一种基于深度学习的出租车载客点推荐方法与流程
本发明涉及计算机应用与机器学习交叉
技术领域:
,尤其涉及一种基于深度学习的出租车载客点推荐技术。
背景技术:
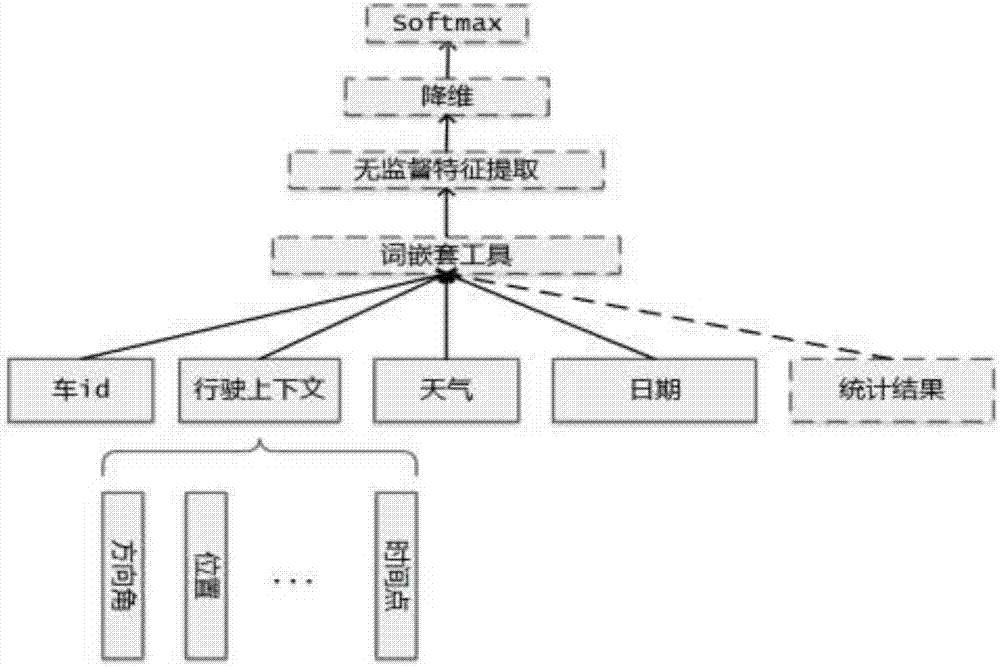
:城市计算是计算机科学以城市为背景,跟城市规划、交通、能源、环境、社会学和经济等学科融合的新兴领域,是一个通过不断获取、整合和分析城市中多种异构大数据来解决城市所面临的挑战(如环境恶化、交通拥堵、能耗增加、规划落后等)的过程。城市计算将无处不在的感知技术、高效的数据管理和分析算法,以及新颖的可视化技术相结合,致力于提高人们的生活品质、保护环境和促进城市运转效率。出租车是城市客运交通的重要组成部分,是常规公共交通的重要补充。随着出租车数量的不断增长,以出租车为主要对象的智能交通相关技术目前已成为城市计算的一个重要研究课题。深度学习是机器学习研究中的一个前沿领域,其概念由hinton等人于2006年提出,目的是通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示,而深度神经网络是深度学习模型的一种重要实例。先前的机器学习方法如随机森林、支持向量机、线性回归、逻辑回归、反向传播神经网络等,都可以被看做是在输入层和输出层之间只有一个单隐层的模型,而深度神经网络模仿人的“神经元”对数据进行感知和学习,为了学习到数据之间非线性的复杂关系,可以将网络设置为多隐层的训练结构。目前,深度神经网络已经成功应用到图像分类、语音识别及自然语言处理等领域中,并取得了较好的成果。我们发现将深度神经网络应用于出租车载客点的推荐过程中来提高其推荐准确度,目前还是一个空白。现有的方法大都使用统计学习和浅层机器学习模型来处理出租车载客点的预测和推荐,这就导致了推荐系统不能很好地捕获底层gps轨迹数据所隐含的模式,从而严重影响出租车载客点的推荐准确度。技术实现要素:本发明为了解决现有方法的上述不足,提出了一种基于深度学习的出租车载客点推荐方法,图1给出了本发明的处理流程图。本发明可以通过以下技术方案流程来实现,主要包括如下三个步骤:1.大数据预处理。本发明首先对地图大数据和出租车gps轨迹大数据进行预处理。对于地图大数据,采用网格化的方法,选定参考点,将地图分成固定大小的网格,形成网格地图。从而,每个网格所包围的区域都有固定的坐标,同时,每个落入该区域的gps点具有一致的数据表示。对于gps轨迹大数据,本发明所采用的格式如下所示:车id经度纬度方向角是否载客时间点日期…首先,本发明根据是否载客,将gps轨迹分成载客旅程和巡游旅程两大类。由于gps设备定位的精度以及外部因素如天气、隧道等原因,轨迹数据往往存在一定的偏移,即并未准确定位到相应的道路上。因此,本发明利用地图匹配技术将gps点映射到相应的道路上,得到更为准确的定位信息。对于载客旅程,本发明利用统计学习方法得到以下信息:载客热点、道路状况以及司机收入信息。其中,载客热点与道路状况都与出租车司机的寻客策略有很大关系。对于巡游旅程,本发明通过预处理得到的司机寻客时的上下文信息,如起始位置、行驶方向、天气等。2.深度学习模型构建。由于将地图进行网格化后,载客点由经纬度组成的连续值变成网格坐标组成的离散值,因此,本发明将乘客预测和路况预测问题均视为分类问题,并用相同的模型架构,如图2所示。在学习模型构造过程中,本发明首先将出租车gps大轨迹数据和地图大数据通过词嵌套工具生成一维向量,并且将一维向量通过无监督学习获取数据特征,然后通过降维方法提取数据特征的主成分信息,即活性特征,从而将活性特征输入到softmax分类器来实现多目标分类。3.载客点推荐。