一种语料库生成方法、装置、设备和计算机存储介质与流程
本发明涉及计算机领域中的种子语料库生成技术,尤其涉及一种语料库生成方法、装置、设备和计算机存储介质。
背景技术:
目前,预料库中的数据都是具有分类的,但是在获取这些具有分类的训练数据的难度较大。现有的获取分类数据的实现方案主要包括以下三种方式:一种是通过抓取已有网站的带有分类的数据;一种是通过对现有无分类数据进行人工标注;还有一种是通过关键词在搜索引擎中搜索和抓取。
但是,现有的获取分类数据的方案得到的分类数据的类别覆盖不全质量参差不齐,并且分类数据的纯度比较低,进而会影响得到的分类数据的准确率。
技术实现要素:
为解决上述技术问题,本发明实施例期望提供一种语料库生成方法、装置、设备和计算机存储介质,解决了现有的分类技术得到的分类数据类覆盖不全的问题,扩展了分类数据的覆盖范围,提高了分类数据的质量和准确率;同时,保证了分类数据的纯度。
本发明实施例的技术方案是这样实现的:
第一方面,提供一种语料库生成方法,所述方法包括:
从待处理信息库中确定第一媒体;其中,所述第一媒体为所述待处理信息库中评分大于第一阈值的媒体;
基于所述第一媒体和所述第一媒体对应的文本,生成第一种子语料;
采用预设算法对所述待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选,生成第二种子语料;其中,所述第二种子语料中包括至少一个种子语料;
基于所述第一种子语料和所述第二种子语料生成基准分类模型;
基于所述第一种子语料和所述第二种子语料从所述待处理信息库中获取增量文本,并采用所述基准分类模型对所述增量文本进行筛选生成目标语料库。
第二方面,提供一种语料库生成装置,所述装置包括:第一确定单元、第一生成单元、第二生成单元、第三生成单元和处理单元,其中:
所述第一确定单元,用于从待处理信息库中确定第一媒体;其中,所述第一媒体为所述待处理信息库中评分大于第一阈值的媒体;
所述第一生成单元,用于基于所述第一媒体和所述第一媒体对应的文本,生成第一种子语料;
所述第二生成单元,用于采用预设算法对所述待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选,生成第二种子语料;其中,所述第二种子语料中包括至少一个种子语料;
所述第三生成单元,用于基于所述第一种子语料和所述第二种子语料生成基准分类模型;
所述处理单元,用于基于所述第一种子语料和所述第二种子语料从所述待处理信息库中获取增量文本,并采用所述基准分类模型对所述增量文本进行筛选生成目标语料库。
第三方面,提供一种语料库生成设备,所述设备包括:处理器和存储器,其中:
所述处理器,用于从所述存储器中存储的待处理信息库中确定第一媒体;其中,所述第一媒体为所述待处理信息库中评分大于第一阈值的媒体;基于所述第一媒体和所述第一媒体对应的文本,生成第一种子语料;采用预设算法对所述待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选,生成第二种子语料;其中,所述第二种子语料中包括至少一个种子语料;基于所述第一种子语料和所述第二种子语料生成基准分类模型;基于所述第一种子语料和所述第二种子语料从所述待处理信息库中获取增量文本,并采用所述基准分类模型对所述增量文本进行筛选生成目标语料库。
第四方面,提供一种计算机可读存储介质,所述计算机可读存储介质中存储有一个或多个计算机程序,该计算机程序被处理器执行时实现第一方面所述方法的步骤。
本发明实施例所提供的语料库生成方法、装置、设备和计算机存储介质,从待处理信息库中确定第一媒体,基于第一媒体和第一媒体对应的文本,生成第一种子语料;采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选生成第二种子语料,基于第一种子语料和第二种子语料生成基准分类模型,之后基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库;这样,用于生成预料库的服务器可以自动根据生成的至少两个种子语料,对需要分类的文本进行分类筛选,最终得到具有分类数据的预料库,而不是直接采用生成种子语料的方法来得到语料库,解决了现有的分类技术得到的分类数据类覆盖不全的问题,扩展了分类数据的覆盖范围,提高了分类数据的质量和准确率;同时,保证了分类数据的纯度。
附图说明
图1为本发明的实施例提供的一种语料库生成方法的流程示意图;
图2为本发明的实施例提供的一种给用户推荐信息的示意图;
图3为本发明的实施例提供的另一种给用户推荐信息的示意图;
图4为本发明的实施例提供的一种语料库生成装置的结构示意图;
图5为本发明的实施例提供的一种语料库生成设备的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
本发明的实施例提供一种语料库生成方法,参照图1所示,该方法包括以下步骤:
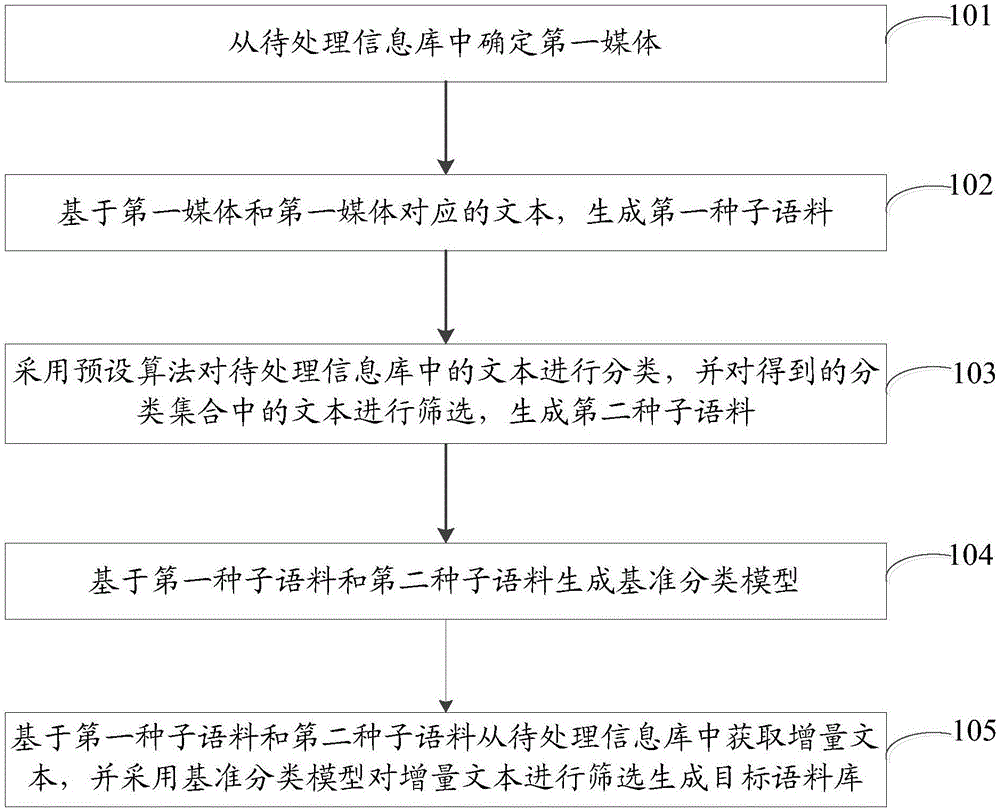
