一种油色谱在线监测数据最优长度选择方法与流程
本发明属于变压器油色谱的在线监测及分析技术领域。特别涉及一种油色谱在线监测数据最优长度选择方法。
背景技术:
变压器是电力系统的重要枢纽设备之一,其运行的可靠性关系到电力系统的安全稳定运行。为了确保变压器的正常运行,使用油中溶解气体分析(dissolvedgasanalysis,dga)在线监测技术对变压器油中溶解气体进行实时测量,根据实时监测值可以及时的发现变压器的早期故障、判断故障的类型、给出检修计划等。变压器油色谱在线监测系统按照一定的采集周期获取油中溶解气体的数据,采集到的油色谱数据随着时间变化,形成油色谱在线监测时间序列。在现有的研究中,油色谱在线监测时间序列被广泛应用于变压器的状态评价、故障预测、油色谱阈值计算和预警等方面。油色谱在线监测时间序列从变压器投运时即开始形成,因此该时间序列时间跨度较长,数据量较大,在实际使用时,往往将所有数据都拿过来分析,或者取一个固定的时间段内的数据进行分析,该固定时间段长度的选取主要依赖于研究人员的主观性,没有统一的标准。而在对数据进一步分析时,如果选取的数据过多,即选择的时间跨度较长时,则数据中靠前的部分可能无法反应当前工况下变压器的运行情况,同样的如果选取的数据量较少,即选择的时间跨度较短时,则由于数据量的缺乏也无法真实的反映变压器当前的运行情况。因此,油色谱分析数据长度选择的问题成为迫切需要解决的问题。然而,近年来却鲜有关于油色谱在线监测数据最优长度选择的研究。
技术实现要素:
本发明的目的是提供一种油色谱在线监测数据最优长度选择方法,其特征在于,所述油色谱在线监测数据最优长度选择方法包括如下步骤:s102,获取变压器在线监测数据作为原始油色谱数据集;s104,重构原始油色谱数据集相空间;s106,计算相空间的最优嵌入维数和最优时间延迟;s108,根据相空间收缩性分析最优嵌入维数与最优长度的关系;s110,根据最优嵌入维数计算原始油色谱数据集的最优长度;s112,根据最优长度从原始油色谱数据集中获取最优油色谱分析数据集;s114,输出最优油色谱分析数据集。
所述步骤s102,获取变压器在线油色谱监测数据作为原始油色谱数据集;以变压器油色谱在线监测系统采集的全部监测数据作为原始的色谱数据集;具体获取变压器油色谱在线监测时间序列数据,每条监测数据对应一个监测时间,且监测时间按照降序排列;
所述步骤s104,重构原始油色谱数据集相空间;对原始油色谱数据集x(n)构造m’维向量x(n):
x(n)=(x(n),x(n-t’),…,x(n-(m’-1)t’)),n=(m’-1)t’+1,…n’;其中参数n=1,2,…n’,t’为预设延迟时间,m’为预设嵌入维数。
所述步骤s106,计算相空间的最优嵌入维数和最优时间延迟采用的计算方法包括:自相关函数法、互信息方法、饱和关联维数法、改进虚假临近点法和c-c法中一种或一种以上。
所述步骤s108,根据相空间收缩性分析最优嵌入维数与最优长度的关系,
所述步骤s108包括:
步骤s108a:由于原始油色谱数据集是有界的,假设在[-r,r]之中,则原始油色谱数据的相空间位于一个以2r为边界的超立方体中,时间序列的n个点平均分布在该超立方中,从每个点到边界的平均距离为:
