一种基于位置和信任关系的网络服务推荐方法与流程
本发明涉及协同过滤推荐技术领域。具体涉及一种基于位置和信任关系的网络服务推荐方法。
背景技术:
随着移动互联网的飞速发展,为用户提供了一个更加丰富多彩的移动网络服务平台。与此同时,服务类型与服务内容的日新月异,有限的移动网络资源和硬件资源,为移动用户带来严重的移动信息过载问题。因此,推荐技术在整个互联网领域的重要性日益凸显,并越来越受到研究者的重视。推荐系统作为缓解“信息过载”的有效手段之一,需要建立用户与项目之间的二元关系,利用已有的选择过程或相似关系挖掘出每个用户潜在感兴趣的对象,从而进行个性化推荐。从信息过滤的角度,目前推荐系统主要分为一下几种:协同过滤推荐(collaborativefilteringrecommendation)、基于内容的推荐(context-basedrecommendation)、混合推荐(hybridrecommendation)。
伴随着普适计算理论的成功引入,使传统推荐系统不再仅仅关注“用户-项目”二元关系,而是将用户所处的上下文环境信息(如时间、位置、周围人贸、情趣、活动状态、网络条件等等)一同考虑进来,形成“上下文-用户-项目”三元组系统,使得系统能够自动发现和利用各种上下文信息,满足用户随上下文信息变化而改变的个性化信息需求。其中,位置服务上下文信息与移动互联网的融合,特别是与移动社会化网络的融合,产生的与人们日常生活紧密联系的、拥有具体场景化的位置服务。
基于位置的社会化网络(location-basedsocialnetworks,lbsns)不仅是在线社会化网络中添加位置信息,使用户在社会化网络中分享与位置有关的信息,而且隐含着用户位置信息及其位置标注媒体信息(例如图片、视频、文档等)中内在关联实体之间形成的新的社会网络结构,其中位置信息是由用户随时间变化的移动位置点构成。此外,实体间内在的关联性不仅包括两个用户出现在相同的位置上或者共享相似的位置信息,而且还包括用户的一般兴趣、社会活动规律、具体位置信息及位置标注的媒体信息中体现出来了的各种知识。基于位置的社会化网络包括六种不同的网络关系:位置-位置网络、用户-用户网络、媒体内容-媒体内容网络、用户-位置网络、用户-媒体内容网络、位置-媒体内容网络。其中位置-位置网络、用户-位置网络和位置-媒体网络是基于位置的社会化网络推荐系统重点研究的内容。大多数基于位置的社会化网络推荐服务都是基于这三种网络层次数据的挖掘与分析。
目前,基于位置的网络服务推荐研究领域,大都围绕移动用户位置变化的轨迹及位置特征挖掘,轨迹匹配的方式寻找相似用户,并以此给出服务推荐策略。很少将位置信息作为一种特殊的上下文信息与传统推荐系统相融合,实现基于位置上下文的推荐。且移动网络服务推荐系统还具有移动性强、易受上下文因素的影响及实时性和互动性强的特征。如何有效的提高推荐的成功率和准确率,是目前亟待解决的问题。
技术实现要素:
为了提高推荐的成功率和精准度,本发明的目的在于提供一种基于用户位置和信任关系的网络服务推荐方法。该方法融合移动用户位置上下文信息、用户偏好及用户之间的信任关系,实现了实时性和互动性的个性化网络服务推荐。从而有效的提高了推荐的成功率和精准度。
为了实现上述目的本发明采用如下技术方案:一种基于位置和信任关系的网络服务推荐方法,包括以下步骤:
s1:收集用户的基本信息数据集x,并进行预处理。
s2:根据用户随时间-位置变化的网络服务特征矩阵建立基于位置的偏好模型,生成全局偏好度矩阵p。
s3:利用s2生成的全局偏好度矩阵p,计算出基于位置的用户之间的全局相似度矩阵sim。
s4:用户信任关系挖掘算法包括直接关系挖掘算法和间接关系挖掘算法,根据用户间的通信数据(包括通话和短信),计算直接好友信任度和间接好友信任度,最终融合生成用户信任度矩阵tr;
s5:将s3生成的全局相似矩阵sim与s4生成的用户信任度矩阵tr融合,使用top-n近邻选择方法生成用户邻居集合矩阵n,并计算出近邻相似权重ω;预测出用户对任意网络服务项目的兴趣度。