步骤101、从待处理信息库中确定第一媒体。
其中,第一媒体为待处理信息库中评分大于第一阈值的媒体。
步骤101从待处理信息库中确定第一媒体可以是由语料库生成装置来实现的;语料库生成装置可以是用于训练数据生成语料库的一种服务器,待处理信息库可以是用于训练生成语料库的一种数据库;例如,待处理信息库可以是各个媒体对应的历史文本库。从待处理信息库中确定第一媒体可以是通过在各个媒体对应的历史文本库中获取评分大于第一阈值的媒体来实现的;媒体的评分可以是根据媒体的等级来确定的,媒体的等级可以是根据媒体发布的文本的质量、用户对其的喜爱度、发布的文本的数量、媒体发布的文本类别(类别是否专一)、用心程度等因素来综合评定的。第一阈值可以是根据实际的应用场景和历史数据设定的能够保证评定的媒体的纯度的数值。
步骤102、基于第一媒体和第一媒体对应的文本,生成第一种子语料。
其中,步骤102基于第一媒体和第一媒体对应的文本,生成第一种子语料可以是由语料库生成装置来实现的;可以获取第一媒体中的关键词,然后根据该关键词从第一媒体对应的额文本中获取第一种子语料。
步骤103、采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选,生成第二种子语料。
其中,第二种子语料中包括至少一个种子语料。
在本发明的其它实施例中,步骤103采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选,生成第二种子语料可以是由语料库生成装置来实现的;预设算法可以是预先设定的用于对文本进行归类并生成种子语料的一种算法。若第二种子语料中包括有至少两种种子语料时,生成这两种种子语料的算法是不同的。
步骤104、基于第一种子语料和第二种子语料生成基准分类模型。
其中,步骤104基于第一种子语料和第二种子语料生成基准分类模型可以是由语料库生成装置来实现的。
步骤105、基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库。
其中,步骤105基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库可以是由语料库生成装置来实现的;增量文本可以根据第一种子语料和第二种子语料从各个媒体对应的历史文本库中获取得到,目标语料库可以采用得到的基准分类模型对增量文本进行分类后筛选来得到。
本发明的实施例所提供的语料库生成方法,从待处理信息库中确定第一媒体,基于第一媒体和第一媒体对应的文本,生成第一种子语料;采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选生成第二种子语料,基于第一种子语料和第二种子语料生成基准分类模型,之后基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库;这样,用于生成预料库的服务器可以自动根据生成的至少两个种子语料,对需要分类的文本进行分类筛选,最终得到具有分类数据的预料库,而不是直接采用生成种子语料的方法来得到语料库,解决了现有的分类技术得到的分类数据类覆盖不全的问题,扩展了分类数据的覆盖范围,提高了分类数据的质量和准确率;同时,保证了分类数据的纯度。
基于前述实施例,本发明的实施例提供一种语料库生成方法,该方法包括以下步骤:
步骤201、语料库生成装置从待处理信息库中确定第一媒体。
其中,第一媒体为待处理信息库中评分大于第一阈值的媒体。
需要说明的是,确定的第一媒体可以包括至少一种媒体。
步骤202、语料库生成装置从第一媒体中确定类别为第一类别的媒体,得到第二媒体。
其中,第一类别为预先设定的需要查找与之对应的文本的类别,可以包括一种也可以包括多种,具体可以是根据实际的应用场景和历史经验值来设定。第二媒体可以从各个媒体对应的历史文本库中获取类别与第一类别相同的媒体来得到。
步骤203、语料库生成装置确定与第一类别具有关联关系的关键词。
其中,关键词可以是从各个媒体对应的历史文本库中确定的与第一类别相关的词;若第一类别可以是娱乐类,那么关键词可以是与娱乐类相关的词,例如关键词可以包括:明星的名字、狗仔、八卦、电影节、影视剧的剧名、晚会、粉丝等。若第一类别可以是科技类,那么关键词可以是与科技类相关的词,例如关键词可以包括:发明、机器人、通信、卫星等。
步骤204、语料库生成装置基于关键词在第二媒体对应的文本中,筛选与关键词具有关联关系的文本,生成第一种子语料。
其中,语料库生成装置可以在确定出来的第二媒体对应的历史文本中筛选与包括有确定的关键词的文本,进而将在同一类别下的关键词对应的文本确定为一类,最终得到第一种子语料;第一种子语料中可以包括一种类别的文本,也可以包括多种类别的文本,但是第一种子语料中的文本是具有分类的文本。
步骤205、语料库生成装置采用第一算法对待处理信息库中的文本进行分类,并对得到的第一分类集合中的文本进行筛选,生成第一子种子语料。
