一种人脸活体识别方法及系统与流程
本发明涉及人脸识别领域,具体涉及一种基于人脸特征点和三维姿态估计的人脸活体识别方法及系统。
背景技术:
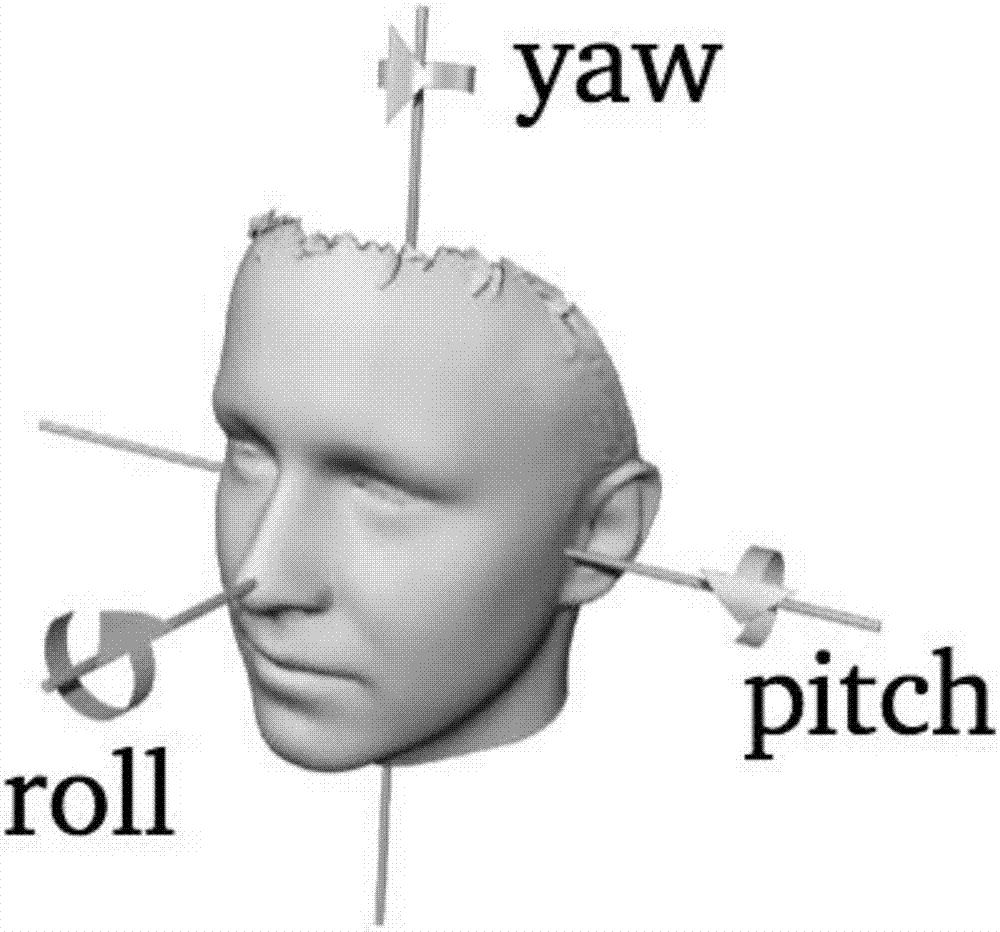
:现如今的人脸识别系统中,大多采用照片或视频进行识别,但是采用这种方法,人们可以用照片和视频骗过系统。而活体识别能有效抵御这种攻击。现有的活体识别系统对于动作的估计并不是很准确,且很占资源。在本发明中,通过轻量级的网络结构,通过基于深度学习的人脸landmark检测和人脸三维姿态估计,能达到很高的准确率,同时模型大小总和不超过3m,在嵌入式设备(安卓手机,苹果手机等)中能达到25fps以上的速度,完全能达到实时的要求。技术实现要素:本发明的目的克服上述现有技术中存在的问题,提供一种人脸活体识别方法及系统。为了实现上述目的,本发明提供了一种基于人脸特征点和三维姿态估计的人脸活体识别方法,包括:对训练图像分别进行人脸特征训练及三维姿态估计训练,分别得到特征预处理图片和三维预处理图片;将人脸特征点映射到特征预处理图片的相应位置上;将三维预处理图片进行数据增强;设置两层人脸特征点的cnn网络,且两个主层cnn网络构成一个级联卷积神经网络;先通过第一主层cnn网络对特征预处理图片处理得到人脸特征点粗略位置的网络输出结果及处理图片,再通过第二主层cnn网络对处理图片的人脸特征点进行校正,并输出人脸特征点模型;输入三维预处理图片和三维角度标注值进行三维姿态估计训练;输出三维角度值模型;通过所述人脸特征点模型对活体人脸表情进行估计并检测识别,通过三维角度值模型对点头及摇头进行估计并检测识别。进一步的,如前述的人脸活体识别方法,对训练图像分别进行人脸特征训练具体包括:通过opencv对训练图像进行人脸检测,将人脸框放大1.2倍,然后缩放到96×96的尺度。更进一步的,如前述的人脸活体识别方法,对训练图像分别进行三维姿态估计训练具体包括:通过opencv对训练图像进行人脸检测,将人脸框放大1.25倍,然后缩放到64×64的尺度。更进一步的,如前述的人脸活体识别方法,所述通过第一主层cnn网络得到特征预处理图片中人脸特征点粗略位置的网络输出结果,具体方法为:将所述特征预处理图片和68个坐标点输入第一主层cnn网络;通过第一主层cnn网络中的前5个子层的cnn网络进行特征提取,然后再通过两个子层稀疏全连接进行特征组合,最后通过一个全连接进行回归操作,并得到包括68个坐标点粗略位置的网络输出结果和处理图片。更进一步的,如前述的人脸活体识别方法,所述通过第二主层cnn网络对处理图片的人脸特征点进行校正,具体方法为:先根据所述网络输出结果对所述处理图片进行相应位置的截图;通过第二主层cnn网络中的前5个子层的cnn网络进行特征提取,然后通过两个子层稀疏化的全连接进行特征组合,最后一层全连接的输出数为相应位置的人脸特征点个数。