一种基于粒子群优化的H‑ELM的驾驶疲劳检测方法与流程
本发明涉及驾驶疲劳的检测方法,特别涉及一种基于粒子群优化的多层学习超限学习机的驾驶疲劳检测方法。
背景技术:
超限学习机(extremelearningmachine,elm)是一种单隐含层前馈神经网络(single-hiddenlayerfeedforwardneuralnetworks,slfns),仅有一个隐含层。相比较于传统的bp神经网络需要多次迭代进行参数的调整,训练速度慢,容易陷入局部极小值,无法达到全局最小等缺点,elm算法随机产生输入层与隐含层的连接权值与偏置,且在训练过程中无需进行隐层参数迭代调整,只需要设置隐含层神经元的个数以及激活函数,便可以通过最小化平方损失函数得到输出权值。
多层学习超限学习机(h-elm)先将输入转换入一个随机的特征空间,再通过多层的无监督学习,提取了数据的高层特征,再通过普通的超限学习机对特征进行学习和分类。而超限学习机的范数和比例因子的选择直接影响超限学习机的分类效果。
技术实现要素:
本发明的目的是在功率谱对信号进行特征提取的基础上,结合粒子群优化算法(pso)对多层学习超限学习机的范数和比例因子进行迭代寻优,提出了一种基于粒子群优化的多层学习超限学习机(pso-helm)的驾驶疲劳检测方法。
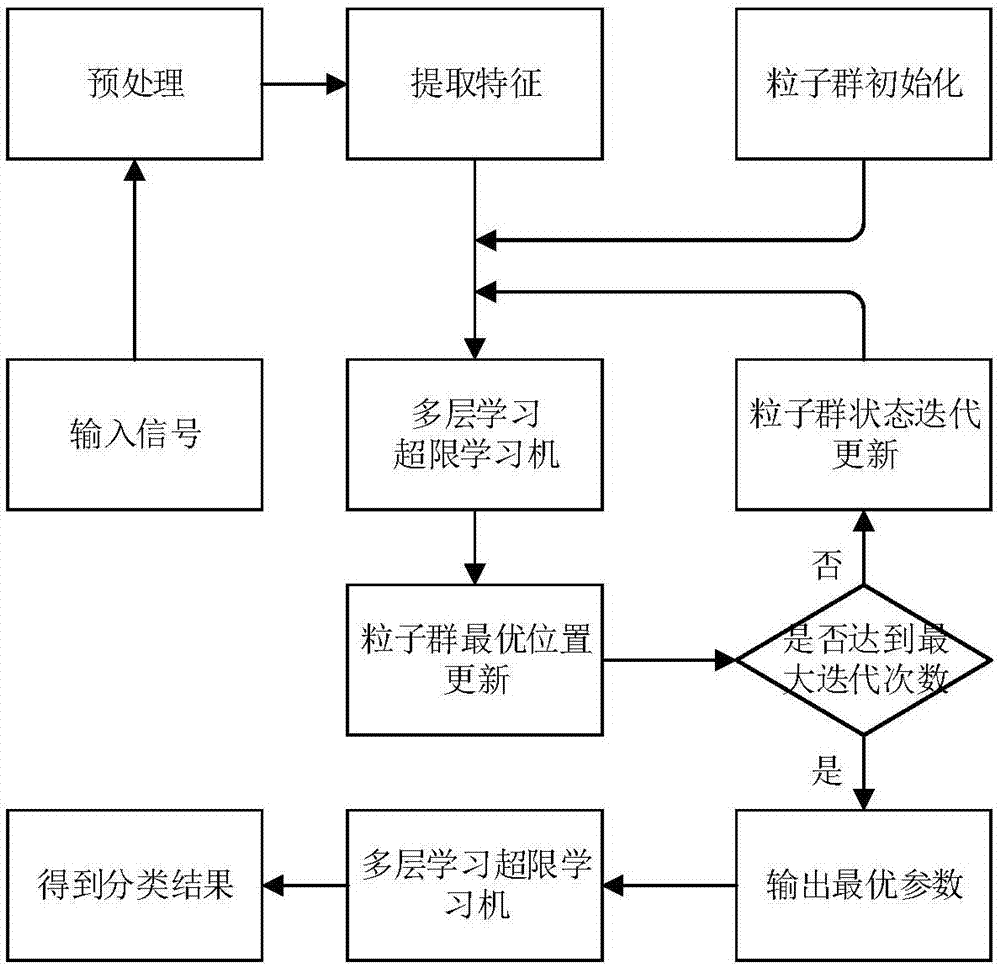
按照本发明提供的技术方案,提出了一种基于粒子群优化的多层学习超限学习机驾驶疲劳检测方法,包括如下步骤:
步骤1、使用脑电采集设备采集32个信道的驾驶脑电信号;
步骤2、对采集到的脑电信号进行预处理,包括降频、降噪;
步骤3、对预处理后的数据加窗进行离散傅里叶变换;
步骤4、根据离散傅里叶变换后的数据求功率谱密度,并根据脑电信号的频带进行频带划分,以各频带的功率作为特征;
步骤5、对提取的特征使用多层学习超限学习机进行分类学习、识别;
步骤6、通过粒子群算法对超限学习机的分类、识别效果进行优化。
所述的步骤4中根据脑电信号的频带进行频带划分,具体为:在每个信道的频域信号中提取五个频带,分别为δ(0.1-3hz)、θ(4-7hz)、α(8-15hz)、β(16-31hz)、γ(32-50hz);
所述的步骤5中,多层学习超限学习机进行分类学习、识别的步骤具体为:
5-1.将输入转换入一个随机的特征空间;
5-2.经过k层隐藏层,每一层隐藏层进行无监督学习,输出的ηk代表了输入数据的高层特征,此时再通过普通的超限学习机对特征进行学习和分类;
其中每一层隐藏层的输出可以表达为
hi=g(hi-1·β),
其中,ηi是第i个隐藏层的输出,ηi-1是第i-1个隐藏层的输出,g(·)是隐藏层的激活函数,β是隐藏层的输出权重;
在隐藏层自学习的过程中,利用无限逼近方法设计隐藏层自编码公式