在以上步骤中,用户的基本信息数据集x为:x=[移动用户的集合、用户的通话记录详单、移动用户短信记录详单、移动用户的地理位置集合(比如:家、路上、办公室、超市等)、移动网络服务集合(如:看新闻、听音乐、看电影、购物等)、移动用户在一个时间周期内所处的地理位置信息集合、每个移动用户在所有地理位置上的应用移动网络服务集合]。
移动通信网中,移动用户位置信息随着时间的变化而改变,这种位置的变迁诱导了移动用户偏好的改变。因此,移动用户基于位置的偏好模型的建立就是要以时间-位置为主线,在训练数据中提取用户随时间-位置变动而导致的不同网络服务集。因此,基于位置的偏好模型中全局偏好度矩阵p的计算过程为:
s21:对于某个移动用户ux(ux∈u)在某一地理位置lx(lx∈l)上提取该用户使用的网络服务集合sx,得到该用户在这个位置上使用的网络服务特征
s22:在同一时间周期内的其他不同位置上,执行s11提取出用户uj在这些位置上使用的网络服务特征
s23:在所有的时间周期内,执行步骤s21和s23,若在不同时间周期内的相同位置上,用户uj使用了相同的网络服务项目则计算该用户对该项网络服务的平均评价值,作为该用户在所有时间周期内对该网络服务的整体评价;否则,将一个时间周期上使用的网络服务评价作为该用户在所有时间周期内对该网络服务的整体评价,得到该用户在整个训练集上的基于位置的全局偏好特征
s24:对所有的移动用户,重复执行s23,获得用户在整个训练集上的全局偏好度矩阵p。
进一步地,全局相似度矩阵sim的用户间网络服务偏好相似度为:
s31:两个移动用户ux和uy分别在位置lx和ly的网络服务特征为px=(lx,sx)和py=(ly,sy),sx和sy分别表示两个用户在位置lx和ly使用的所有网络服务多维特征向量,经归一化处理,使它们具有相同的长度,其中,dis(lx,ly)表示用户所在的位置之间的距离,则基于位置的移动用户网络服务偏好相似度定义为:
s32:对任意的ux,uy,uz∈u,用户间网络服务偏好相似度通过以下不等式进行测度:
sim(ux,uy)sim(uy,uz)≤[sim(ux,uy)+sim(uy,uz)]sim(ux,uz)
sim(ux,uy),sim(uy,uz),sim(ux,uz)分别表示用户ux和uy,x和uz,ux和uz的网络服务偏好相似度。
上述步骤s4中用户信任度矩阵tr的构建过程为:
s41:提取用户集中的某个用户ux,统计短信信息总数c以及各个充当接受方的用户uj和对应的短信数ci;用户ux通话总时间t,通话总次数q,用户ux与uj通话的总数时间ti,通话的总次数qi,则ux对uj的直接好友信任度
s42:对于移动用户集合u中的每一个用户,都执行步骤s41,并把直接好友信任程度
s43:对于用户ux,将itr中的用户ux的直接好友集合tx取出,与u中的ux非好友关系用户进行比较,用ty表示uy的好友集合;
其中,
则有,
将好友关系及对应的信任程度
s44:将直接好友信任度矩阵itr和间接好友信任程度矩阵dtr合成信任度矩阵tr,即:
在步骤s5中近邻相似权重ω的计算为:使用传统的协同过滤推荐算法中,top-n方法近邻选择方法,将信任关系信息引入到协同过滤推荐算法中,其中,用户ux用x表示,用户uy用y表示,sim(x,y)表示x和y两个用户的相似度矩阵,tr(x,y)表示两个用户的信任矩阵,用户x和y的相似矩阵分别为simx和,用户x信任度矩阵为trx,用户的邻居用户集的网络服务集合为nsx,邻居用户集的直接好友集合ntx,用户邻居用户集nbx=simx∪trx,则近邻相似权重ω:
更进一步用户对任意网络服务项目的兴趣度为:
其中,
本发明使用基本用户通信数据集信息提出了一种信任值计算方法。把它们融合并应用于基于移动用户位置和信任关系的网络服务推荐过程中,从而形成了一种基于移动用户位置的个性化网络服务推荐方法。该方法有效地提高了网络服务推荐的准确性和可靠性,同时缓解了推荐过程中可能存在的数据稀疏性以及冷启动问题。
附图说明
本发明的上述和/或附加的方面和优点,结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1是本发明的整体流程示意图;
图2是本发明的基于位置上下文的用户偏好提取示意图;
