本发明涉及网络信息处理领域,具体涉及一种社交媒体评论的情感分析方法、设备及其存储设备。
背景技术:
在新闻类社交媒体上,用户往往会就一些热门事件留下自己的评论,例如前段时间的“萨德”事件,目前的印度事件等。但用户的评论信息中可能会存在误导大众或具有威胁性的内容,类似的评论数据如果在社交媒体平台上长时间留存,可能造成不必要的舆论恐慌。因此,及时监控社交媒体平台上用户评论内容中具有威胁性或误导性的内容,并对这些内容进行快速、精确地处理就成为亟待解决的问题。
技术实现要素:
为了解决上述问题,本发明提供了一种社交媒体评论的情感分析方法、设备及其存储设备,首先通过采用python爬虫程序采集待处理数据信息,然后结合mysql数据库对采集到的数据进行预处理,最后利用贝叶斯理论训练分类器,可以有效解决上述问题。
本发明提供的技术方案是:一种社交媒体评论的情感分析方法,所述方法包括步骤:用特定程序获取用户评论信息;使用数据库处理获取的用户评论信息并将该信息分为训练集和测试集;对所述训练集和测试集分别进行预处理并提取特征词;设置情感分类等级及阈值,使用贝叶斯方法结合训练集进行训练得到分类器;用所述分类器对测试集中进行分类并输出分类结果;删除分类结果中感情分类等级低于阈值的评论。一种存储设备,所述存储设备存储指令及数据用于实现所述一种社交媒体评论的情感分析方法。一种社交媒体评论的情感分析设备,所述设备包括处理器及所述存储设备;所述处理器加载并执行所述存储设备中的指令及数据用于实现所述的一种社交媒体评论的情感分析方法。
本发明的有益效果是:本发明提供了一种社交媒体评论的情感分析方法、设备及其存储设备,能够及时发现社交平台中具有威胁性导向的用户评论。同时,还可以做到在发现后对威胁性用户评论进行快速、精确地处理,并定位威胁性评论的id。
附图说明
图1是本发明实施例中社交媒体评论的情感分析方法的整体流程图;
图2是本发明训练集和测试集预处理并提取特征词流程图;
图3是本发明实施例的分类器训练流程示意图;
图4是本发明实施例的硬件设备工作示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地描述,下文中提到的具体技术细节,如:方法,设备等,仅为使读者更好的理解技术方案,并不代表本发明仅局限于以下技术细节。
本发明的实施例提供了一种社交媒体评论的情感分析方法、设备及其存储设备,通过将。请参阅图1,图1是本发明实施例中社交媒体评论的情感分析方法的整体流程图,所述方法由一种社交媒体评论的情感分析设备实现,具体步骤包括:
s101:用特定程序获取用户评论信息;所述特定程序为python爬虫程序,所述特定程序获取社交媒体用于存储评论的服务器地址;设定新闻事件的热度排名阈值;根据所述热度排名阈值获取评论;按新闻主题分类存储获取的评论。
s102:使用数据库处理获取的用户评论信息并将该信息分为训练集和测试集所述数据库为mysql数据库;所述mysql数据库分为8个字段,分别为:评论获点赞数目记为numofzan、评论发表时间记为createtime、用户名记为username、用户id记为userid、该评论被评论的数目记为replycount、评论内容记为commenttext、新闻主题id记为group_id和评论的id记为onlyid;所述onlyid是评论的唯一标识;使用sql语句将获取的用户评论中的评论数据进行去重操作;去重后的评论数据记为comment_nonrepetitive;将所述comment_nonrepetitive分为训练集和测试集。
