一种基于词序列的钓鱼URL检测方法及系统与流程
本发明涉及信息安全领域,尤其涉及一种基于词序列的钓鱼url检测方法及系统。
背景技术:
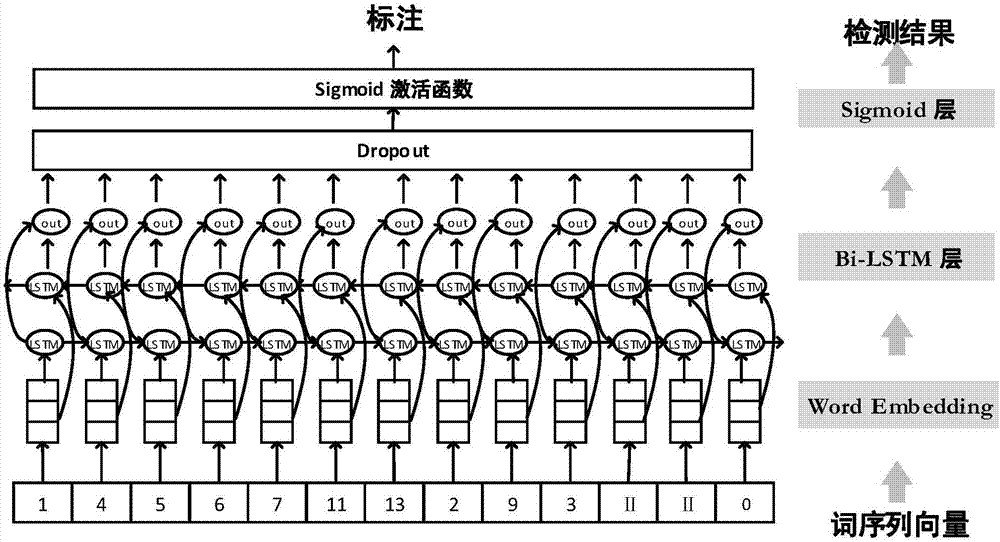
:钓鱼url是一种网络钓鱼行为,通过伪装成信誉卓著的法人媒体网站以获取用户的敏感信息,如用户名、密码和信用卡明细等。钓鱼url通常都声称自己来自于流行的社交网站(包括youtube、facebook、twitter等)、拍卖网站(ebay)、电子购物网站(paypal、alibaba等)、或网络管理者(谷歌、雅虎、互联网服务提供商)等,以此来诱骗受害人的轻信。攻击者经常采用的欺骗手段是在url中嵌入混淆用户的关键词,如攻击者利用形如“login.mydomain.tld/paypal”的url来诱骗paypal用户。目前,无论在研究领域,还是商业产品中,已有很多钓鱼url检测的方法和安全产品,其主要原理大都基于人工提取url相关数据的特征,构建分类模型,对url进行分类,从而检测出钓鱼url。根据分析数据的不同,已有检测方法可以分为基于多源信息的检测方法和基于url自身的检测方法两大类。基于多源信息的检测方法需要采集url相关的多种数据,包括alexa排名、whois信息、网页内容等,构造复杂的模型对标注好的数据进行训练,用来检测未知url是否为钓鱼url。这种方法通常具有比较高的准确率,但是,由于采集这些多种数据需要很大的资源和时间等额外的开销,因此,不适用于高速网络中的实时检测。而基于url自身的检测方法,只分析url字符串本身的文本特征,用来构建分类模型,是一种轻量级的检测方法,适用于实时检测。具体而言,基于url自身的钓鱼检测方法,通过提取url字符串的文本特征,训练分类模型,用来检测钓鱼url。url字符串本身的文本特征又可以分为字符特征和词特征两类。字符特征主要考虑组成url文本串的字符表现的特征,包括字符长度、元音辅音比例、数字个数、特殊符号个数、字符分布的熵值等。词特征主要分析url中包含的有语义信息的单词及其出现频度特征等,如url中常用的词login、update等以及流行的知名品牌paypal、alibaba等。基于url自身的轻量级钓鱼检测更符合高速网络中实时响应的需求。基于字符的特征忽略了url中包含的语义信息,url是用来方便人记忆的,因此通常具有可读性和易记忆性,包含多个有含义的常用词。而且,在钓鱼攻击中,攻击者经常采用的策略是利用关键词来迷惑用户。而目前已有的基于词特征的钓鱼url检测方法大多采用词和出现的频率作为特征,没有考虑url中包含的词序列特征,而且这些特征都是基于人工提出,有一定的局限性。首先,人工提取特征需要耗费大量的人力和资源去统计分析和验证特征的有效性;其次,人工提取的特征通常只对某一类数据有效,鲁棒性差;而且,攻击者在钓鱼url中使用的关键词通常与正常url相似,这样才可以混淆用户,造成分类模型检测效率降低。技术实现要素:针对上述现有技术存在的不足,本发明的目的在于提供一种基于词序列的钓鱼url检测方法及系统,用来检测钓鱼url。通过对url字符串进行分词,进而得到词序列的向量表示,然后利用深度学习模型自动学习词序列中的上下文信息和特征,不需要人工提取url中包含单词相关的文本特征,采用训练好的模型用来检测钓鱼url。从而,解决前面提到的已有基于词特征的钓鱼url检测中遇到的问题。为达上述目的,本发明采取的技术方案是:一种基于词序列的钓鱼url检测方法,包括以下步骤:将已标注url转换为词序列向量作为训练数据;采用训练数据训练分类模型;将未知的url转换为词序列向量并输入到训练好的分类模型中进行标注。