更进一步的,如前述的人脸活体识别方法,所述进行三维姿态估计训练,具体为:将batchnormalization加入的五层卷积对所述三维预处理图片进行特征提取,通过一层稀疏的全连接进行特征组合,最后接一个输出为3的全连接,输出三维角度预测值。本发明还提供一种人脸活体识别系统,所述系统通过所述人脸特征点模型对活体人脸表情进行估计并检测识别,通过三维角度值模型对点头及摇头进行估计并检测识别。在上述技术方案中,本发明具有如下所述有益效果:速度快:三维姿态估计模型在单核cpu上能达到200fps的速度,级联人脸landmark估计模型在单核cpu上能达到50fps的速度。均能满足实时的要求。模型小:通过降维压缩,使得模型大小缩小100倍以上。准确率高:人脸landmark估计在数据集helen,afw,300-w上都达到很高的准确率。防作弊:通过本发明方法及系统,能够有效融合活体识别和人脸检测,并减少作弊者的攻击。附图说明为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。图1是本发明一种实施例中人脸活体识别方法流程图;图2是本发明一种实施例中三维角度的示意图;图3是本发明一种应用例中检测方法流程图;图4是本发明一种实施例中应用的网络结构如图。具体实施方式为了使本领域的技术人员更好地理解本发明的技术方案,下面将结合附图对本发明作进一步的详细介绍。如图1所示,本发明提供一种基于人脸特征点和三维姿态估计的人脸活体识别方法,包括:对训练图像分别进行人脸特征训练及三维姿态估计训练,对训练图像进行人脸特征训练具体包括:通过opencv对训练图像进行人脸检测,将人脸框放大1.2倍(在人脸框的基础上将框扩大1.2倍),然后缩放到96×96的分辨率尺度,如果不足96×96,则会通过缩放,达到96×96的尺度;对训练图像进行三维姿态估计训练具体包括:通过opencv对训练图像进行人脸检测,将人脸框放大1.25倍,然后缩放到64×64的尺度;然后,分别得到特征预处理图片和三维预处理图片;将人脸特征点映射到特征预处理图片的相应位置上;将三维预处理图片进行数据增强,所述数据增强可包括但不限于翻转、模糊和光线变换;设置两层人脸特征点的cnn网络,且两个主层cnn网络构成一个级联卷积神经网络;先通过第一主层cnn网络对特征预处理图片处理得到人脸特征点粗略位置的网络输出结果及处理图片,具体方法为:将所述特征预处理图片和68个坐标点输入第一主层cnn网络,所述68个坐标点通过训练好的卷积神经网络预测得到;通过第一主层cnn网络中的前5个子层的cnn网络进行特征提取,然后再通过两个子层稀疏全连接进行特征组合,最后通过一个全连接进行回归操作,并得到包括68个坐标点粗略位置的网络输出结果和处理图片;再通过第二主层cnn网络对处理图片的人脸特征点进行校正,具体方法为:先根据所述网络输出结果对所述处理图片进行相应位置的截图;通过第二主层cnn网络中的前5个子层的cnn网络进行特征提取,然后通过两个子层稀疏化的全连接进行特征组合,最后一层全连接的输出数为相应位置(眼睛,嘴巴,鼻子)的人脸特征点个数,并输出人脸特征点模型;在训练过程中,在前两层的全连接部分先用大的参数进行训练,其中,所述前两层具体指的是卷积神经网络前两层的全连接,训练过程中使用的网络结构如图4所示,图中fc6,fc7为所述前两层全连接,第三层全连接fc8用于输出预测的人脸特征点;这样能加速训练过程,使得卷积部分的参数得到很好的适应。