基于搜索及网页爬虫的数据抓取算法的制作方法
本发明涉及网页数据搜索技术,具体为基于搜索及网页爬虫的数据抓取算法。
背景技术:
爬虫作为一种自动获取网页内容的程序,是搜索引擎的重要组成部分。网络爬虫,是一种按照一定的规则,自动抓取互联网信息的程序或者脚本。现有技术中,爬虫任务一般分为数据读取、数据提取、关键词搜索、数据存储四个阶段,且每个阶段都有各自的输入输出,也就是说,不同阶段的输入或输出的内容、格式均有所不同,从而导致爬虫的过程不可分割,必须按照既定的阶段顺序执行,相邻两个阶段之间的耦合性较大,且网络爬虫的代码重用性低。
也就是说,现有技术存在的问题是程序的耦合性不高,适应性不强,网络爬虫需要根据所需爬取网站的不同而做相应的修改。
技术实现要素:
为了解决现有技术所存在的问题,本发明提出基于搜索及网页爬虫的数据抓取算法,数据处理方式耦合性极高,数据匹配获取的链接具有极强的不同环境的适应性,能够准确地捕捉到多种形式的链接,以适应不同的环境。
本发明采用如下技术方案来实现:基于搜索及网页爬虫的数据抓取算法,包括以下步骤:
s1、配置顶级域名的链接;
s2、运用广度优先搜索算法提取一个网站所有的网页链接;
s3、将所有提取到的网页链接采用哈希链表的方式保存进集合中;
s4、运用数据匹配算法过滤重复的网页链接,提取网页页面内容;
s5、采用模式匹配算法,输入关键词或关键字查找网页页面上的内容。
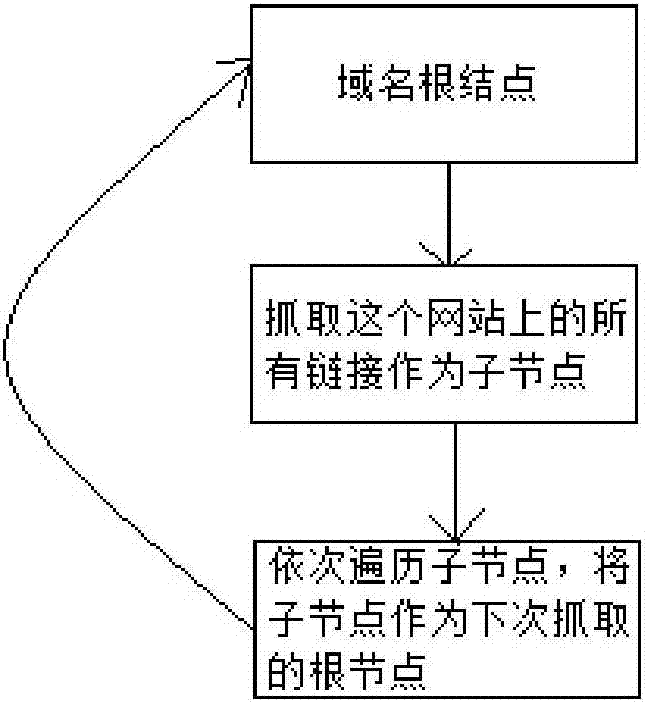
所述步骤s2包括:首先,读取配置的顶级域名,并将顶级域名设置为数据抓取的根节点,网络爬虫程序读取所述顶级域名并抓取顶级域名网站上所有的网页链接,并将所抓取的网页链接封装到一个集合中;然后再逐一读取集合中的网页链接,继续抓取集合中网页链接所对应网站上的所有网页链接,并将所抓取的网页链接封装进集合中。
所述步骤s3中哈希链表为以键-值存储数据的结构,将提取到的网页链接作为哈希链表中的键结构,并对是否已遍历进行标记,标记作为哈希链表中的值结构,如果还未遍历标记为false,如果已经遍历则标记为true。
所述步骤s4中,首先通过正则表达式进行网页链接的匹配,以去除已经保存的网页链接;然后取出保存网页链接的集合,进行集合的遍历,取到每一个网页链接,进行get请求,读取网页页面内容到内存中;对步骤s3中未遍历过的新网页链接不断发起get请求,读取网页页面内容并保存,一直到遍历完整个集合都没能发现新的网页链接。
与现有技术相比,本发明具有如下优点及有益效果:
1、本发明采用的网页搜索和网络爬虫算法,适用于各种网站数据的爬取,其中的数据处理方式耦合性极高,数据匹配获取的链接具有极强的不同环境的适应性,能够准确地捕捉到多种形式的链接,以适应不同的环境。
2、本发明只需在系统上配置想抓取数据的网站的域名,系统就会自动地去抓取这个网站所有可以抓取的网页链接,将网页链接存进集合中,同时对于相同的域名进行去重处理,提高数据抓取的效率;对未遍历过的新链接不断发起get请求,通过正则表达式匹配出想要的数据,保存下来,一直到遍历完整个集合都没能发现新的链接,则表示数据抓取完成。
3、本发明高度智能化,采用递归思想和广度优先搜索算法进行数据抓取;采用哈希算法保存需要遍历的链接,提高存取速度和抓取效率;通过数据匹配算法去重域名,从而进一步提高抓取效率;通过模式匹配算法匹配用户想要的信息。
4、另外,本算法采用多线程的方式进行数据抓取,有效提高了数据抓取的效率,并且及时释放堆内存,以达到节省系统资源的目的,从而形成一整套的数据抓取流程。
附图说明
图1是本发明利用广度优先搜索算法抓取网页链接的示意图;
图2是广度优先搜索算法访问链接抓取数据的流程图;
图3是哈希算法保存链接的流程图;
图4是数据匹配算法流程图;
图5是网页内容的提取流程图;
图6为采用模式匹配算法查找网页内容的示意图。
具体实施方式
下面将结合实施例及说明书附图对本发明做进一步详细的描述。
本发明用于抓取互联网上某个领域或者行业的相关数据,以进行基于大数据的统计、调研、搜索、分析等工作。本发明采用的算法相对于其他算法更注重于系统资源的合理利用、抓取数据的效率以及数据的全面性,能够全面快速地抓取相关网站的数据信息,从而将其进行处理保存,以便于后期的数据分析等工作。本发明算法包括以下步骤:
s1、配置域名根链接,即顶级域名的链接。