进一步地,将已标注url或未知的url转换为词序列向量包括:过滤掉已标注url或未知的url中的协议和通用顶级域名;对过滤后剩余的部分进行分割,对分割获得的每一个分段的字符串使用词典通过正向最大匹配的方式进行分词,得到词序列;对上述词典中所有的词从1开始进行编号,使每个词都有唯一编号,把每个已标注url或未知的url的词序列转换为数字表示的定长向量。进一步地,所述协议包括http、https、ftp、ftps、gopher;所述通用顶级域名包括com、org、net、edu、gov。进一步地,所述使用词典通过正向最大匹配的方式进行分词包括:判断整个字符串是否在词典中,如是,则不再进行分词;如果否,则去掉最后一个字符,判断剩余的字符串是否在词典中;重复前述判断过程直到匹配到在词典中的词,然后去掉匹配中的词;对字符串剩下的部分继续进行上述步骤,直至字符串全部处理完毕;如字符串不包含词典中的词,则分为单个字符。进一步地,所述词典选用peternorvig公开的谷歌英文单词语料库。进一步地,采用训练数据训练的分类模型选用基于词序列的双向lstm模型进行训练。进一步地,采用训练数据训练分类模型包括:将训练数据随机分为训练部分和验证部分,通过设置神经网络模型的超参数和激活函数等参数对双向lstm模型进行训练。进一步地,双向lstm模型包含嵌入层、双向lstm层、dropout层和sigmoid层四层神经网络,采用训练数据训练分类模型还包括:对双向lstm层的输出使用dropout函数用于防止过拟合。一种基于词序列的钓鱼url检测系统,包括:转换模块及分类训练模型;转换模块用以将已标注url转换为词序列向量作为训练分类模型的训练数据;并用以将未知的url转换为词序列向量并输入到训练好的分类模型中进行标注。如上所述,本发明提供的方法及系统,不需要人工提取任何特征,只需要把url转换为词序列向量表示,通过深度神经网络(双向lstm模型)自动学习词序列中的上下文信息和特征,用来检测钓鱼url。相较于传统的检测钓鱼url的技术,具有以下优点:首先,不需要额外采集url的相关数据以及人工提取url的文本特征,通过采用深度学习模型自动学习url的词序列上下文信息和特征,并藉此检测钓鱼url;明显降低开销。另外,通过深度挖掘url的词序列包含的上下文信息和特征,相比于基于人工提取的词特征的机器学习模型和基于字符序列的深度学习模型都有较好的效果,在相同数据集上的检测效果较佳。最后,通过本发明的方法和系统,使用训练好的模型,在普通的服务器上,单线程预测速度达每秒钟不少于600个url。在提高检测准确率的前提下,能够同时满足实时检测的需求。附图说明图1是本发明一实施例中基于词序列的钓鱼url检测方法的流程示意图。图2为本发明一实施例中基于词序列的钓鱼url检测方法中采用的双向lstm模型的结构示意图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。在本发明的一实施例中,提供一种基于词序列的钓鱼url检测方法及系统,方法的主要步骤包括:(1)词序列向量表示,首先,采用基于词典匹配的方法得到url中包含的关键词序列,然后基于词典编码得到url词序列的向量表示;(2)模型训练,对上一步中得到的词序列向量,使用标注好的训练数据训练基于词序列的双向lstm模型;(3)钓鱼url检测,使用训练好的基于词序列的双向lstm模型检测未知url是否为钓鱼。系统包括:转换模块及分类训练模型;转换模块用以将已标注url转换为词序列向量表示作为训练分类模型的训练数据;并用以将未知的url转换为词序列向量表示并输入到训练好的分类模型中进行标注。