其中,oβ为隐藏层输入数据x和输出数据的最小误差,η为自编码的随机输出映射,β为隐藏层的输出权重,l1为范数优化参数。
所述的步骤6中,通过粒子群算法对超限学习机的分类、识别效果进行优化,具体步骤为:
6-1.在d维空间中,初始化m个粒子的初始位置和速度,包括设定粒子群初始参数c1和c2,确定每个粒子的位置范围以及每个粒子的速度范围;
6-2.定义每个粒子的最优位置和整个粒子群的全局最优位置:
pbesti=(pi1,pi2,...,pid)
gbesti=(gi1,gi2,...,gid)
其中pbest为第i个粒子的最优位置,gbest为种群的全局最优位置,i=1,2,...m;
6-3.利用初始化的参数建立多层学习超限学习机,根据训练样本对该模型进行训练,并计算适应度函数值;
6-4.根据粒子的初始适应度值得到初始的个体及全局最优位置;
6-5.根据粒子的位置和速度迭代更新公式,对粒子状态进行更新:
xij(t+1)=xij(t)+vij(t+1)
vij(t+1)=ωvij(t)+c1r1(pbestij(t)-xij(t))+c2r2(gbestj(t)-xij(t))
其中,xij(t)为粒子i在第j代的位置,vij(t)为粒子i在第j代的速度,r1和r2是[0,1]的随机数;
6-6.计算粒子的适应度值,并更新个体及全局最优位置;
6-7.保持迭代更新,直到达到最大的迭代次数或满足要求的误差条件。此时,全局最优位置即为参数的最优解;
6-8.以此时的参数构建多层学习超限学习机,对驾驶疲劳进行检测。
本发明有益效果如下:
利用功率谱密度进行特征提取后,将基于pso-helm分类识别结果与单一helm进行分类识别、传统的svm分类识别结果、传统的knn分类识别结果进行对比,结果表明,使用pso优化后的h-helm分类器对驾驶疲劳进行检测的正确率更高,有效的提高了分类检测识别率。
附图说明
图1为多层学习极限学习机原理图;
图2为pso-helm迭代寻优流程图。
具体实施方式:
下面结合具体实施例对本发明作进一步说明。以下描述仅作为示范和解释,并不对本发明作任何形式上的限制。
如图1与图2所示本发明实现的步骤如下:
步骤1、使用脑电采集设备采集驾驶脑电信号;
步骤2、对采集到的脑电信号进行预处理,包括降频、降噪;
步骤3、对预处理后的数据加窗进行离散傅里叶变换;
步骤4、根据离散傅里叶变换后的数据求功率谱密度,并根据脑电信号的频带进行频带划分,以各频带的功率作为特征;
步骤5、对提取的特征使用多层学习超限学习机进行分类学习、识别;
步骤6、通过粒子群算法对超限学习机的分类、识别效果进行优化。
所述的步骤4中,所述的步骤4中根据脑电信号的频带进行频带划分,具体为:在每个信道的频域信号中提取五个频带,分别为δ(0.1-3hz)、θ(4-7hz)、α(8-15hz)、β(16-31hz)、γ(32-50hz)五个频带,此时,每个信道的信号特征维度已减少至五维。
