一种基于大规模射频识别系统的多类信息收集方法与流程
本发明涉及大规模rfid系统信息收集协议,具体为一种基于大规模射频识别系统的多类信息收集方法。
背景技术:
大规模rfid系统在商场、仓库、供应链中应用非常广泛,由于其成本低,外形灵巧,且具有一定存储信息能力,通过与阅读器的通信,可以将自身存储的关于物品的信息以及监测到的关于周围环境信息传给阅读器,极大地方便了用户对大量物品的管理。然而由于不同类型的物品,其附着的标签存储和检测的信息不同、数据量不同,导致标签传送给阅读器所用的时隙长度不同,从而使得整个信息收集过程很慢长。因此,设计一种高效的信息收集协议,对于rfid系统大规模应用具有重要的意义。
技术实现要素:
本发明为大规模rfid系统提供了一种高效的信息收集协议,具体为一种基于大规模射频识别系统的多类信息收集方法。
本发明是采用如下的技术方案实现的:一种基于大规模射频识别系统的多类信息收集方法,包括分类阶段、排序阶段和信息收集阶段,
其中分类阶段包括以下步骤:
首先阅读器广播携带有<f,r>的命令给识别区域的所有标签,f是帧长,r为随机数;
接收到这个命令的所有标签通过哈希函数h(id;r)mod(f)计算第一次的类别码,若有不同类标签得到的类别码相同时,阅读器重新发送一个新的帧长f和随机数r,标签再计算类别码,重新计算的类别码结合第一次的类别码形成第二次的类别码,若第二次的类别码有相同时,阅读器重新发送一个新的帧长f和随机数r,标签再计算类别码,重新计算的类别码结合第二次的类别码形成第三次的类别码,直到不同类的标签拥有不同的类别码;
排序阶段包括以下步骤:
首先,阅读器给识别区域的所有标签广播某一类标签的类别码,收到类别码的标签通过对比,类别码与自身相同的被激活,不同类的标签将保持沉默;
阅读器先用第一个哈希函数h1对该类别所有标签的id段进行计算,并将得到的值对应的时隙标记为1,若有两个和两个以上的标签映射到同一个时隙,则这个时隙标记为0,映射到单时隙的标签将不参与这阶段接下来的运算,其余标签id段将继续用第二个哈希函数h2、第三个哈希函数h3等等依次进行计算,并将映射到的单时隙标记为所有哈希函数的序号值,最终构建好的矢量称为标签回复排序矢量;
信息收集阶段包括以下步骤:
首先阅读器发送标签回复排序矢量以及每轮依次使用的随机数r的命令给这组所有的标签,接收到命令的标签先用自己的id段和相应轮的随机数r通过第一个哈希函数h1进行计算,然后将哈希函数的序号1与阅读器发过来的矢量相应位进行对比,看相应位的标记是否为1,若是则将这个时隙的位置保存到计数器n中,此时,若发现在接收到的矢量相应位前面有未被安排的时隙时,计数器需要减去矢量相应位前未安排时隙的总个数,并等待计数器n变成0时向阅读器发送信息;若不是则继续用第二个哈希函数h2、第三个哈希函数h3等等依次进行计算,直到矢量相应位的标记值与最后一个计算的哈希函数的序号相同为止。
本技术方案主要是针对大规模rfid系统的应用提出一种快速有效的信息收集方法(iccp),阅读器将识别区域的标签根据传送信息量的大小分为数类,通过分类可以避免数据量小的信息在大的时隙中传输,节约信息收集时间,同时可以排除一分部不需要收集信息的标签的响应。然后对每类标签通过多个哈希函数进行伪随机排序,最后通过处理将标签回复过程中的空时隙剔除,让标签依次按序向阅读器发送信息,使得iccp更接近理想信息收集的时间。
附图说明
图1为标签分类示意图。
图2为标签排序示意图。
具体实施方式
一种基于大规模射频识别系统的多类信息收集方法,分为三个部分,第一个部分是当阅读器需要读取标签信息时,先将所有标签按需要传送信息量的大小进行分类,这样可以使不需要回复信息的标签保持沉默,减少对需要回复信息的标签通信时的干扰,也可以避免小信息量在大的时隙中传输造成时隙的浪费,缩短整个方法的执行时间;第二部分是对每类标签通过多次哈希函数进行排序,使其在相应的时隙中将信息回复给标签,避免标签之间的碰撞;在第三部分中引入了计数器n,对第二部分产生的回复矢量排序进行压缩,将空时隙剔除,减少空时隙的浪费,降低协议的执行时间,提高协议的效率。
第一部分分类阶段
首先阅读器广播携带有<f,r>的命令给识别区域的所有标签,f是虚拟帧的帧长,r为随机数,这个命令同时定义了阅读器与标签之间的通信方式和具体细节,包括数据传输率、编码方式等等,阅读器可以将识别区域内所有的标签通过哈希函数计算出虚拟bloom矢量,虚拟bloom矢量并不会真实的展示出来,而是在阅读器端进行,也就是说能在很大程度上节省标签的能量,减少通信过程中的损失。在这个阶段只有单时隙是有用的。接收到这个命令的所有标签通过哈希函数h(id;r)mod(f)计算它的类别码,同时阅读器端也可以通过相同的计算得到相同的结果。若仍有不同类标签得到的类别码相同时,阅读器重新发送一个新的虚拟帧的帧长f和随机数r,直到不同类的标签拥有不同的类别码。