其中,第一算法可以是用于对各个媒体对应的历史文本库中的文本进行分类的一种算法;第一子种子语料可以是对分类后的文本集合中的文本进行筛选后得到的。
步骤206、语料库生成装置采用第二算法对待处理信息库中的文本进行分类,并对得到的第二分类集合中的文本进行筛选,生成第二子种子语料。
其中,第二算法可以是用于对各个媒体对应的历史文本库中的文本进行分类的一种算法;第二子种子语料可以是对分类后的文本集合中的文本进行筛选后得到的。第二算法与第一算法不同,第一分类集合与第二分类集合不同。
步骤207、语料库生成装置将第一种子语料、第一子种子语料和第二子种子语料合并,得到语料集合。
步骤208、语料库生成装置采用第三算法对语料集合进行处理,得到基准分类模型。
其中,第三算法可以是用于得到分类模型的一种算法;例如第三算法可以是逻辑回归(logisticregression,lr)算法;基准分类模型可以是采用lr算法对语料集合进行训练后得到的;当然,可以将基准分类模型记为分类器-a。
步骤209、语料库生成装置分别对第一种子语料、第一子种子语料和第二子种子语料对应的文本进行标注。
其中,对第一种子语料、第一子种子语料和第二子种子语料对应的文本进行标注可以是通过第一种子语料、第一子种子语料和第二子种子语料进行标记来实现的。
需要说明的是,在本发明的其它实施例中,若第二种子语料包括第一子种子语料,语料集合可以是将第一种子语料和第一子种子语料合并得到的;如果第二种子语料包括第二子种子语料,语料集合可以是将第一种子语料和第二子种子语料合并得到的;当然,后续在进行语料标注的时候,如果语料集合是将第一种子语料和第一子种子语料合并得到的,那么需要对第一种子语料和第一子种子语料对应的文本进行标注;如果语料集合是将第一种子语料和第二子种子语料合并得到的,那么需要对第一种子语料和第二子种子语料对应的文本进行标注。
当然,在本发明的其它实施例中,第二种子语料也可以包括至少三种子种子语料。其中,第二种子语料包括的子种子语料越多,最终生成的目标语料库的数据越准确。在具体的应用场景中,可以根据实际的需求确定第二种子语料中包括的子种子语料的数量。
步骤210、语料库生成装置从待处理信息库中获取未标注文本,并采用预设规则对未标注文本进行标注得到增量文本。
其中,预设规则可以是用于对各个媒体对应的历史文本库中的文本中没有标注的文本进行标注的一种规则。
步骤211、语料库生成装置采用基准分类模型对增量文本进行筛选,生成目标语料库。
其中,得到增量文本后,语料库生成装置可以根据基准分类模型对增量文本进行分类,然后从得到的分类后的增量文本中筛选符合一定要求的文本进而得到这个类别下的文本;最终得到的目标语料库中可以包括一种类别也可以包括多种类别,并且目标语料库中的文本都是具有分类的文本。
需要说明的是,本实施例中与其他实施例中相同步骤或相关概念的解释可以参照其他实施例中的描述,此处不再赘述。
本发明的实施例所提供的语料库生成方法,从待处理信息库中确定第一媒体,基于第一媒体和第一媒体对应的文本,生成第一种子语料;采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选生成第二种子语料,基于第一种子语料和第二种子语料生成基准分类模型,之后基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库;这样,用于生成预料库的服务器可以自动根据生成的至少两个种子语料,对需要分类的文本进行分类筛选,最终得到具有分类数据的预料库,而不是直接采用生成种子语料的方法来得到语料库,解决了现有的分类技术得到的分类数据类覆盖不全的问题,扩展了分类数据的覆盖范围,提高了分类数据的质量和准确率;同时,保证了分类数据的纯度。
基于前述实施例,本发明的实施例提供一种语料库生成方法,该方法包括以下步骤:
步骤301、语料库生成装置从待处理信息库中确定第一媒体。
其中,第一媒体为待处理信息库中评分大于第一阈值的媒体。
步骤302、语料库生成装置从第一媒体中确定类别为第一类别的媒体,得到第二媒体。
步骤303、语料库生成装置确定与第一类别具有关联关系的关键词。
步骤304、语料库生成装置基于关键词在第二媒体对应的文本中,筛选与关键词具有关联关系的文本,生成第一种子语料。
步骤305、语料库生成装置采用预设分类模型对待处理信息库中的文本进行分类,得到第一分类集合。
其中,预设分类模型可以是用于对文本进行聚类的一种模型,例如预设分类模型可以包括文档主题生成模型(latentdirichletallocation,lda)。第一分类集合可以是采用lda对各个媒体对应的历史文本库中的文本进行分类后得到的,第一分类集合中可以包括多种类别,每种类别中包括有与之对应的文本。
步骤306、语料库生成装置基于第一类别,从第一分类集合中获取与第一类别具有关联关系的第一文本。
其中,得到第一分类集合后,语料库生成装置可以从第一分类集合中的每个类别的文本中获取类别属于第一类别的文本,最终得到第一文本。
步骤307、语料库生成装置获取第一文本中权重值大于第二阈值的文本,生成第一子种子语料。