在步骤2深度学习模型构建的基础上,为了保证推荐的效果,使得出租车寻客效率更高,本发明将收入因素也纳入到载客点推荐的影响因素当中,并设计如下载客点推荐的计算公式:其中,ζ表示推荐分数,o和d分别表示出租车寻客的出发点和乘客可能出现的地点网格,t和t'分别是从o的出发时间和d的到达时间,α是乘客预测的准确度,hd,t'是网格d在时间t'的热度值,二者乘积表示d对出租车的吸引力;β是路况预测的权重,co,d,t表示在t时从o点出发到d点时的路况,通常可以用平均速度表示;γ是预期收入的预测准确度,ld,t'表示潜在载客旅程的长度(与收入成正相关),dis(o,d)表示从o到d的距离。因此,该计算公式可以看做是给在某时刻t出发的从o到d的一趟寻客旅程的打分公式。分数越高,表示该目的地越值得出租车前往寻客。与现有技术相比,本发明具有以下优点:1、本发明使用深度学习模型,能够显著提高出租车载客点预测的准确度;2、本发明综合考虑影响出租车载客的各项因素,能够为司机推荐收益高的载客地点;3、本发明使用大规模gps轨迹数据,能够显著提高出租车载客点推荐的泛化能力。附图说明图1本发明的处理流程图图2本发明乘客预测和路况预测深度学习模型具体实施方式实施例本发明在gps轨迹大数据获取上,选取上海某一出租车公司中的10000辆出租车,并获得它们两个月产生的gps轨迹数据,大小约为800gb,而地图选取上海百度地图。由于很少有计算机的内存配置能够达到处理如此大量数据的级别,因此,为了数据处理的稳定性,本发明部署计算机集群,其中包含20台高配置台式机。对于上述gps轨迹大数据的预处理,本发明按照如下等式关系进行实施:r([车id,出发点,出发时刻,行驶方向,天气,周几])=寻客点。该等式表示的是寻客点与出租车寻客规律之间的关系,即出租车司机在当前环境下最可能去哪个地方寻找下一个潜在的乘客。将数据处理成上述格式之后,在深度学习模型构造中,本发明通过google公司的word2vec工具将它转换成长度为500的一维向量,然后将这一维向量通过降噪自编码器(denoisingautoencoder)来无监督学习出长度为250的一维数据特征。在长度为250的一维数据特征基础上,本发明进一步使用主成分识别算法(pca)和t-分布邻域嵌入算法(t-sne)分别对它进行降维操作,提取其中最有意义的特征向量。本发明将该特征向量的长度设为150。最后,将这长度为250的一维特征向量输入到类别数为地图网络个数的softmax分类器中。本发明中的地图网络个数为4000。对于参数优化过程,本发明使用随机优化方法来具体实施。在载客点推荐过程中,本发明按照分数计算公式来实施。在本实施例中,我们选取出租车寻客的出发点o为虹桥机场所在的地点网络,d为乘客可能出现的地点网格,有3999个,对应softmax分类器中除了o之外的3999个目标类,而softmax分类器共有4000个目标类。出租车从o出发时间t和到达d时间t'取值依据一次寻客过程的具体时间点来给定,假定t为早上8:30,t'为9:15。乘客预测的准确度α、路况预测的权重β通过步骤2的深度学习模型来计算,假定α=0.92,β=0.88,而预期收入的预测准确度γ通过统计学习方法来计算,假定γ=0.85。网格d在时间t'的热度值hd,t'通过近一个月的历史数据做统计分析求得,假定hd,t'=1.55,在t时从o点出发到d点时的路况(即平均速度)co,d,t通过近一个月的历史数据做统计分析求得,假定co,d,t=48.5,潜在载客旅程的长度ld,t'通过近一个月的历史数据做统计分析求得,假定ld,t'=12.5,从o到d的距离dis(o,d)取值依据一次寻客过程来具体确定,假定dis(o,d)=23.4。那么可以求出分数ζ(o,d,t)=0.92×1.55×0.88×48.5×0.92×0.85×12.5÷23.4=25.4。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1