s103:对所述训练集和测试集分别进行预处理并提取特征词。
s104:设置情感分类等级及阈值,使用贝叶斯方法结合训练集进行训练得到分类器。
s105:用所述分类器对测试集中进行分类并输出分类结果。
s106:删除分类结果中感情分类等级低于阈值的评论。
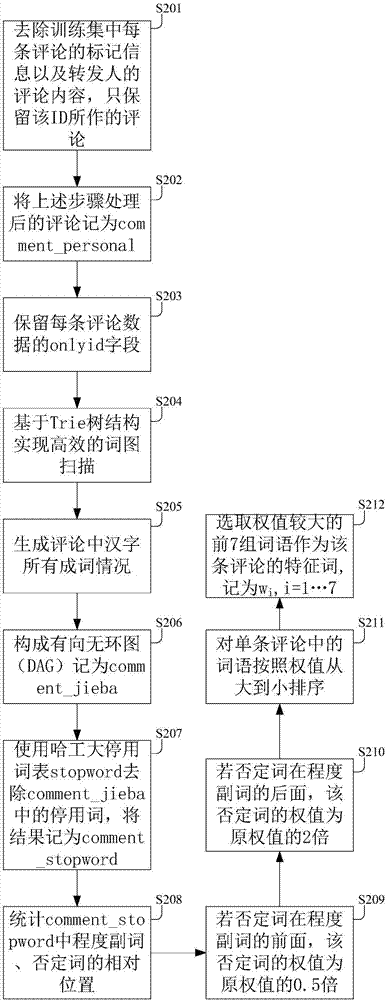
参见图2,图2是本发明训练集和测试集预处理并提取特征词流程图,具体包括:
s201:去除训练集中每条评论的标记信息以及转发人的评论内容,只保留该id所作的评论。
s202:将上述步骤处理后的评论记为comment_personal。
s203:保留每条评论数据的onlyid字段。
s204:基于trie树结构实现高效的词图扫描。
s205:生成评论中汉字所有成词情况。
s206:构成有向无环图(dag)记为comment_jieba。
上述s204~s206即为对comment_personal进行jieba分词。
s207:使用哈工大停用词表stopword去除comment_jieba中的停用词,将结果记为comment_stopword。
s208:统计comment_stopword中程度副词、否定词的相对位置。
s209:若否定词在程度副词的前面,该否定词的权值为原权值的0.5倍。
s210:若否定词在程度副词的后面,该否定词的权值为原权值的2倍。
s211:对单条评论中的词语按照权值从大到小排序。
s212:选取权值较大的前7组词语作为该条评论的特征词,记为wi,i=1…7。
参见图3,图3是本发明实施例的分类器训练流程示意图,具体包括:
s301:确定类别集合c={c1:极负,c2:负向,c3:较负,c4:中立,c5:正向},并设定阈值为c1。
s302:统计得到各类别下各特征词的条件概率:
p(w1|c1),p(w2|c1)…p(w7|c1)…p(w1|c2)…p(w7|c2)…p(w1|c5)…p(w7|c5)。对于特征词不足7个的评论,用null补充特征词,并定义p(null|ci)=1。
s303:统计训练集中各类别概率:p(c1),p(c2),p(c3),p(c4)及p(c5)。
s304:评论x划分为ci类的标准为p(ci|x)=max{p(c1|x),p(c2|x)…p(c5|x)}。若评论的分类结果为c1,则根据onlyid进行查找匹配,并及时删除该条评论。
s305:使用贝叶斯定理计算p(ci|x)。设定各特征词之间为条件独立,则
s306:对训练集中每条评论采用上述步骤完成分类器构建。
参见图4,图4是本发明实施例的硬件设备工作示意图,所述硬件设备具体包括:一种社交媒体评论的情感分析设备401、处理器402及存储设备403。
一种社交媒体评论的情感分析设备401:所述一种社交媒体评论的情感分析设备401实现所述一种社交媒体评论的情感分析方法。
处理器402:所述处理器402加载并执行所述存储设备403中的指令及数据用于实现所述的一种社交媒体评论的情感分析方法。
存储设备403:所述存储设备403存储指令及数据;所述存储设备403用于实现所述的一种社交媒体评论的情感分析方法。
通过执行本发明的实施例,本发明权利要求里的所有技术特征都得到了详尽阐述。
区别于现有技术,本发明的实施例提供了一种社交媒体评论的情感分析方法、设备及其存储设备,通过将,并有效地。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。