其中,在使用预设分类模型即lda模型对各个媒体对应的历史文本库中的文本进行分类得到第一分类集合后,第一分类集合中每个类别对应的文本都会生成各自的权重值;第二阈值是预先设定的能够筛选出与第一类别的类别最接近的文本的数值。
步骤308、语料库生成装置采用预设转换模型将待处理信息库中的文本进行转换,得到词向量。
其中,预设转换模型是用于将文本转换成向量的一种模型,示例性的预设转换模型可以是word2vec。
步骤309、语料库生成装置采用预设处理方法对词向量进行计算,并基于计算结果对词向量进行分类得到第二分类集合。
其中,预设处理方法可以是用于得到每个词向量之间的关系的一种方法,示例性的,可以是计算两个词向量之间的夹角或者计算两个词向量之间的距离;之后,可以根据词向量之间的夹角或者词向量之间的距离确定两个词向量是否属于同一类别,最终对词向量进行分类得到第二分类集合。具体可以是根据词向量之间的夹角与预设角度阈值,或者词向量之间的距离或者预设距离阈值之间的关系来确定的。
步骤310、语料库生成装置计算第二分类集合中每个类别中的每个文本的权重值。
其中,权重值可以是根据第二分类集合的每个类别中的文本与当前所属类别的文本之间的关系计算得到的,例如可以是根据词向量之间的夹角或者词向量之间的距离的大小关系计算得到的。
步骤311、语料库生成装置从第二分类集合中获取与第一类别具有关联关系的第二文本,并从第二文本中获取权重值大于第三阈值的文本,生成第二子种子语料。
其中,第二文本可以从第二分类集合中的每个类别的文本中获取类别属于第一类别的文本后得到的;第三阈值是预先设定的能够筛选出与第一类别的类别最接近的文本的数值,第二阈值与第三阈值可以不同
步骤312、语料库生成装置将第一种子语料、第一子种子语料和第二子种子语料合并,得到语料集合。
步骤313、语料库生成装置采用第三算法对语料集合进行处理,得到基准分类模型。
步骤314、语料库生成装置分别对第一种子语料、第一子种子语料和第二子种子语料对应的文本进行标注。
示例性的,可以将第一种子语料标记为语料-media+keywords,可以将第一子种子语料标记为语料-lda,可以将第二子种子语料标记为语料-word2vec。
步骤315、语料库生成装置从待处理信息库中获取未标注文本,并采用预设规则对未标注文本进行标注得到增量文本。
步骤316、语料库生成装置采用基准分类模型对增量文本进行筛选,生成目标语料库。
需要说明的是,本实施例中与其他实施例中相同步骤或相关概念的解释可以参照其他实施例中的描述,此处不再赘述。
本发明的实施例所提供的语料库生成方法,从待处理信息库中确定第一媒体,基于第一媒体和第一媒体对应的文本,生成第一种子语料;采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选生成第二种子语料,基于第一种子语料和第二种子语料生成基准分类模型,之后基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库;这样,用于生成预料库的服务器可以自动根据生成的至少两个种子语料,对需要分类的文本进行分类筛选,最终得到具有分类数据的预料库,而不是直接采用生成种子语料的方法来得到语料库,解决了现有的分类技术得到的分类数据类覆盖不全的问题,扩展了分类数据的覆盖范围,提高了分类数据的质量和准确率;同时,保证了分类数据的纯度。
基于前述实施例,本发明的实施例提供一种语料库生成方法,该方法包括以下步骤:
步骤401、语料库生成装置从待处理信息库中确定第一媒体。
其中,第一媒体为待处理信息库中评分大于第一阈值的媒体。
步骤402、语料库生成装置从第一媒体中确定类别为第一类别的媒体,得到第二媒体。
步骤403、语料库生成装置确定与第一类别具有关联关系的关键词。
步骤404、语料库生成装置基于关键词在第二媒体对应的文本中,筛选与关键词具有关联关系的文本,生成第一种子语料。
步骤405、语料库生成装置采用预设分类模型对待处理信息库中的文本进行分类,得到第一分类集合。
步骤406、语料库生成装置基于第一类别,从第一分类集合中获取与第一类别具有关联关系的第一文本。
步骤407、语料库生成装置获取第一文本中权重值大于第二阈值的文本,生成第一子种子语料。
步骤408、语料库生成装置采用预设转换模型将待处理信息库中的文本进行转换,得到词向量。
步骤409、语料库生成装置采用预设处理方法对词向量进行计算,并基于计算结果对词向量进行分类得到第二分类集合。
步骤410、语料库生成装置计算第二分类集合中每个类别中的每个文本的权重值。
步骤411、语料库生成装置从第二分类集合中获取与第一类别具有关联关系的第二文本,并从第二文本中获取权重值大于第三阈值的文本,生成第二子种子语料。
步骤412、语料库生成装置将第一种子语料、第一子种子语料和第二子种子语料合并,得到语料集合。
步骤413、语料库生成装置采用第三算法对语料集合进行处理,得到基准分类模型。