图3是本发明的用户信任关系算法流程图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的含义。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
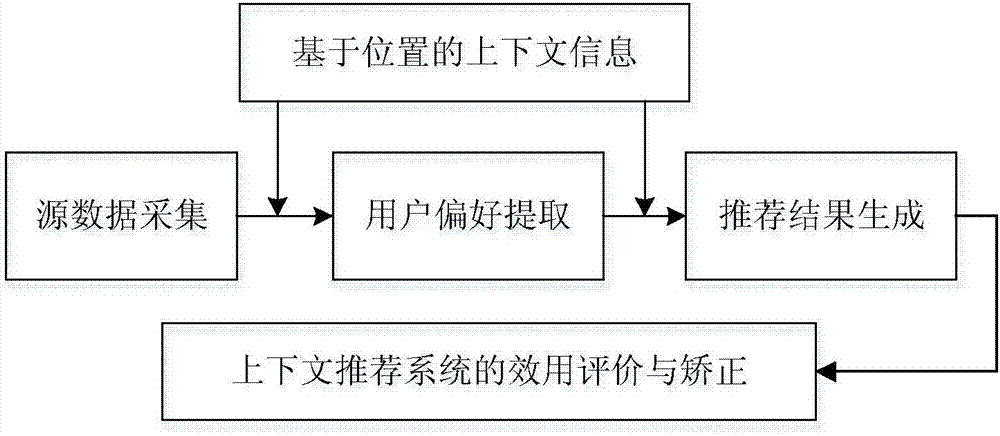
图1是本发明的整体流程结构示意图。如图所示,本发明提供一种基于位置和信任关系的网络服务推荐方法。首先,对基于用户位置上下文信息进行偏好相似度预测;然后计算出移动用户间信任关系的进行近邻选择,最后产生出预测的结果。具体步聚如下:
s1:收集用户的基本信息数据集,并进行预处理。
s2:建立以时间-位置为主线的移动用户集合u的基于位置的偏好模型,生成用户全局偏好度矩阵p。
s3:通过利用s2生成的所有用户全局偏好矩阵,计算出基于位置的用户之间的全局相似度矩阵sim;
s4:用户信任关系挖掘算法包括直接关系挖掘算法和间接关系挖掘算法,根据用户间的通信数据(包括通话和短信)记录,经格式化处理,直接信任关系和间接信任关系的挖掘,最终生成移动用户信任关系矩阵tr;
s5:将s3生成的全局相似矩阵sim与s4生成的信任关系矩阵tr融合生成用户邻居集合。使用top-n近邻选择方法生成用户邻居集合矩阵n,并计算出近邻相似权重ω;
s6:预测出用户对其网络服务项目的兴趣度。
本发明融合移动用户位置上下文信息、用户偏好及用户之间的信任关系,实现了实时性和互动性的个性化网络服务推荐。从而有效的提高了推荐的成功率和精准度。并且分析用户的移动通信信息,将用户好友关系信息作为一种特殊的近邻关系融入到相似矩阵中,形成最终的推荐候选近邻用户集,一方面扩大了推荐候选近邻集的数目,缓解了单一相似近邻用户集作为推荐候选近邻集的稀疏性:另一方面,相对于相似近邻的冷启动用户,可以从可能的通信好友集中为其挑选推荐候选,从而在一定程度上降低冷启动用户存在的可能性。
图2是本发明的基于位置上下文的用户偏好提取示意图。如图所示,首先对于某个移动用户ux(ux∈u),在某一地理位置lx(lx∈l)上提取该用户使用的网络服务集合si,得到该用户在这个位置上使用的网络服务特征
然后,提取出用户ux和uy分别在位置lx和ly的网络服务项目的应用特征为px=(lx,sx)和py=(ly,sy)。其中经归一化处理后用dis(lx,ly)表示用户所在的位置之间的距离。则基于位置的移动用户网络服务偏好相似度定义为:
最后,对任意的ux,uy,uz∈u,用户间网络服务偏好相似度可以通过以下不等式进行测度:
sim(ux,uy)sim(uy,uz)≤[sim(ux,uy)+sim(uy,uz)]sim(ux,uz)
本发明根据用户位置随时间的周期性变化,学习用户对信息的个性化需求随着位置变化的规律,提取用户对个性化信息需求偏好模型。从而有效的提高了推荐的成功率和精准度。
图3是本发明的用户信任关系算法流程图。如图所示,首先计算直接好友信任度itr。提取将数据中的通信主体抽取出来,判断是否是所需要预测的目标,如果不是,则删除数据,形成矩阵tr′。以某个用户ux为例,统计短信信息总数c以及各个充当接受方的用户uj和对应的短信数ci;用户ux通话总时间t,通话总次数q,用户ux与uj通话的总数时间ti,通话的总次数qi。则,ux对uj的信任度
在tr′中的所有通信组合中,ux仅与通信对象中的80%用户是好友关系,所以提取出
然后生成间接好友信任度矩阵dtr。由通信记录确定的直接好友关系比较稀疏,不利于推荐,而且现实中,也不是所有的好友间都有通信行为,因而从通信记录中无法全面地获取用户间的好友关系,所以需要通过矩阵itr挖掘更多有用的信息。对于任意两个好友而言,他们的好友集合或多或少会存在交集。同样的,对于用户ux,将itr中的用户ux的直接好友集合tx取出,与u中的ux非好友关系用户进行比较,用ty表示uy的好友集合。
其中,
则有,
将好友关系及对应的信任程度
最后,由itr和dtr最终确定的好友信任矩阵tr。即:
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!