其中,r为数据取值的边界,m为最优嵌入维数,n为最优长度,
步骤s108b:每个点对应的体积为:v0=(2r)m/n,其中,r为数据取值的边界,m为最优嵌入维数,n为最优长度,相邻点的特征长度为:
rn=(v0)1/m=2r(1/n)1/m(2)
其中,r为数据取值的边界,m为最优嵌入维数,n为最优长度;
步骤s108c:当rn=rs时相空间具有可收缩和饱和的特性,否则将始终收缩或者始终饱和,因此可以得到最优嵌入维数与最优长度的关系:
n1/m=2(m+1)(3)
其中,m为最优嵌入维数,n为最优长度。
所述步骤s110,根据最优嵌入维数计算原始油色谱数据集的最优长度,
计算油色谱分析数据的最优长度:n=2m(m+1)m;
所述步骤s112,根据最优长度从原始油色谱数据集中获取最优油色谱分析数据集,根据所述的最优长度,在原始油色谱数据集时间序列中选择从最近时间开始之前的n个数据作为最优油色谱分析数据集;
步骤s114,,输出最优油色谱分析数据集,将步骤s112的最优油色谱分析数据集输出。
所述步骤s106采用c-c法计算最佳嵌入维数和最佳时间延迟进行说明:
步骤s106a,定义x(n)的嵌入时间序列的关联积分为:
其中,τ为时间延迟;m为嵌入维数;m=n-(m-1)τ;n为数据的个数;dij=||yi-yj||∞,为∞函数;r为搜索半径,取小于max(dij)的任意实数;θ(x)为heaviside函数,当x≥0是,θ(x)=1,当x<0是,θ(x)=0。步骤s106b,定义x(n)的检验统计量:
其中,τ为时间延迟;m为嵌入维数;n为数据的个数;r为搜索半径,取小于max(dij)的任意实数;
步骤s106c,定义x(n)的偏差统计量:
δs(m,n,r,τ)=max{s(m,n,r,τ)}-min{s(m,n,r,τ)}(6)
其中,τ为时间延迟;m为嵌入维数;n为数据的个数;r为搜索半径,取小于max(dij)的任意实数;max{s(m,n,r,τ)}表示s(m,n,r,τ)的最大值;min{s(m,n,r,τ)}表示s(m,n,r,τ)的最大值。步骤s106d,定义x(n)平均检验统计量:
其中,τ为时间延迟;m为嵌入维数;n为数据的个数;s(m,n,r,τ)表示x(n)的检验统计量;nm为嵌入维数m可能取值的个数;nk为搜索半径r可能取值的个数。步骤s106e,定义x(n)平均偏差统计量:
其中,τ为时间延迟;m为嵌入维数;n为数据的个数;δs(m,n,r,τ)表示x(n)的偏差统计量;nm为嵌入维数m可能取值的个数。
步骤s106f,定义x(n)平均指标统计量:
其中,
步骤s106g,选择式(7)的第一个零点和式(8)的第一个极小值点对应的两个延迟时间的最小值作为最优延迟时间t,
步骤s106h,选择式(9)的全局最小点即为最优延迟时间窗口τω,
步骤s106i,根据τω=(m-1)τ计算得到嵌入维数m。
本发明的有益效果是可以从大量的油色谱在线监测数据中获取最优的分析数据集,使得分析效率及分析准确率更高。
附图说明
图1是根据本发明实施例的一种可选的油色谱在线监测数据最优长度选择方法的流程图。