步骤414、语料库生成装置分别对第一种子语料、第一子种子语料和第二子种子语料对应的文本进行标注。
步骤415、语料库生成装置基于待处理信息库中的文本构建第一模型。
其中,第一模型是封闭的,第一模型中包括节点。
在本发明的其它实施例中,第一模型可以是图;语料库生成装置可以是以各个媒体对应的历史文本库中的每一个文本为节点,将节点连接起来进而得到一个封闭的图。当然,每个节点中可以包括多个数据点,数据点可以包括:媒体、标题、文章中的词、类别等内容。
步骤416、语料库生成装置计算第一模型中相邻的两个节点之间的边的权重。
其中,边的权重可以是根据两个节点对应的文本的相似度来生成的;两个文本的相似度可以根据文本的内容、文本的出处、文本的主题等因素来确定。
步骤417、语料库生成装置基于第一模型中的每个边的权重计算每个节点的转移概率。
其中,每个节点的转移概率指的是一个节点转移到另一个节点的概率;示例性的节点i到节点j的转移概率pij可以是用节点i与节点j之间的边的权重值除以图中所有边的权重值的和得到的。
步骤418、语料库生成装置基于每个节点的id号、每个边的权重和节点构建第一转移矩阵。
第一转移矩阵可以是按照每个节点(每个文本)的id号的顺序,将每个边的权重值作为基本元素得到的。
步骤419、语料库生成装置从第一转移矩阵中获取未标注元素得到未标注文本。
其中,第一转移矩阵中未标注的元素就是第一转移矩阵的所有元素中除与第一种子语料、第一子种子语料和第二子种子语料相关的元素之外的元素。
步骤420、语料库生成装置基于每个节点的转移概率,采用预设规则对未标注文本进行标注得到增量文本。
其中,步骤420基于每个节点的转移概率,采用预设规则对未标注文本进行标注得到增量文本可以通过以下方式来实现:
a、将每个节点的转移概率与第一转移矩阵中的对应元素相乘,得到第二转移矩阵;
其中,第二转移矩阵中的元素的值是第一转移矩阵中的元素的值乘以对应的概率。
b、计算第二转移矩阵中未标注元素的值与标注元素的值的差值。
c、基于差值与预设阈值之间的关系对未标注元素进行标注;
其中,如果第二转移矩阵中未标注元素的值与标注元素的值的差值在预设阈值范围内,那么将未标注元素标记为与其差值在预设阈值范围内的标注元素的标注相同的标注。
d、若第二矩阵中的标注元素数量未达到预设数值,将每个节点的转移概率与所述第二转移矩阵中的对应元素相乘得到第三转移矩阵,并根据第三转移矩阵中未标注元素的值与标注元素的值的差值与预设阈值的关系对未标注元素进行标注,直到标注元素数量达到预设数值;
其中,将第二转移矩阵中的元素进行标注之后,如果标注元素数量达到预设数值,直接将已经标注元素对应的文本确定为增量文本;如果标注元素数量没有达到与预设数值,将每个节点的转移概率与第二转移矩阵中的对应元素相乘得到第三转移矩阵,之后计算第三转移矩阵中未标注元素的值与标注元素的值的差值并根据该差值与预设阈值的关系对未标注元素进行标注;继续判断第三转移矩阵中标注元素的数量是否达到预设数值,如果第三矩阵中标注元素数量没有达到与预设数值,将每个节点的转移概率与第三转移矩阵中的对应元素相乘得到第四转移矩阵,之后计算第四转移矩阵中未标注元素的值与标注元素的值的差值并根据该差值与预设阈值的关系对未标注元素进行标注;如果第四转移矩阵中标注元素的数量仍然未达到预设数量,则继续将每个节点的转移概率与第三转移矩阵中的对应元素相乘得到第五转移矩阵,直到转移矩阵中标注元素的数量达到预设数量。
e、确定标注元素对应的文本为增量文本。
步骤420、语料库生成装置采用基准分类模型对增量文本进行筛选,生成目标语料库。
得到增量文本后,先从增量文本中的文本筛选一定数量的文本后,采用基准分类模型对筛选出来的文本进行分类,得到目标语料库;其中,目标语料库中的文本是具有分类的文本。
需要说明的是,本实施例中与其他实施例中相同步骤或相关概念的解释可以参照其他实施例中的描述,此处不再赘述。
本发明的实施例所提供的语料库生成方法,从待处理信息库中确定第一媒体,基于第一媒体和第一媒体对应的文本,生成第一种子语料;采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选生成第二种子语料,基于第一种子语料和第二种子语料生成基准分类模型,之后基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库;这样,用于生成预料库的服务器可以自动根据生成的至少两个种子语料,对需要分类的文本进行分类筛选,最终得到具有分类数据的预料库,而不是直接采用生成种子语料的方法来得到语料库,解决了现有的分类技术得到的分类数据类覆盖不全的问题,扩展了分类数据的覆盖范围,提高了分类数据的质量和准确率;同时,保证了分类数据的纯度。