s2、运用广度优先搜索算法提取一个网站所有可以抓取的网页链接。
首先,读取用户配置的顶级域名,并将顶级域名设置为数据抓取的根节点,网络爬虫程序读取所述顶级域名并抓取这个网站上所有可以抓取的网页链接,并将所抓取的网页链接封装到一个集合中,然后再逐一读取集合中的链接,继续抓取集合中链接所对应网站上可以抓取的所有网页链接,并将所抓取的网页链接按照上述方法封装进集合中。
如图1所示,本算法所采用的遍历算法实现方式如下:
第1步:访问a域名节点。
第2步:依次访问c、d、b域名节点。
在访问了a域名节点之后,接下来访问a域名节点所包含的子节点。在本算法实现中,节点acdbfeg按照顺序存储,c在d和b的前面,因此,先访问c,访问完c之后,再依次访问d、b。
第3步:依次访问f、e域名节点。
在第2步访问完c、d、b之后,再依次访问它们的子节点。首先访问c的子节点f,再访问b的子节点e。
第4步:访问g域名节点。
在第3步访问完f、e之后,再依次访问它们的子节点。只有e有子节点g,因此访问e的子节点g。
因此访问顺序是:a->c->d->b->f->e->g。
如图2所示,本算法结合递归和广度优先搜索算法,由顶级域名开始,不断深入访问子链接,并将子链接封装入集合中,以便后续进行数据抓取操作。
s3、运用哈希算法将链接保存进集合中。
本算法中,所有抓取到的网页链接均采用哈希链表的方式保存。哈希链表是一种以键-值(key-indexed)存储数据的结构,可以快速访问任意键的值。从而实现存取速度快,提高算法抓取数据的效率。另外,由于哈希函数是一个压缩映象,因此,在一般情况下,很容易产生“冲突”现象,即:
key1!=key2,而f(key1)=f(key2)。
由于哈希表的这种特性,可以利用其进行简单地进行域名节点的去重,提高数据抓取的效率。如图3所示,将抓取到的链接作为哈希链表中的键结构保存进数据集合中,并对是否已遍历过进行标记,标记作为哈希链表中的值结构,如果还未遍历(即未抓取数据)标记为false,以便后续进行get请求抓取数据;如果已经遍历则标记为true,表示已经抓取过数据,后续不用再遍历进行数据抓取了,但是仍保留链接,以便后续进行数据匹配去重,以提高数据抓取的效率。
s4、运用数据匹配算法过滤重复的网页链接,提取网页页面内容。
通过正则表达式进行链接/域名的匹配,以便去除那些已经保存的链接,以免重复保存,导致进行重复的数据抓取而降低抓取效率。
如图4所示,通过数据匹配后,将抓取到的重复链接过滤掉,以便后续的数据抓取环节不会重复抓取,从而提高了数据抓取的效率。
链接去重后,取出保存网页链接的集合,进行集合的遍历,取到每一个网页链接,进行get请求,读取网页页面内容到内存中,将所有数据均以文件读写的方式写入文件中。然后,开放出一个接口,用户可以通过接口输入关键字或关键词,系统便通过模式匹配算法,匹配出关键字相关的内容,然后返回给用户,从而实现网页页面的数据抓取,具体的实现流程如图5所示。对步骤s3中未遍历过的新网页链接不断发起get请求,读取页面内容并保存,一直到遍历完整个集合都没能发现新的链接。
s5、采用模式匹配算法,用户可以通过输入关键词或关键字的方式查找网页页面上的内容。
模式匹配算法获取用户想要的信息:子串定位运算又称为模式匹配(patternmatching)或串匹配(stringmatching)。在串匹配中,一般将主串称为目标串,将子串称为模式串。用s表示目标串,t表示模式串,将从目标串s中查找模式串t的过程称为模式匹配。模式匹配算法实现原理如图6所示。
可以看到匹配流程完全是按照上面给出的基本思想走下来的,首先从目标串s的第一个字符开始和模式串t的第一个字符进行比较(第一趟),如果相等则进一步比较二者的后继字符(第二趟),否则从目标串的第二个字符开始再重新与模式串t的第一个字符进行比较(第三趟、第四趟)。我们重点来关注一下第三趟,此时发现s[i]!=t[j],则要从目标串s的第二个字符再重新开始,i回溯到i=i-j+1。因为i-j表示这一趟的起始匹配位置,i-j+1则意为从这一趟起始比较位置的下一个位置继续进行比较。同时j要回溯到0,即重新与模式串t的第一个字符进行比较。最后,经历了第五、六、七趟后,匹配成功。
如上所述,便可较好地实现本发明。
- 还没有人留言评论。精彩留言会获得点赞!