人脸表情合成后的图像优化方法、装置、存储介质和计算机设备与流程
本发明涉及计算机视觉和计算机图形学技术领域,特别是涉及一种人脸表情合成后的图像优化方法、装置、存储介质和计算机设备。
背景技术:
近年来,一些研究者提出了“表情转移”技术,即捕捉视频中人脸表情后将其转移予虚拟形象以完成动画制作。这些工作实现了虚拟人物的仿真化,赋予了动画角色更加丰富生动的表情,有效地增添了动画作品的趣味性,提高了视觉效果的真实感。而2015年,thiesj与他的同事们则走得更远一步,提出了在不同的真人个体间进行表情转移,其工作内容是:同时获取两个视频,源视频与目标视频,首先捕捉源视频中的人物表情,然后将该表情重现在目标视频中另一个人物的脸上,达到操控目标人物表情的效果。该项技术可以被应用在视频会议、译制片等场景中,将翻译人员的表情转移到说话者的脸上,可以使得嘴型神态与发音更好地匹配,从而带来更加自然舒适的观感体验。但是传统的表情转移方法只是对目标图像进行了表情转移,而未对表情转移后的图像是否自然合理进行优化。
技术实现要素:
基于此,有必要针对上述技术问题,提供一种人脸表情合成后的图像优化方法、装置、存储介质和计算机设备。
一种人脸表情合成后的图像优化方法,所述方法包括:
制作3d牙齿模型;
获取表情转移后的3d合成脸模型;
对所述牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与所述合成脸模型对齐;
将所述牙齿模型转换为2d图像,将所述合成脸模型转换为2d图像,将所述牙齿模型对应的2d图像融合至所述合成脸模型对应的2d图像中,获得融合后的合成脸图像。
在其中一个实施例中,所述制作3d牙齿模型,包括:
扫描人物牙齿部分和口腔部分,获得牙齿部分和口腔部分扫描结果图;
对所述扫描结果图进行特征点定位;
对经过特征点定位后的扫描结果图进行3d建模,得到3d牙齿模型。
在其中一个实施例中,所述对所述牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与所述合成脸模型对齐,包括:
通过计算放缩因子、平移参数及旋转因子来对所述牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与所述合成脸模型对齐。
在其中一个实施例中,所述将所述牙齿模型转换为2d图像,将所述合成脸模型转换为2d图像,将所述牙齿模型对应的2d图像融合至所述合成脸模型对应的2d图像中,获得融合后的合成脸图像,包括:
采用拉普拉斯图像融合方法,将所述牙齿模型对应的2d图像融合至所述合成脸模型对应的2d图像中,获得融合后的合成脸图像。
在其中一个实施例中,所述方法还包括:
对融合后的合成脸图像进行皱纹刻画。
在其中一个实施例中,所述对融合后的合成脸图像进行皱纹刻画,包括:
从表情转移后的3d合成脸模型对应的源图像中,获取皱纹区域,所述源图像中包含转移的表情;
通过泊松图像克隆将所述皱纹区域中的皱纹克隆至融合后的合成脸图像上。
一种人脸表情合成后的图像优化装置,所述装置包括:
牙齿模型制作模块,用于制作3d牙齿模型;
合成脸模型获取模块,用于获取表情转移后的3d合成脸模型;
牙齿模型对齐模块,用于对所述牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与所述合成脸模型对齐;
融合模块,用于将所述牙齿模型转换为2d图像,将所述合成脸模型转换为2d图像,将所述牙齿模型对应的2d图像融合至所述合成脸模型对应的2d图像中,获得融合后的合成脸图像。
在其中一个实施例中,所述牙齿模型制作模块包括:
扫描模块,用于扫描人物牙齿部分和口腔部分,获得牙齿部分和口腔部分扫描结果图;
定位模块,用于对所述扫描结果图进行特征点定位;
建模模块,用于对经过特征点定位后的扫描结果图进行3d建模,得到3d牙齿模型。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现以下步骤:
制作3d牙齿模型;
获取表情转移后的3d合成脸模型;
对所述牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与所述合成脸模型对齐;
将所述牙齿模型转换为2d图像,将所述合成脸模型转换为2d图像,将所述牙齿模型对应的2d图像融合至所述合成脸模型对应的2d图像中,获得融合后的合成脸图像。
一种计算机设备,所述计算机设备包括存储器,处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
制作3d牙齿模型;
获取表情转移后的3d合成脸模型;
对所述牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与所述合成脸模型对齐;
将所述牙齿模型转换为2d图像,将所述合成脸模型转换为2d图像,将所述牙齿模型对应的2d图像融合至所述合成脸模型对应的2d图像中,获得融合后的合成脸图像。
上述人脸表情合成后的图像优化方法、装置、存储介质和计算机设备,首先,制作3d牙齿模型,获取表情转移后的3d合成脸模型。其次,对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐,即牙齿模型会随着合成脸模型中嘴部张开而改变方位,呈现出了更加贴合实际的效果。最后,将经过变换操作后的牙齿模型转换为2d图像,将合成脸模型转换为2d图像,将牙齿模型对应的2d图像融合至合成脸模型对应的2d图像中,获得融合后的合成脸图像。这样经过融合之后,牙齿与脸部的接合部分柔和了许多,整体效果更加自然。传统的方法,只进行了表情转移,并未对牙齿及其他口腔细节进行刻画,导致表情转移的图像的视觉效果非常突兀与奇怪。
附图说明
图1为一个实施例中服务器的内部结构图;
图2为一个实施例中人脸表情合成后的图像优化方法的流程图;
图3中一个实施例中上牙齿部分和口腔部分的扫描结果图;
图4为图2中制作3d牙齿模型方法的流程图;
图5为一个实施例中3d牙齿模型结构示意图;
图6为一个实施例中人脸特征点分布示意图;
图7为一个实施例中求解放缩因子选取距离示意图;
图8为另一个实施例中人脸表情合成后的图像优化方法的流程图;
图9为图8中皱纹刻画方法的流程图;
图10为一个实施例中添加皱纹的效果图;
图11为泊松图片克隆流程示意图;
图12为一个实施例中人脸表情合成后的图像优化装置的结构示意图;
图13为图12中牙齿模型制作模块的结构示意图;
图14为另一个实施例中人脸表情合成后的图像优化装置的结构示意图;
图15为图14中皱纹刻画模块的结构示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。在下面的描述中阐述了很多具体细节以便于充分理解本发明。但是本发明能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似改进,因此本发明不受下面公开的具体实施的限制。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