图2c-c方法的
图3c-c方法的
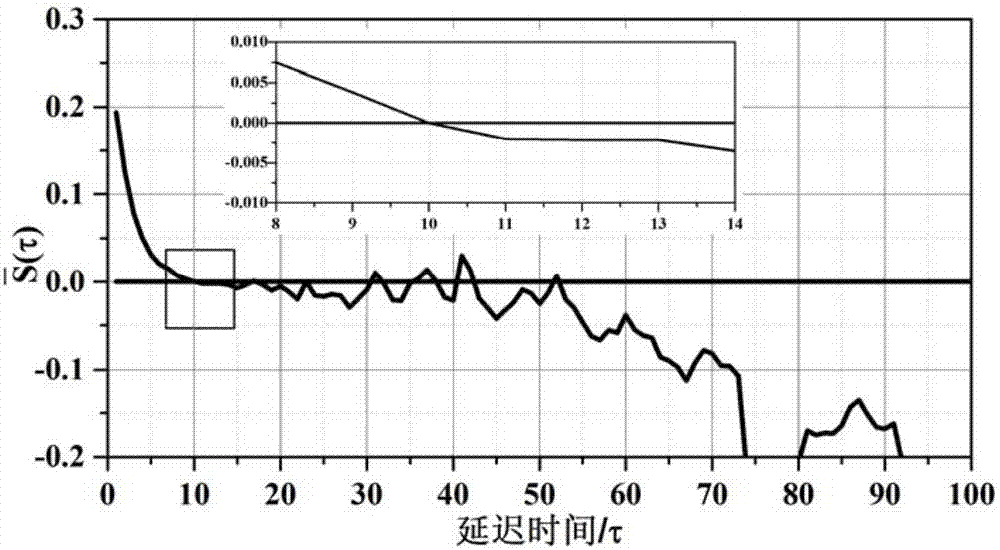
图4c-c方法的scor(τ)曲线
具体实施方式
实施例1
本发明的目的是提供一种油色谱在线监测数据最优长度选择方法,所述油色谱在线监测数据最优长度选择方法包括如下步骤:s102,获取变压器在线监测数据作为原始油色谱数据集;s104,重构原始油色谱数据集相空间;s106,计算相空间的最优嵌入维数和最优时间延迟;s108,根据相空间收缩性分析最优嵌入维数与最优长度的关系;s110,根据最优嵌入维数计算原始油色谱数据集的最优长度;s112,根据最优长度从原始油色谱数据集中获取最优油色谱分析数据集;s114,输出最优油色谱分析数据集。
下面结合附图对本发明的实施步骤进一步说明。
图1为一种可选的油色谱在线监测数据最优长度选择方法的流程图,
图1所示如下步骤,进一步说明如下:
步骤s102,获取变压器在线油色谱监测数据作为原始油色谱数据集;以变压器油色谱在线监测系统采集的全部监测数据作为原始的色谱数据集;
所述步骤s102具体包括;获取变压器油色谱在线监测时间序列数据,每条监
测数据对应一个监测时间,且监测时间按照降序排列;
例如本实施例中,获取某变压器2012年1月1日至2014年12月31日的在线监测油色谱中h2的时间序列数据共1095条,数据格式如表1所示。
表1
步骤s104,重构原始油色谱数据集相空间;对原始油色谱数据集x(n)构造m’维向量x(n):
x(n)=(x(n),x(n-t’),…,x(n-(m’-1)t’)),n=(m’-1)t’+1,…n’;其中参数n=1,2,…n’,t’为预设延迟时间,m’为预设嵌入维数。
步骤s106,计算相空间的的最优嵌入维数和最优时间延迟,计算方法包括:自相关函数法、互信息方法、饱和关联维数法、改进虚假临近点法和c-c法中一种或一种以上;
下面对使用c-c法计算最佳嵌入维数和最佳时间延迟进行说明:
步骤s106a,定义x(n)的嵌入时间序列的关联积分为:
其中,τ为时间延迟;m为嵌入维数;m=n-(m-1)τ;n为数据的个数;dij=||yi-yj||∞,为∞函数;r为搜索半径,取小于max(dij)的任意实数;θ(x)为heaviside函数,当x≥0是,θ(x)=1,当x<0是,θ(x)=0。
步骤s106b,定义x(n)的检验统计量:
其中,τ为时间延迟;m为嵌入维数;n为数据的个数;r为搜索半径,取小于max(dij)的任意实数;
步骤s106c,定义x(n)的偏差统计量:
δs(m,n,r,τ)=max{s(m,n,r,τ)}-min{s(m,n,r,τ)}(6)
其中,τ为时间延迟;m为嵌入维数;n为数据的个数;r为搜索半径,取小于max(dij)的任意实数;max{s(m,n,r,τ)}表示s(m,n,r,τ)的最大值;min{s(m,n,r,τ)}表示s(m,n,r,τ)的最大值。步骤s106d,定义x(n)平均检验统计量:
其中,τ为时间延迟;m为嵌入维数;n为数据的个数;s(m,n,r,τ)表示x(n)的检验统计量;nm为嵌入维数m可能取值的个数;nk为搜索半径r可能取值的个数。
