述分割系数将所述标准时间序列划分到多个集合中,并采用数据点所在的集合编号组成的一维标准序列表示所述标准时间序列;
c、计算所述一维待测序列和一维标准序列的最小哈希值相等的概率作为杰拉德系数。
在根据本发明基于最小哈希的时间序列相似性查询方法中,优选地,所述步骤a包括:
依据预设的分割系数σ和ε将待测时间序列s的数据点划分到m×n个集合中,其中总行数m=(xmax-xmin)/σ,总列数n=(tmax-tmin)/ε,每个集合的大小均为σ×ε,其中tmax和tmin为待测时间序列s的数据范围中时间上限值和下限值,xmax和xmin为待测时间序列s的数据范围中幅值上限值和下限值;
对所述多个集合进行编号,假设待测时间序列s上的数据点p(ti,xi),1≤i≤k,其中k为所述待测时间序列s的数据点总数;则该数据点p(ti,xi)所在集合编号为:ni=(mi-1)×n+ni,其中mi=(xi-xmin)/σ,ni=(ti-tmin)/ε,将待测时间序列s使用一维待测序列s'={n1,n2,…,nk}表示。
在根据本发明基于最小哈希的时间序列相似性查询方法中,优选地,所述步骤c包括:
根据所述一维待测序列s’和一维标准序列q’生成特征矩阵,所述特征矩阵包括三个行向量;其中
第一行向量包括一维待测序列s’和一维标准序列q’的所有元素;
第二行向量包括一维待测序列的标志值,其中当一维待测序列包含第一行向量的元素时,与该元素同列的一维待测序列的标志值置为第一标志值,当不包含第一行向量的元素时,与该元素同列的一维待测序列的标志值置为第二标志值;
第三行向量包括一维标准序列的标志值,其中当一维标准序列包含第一行向量的元素时,与该元素同列的一维标准序列的标志值置为第一标志值,当不包含第一行向量的元素时,与该元素同列的一维标准序列的标志值置为第二标志值;
将特征矩阵的列向量进行随机排列,得到新的特征矩阵;新的特征矩阵中第二行向量和第三行向量中第一个为第一标志值对应的第一行向量的元素分别为一维待测序列的最小哈希值h(s′)和一维标准序列的最小哈希值q(s′);
计算多次所述随机排列得到的多组最小哈希值中h(s′)和q(s′)相等的频率作为杰拉德系数。
在根据本发明基于最小哈希的时间序列相似性查询方法中,优选地,所述步骤c包括:
根据所述一维待测序列s’和一维标准序列q’生成特征矩阵,所述特征矩阵包括三个列向量;其中
第一列向量包括一维待测序列s’和一维标准序列q’的所有元素;
第二列向量包括一维待测序列的标志值,其中当一维待测序列包含第一列向量的元素时,与该元素同行的一维待测序列的标志值置为第一标志值,当不包含第一列向量的元素时,与该元素同行的一维待测序列的标志值置为第二标志值;
第三列向量包括一维标准序列的标志值,其中当一维标准序列包含第一列向量的元素时,与该元素同行的一维标准序列的标志值置为第一标志值,当不包含第一列向量的元素时,与该元素同行的一维标准序列的标志值置为第二标志值;
将特征矩阵的列向量进行随机排列,得到新的特征矩阵;新的特征矩阵中第二列向量和第三列向量中第一个为第一标志值对应的第一列向量的元素分别为一维待测序列的最小哈希值h(s′)和一维标准序列的最小哈希值q(s′);
计算多次所述随机排列得到的多组最小哈希值中h(s′)和q(s′)相等的频率作为杰拉德系数。
在根据本发明基于最小哈希的时间序列相似性查询方法中,优选地,所述第一标志值为1,所述第二标志值为0。
本发明第二方面,提供了一种基于最小哈希的时间序列相似性查询装置,包括:
待测数据分割模块,用于根据待测时间序列的数据范围以及预设的分割系数将所述待测时间序列划分到多个集合中,并采用数据点所在的集合编号组成的一维待测序列表示所述待测时间序列;
标准数据分割模块,用于根据标准时间序列的数据范围以及所述分割系数将所述标准时间序列划分到多个集合中,并采用数据点所在的集合编号组成的一维标准序列表示所述标准时间序列;
相似性计算模块,计算所述一维待测序列和一维标准序列的最小哈希值相等的概率作为杰拉德系数。
在根据本发明基于最小哈希的时间序列相似性查询装置中,优选地,所述待测数据分割模块包括:
数据分割单元,用于依据预设的分割系数σ和ε将待测时间序列s的数据点划分到m×n个集合中,其中总行数m=(xmax-xmin)/σ,总列数n=(tmax-tmin)/ε,每个集合的大小均为σ×ε,其中tmax和tmin为待测时间序列s的数据范围中时间上限值和下限值,xmax和xmin为待测时间序列s的数据范围中幅值上限值和下限值;
数据编号单元,对所述多个集合进行编号,假设待测时间序列s上的数据点p(ti,xi),1≤i≤k,其中k为所述待测时间序列s的数据点总数;则该数据点p(ti,xi)所在集合编号为:ni=(mi-1)×n+ni,其中mi=(xi-xmin)/σ,ni=(ti-tmin)/ε,构建一维待测序列s'={n1,n2,…,nk}。
在根据本发明基于最小哈希的时间序列相似性查询装置中,优选地,所述相似性计算模块包括:
矩阵生成单元,用于根据所述一维待测序列s’和一维标准序列q’生成特征矩阵,所述特征矩阵包括三个行向量;其中
第一行向量包括一维待测序列s’和一维标准序列q’的所有元素;
第二行向量包括一维待测序列的标志值,其中当一维待测序列包含第一行向量的元素时,与该元素同列的一维待测序列的标志值置为第一标志值,当不包含第一行向量的元素时,与该元素同列的一维待测序列的标志值置为第二标志值;
第三行向量包括一维标准序列的标志值,其中当一维标准序列包含第一行向量的元素时,与该元素同列的一维标准序列的标志值置为第一标志值,当不包含第一行向量的元素时,与该元素同列的一维标准序列的标志值置为第二标志值;
矩阵变换单元,用于将特征矩阵的列向量进行随机排列,得到新的特征矩阵;新的特征矩阵中第二行向量和第三行向量中第一个为第一标志值对应的第一行向量的元素分别为一维待测序列的最小哈希值h(s′)和一维标准序列的最小哈希值q(s′);
系数计算单元,用于计算多次所述随机排列得到的多组最小哈希值中h(s′)和q(s′)相等的频率作为杰拉德系数。
在根据本发明基于最小哈希的时间序列相似性查询装置中,优选地,所述相似性计算模块包括:
矩阵生成单元,用于根据所述一维待测序列s’和一维标准序列q’生成特征矩阵,所述特征矩阵包括三个列向量;其中
第一列向量包括一维待测序列s’和一维标准序列q’的所有元素;
第二列向量包括一维待测序列的标志值,其中当一维待测序列包含第一列向量的元素时,与该元素同行的一维待测序列的标志值置为第一标志值,当不包含第一列向量的元素时,与该元素同行的一维待测序列的标志值置为第二标志值;
第三列向量包括一维标准序列的标志值,其中当一维标准序列包含第一列向量的元素时,与该元素同行的一维标准序列的标志值置为第一标志值,当不包含第一列向量的元素时,与该元素同行的一维标准序列的标志值置为第二标志值;