如图1所示:这里有5类不同的标签,首先阅读器向所有标签广播携带有<f,r1>的命令,收到命令的标签进行哈希函数h(id,r1)modf计算,同时阅读器端也可以计算得到相同的结果。c1、c2、c3、c4、c5这5类标签通过计算得到的值分别为0、3、1、3和2,将这个结果作为这一次的类别号,可以看出其中第2类和第4类未成功区分,需要阅读器重新选取随机数发送给标签进行哈希计算。经过第二次用另一不同的随机数r2哈希计算,c1、c2、c3、c4、c5这5类标签得到的计算结果分别为2、1、4、2和3,将此作为标签的第二位类别码,可以看出上一次未区分的第2类和第4类标签已成功区分。所以最终5类标签的类别码分别为“02”、“31”、“14”、“32”、“23”,至此已成功给5类标签分配好各自的类别码。当阅读器需要收集某几类或全部标签的传感器信息时,只需要广播相应的类别码,收到命令的标签通过比对类别码,通过的将被激活并通过下面的阶段将信息传回给阅读器,类别码比对结果不同的标签将在之后的阶段保持沉默。
在分类阶段,阅读器只需要发送含有随机数r以及帧长f的命令给所有标签,接收到此命令的标签将通过h(id,ri)modf计算得到的结果作为它的类别号,此过程中由于阅读器不需要传输除命令以外的信息,所以执行时间仅为阅读器发送命令时间加上标签的计算时间,非常短,可以忽略不计。同时由于不需要传输构成的bloom矢量,所以此阶段不存在假阳性概率问题,大大减少了误差。
第二部分排序阶段
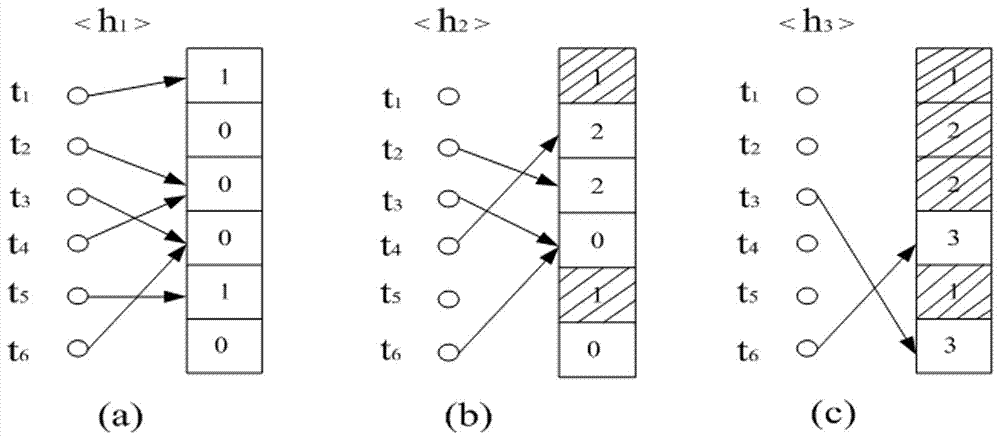
排序阶段包括多轮,每一轮使用一个哈希函数。阅读器通过多个哈希函数,对某组的所有标签进行排序,以确定每个标签传回信息时所规定的单时隙。首先,阅读器向所有标签广播这一类标签的类别码,收到命令的标签通过对比,类别码与自身相同的被激活,不同类的标签将保持沉默。然后阅读器对这类标签进行哈希计算,得到bloom矢量,这里帧长等于标签数,并将空时隙和冲突时隙用“0”标记,单时隙用相应的哈希函数序号进行标记。
序号序号序号如图2所示,在这个阶段,阅读器先通过第一个哈希函数h1计算将标签映射到时隙中,如果一个标签被映射到一个时隙,且这个时隙没有其它标签映射,则将这个时隙标记为“1”,其余的没有标签映射的时隙以及多个标签映射的时隙标记为“0”。在图2(a)中,阅读器将没有成功映射到单时隙的标签用第二个哈希函数h2计算,同理成功映射到单时隙的标签将在这个阶段之后的过程中保持沉默,而这个时隙被标记为“2”。以此类推,直到所有的标签都被映射到单独的时隙,即标签排序成功。
第三部分信息收集阶段
在这一阶段,每个标签需要维持一个计数器n,计数器的初始值设为0,在每个时隙开始时,如果标签的计数器为0则立即发送自己的信息,否则该时隙不响应。当标签的信息被成功接收时,该标签将进入沉默状态,对以后时隙的阅读器命令均不响应。首先阅读器发送标签回复排序矢量、以及每轮依次使用的随机数r的命令给这组所有的标签,接收到命令的标签先用自己的id段(截取的id部分信息)和和相应轮的随机数r通过第一个哈希函数h1进行计算,然后将哈希函数的序号1与阅读器发过来的矢量相应位进行对比,看相应位的标记是否为1,若是则将这个时隙的位置保存到计数器n中,此时,若发现在接收到的矢量相应位前面有未被安排的时隙时,计数器需要减去矢量相应位前未安排时隙的总个数,并等待计数器n变成0时向阅读器发送信息;若不是则继续用第二个哈希函数h2、第三个哈希函数h3等等依次进行计算,直到矢量相应位的标记值与最后一个计算的哈希函数的序号相同为止。
由于在第一个标签分类阶段,阅读器和所有标签只需要用id段进行几个简单的哈希计算,不需要传送其他的信息,所以执行时间非常短,可以忽略。在第二阶段,也就是对某组标签的排序阶段,阅读器构建一个排序矢量用于回复标签信息。假设参与第二阶段的标签总数为m,每一个时隙中标记符为ybit,y与使用的哈希函数个数有关,若标签通过6个哈希函数计算后成功被排序,那么用二进制表示为110,只需要3bit。所以阅读器发送标签回复排序矢量的时间为:
基于以上分析,iccp总执行时间的计算如下
- 还没有人留言评论。精彩留言会获得点赞!