但是实用过程中,全连接的参数太大,会使得模型变得很大,速度也会变慢。因此在卷积的参数训练好之后,降低全连接的参数,再进行模型微调,这样在准确率不变的情况下,使得模型的大小压缩了100倍以上,同时速度也得到了提高。在评估性能的时候,用平均定位偏差指标err:其中,m是人脸特征点的数量,p是预测的位置,g是标注的位置,l和r是左眼和右眼的中心位置。通过该方法landmarkerr指标能达到5.2左右。输入三维预处理图片和三维角度标注值进行三维姿态估计训练,具体为:将batchnormalization加入的五层卷积对所述三维预处理图片进行特征提取,通过一层稀疏的全连接进行特征组合,最后接一个输出为3的全连接,输出三维角度预测值;输出三维角度值模型;具体的,三维角度的定义如图2所示。三维姿态估计我们使用两个指标来进行评价,一个是平均预测偏差,即每个预测值和标注值的差的平均值;另一个指标是预测准确率,我们认为偏差在15°以内为预测正确,反之为预测错误。我们使用压缩后的模型,在三个角度上的预测准确率均得到90%以上。具体三维角度的平均偏差和准确率如下表所示:rollpitchyawdeviation5.2°9.3°6.7°accuracy95%90%92%通过所述人脸特征点模型对活体人脸表情进行估计并检测识别,通过三维角度值模型对点头及摇头进行估计并检测识别。本发明还提供一种人脸活体识别系统,所述系统通过所述人脸特征点模型对活体人脸表情进行估计并检测识别,通过三维角度值模型对点头及摇头进行估计并检测识别。应用例:本发明系统可以分为三个模块:人脸检测,人脸动作识别,人脸识别。对于输入的测试图片,我们通过opencv的人脸检测,来定位人脸的位置,如果检测发现在有效区域内出现了多张人脸,则提示错误。如果检测到只有一张人脸,则通过,进入下一个环节。在人脸动作识别,即活体识别中,用户按照我们的提示做动作,如果动作识别成功,则进入人脸识别环节。具体检测方法如图n所示。人脸识别环节将真人的照片和身份证上的照片进行比对,我们用基于深度特征的人脸识别算法,返回两个照片的相似度,如果相似度大于设定的阈值,则比对通过。以上只通过说明的方式描述了本发明的某些示范性实施例,毋庸置疑,对于本领域的普通技术人员,在不偏离本发明的精神和范围的情况下,可以用各种不同的方式对所描述的实施例进行修正。因此,上述附图和描述在本质上是说明性的,不应理解为对本发明权利要求保护范围的限制。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1