矩阵变换单元,用于将特征矩阵的列向量进行随机排列,得到新的特征矩阵;新的特征矩阵中第二列向量和第三列向量中第一个为第一标志值对应的第一列向量的元素分别为一维待测序列的最小哈希值h(s′)和一维标准序列的最小哈希值q(s′);
系数计算单元,用于计算多次所述随机排列得到的多组最小哈希值中h(s′)和q(s′)相等的频率作为杰拉德系数。
在根据本发明基于最小哈希的时间序列相似性查询装置中,优选地,所述第一标志值为1,所述第二标志值为0。
实施本发明的基于最小哈希的时间序列相似性查询方法及装置,具有以下有益效果:本发明提出的方法将最小哈希运算应用于基于集合的时间序列相似性查询当中,进一步减小了运算量,使这种基于集合的时间序列相似性查询算法更适用于大规模时间序列中。
附图说明
图1为根据本发明优选实施例的基于最小哈希的时间序列相似性查询方法的流程图;
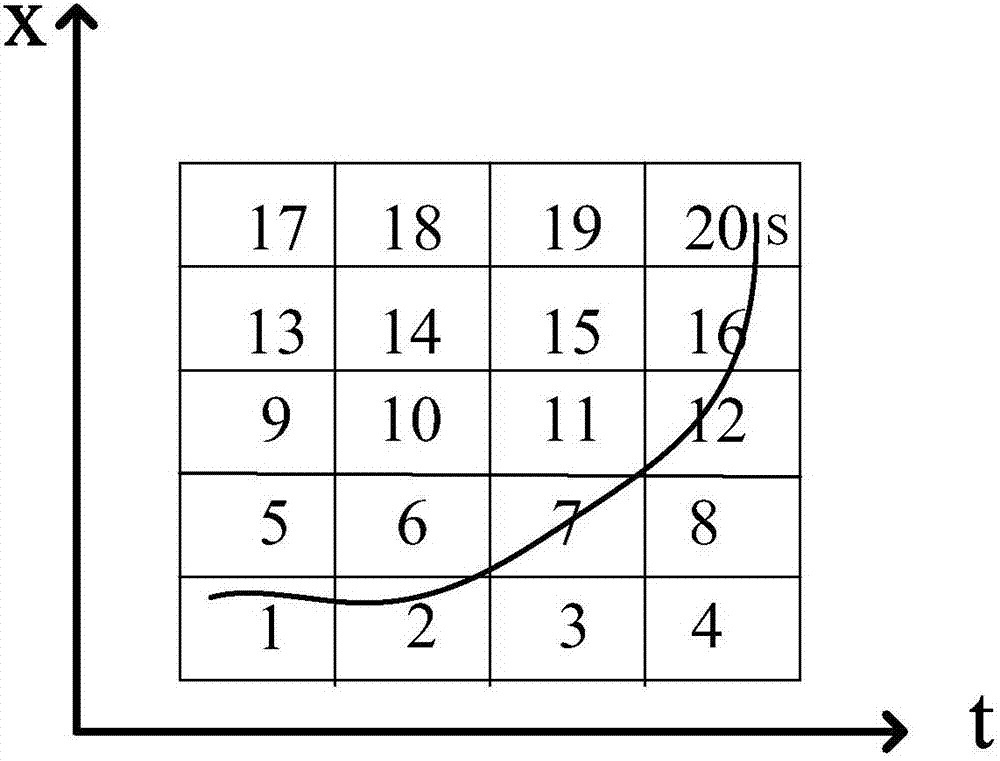
图2为根据本发明优选实施例的基于最小哈希的时间序列相似性查询方法的待测时间序列分割示意图;
图3为根据本发明优选实施例的基于最小哈希的时间序列相似性查询方法的标准时间序列分割示意图;
图4为根据本发明的基于最小哈希的时间序列相似性查询方法中相似性计算步骤第一实施方式的流程图;
图5为根据本发明的基于最小哈希的时间序列相似性查询方法中相似性计算步骤第二实施方式的流程图;
图6为根据本发明优选实施例的基于最小哈希的时间序列相似性查询装置的模块框图;
图7为根据本发明优选实施例的装置中的待测数据分割模块的一种实施方式的示意图;
图8为根据本发明优选实施例的装置中的相似性计算模块的一种实施方式的示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,为根据本发明优选实施例的基于最小哈希的时间序列相似性查询方法的流程图。如图1所示,该方法包括以下步骤:
首先,在步骤s101中,根据待测时间序列s的数据范围以及预设的分割系数将待测时间序列s划分到多个集合中,并采用数据点所在集合编号组成的一维待测序列s'表示待测时间序列s。其中,待测时间序列s的数据范围包括tmax、tmin、xmax和xmin,预设的分割系数包括σ和ε。分割系数σ和ε决定每个集合的大小,由实际需要的异常状态检测精度和数据量决定。
在本发明更优选的实施方式中,该步骤s101具体包括:
(1)依据预设的分割系数σ和ε将待测时间序列s的数据点划分到m×n个集合中,其中总行数m=(xmax-xmin)/σ,总列数n=(tmax-tmin)/ε。其中tmax和tmin为待测时间序列s的时间上限值和下限值,xmax和xmin为待测时间序列s的幅值上限值和下限值。也就是说,依据预设的分割系数σ和ε,将待测时间序列s的时间轴划分为n=(tmax-tmin)/ε个小区间,幅值轴划分为m=(xmax-xmin)/σ个小区间,使得待测时间序列s的数据点按照各自的坐标值被划分在了m×n个大小均为σ×ε的集合中。
(2)对步骤(1)得到的多个集合进行编号,假设待测时间序列s上的数据点p(ti,xi),1≤i≤k,其中k为所述待测时间序列s的数据点总数。则该数据点p(ti,xi)所在集合编号为:ni=(mi-1)×n+ni,其中该数据点所在行数mi=(xi-xmin)/σ,该数据点所在列数ni=(ti-tmin)/ε,由此构建一维待测序列s'={n1,n2,…,nk}。可见,集合编号ni中既包含着集合中数据点的时间信息,也包含着幅值信息,因此,可用由集合编号组成的新的数据表s’代替原始的待测时间序列s,从而将二维数据转换成一维数据。