在一个实施例中,如图1所示,还提供了一种服务器,该服务器包括通过系统总线连接的处理器、非易失性存储介质、内存储器、网络接口,非易失性存储介质中存储有操作系统和一种人脸表情合成后的图像优化装置,该人脸表情合成后的图像优化装置用于执行一种人脸表情合成后的图像优化方法。该处理器用于提高计算和控制能力,支撑整个服务器的运行。内存储器用于为非易失性存储介质中的人脸表情合成后的图像优化装置的运行提供环境,该内存储器中可储存有计算机可读指令,该计算机可读指令被处理器执行时,可使得该处理器执行一种人脸表情合成后的图像优化方法。网络接口用于与终端进行网络通信,接收或发送数据,例如接收终端发送的人脸表情合成后的图像优化的请求,以及向终端发送图像优化后的图像等。
本发明实施例可以实现将从一个视频中捕捉到的人物表情渲染到另一个视频中的人脸上,以达到表情转移的效果,并对表情转移后的图像进行添加牙齿、皱纹等细节。例如,该项技术可以被应用在视频会议、译制片等场景中,将翻译人员的表情转移到说话者的脸上,可以使得嘴型、牙齿及皱纹神态与发音更好地匹配,从而带来更加自然舒适的观感体验。当然,也可以使用在动画制作等领域,将从一个视频中捕捉人脸表情后将其转移予另一视频中的虚拟形象以完成动画制作。这些工作实现了虚拟人物的仿真化,赋予了动画角色更加丰富生动的表情,有效地增添了动画作品的趣味性,提高了视觉效果的真实感。
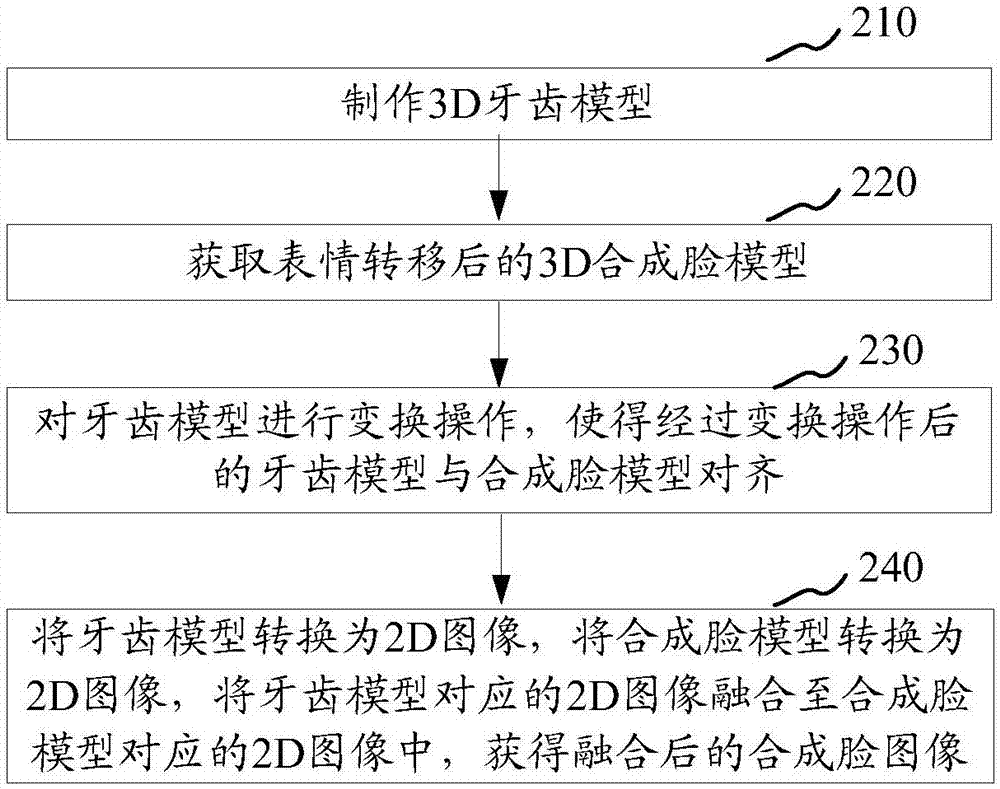
在一个实施例中,如图2所示,提供了一种人脸表情合成后的图像优化方法,以该方法应用于图1中的服务器为例进行说明,包括:
步骤210,制作3d牙齿模型。
在对牙齿进行建模时,首先,扫描人物牙齿部分和口腔部分,获得牙齿部分和口腔部分扫描结果图。具体的,可以使用扫描仪进行扫描,获得的扫描结果图如图3所示。图3中上半部分为口腔部分的扫描结果图,图3中下半部分为牙齿部分的扫描结果图。
其次,对所述扫描结果图进行特征点定位。具体为,从训练模型中得到牙齿部分和口腔部分的平均特征点位置。训练模型为:sdm(监督下降方法,superviseddescentmethod)。该训练模型的主要思想为:从训练数据中学习梯度下降的方向,并建立相应的回归模型,然后再利用训练所得模型进行梯度方向估计,从而在较低的计算复杂度下解决了最小二乘问题。通过训练,sdm模型可以在最优化过程的迭代中不断学习,从而学会如何从初始位置逐步收敛到最佳位置,由此我们可以实现特征点的自动定位。从而从训练模型中得到牙齿部分和口腔部分的初始平均特征点位置。将平均特征点位置进行等比放缩,将等比放缩后得到的特征点位置放置于扫描结果图中。对特征点位置进行优化,优化后的特征点位置能够与扫描结果图中的牙齿部分和口腔部分吻合。
最后,对经过特征点定位后的扫描结果图进行3d建模,得到3d牙齿模型。具体为,将经过特征点定位后的扫描结果图通过sfm模型进行模型拟合,得到3d牙齿模型。
sfm(surreyfacemodel)模型由英国萨里大学的图像、语音与信号处理中心(centreofvision,speechandsignalprocessingattheuniversityofsurrey)所建立的3d人脸形变模型,是一种可使用的开源模型。该模型有四种不同的规模,分别包含有29387、16759、3448、1724个顶点,每种规模既有仅仅包含形状的模型,也有形状与颜色均包含在内的模型。sfm的训练集有169个人,既包含十几岁少年也包含六十岁以上老人,以20-29岁间青年居多。其中,欧洲白种人有101人,剩余为亚洲人、非洲人、拉丁美洲人。因为sfm模型中包含全球各种人种的人,所以拟合的效果比较满意。sfm由两部分组成:一个pca形状模型,一个pca颜色模型。
步骤220,获取表情转移后的3d合成脸模型。