需要说明的是,上述实施例中的文本可以包括文章;示例性的,以给用户推荐新闻为例进行说明,如果用户平常比较感兴趣的新闻是关于科技的新闻,那么推荐给用户的新闻就是关于科技的新闻;如图2中所示为采用现有方案中的分类技术生成的语料库从给用户推荐的新闻,但是推荐的新闻中关于“中国科技大学2017年优秀大学生夏令营开营”的新闻a1不属于科技类新闻。因为现有的语料库是通过关键词检索得到的,如果检索得到类别为科技类的文章的关键词是“科技”,因为关于“中国科技大学2017年优秀大学生夏令营开营”的文章中包括关键词“科技”,因此就误将该文章归为科技类文章,进而导致最终推荐给用户的新闻不准确。如图3所示,在采用本发明实施例中提供的语料库生成方法生成的语料库中推荐给用户的新闻a2、b、c和d全部都是科技类新闻,推荐的信息比较准确。
基于前述实施例,本发明的实施例提供一种语料库生成装置5,该装置5可以应用于上述实施例提供的一种语料库生成方法中,参照图4所示,该装置包括:第一确定单元51、第一生成单元52、第二生成单元53、第三生成单元54和处理单元55,其中:
第一确定单元51,用于从待处理信息库中确定第一媒体;
其中,第一媒体为待处理信息库中评分大于第一阈值的媒体;
第一生成单元52,用于基于第一媒体和第一媒体对应的文本,生成第一种子语料;
第二生成单元53,用于采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选,生成第二种子语料;
其中,第二种子语料中包括至少一个种子语料;
第三生成单元54,用于基于第一种子语料和第二种子语料生成基准分类模型;
处理单元55,用于基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库。
本发明的实施例所提供的语料库生成装置,从待处理信息库中确定第一媒体,基于第一媒体和第一媒体对应的文本,生成第一种子语料;采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选生成第二种子语料,基于第一种子语料和第二种子语料生成基准分类模型,之后基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库;这样,用于生成预料库的服务器可以自动根据生成的至少两个种子语料,对需要分类的文本进行分类筛选,最终得到具有分类数据的预料库,而不是直接采用生成种子语料的方法来得到语料库,解决了现有的分类技术得到的分类数据类覆盖不全的问题,扩展了分类数据的覆盖范围,提高了分类数据的质量和准确率;同时,保证了分类数据的纯度。
基于前述实施例,在本发明的其它实施例中,第一生成单元包括:第一获取模块和第一生成模块,其中:
第一获取模块,用于从第一媒体中确定类别为第一类别的媒体,得到第二媒体;
第一获取模块,还用于确定与第一类别具有关联关系的关键词;
第一生成模块,用于基于关键词在第二媒体对应的文本中,筛选与关键词具有关联关系的文本,生成第一种子语料。
基于前述实施例,在本发明的其它实施例中,第二生成单元包括:第二生成模块和第三生成模块,其中:
第二生成模块,用于采用第一算法对待处理信息库中的文本进行分类,并对得到的第一分类集合中的文本进行筛选,生成第一子种子语料;
第三生成模块,用于采用第二算法对待处理信息库中的文本进行分类,并对得到的第二分类集合中的文本进行筛选,生成第二子种子语料。
基于前述实施例,在本发明的其它实施例中,第二生成模块具体用于执行以下步骤:
采用预设分类模型对待处理信息库中的文本进行分类,得到第一分类集合;
基于第一类别,从第一分类集合中获取与第一类别具有关联关系的第一文本;
获取第一文本中权重值大于第二阈值的文本,生成第一子种子语料。
基于前述实施例,在本发明的其它实施例中,第三生成模块具体用于执行以下步骤:
采用预设转换模型将待处理信息库中的文本进行转换,得到词向量;
采用预设处理方法对词向量进行计算,并基于计算结果对词向量进行分类得到第二分类集合;
计算第二分类集合中每个类别中的每个文本的权重值;
从第二分类集合中获取与第一类别具有关联关系的第二文本,并从第二文本中获取权重值大于第三阈值的文本,生成第二子种子语料。
进一步,第三生成单元包括:第二获取模块和第一处理模块,其中:
第二获取模块,用于将第一种子语料、第一子种子语料和第二子种子语料合并,得到语料集合;
第一处理模块,用于采用第三算法对语料集合进行处理,得到基准分类模型。
进一步,处理单元包括:第二处理模块、第三处理模块和筛选模块,其中:
第二处理模块,用于分别对第一种子语料、第一子种子语料和第二子种子语料对应的文本进行标注;
第三处理模块,用于从待处理信息库中获取未标注文本,并采用预设规则对未标注文本进行标注得到增量文本;
筛选模块,用于采用基准分类模型对增量文本进行筛选,生成目标语料库。
基于前述实施例,在本发明的其它实施例中,第三处理模块具体还用于执行以下步骤:
基于待处理信息库中的文本构建第一模型;
其中,第一模型是封闭的,第一模型中包括节点;
计算第一模型中相邻的两个节点之间的边的权重;
基于第一模型中的每个边的权重计算每个节点的转移概率;
基于每个节点的id号、每个边的权重和节点构建第一转移矩阵;
从第一转移矩阵中获取未标注元素得到未标注文本;
基于每个节点的转移概率,采用预设规则对未标注文本进行标注得到增量文本。