其中步骤5中,多层学习超限学习机进行分类学习、识别的步骤具体为:
5-1.将输入转换入一个随机的特征空间;
5-2.经过k层隐藏层,每一层隐藏层进行无监督学习,输出的ηk代表了输入数据的高层特征,此时再通过普通的超限学习机对特征进行学习和分类;
其中每一层隐藏层的输出可以表达为
hi=g(hi-1·β),
其中,ηi是第i个隐藏层的输出,ηi-1是第i-1个隐藏层的输出,g(·)是隐藏层的激活函数,β是隐藏层的输出权重;
在隐藏层自学习的过程中,利用无限逼近方法设计隐藏层自编码公式
其中,oβ为隐藏层输入数据x和输出数据的最小误差,η为自编码的随机输出映射,β为隐藏层的输出权重,l1为范数优化参数。
所述的步骤6中,通过粒子群算法对超限学习机的分类、识别效果进行优化,具体步骤为:6-1.在d维空间中,初始化m个粒子的初始位置和速度,包括设定粒子群初始参数c1和c2,确定每个粒子的位置范围以及每个粒子的速度范围;
6-2.定义每个粒子的最优位置和整个粒子群的全局最优位置:
pbesti=(pi1,pi2,…,pid)
gbesti=(gi1,gi2,…,gid)
其中pbest为第i个粒子的最优位置,gbest为种群的全局最优位置,i=1,2,...m;
6-3.利用初始化的参数建立多层学习超限学习机,根据训练样本对该模型进行训练,并计算适应度函数值;
6-4.根据粒子的初始适应度值定义初始的个体及全局最优位置;
6-5.根据粒子的位置和速度迭代更新公式,对粒子状态进行更新:
xij(t+1)=xij(t)+vij(t+1)
vij(t+1)=ωvij(t)+c1r1(pbestij(t)-xij(t))+c2r2(gbestj(t)-xij(t))
其中,xij(t)为粒子i在第j代的位置,vij(t)为粒子i在第j代的速度,r1和r2是[0,1]的随机数;
6-6.计算粒子的适应度值,并更新pbest和gbest的值;
6-7.保持迭代更新,直到达到最大的迭代次数或满足要求的误差条件。此时,全局最优位置即为参数的最优解;
6-8.以此时的参数构建多层学习超限学习机,对驾驶疲劳进行检测。
以480个驾驶时的脑电样本为训练数据,960个脑电样本为测试数据时,分别使用knn,svm,h-elm和pso-helm算法进行分类,其分类结果如下表1所示。
表1四种分类算法分类准确率对比
通过对比四种算法的分类识别率,可以明显看出h-elm分类算法比传统的knn算法和svm算法有更好的分类效果,而pso-helm在h-elm算法的基础上,进一步优化参数,使分类准确率提高了2.5%左右,表明pso-helm获取最优参数的同时有效的提高了多层学习超限学习机的性能。
- 还没有人留言评论。精彩留言会获得点赞!