获取表情转移后的3d合成脸模型。表情转移的过程具体为,首先,从源视频和目标视频中获取图像,分别对获取的图像进行人脸特征点定位。分别对经过人脸特征点定位后的图像进行3d人脸建模,得到3d人脸模型。然后,对3d人脸模型先在形状层面进行表情转移,之后再进行纹理贴图。最终,得到了表情转移后的合成脸模型。
步骤230,对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐。
具体为,通过计算放缩因子、平移参数及旋转因子来对所述牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与所述合成脸模型对齐。
步骤240,将牙齿模型转换为2d图像,将合成脸模型转换为2d图像,将牙齿模型对应的2d图像融合至合成脸模型对应的2d图像中,获得融合后的合成脸图像。
采用拉普拉斯图像融合方法,将所述牙齿模型对应的2d图像融合至所述合成脸模型对应的2d图像中,获得融合后的合成脸图像。
本实施例中,首先,制作3d牙齿模型,获取表情转移后的3d合成脸模型。其次,对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐,即牙齿模型会随着合成脸模型中嘴部张开而改变方位,呈现出了更加贴合实际的效果。最后,将经过变换操作后的牙齿模型转换为2d图像,将合成脸模型转换为2d图像,将牙齿模型对应的2d图像融合至合成脸模型对应的2d图像中,获得融合后的合成脸图像。这样经过融合之后,牙齿与脸部的接合部分柔和了许多,整体效果更加自然。传统的方法,只进行了表情转移,并未对牙齿及其他口腔细节进行刻画,导致表情转移的图像的视觉效果非常突兀与奇怪。
在一个实施例中,如图4所示,制作3d牙齿模型,包括:
步骤212,扫描人物牙齿部分和口腔部分,获得牙齿部分和口腔部分扫描结果图。
具体的,可以使用扫描仪进行扫描,获得的扫描结果如图3所示。图3中上半部分为口腔部分的扫描结果图,图3中下半部分为牙齿部分的扫描结果图。
步骤214,对扫描结果图进行特征点定位。
具体为,从训练模型中得到牙齿部分和口腔部分的平均特征点位置。训练模型为:sdm(监督下降方法,superviseddescentmethod)。该训练模型的主要思想为:从训练数据中学习梯度下降的方向,并建立相应的回归模型,然后再利用训练所得模型进行梯度方向估计,从而在较低的计算复杂度下解决了最小二乘问题。通过训练,sdm模型可以在最优化过程的迭代中不断学习,从而学会如何从初始位置逐步收敛到最佳位置,由此我们可以实现特征点的自动定位。从而从训练模型中得到牙齿部分和口腔部分的初始平均特征点位置。将平均特征点位置进行等比放缩,将等比放缩后得到的特征点位置放置于扫描结果图中。对特征点位置进行优化,优化后的特征点位置能够与扫描结果图中的牙齿部分和口腔部分吻合。
步骤216,对经过特征点定位后的扫描结果图进行3d建模,得到3d牙齿模型。
具体为,将经过特征点定位后的扫描结果图通过sfm模型进行模型拟合,得到3d牙齿模型。构造的牙齿模型结构示意图如图5所示,图5中左图a)为上牙模型,右图b)为下牙模型。其中,上牙模型含有440个顶点、820个面;下牙模型含有412个顶点、767个面。它们的颜色,包括牙龈与牙齿,均是通过反复试验选取得到的结果。3d牙齿模型保存为常用网格格式obj文件(obj文件是3d模型文件格式)。其记录方式为,为每个顶点标号,用v开头的行描述顶点位置及颜色,用f开头的行描述面的组成顶点。为了在程序中使用这两个模型,本发明实施例中使用了函数read_obj。该函数读入obj文件,将相应顶点信息、面信息解析保存,最终输出网格类实体。