基于前述实施例,在本发明的其它实施例中,第三处理模块具体还用于执行以下步骤:
将每个节点的转移概率与第一转移矩阵中的对应元素相乘,得到第二转移矩阵;
计算第二转移矩阵中未标注元素的值与标注元素的值的差值;
基于差值与预设阈值之间的关系对未标注元素进行标注,得到增量文本。
需要说明的是,本实施例中各个单元和模块之间的交互过程,可以参照前述实施例提供的一种语料库生成方法中的交互过程,此处不再赘述。
本发明的实施例所提供的语料库生成装置,从待处理信息库中确定第一媒体,基于第一媒体和第一媒体对应的文本,生成第一种子语料;采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选生成第二种子语料,基于第一种子语料和第二种子语料生成基准分类模型,之后基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库;这样,用于生成预料库的服务器可以自动根据生成的至少两个种子语料,对需要分类的文本进行分类筛选,最终得到具有分类数据的预料库,而不是直接采用生成种子语料的方法来得到语料库,解决了现有的分类技术得到的分类数据类覆盖不全的问题,扩展了分类数据的覆盖范围,提高了分类数据的质量和准确率;同时,保证了分类数据的纯度。
基于前述实施例,本发明的实施例提供一种语料库生成设备6,该设备可以应用于上述实施例提供的一种语料库生成方法中,参照图5所示,该设备可以包括:处理器61、存储器62和通信接口63,处理器62存在于处理组件64中,其中:
通信接口63,用于实现处理器61与存储器62之间的通信连接;
处理器61,用于从存储器中存储的待处理信息库中确定第一媒体;其中,第一媒体为待处理信息库中评分大于第一阈值的媒体;基于第一媒体和第一媒体对应的文本,生成第一种子语料;采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选,生成第二种子语料;其中,第二种子语料中包括至少一个种子语料;基于第一种子语料和第二种子语料生成基准分类模型;基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库。
在本发明的其它实施例中,处理器61还用于执行以下步骤:
从第一媒体中确定类别为第一类别的媒体,得到第二媒体;
确定与第一类别具有关联关系的关键词;
基于关键词在第二媒体对应的文本中,筛选与关键词具有关联关系的文本,生成第一种子语料。
在本发明的其它实施例中,处理器61还用于执行以下步骤:
采用第一算法对待处理信息库中的文本进行分类,并对得到的第一分类集合中的文本进行筛选,生成第一子种子语料;
采用第二算法对待处理信息库中的文本进行分类,并对得到的第二分类集合中的文本进行筛选,生成第二子种子语料。
在本发明的其它实施例中,处理器61还用于执行以下步骤:
采用预设分类模型对待处理信息库中的文本进行分类,得到第一分类集合;
基于第一类别,从第一分类集合中获取与第一类别具有关联关系的第一文本;
获取第一文本中权重值大于第二阈值的文本,生成第一子种子语料。
在本发明的其它实施例中,处理器61还用于执行以下步骤:
采用预设转换模型将待处理信息库中的文本进行转换,得到词向量;
采用预设处理方法对词向量进行计算,并基于计算结果对词向量进行分类得到第二分类集合;
计算第二分类集合中每个类别中的每个文本的权重值;
从第二分类集合中获取与第一类别具有关联关系的第二文本,并从第二文本中获取权重值大于第三阈值的文本,生成第二子种子语料。
在本发明的其它实施例中,处理器61还用于执行以下步骤:
将第一种子语料、第一子种子语料和第二子种子语料合并,得到语料集合;
采用第三算法对语料集合进行处理,得到基准分类模型。
在本发明的其它实施例中,处理器61还用于执行以下步骤:
分别对第一种子语料、第一子种子语料和第二子种子语料对应的文本进行标注;
从待处理信息库中获取未标注文本,并采用预设规则对未标注文本进行标注得到增量文本;
采用基准分类模型对增量文本进行筛选,生成目标语料库。
在本发明的其它实施例中,处理器61还用于执行以下步骤:
基于待处理信息库中的文本构建第一模型;
其中,第一模型是封闭的,第一模型中包括节点;
计算第一模型中相邻的两个节点之间的边的权重;
基于第一模型中的每个边的权重计算每个节点的转移概率;
基于每个节点的id号、每个边的权重和节点构建第一转移矩阵;
从第一转移矩阵中获取未标注元素得到未标注文本;
基于每个节点的转移概率,采用预设规则对未标注文本进行标注得到增量文本。
在本发明的其它实施例中,处理器61还用于执行以下步骤:
将每个节点的转移概率与第一转移矩阵中的对应元素相乘,得到第二转移矩阵;
计算第二转移矩阵中未标注元素的值与标注元素的值的差值;
基于差值与预设阈值之间的关系对未标注元素进行标注,得到增量文本。
需要说明的是,本实施例中各个器件之间的交互过程,可以参照前述实施例提供的语料库生成方法中的交互过程,此处不再赘述。