请结合参阅图2,为根据本发明优选实施例的基于最小哈希的时间序列相似性查询方法的待测时间序列分割示意图。如图2所示,其中依据预设的分割系数σ和ε,将待测时间序列s的时间轴t划分为n=4个小区间,幅值轴划分为m=5个小区间,从而将待测时间序列s分割到5×4个集合中,按照前述规律对每个集合进行编号后,可以使用待测时间序列s所有数据点分布的集合编号来构建一维序列作为一维待测序列s',如图2中s'={1,2,6,7,11,12,16,20}。
随后,在步骤s102中,根据标准时间序列q的数据范围以及与步骤s101中相等的分割系数σ和ε将标准时间序列q分为多个集合,同样采用标准时间序列q的数据点所在的集合编号组成的一维标准序列q’表示标准时间序列q。该步骤s102的集合分割方法与步骤s101中相同,编号方法也相同。
请结合参阅图3,为根据本发明优选实施例的基于最小哈希的时间序列相似性查询方法的标准时间序列分割示意图。如图3所示,其中依据预设的分割系数σ和ε,将标准时间序列q的时间轴t划分为n=4个小区间,幅值轴划分为m=5个小区间,从而将标准时间序列q分割到5×4个集合中,按照前述规律对每个集合进行编号后,可以使用标准时间序列q所有数据点分布的集合编号来构建一维序列作为一维标准序列q',如图3中q'={1,5,6,10,11,15,16,20}。
随后,在步骤s103中,计算一维待测序列s'和一维标准序列q'的最小哈希值相等的概率作为杰拉德系数。
请结合参阅图4,为根据本发明的基于最小哈希的时间序列相似性查询方法中相似性计算步骤第一实施方式的流程图。在该实施方式中,该步骤s103具体包括:
首先,在步骤s401中,根据所述一维待测序列s’和一维标准序列q’生成特征矩阵,该特征矩阵包括三个行向量;其中
第一行向量包括一维待测序列s’和一维标准序列q’的所有元素;
第二行向量包括一维待测序列的标志值,其中当一维待测序列包含第一行向量的元素时,与该元素同列的一维待测序列的标志值置为第一标志值,当不包含第一行向量的元素时,与该元素同列的一维待测序列的标志值置为第二标志值;
第三行向量包括一维标准序列的标志值,其中当一维标准序列包含第一行向量的元素时,与该元素同列的一维标准序列的标志值置为第一标志值,当不包含第一行向量的元素时,与该元素同列的一维标准序列的标志值置为第二标志值。优选地,本发明中第一标志值为1,第二标志值为0。
例如,当前述一维待测序列s'={1,2,6,7,11,12,16,20},一维时间序列q'={1,5,6,10,11,15,16,20}时,特征矩阵分布表如表格1所示。其中行序号为s’和q’包含的所有元素,若s’和q’包含该元素,则对应位置置1,若不包含,则置0。
表格1
由此可得生成的特征矩阵m可表示为:
随后,在步骤s402中将特征矩阵的列向量进行随机排列,得到新的特征矩阵。新的特征矩阵中第二行向量和第三行向量中第一个为第一标志值对应的第一行向量的元素分别为一维待测序列的最小哈希值h(s′)和一维标准序列的最小哈希值q(s′)。
例如,上述矩形m经过1次随机排列后,得到如表格2所示的特征矩阵分布表:
表格2
由此可得变换得到的新的特征矩阵m’可表示为:
得到本次随机排列后的一维待测序列s’的最小哈希值h(s′)=7,和一维标准序列q’的最小哈希值q(s′)=20。则h(s′)≠q(s′)。