sfm(surreyfacemodel)模型由英国萨里大学的图像、语音与信号处理中心(centreofvision,speechandsignalprocessingattheuniversityofsurrey)所建立的3d人脸形变模型,是一种可使用的开源模型。该模型有四种不同的规模,分别包含有29387、16759、3448、1724个顶点,每种规模既有仅仅包含形状的模型,也有形状与颜色均包含在内的模型。sfm的训练集有169个人,既包含十几岁少年也包含六十岁以上老人,以20-29岁间青年居多。其中,欧洲白种人有101人,剩余为亚洲人、非洲人、拉丁美洲人。因为sfm模型中包含全球各种人种的人,所以拟合的效果比较满意。sfm由两部分组成:一个pca形状模型,一个pca颜色模型。
在本实施例中,通过sdm模型对已知特征点正确位置的牙齿部分和口腔部分图片进行训练,得到牙齿部分和口腔部分的平均特征点位置。对训练集进行训练这样得出的平均特征点位置更加准确,进而使得最终得到的与本次实测的牙齿和口腔部分图像吻合的特征点位置更加准确。再将平均特征点位置进行等比放缩,将等比放缩后得到的特征点位置放置于扫描结果图中。对特征点位置进行优化,优化后的特征点位置能够与扫描结果图中的牙齿部分和口腔部分吻合。将经过特征点定位后的扫描结果图通过sfm模型进行模型拟合,得到3d牙齿模型。从而构造了存在于三维空间可以由任意角度观察的3d牙齿模型,更加符合现实情况。
在一个实施例中,对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐,包括:
通过计算放缩因子、平移参数及旋转因子来对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐。
为了让牙齿能够随着嘴部形状的改变而进行旋转移动等变换,我们需要将牙齿模型与脸部模型对齐,形象地说,即是将牙齿与嘴唇“粘合”,使得在张嘴时,牙齿能够如同实际中一样,由闭合的状态转化为打开的状态。通过计算放缩因子、平移参数及旋转因子来对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐。
具体的计算过程如下:需要在牙齿模型上与脸部模型上选取n≥3三组以上对应点,例如本发明实施例中采用了10组对应点,当然,在其他实施例中也可以采用其他数量的对应点。请参见图6,图6为一个实施例中人脸特征点分布示意图。其中,选取的上牙的10组对应点为图6中的第49、51、52、53、55、61、62、63、64、65号特征点,选取的下牙的10组对应点为第49、55、57、58、59、61、65、66、67、68号特征点,记牙齿模型上的点为pteeth,脸部模型上的点为pface,均用三维坐标表示。目的是求得放缩因子s,平移参数t,和旋转矩阵r,使得:
首先,求解放缩因子s,考虑到牙齿的大小应该和嘴部匹配,所以首先,我们需要对牙齿模型进行放缩。具体操作为,分别计算脸部模型中两嘴角点(特征点49和55对应位置)之间距离和牙齿模型中事前选定的两点之间的距离,记为dist_f和dist_t。请参见图7所示,图7为一个实施例中求解放缩因子选取距离示意图。图7中左图标出了脸部模型中特征点49和55之间的距离dist_f,图7中右图标出了牙齿模型中事前选定的两点之间的距离dist_t。则放缩因子即为两者之比,也就是说s=dist_f/dist_t。
其次,求解平移参数t。具体操作为,要求解平移参数,即是得到式(1)中关于t求导数为0时候的t值。具体推导如下:
如果记牙齿模型和人脸模型上所用于对齐的十个点的质心,即它们的平均点,分别为centroid_t和centroid_f:
那么式子(2)实际上可以表示为
t=-r(s·centroidt)+centriod_f(4)
所以在求解平移参数t之前,应该先求得旋转矩阵r,然后代入该式中,自然可以得到t。
求解旋转矩阵,若将式(4)代入式(1),可以得到:
其中
可见,该问题得到了简化,变成了对原来的点集做一个减质心的预处理,然后再求两个最小二乘的旋转量,更加利于计算。将上式展开可得:
倒数第二步等式是由于旋转矩阵为正交矩阵,所以rtr=i。同时可以知道yitrxi和xitrtyi都是标量,而一个标量的转置即是其自身,则推算得到最终表示。则求旋转矩阵即是求参数r使得式(7)最小,也即是使得其中间一项最大。将其用矩阵形式表示:
其中tr(.)表示求矩阵的迹,即对角线元素之和;x和y都是3xn的矩阵。由迹的特性tr(ab)=tr(ba),可以得到tr(ytrx)=tr(rxyt)。利用奇异值(svd)分解,将xyt分解为一个正交矩阵u乘上一个对角矩阵,再乘上一个正交矩阵的转置vt。则得到tr(ruσvt),可进一步利用交换率得到tr(σvtru)。
由于v、r、u都是正交矩阵,则m=vtru也是一个正交矩阵,满足:
d是矩阵m的维度。则对于式(8)即是:
故而可以知道,要使得迹最大,必须使得mii=1,而其它mij均为0,即是m为单位矩阵。旋转矩阵r即可以求得:
i=m=vtru=>v=ru=>r=vut
(11)
通过上述操作得到放缩因子s,平移参数t,和旋转矩阵r之后,就可以对牙齿模型进行变换操作,将其与人脸模型对齐。
在本实施例中,通过计算放缩因子、平移参数及旋转因子来对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐。经过对齐,牙齿模型会随着嘴部张开而改变方位,呈现出了更加贴合实际的效果。对表情转移后的图像加入了牙齿和口腔部分的图像,填补了牙齿和口腔部位的空缺,这样使得添加后的表情更加真实完整。
在一个实施例中,将牙齿模型转换为2d图像,将合成脸模型转换为2d图像,将牙齿模型对应的2d图像融合至合成脸模型对应的2d图像中,获得融合后的合成脸图像,包括:
采用拉普拉斯图像融合方法,将牙齿模型对应的2d图像融合至合成脸模型对应的2d图像中,获得融合后的合成脸图像。
拉普拉斯金字塔的构建为,首先对高斯金字塔的l层图像gl进行上采样与插值滤波,得到与l-1层同样尺度的预测图像gl*,具体做法为:1)将图像在每个方向上扩大为原来的两倍,新增的行和列以0填充;2)使用与之前高斯金字塔构造时相同的高斯核与放大后的图像卷积,获得新增像素的近似值。
拉普拉斯图像融合是将图像的拉普拉斯金字塔在相应层上以一定的规则融合得到合成金字塔,然后再将该合成金字塔按照其构建的逆过程进行重构,得到融合图像的方法。得到了各个层次的融合图像后,可以利用逆过程,从顶层开始逐层向下递推,从而恢复其对应得到的高斯金字塔,并可以得到最终与原图同尺寸的合成结果。
在本实施例中,将对齐后的人脸模型和牙齿模型进行拉普拉斯图像融合,使得牙齿与脸部的接合部分更加柔和。
在一个实施例中,如图8所示,方法还包括:
步骤250,对融合后的合成脸图像进行皱纹刻画。
在本实施例中,用拉普拉斯图像融合方法得到的拼合效果,牙齿与脸部的接合部分柔和了许多,但是因为未添加表情引起的皱纹,所以还是略显生硬。对融合后的合成脸图像进行皱纹刻画,就使得整体效果更加自然。
在一个实施例中,如图9所示,对融合后的合成脸图像进行皱纹刻画,包括:
步骤252,从表情转移后的3d合成脸模型对应的源图像中,获取皱纹区域,源图像中包含转移的表情。