步骤s106e,定义x(n)平均偏差统计量:
其中,τ为时间延迟;m为嵌入维数;n为数据的个数;δs(m,n,r,τ)表示x(n)的偏差统计量;nm为嵌入维数m可能取值的个数。
步骤s106f,定义x(n)平均指标统计量:
其中,
步骤s106g,选择式(7)的第一个零点和式(8)的第一个极小值点对应的两个延迟时间的最小值作为最优延迟时间t,
步骤s106h,选择式(8)的全局最小点即为最优延迟时间窗口τω,
步骤s106i,根据τω=(m-1)τ计算得到嵌入维数m。
在本实施例中,对相空间x(n)分别计算式(7)、(8)、(9)的值并绘制取值变化图如图2、图3、图4所示。由图中可以看出式(7)的第一个零点为10,式(9)的第一个极值点为6,所以延迟时间为6,由图中可以看出式(9)的全局最小点为12,所以嵌入维数m=(12/6)+1=3。
步骤s108,根据相空间收缩性分析最优嵌入维数与最优长度的关系,
由于原始油色谱数据集是有界的,假设在[-r,r]之中,则原始油色谱数据的相空间位于一个以2r为边界的超立方体中,时间序列的n个点平均分布在该超立方中,从每个点到边界的平均距离为:
所述步骤s108包括:
步骤s108a:由于原始油色谱数据集是有界的,假设在[-r,r]之中,则原始油色谱数据的相空间位于一个以2r为边界的超立方体中,时间序列的n个点平均分布在该超立方中,从每个点到边界的平均距离为:
其中,r为数据取值的边界,m为最优嵌入维数,n为最优长度,
步骤s108b:每个点对应的体积为:v0=(2r)m/n,其中,r为数据取值的边界,m为最优嵌入维数,n为最优长度,相邻点的特征长度为:
rn=(v0)1/m=2r(1/n)1/m(2)
其中,r为数据取值的边界,m为最优嵌入维数,n为最优长度;
步骤s108c:当rn=rs时相空间具有可收缩和饱和的特性,否则将始终收缩或者始终饱和,因此可以得到最优嵌入维数与最优长度的关系:
n1/m=2(m+1)(3)
其中,m为最优嵌入维数,n为最优长度。
在本实施例中,最优嵌入维数m=3,所以,最优嵌入维数与最优长度的关系为:
n1/3=2(3+1)
步骤s110,根据最优嵌入维数计算原始油色谱数据集的最优长度,
计算油色谱分析数据的最优长度:n=2m(m+1)m;
根据最优嵌入维数计算原始油色谱数据集的最优长度:
n=23(3+1)3=512
步骤s112,根据最优长度从原始油色谱数据集中获取最优油色谱分析数据集,
根据所述的最优长度,在原始油色谱数据集时间序列中选择从最近时间开始向后的n个数据作为最优油色谱分析数据集;
在本实施例从最近时间2014年12月31日开始之后的512条数据为最优油色谱分析数据集,获取的最优油色谱分析数据集数据及日期如表2所示。
表2
所述步骤s114,将表2中的数据作为最优分析数据集进行输出。
通过上述步骤s102-s114,即可以对变压器在线监测数据进行相空间重构,并计算最优嵌入维数和延迟时间,并分析最优嵌入维数与最优长度之间的关系,根据最优长度从原始的油色谱监测数据中选择最优的油色谱分析数据集。
- 还没有人留言评论。精彩留言会获得点赞!