最后,在步骤s403中,计算多次所述随机排列得到的多组最小哈希值中h(s′)和q(s′)相等的频率作为杰拉德系数。例如对特征矩阵m进行n次随机排列,再计算n次随机排列得到的h(s′)和q(s′)相等的次数k。由最小哈希的理论可知s’和q’最小哈希值相等的概率即为s’和q’的jaccard系数,即jac(s′,q′)=p(h(s′)=h(q′))=k/n。因此我们将计算jaccard系数的运算转换为了求概率的运算,也就是说,在实际算法中,可用n次随机行排列后得到的n组最小哈希值中h(s′)和h(q′)相等的频率来代表二者相等的概率。
请结合参阅图5,为根据本发明的基于最小哈希的时间序列相似性查询方法中相似性计算步骤第二实施方式的流程图。该第二实施方式与第一实施方式相同,区别仅在于将特征矩阵的行和列进行置换。在该实施方式中,该步骤s103具体包括:
首先,在步骤s501中,根据所述一维待测序列s’和一维标准序列q’生成特征矩阵,该特征矩阵包括三个列向量;其中
第一列向量包括一维待测序列s’和一维标准序列q’的所有元素;
第二列向量包括一维待测序列的标志值,其中当一维待测序列包含第一列向量的元素时,与该元素同行的一维待测序列的标志值置为第一标志值,当不包含第一列向量的元素时,与该元素同行的一维待测序列的标志值置为第二标志值;
第三列向量包括一维标准序列的标志值,其中当一维标准序列包含第一列向量的元素时,与该元素同行的一维标准序列的标志值置为第一标志值,当不包含第一列向量的元素时,与该元素同行的一维标准序列的标志值置为第二标志值。优选地,本发明中第一标志值为1,第二标志值为0。
例如,当前述一维待测序列s'={1,2,6,7,11,12,16,20},一维时间序列q'={1,5,6,10,11,15,16,20}时,生成的特征矩阵m可表示为:
随后,在步骤s502中将特征矩阵的行向量进行随机排列,得到新的特征矩阵。新的特征矩阵中第二列向量和第三列向量中第一个为第一标志值对应的第一列向量的元素分别为一维待测序列的最小哈希值h(s′)和一维标准序列的最小哈希值q(s′)。
例如,上述矩形m经过1次随机排列后得到如表格2所示的特征矩阵分布表后变换得到的新的特征矩阵m’可表示为:
得到本次随机排列后的一维待测序列s’的最小哈希值h(s′)=7,和一维标准序列q’的最小哈希值q(s′)=20。则h(s′)≠q(s′)。
最后,在步骤s503中,计算多次所述随机排列得到的多组最小哈希值中h(s′)和q(s′)相等的频率作为杰拉德系数。例如对特征矩阵m进行n次随机排列,再计算n次随机排列得到的h(s′)和q(s′)相等的次数k。由最小哈希的理论可知s’和q’最小哈希值相等的概率即为s’和q’的jaccard系数,即jac(s′,q′)=p(h(s′)=h(q′))=k/n。
请结合参阅图6,为根据本发明优选实施例的基于最小哈希的时间序列相似性查询装置的模块框图。如图6所示,该实施例提供的基于最小哈希的时间序列相似性查询装置600至少包括:待测数据分割模块601、标准数据分割模块602和相似性计算模块603。
其中,待测数据分割模块601根据待测时间序列s的数据范围以及预设的分割系数将待测时间序列s划分到多个集合中,并采用数据点所在集合编号组成的一维待测序列s'表示待测时间序列s。
标准数据分割模块602用于根据标准时间序列q的数据范围以及与待测数据分割模块100中相等的分割系数σ和ε将标准时间序列q分为多个集合,同样采用标准时间序列q的数据点所在的集合编号组成的一维标准序列q’表示标准时间序列q。即标准数据分割模块602采用与待测数据分割模块601同样的方法进行分割和编号。