如图10所示,图10为一个实施例中添加皱纹的效果图。表情转移的源图像为图10中左上角的女孩张嘴惊讶表情,将该表情转移至图10中右上角图中的男孩的图像中。源图像中鼻翼两侧由于嘴部的长大产生了明显的纹路,但未添加细节效果的合成张嘴图中,男孩却没有该纹路,从而使得表情不够生动。因此,为了使得表情转移后的结果更加写实,皱纹细节的刻画非常有必要。本发明实施例中采用泊松图片克隆的方法实现皱纹刻画。
为了选取待克隆区域,即所需皱纹区域,我们先要构造遮挡层(mask)。以法令纹为例,根据观察,法令纹出现的位置大致在图6中特征点30和特征点5、特征点30和特征点12的连线上,从而可以通过特征点位置选取得到皱纹区域(注意还需要去掉鼻子区域),如图10所示。
步骤254,通过泊松图像克隆将皱纹区域中的皱纹克隆至融合后的合成脸图像上。
泊松图片克隆的主要思想与流程如图11所示:对于待克隆区域g(如图11左上)与背景图片s(如图11中上),我们的目的是把g克隆粘贴到s上,并且实现自然融合的效果(如图11右上),其中
解决上式可得到一个有dirichlet边界条件的泊松方程组如下,求解该方程组可得结果。
具体算法实现为:1)首先通过差分的方法求解图像g的梯度场v(如图11左下);2)然后计算背景图片的梯度场(如图11中下);3)将背景图片的ω区域的梯度场替换为图像g的梯度场(如图11右下)。4)对梯度求偏导,获得ω区域上的散度场δg。5)最后构建泊松方程,求解系数矩阵,得到f。
然后利用泊松图像克隆,可以将皱纹转移到目标图像上。
在本实施例中,先结合人脸特征点分布示意图选取出皱纹区域,再利用泊松图像克隆将皱纹区域中的皱纹转移至目标图像上。从而使得表情转移后的图像更加真实自然。
在一个实施例中,如图12所示,还提供了一种人脸表情合成后的图像优化装置300,该装置包括:牙齿模型制作模块310、合成脸模型获取模块320、牙齿模型对齐模块330及融合模块340。
牙齿模型制作模块310,用于制作3d牙齿模型。
合成脸模型获取模块320,用于获取表情转移后的3d合成脸模型。
牙齿模型对齐模块330,用于对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐。
融合模块340,用于将牙齿模型转换为2d图像,将合成脸模型转换为2d图像,将牙齿模型对应的2d图像融合至合成脸模型对应的2d图像中,获得融合后的合成脸图像。
在一个实施例中,如图13所示,牙齿模型制作模块310包括:
扫描模块312,用于扫描人物牙齿部分和口腔部分,获得牙齿部分和口腔部分扫描结果图。
定位模块314,用于对扫描结果图进行特征点定位。
建模模块316,用于对经过特征点定位后的扫描结果图进行3d建模,得到3d牙齿模型。
在一个实施例中,牙齿模型对齐模块330还用于通过计算放缩因子、平移参数及旋转因子来对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐。
在一个实施例中,融合模块340还用于采用拉普拉斯图像融合方法,将牙齿模型对应的2d图像融合至合成脸模型对应的2d图像中,获得融合后的合成脸图像。
在一个实施例中,如图14所示,还提供了一种人脸表情合成后的图像优化装置300,该装置还包括:
皱纹刻画模块350,用于对融合后的合成脸图像进行皱纹刻画。
在一个实施例中,如图15所示,皱纹刻画模块350包括皱纹区域获取模块352及泊松图像克隆模块354。
皱纹区域获取模块352,用于从表情转移后的3d合成脸模型对应的源图像中,获取皱纹区域,源图像中包含转移的表情。
泊松图像克隆模块354,用于通过泊松图像克隆将皱纹区域中的皱纹克隆至融合后的合成脸图像上。