本发明的实施例所提供的语料库生成设备,从待处理信息库中确定第一媒体,基于第一媒体和第一媒体对应的文本,生成第一种子语料;采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选生成第二种子语料,基于第一种子语料和第二种子语料生成基准分类模型,之后基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库;这样,用于生成预料库的服务器可以自动根据生成的至少两个种子语料,对需要分类的文本进行分类筛选,最终得到具有分类数据的预料库,而不是直接采用生成种子语料的方法来得到语料库,解决了现有的分类技术得到的分类数据类覆盖不全的问题,扩展了分类数据的覆盖范围,提高了分类数据的质量和准确率;同时,保证了分类数据的纯度。
基于前述实施例,本发明的实施例提供一种计算机可读存储介质,该计算机可读存储介质中存储有一个或多个计算机程序,该计算机程序被处理器执行时实现以下步骤:
从存储器中存储的待处理信息库中确定第一媒体;其中,第一媒体为待处理信息库中评分大于第一阈值的媒体;基于第一媒体和第一媒体对应的文本,生成第一种子语料;采用预设算法对待处理信息库中的文本进行分类,并对得到的分类集合中的文本进行筛选,生成第二种子语料;其中,第二种子语料中包括至少一个种子语料;基于第一种子语料和第二种子语料生成基准分类模型;基于第一种子语料和第二种子语料从待处理信息库中获取增量文本,并采用基准分类模型对增量文本进行筛选生成目标语料库。
进一步,该计算机程序被处理器执行时还可以实现以下步骤:
从第一媒体中确定类别为第一类别的媒体,得到第二媒体;
确定与第一类别具有关联关系的关键词;
基于关键词在第二媒体对应的文本中,筛选与关键词具有关联关系的文本,生成第一种子语料。
进一步,该计算机程序被处理器执行时还可以实现以下步骤:
采用第一算法对待处理信息库中的文本进行分类,并对得到的第一分类集合中的文本进行筛选,生成第一子种子语料;
采用第二算法对待处理信息库中的文本进行分类,并对得到的第二分类集合中的文本进行筛选,生成第二子种子语料。
在本发明的其它实施例中,该计算机程序被处理器执行时还可以实现以下步骤:
采用预设分类模型对待处理信息库中的文本进行分类,得到第一分类集合;
基于第一类别,从第一分类集合中获取与第一类别具有关联关系的第一文本;
获取第一文本中权重值大于第二阈值的文本,生成第一子种子语料。
在本发明的其它实施例中,该计算机程序被处理器执行时还可以实现以下步骤:
采用预设转换模型将待处理信息库中的文本进行转换,得到词向量;
采用预设处理方法对词向量进行计算,并基于计算结果对词向量进行分类得到第二分类集合;
计算第二分类集合中每个类别中的每个文本的权重值;
从第二分类集合中获取与第一类别具有关联关系的第二文本,并从第二文本中获取权重值大于第三阈值的文本,生成第二子种子语料。
进一步,该计算机程序被处理器执行时还可以实现以下步骤:
将第一种子语料、第一子种子语料和第二子种子语料合并,得到语料集合;
采用第三算法对语料集合进行处理,得到基准分类模型。
在本发明的其它实施例中,该计算机程序被处理器执行时还可以实现以下步骤:
分别对第一种子语料、第一子种子语料和第二子种子语料对应的文本进行标注;
从待处理信息库中获取未标注文本,并采用预设规则对未标注文本进行标注得到增量文本;
采用基准分类模型对增量文本进行筛选,生成目标语料库。
在本发明的其它实施例中,该计算机程序被处理器执行时还可以实现以下步骤:
基于待处理信息库中的文本构建第一模型;
其中,第一模型是封闭的,第一模型中包括节点;
计算第一模型中相邻的两个节点之间的边的权重;
基于第一模型中的每个边的权重计算每个节点的转移概率;
基于每个节点的id号、每个边的权重和节点构建第一转移矩阵;
从第一转移矩阵中获取未标注元素得到未标注文本;
基于每个节点的转移概率,采用预设规则对未标注文本进行标注得到增量文本。
可选的,该计算机程序被处理器执行时还可以实现以下步骤:
将每个节点的转移概率与第一转移矩阵中的对应元素相乘,得到第二转移矩阵;
计算第二转移矩阵中未标注元素的值与标注元素的值的差值;
基于差值与预设阈值之间的关系对未标注元素进行标注,得到增量文本。
在实际应用中,所述第一确定单元51、第一生成单元52、第二生成单元53、第三生成单元54、处理单元55、第一获取模块、第一生成模块、第二生成模块、第三生成模块、第二获取模块、第一处理模块、第二处理模块、第三处理模块和筛选模块均可由位于无线数据发送设备中的中央处理器(centralprocessingunit,cpu)、微处理器(microprocessorunit,mpu)、数字信号处理器(digitalsignalprocessor,dsp)或现场可编程门阵列(fieldprogrammablegatearray,fpga)等实现。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!