相似性计算模块603与待测数据分割模块601以及标准数据分割模块602相连,用于计算一维待测序列s'和一维标准序列q'的最小哈希值相等的概率作为杰拉德系数。
请结合参阅图7,为根据本发明优选实施例的装置中的待测数据分割模块的一种实施方式的示意图。如图7所示,该待测数据分割模块601包括:数据分割单元701以及与之相连的数据编号单元702。
其中数据分割单元701,用于依据预设的分割系数σ和ε将待测时间序列s的数据点划分到m×n个集合中,其中总行数m=(xmax-xmin)/σ,总列数n=(tmax-tmin)/ε。其中tmax和tmin为待测时间序列s的时间上限值和下限值,xmax和xmin为待测时间序列s的幅值上限值和下限值。
数据编号单元702用于对数据分割单元701分割的多个集合进行编号,假设待测时间序列s上的数据点p(ti,xi),1≤i≤k,其中k为所述待测时间序列s的数据点总数;则该数据点p(ti,xi)所在集合编号为:ni=(mi-1)×n+ni,其中mi=(xi-xmin)/σ,ni=(ti-tmin)/ε,由此构建一维待测序列s'={n1,n2,…,nk}。
请结合参阅图8,为根据本发明优选实施例的装置中的相似性计算模块的一种实施方式的示意图。如图5所示,该相似性计算模块603包括:矩阵生成单元801、矩阵变换单元802以及系数计算单元803。
矩阵生成单元801用于根据所述一维待测序列s’和一维标准序列q’生成特征矩阵,该特征矩阵包括三个行向量。
矩阵变换单元802用于将特征矩阵的列向量进行随机排列,得到新的特征矩阵。新的特征矩阵中第二行向量和第三行向量中第一个为第一标志值对应的第一行向量的元素分别为一维待测序列的最小哈希值h(s′)和一维标准序列的最小哈希值q(s′)。
系数计算单元803用于计算多次所述随机排列得到的多组最小哈希值中h(s′)和q(s′)相等的频率作为杰拉德系数。
本发明还提供了相似性计算模块的另一种实施方式,其中:
矩阵生成单元801用于根据所述一维待测序列s’和一维标准序列q’生成特征矩阵,该特征矩阵包括三个列向量。
矩阵变换单元802用于将特征矩阵的行向量进行随机排列,得到新的特征矩阵。新的特征矩阵中第二列向量和第三列向量中第一个为第一标志值对应的第一列向量的元素分别为一维待测序列的最小哈希值h(s′)和一维标准序列的最小哈希值q(s′)。
系数计算单元803用于计算多次所述随机排列得到的多组最小哈希值中h(s′)和q(s′)相等的频率作为杰拉德系数。
综上所述,本发明首先将分布于时间轴上的数据按照一定的规则和分割系数分割为集合,并对集合编号,集合序号包含着该集合中数据点的幅值信息和在时间轴上的位置信息。然后将包含着多个数据点的集合看作新的元素,与标准时间序列比较,并利用jaccard系数衡量两序列的相似性。这种方法将比较时间序列的相似性转换为比较集合的相似性,大大加快了运算速度,并且具有良好的可扩展性。
并且,本发明的关键点还在于将最小哈希运算应用于基于集合的时间序列相似性查询当中,用s’和q’最小哈希值相等的概率来计算二者的jaccard系数,减小了计算jaccard系数的运算量,进一步提高了算法效率。最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!