在一个实施例中,还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现以下步骤:制作3d牙齿模型;获取表情转移后的3d合成脸模型;对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐;将牙齿模型转换为2d图像,将合成脸模型转换为2d图像,将牙齿模型对应的2d图像融合至合成脸模型对应的2d图像中,获得融合后的合成脸图像。
在一个实施例中,上述程序被处理器执行时还实现以下步骤:扫描人物牙齿部分和口腔部分,获得牙齿部分和口腔部分扫描结果图;对扫描结果图进行特征点定位;对经过特征点定位后的扫描结果图进行3d建模,得到3d牙齿模型。
在一个实施例中,上述程序被处理器执行时还实现以下步骤:通过计算放缩因子、平移参数及旋转因子来对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐。
在一个实施例中,上述程序被处理器执行时还实现以下步骤:采用拉普拉斯图像融合方法,将牙齿模型对应的2d图像融合至合成脸模型对应的2d图像中,获得融合后的合成脸图像。
在一个实施例中,上述程序被处理器执行时还实现以下步骤:对融合后的合成脸图像进行皱纹刻画。
在一个实施例中,上述程序被处理器执行时还实现以下步骤:从表情转移后的3d合成脸模型对应的源图像中,获取皱纹区域,源图像中包含转移的表情;通过泊松图像克隆将皱纹区域中的皱纹克隆至融合后的合成脸图像上。
在一个实施例中,还提供了一种计算机设备,该计算机设备包括存储器,处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现以下步骤:制作3d牙齿模型;获取表情转移后的3d合成脸模型;对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐;将牙齿模型转换为2d图像,将合成脸模型转换为2d图像,将牙齿模型对应的2d图像融合至合成脸模型对应的2d图像中,获得融合后的合成脸图像。
在一个实施例中,上述处理器执行计算机程序时还实现以下步骤:扫描人物牙齿部分和口腔部分,获得牙齿部分和口腔部分扫描结果图;对扫描结果图进行特征点定位;对经过特征点定位后的扫描结果图进行3d建模,得到3d牙齿模型。
在一个实施例中,上述处理器执行计算机程序时还实现以下步骤:通过计算放缩因子、平移参数及旋转因子来对牙齿模型进行变换操作,使得经过变换操作后的牙齿模型与合成脸模型对齐。
在一个实施例中,上述处理器执行计算机程序时还实现以下步骤:采用拉普拉斯图像融合方法,将牙齿模型对应的2d图像融合至合成脸模型对应的2d图像中,获得融合后的合成脸图像。
在一个实施例中,上述处理器执行计算机程序时还实现以下步骤:对融合后的合成脸图像进行皱纹刻画。
在一个实施例中,上述处理器执行计算机程序时还实现以下步骤:从表情转移后的3d合成脸模型对应的源图像中,获取皱纹区域,源图像中包含转移的表情;通过泊松图像克隆将皱纹区域中的皱纹克隆至融合后的合成脸图像上。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,程序可存储于一非易失性的计算机可读取存储介质中,如本发明实施例中,该程序可存储于计算机系统的存储介质中,并被该计算机系统中的至少一个处理器执行,以实现包括如上述各方法的实施例的流程。其中,存储介质可为磁碟、光盘、只读存储记忆体(read-onlymemory,rom)或随机存储记忆体(randomaccessmemory,ram)等。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!