该方法中的词序列向量表示步骤,主要是为了得到url词序列的向量表示,主要有以下几步:i)首先,过滤掉url中公知的协议和通用顶级域名两部分,常用的协议包括http、https、ftp、ftps、gopher等,通用顶级域名包括com、org、net、edu、gov等14个;ii)对剩余的部分,先用符号进行分割,然后对每一个分段使用预先准备好的词典通过正向最大匹配的方法进行分词,结合下表算法1所示的伪代码,具体分词过程为:首先判断整个字符串是否在词典中,如果在,则不需要再进行分词;如果不在,则去掉最后一个字符,判断剩下的字符串是否在词典中,直到匹配到在词典中的词,然后去掉匹配中的词,对字符串剩下的部分继续进行上述步骤,直到字符串全部处理完,如果字符串不包含词典中的词,则分为单个字符。上述分词过程中采用的词典是peternorvig公开的谷歌英文单词语料库(包含333,333个英文单词);不适用其他英文单词词典,该词典是peternorvig统计了在web网页中常用的单词,更符合url的命名方式。iii)然后,对上述词典中所有的词从1开始进行编号,每个词都有唯一一个编号,把每个url的词序列转换为数字表示的定长向量;该方法中的模型训练步骤,对上一步中得到的向量集合,使用标注好的向量集合作为训练数据对基于词序列的双向lstm模型进行训练。将训练样本集随机分为训练和验证两部分(分别约占全部标注数据的80%和20%),通过设置神经网络模型的超参数(每一层的输出维度等)和激活函数等参数对双向lstm模型进行训练。所使用的深度学习模型包含多层神经网络,分别为嵌入层、双向lstm层、dropout层和sigmoid层四层神经网络,对双向lstm层的输出使用dropout函数用于防止过拟合。该方法中的钓鱼url检测步骤,主要实现对未标注的数据,即未知url,检测其是否为钓鱼。将未知url的词序列向量输入到训练好的双向lstm模型中进行标注,如果输出为1则表示其为钓鱼url,否则为正常url。结合实例做进一步说明:基于词序列的钓鱼url检测方法,其总体流程如图1所示,基于词序列的双向lstm模型结构如图2所示。以钓鱼url:http://shen.mansell.tripod.com/games/gameboy.html为例,该url标注状态为1,对url进行定长的词序列向量表示和训练双向lstm模型,并使用训练好的模型对未知url:http://fly-project.net//yahoo.link/yah/t/y.html进行检测。1)首先对输入的url进行词序列向量表示,首先使用预先准备好的词典对url进行分词:然后对词典中的词进行编号,词序列表示为长度为n的定长向量,n的取值可以通过统计得到,经过统计发现超过百分之九十的url中包含13个词,因此设定n=13,那么两个url分别得到向量(1,4,5,6,7,11,13,0,0,0,0,0,0)和(2,19,3,9,12,8,14,0,0,0,0,0,0)。用相同的方法得到样本集中所有url的词序列向量表示。样本集中包含已经标注的正常url和钓鱼url数据。2)使用词序列向量集合中标注的数据作为训练数据输入到如图2所示的基于词序列的双向lstm模型中进行训练,首先url的词序列向量输入到embedding层降维处理,然后输入到双向lstm层中进行学习,学习的结果输入到dropout层防止过拟合,最后一层sigmoid函数输出检测结果。标注1表示为钓鱼url,标注为0表示正常url,实际是个二分类问题,因此模型输出使用sigmoid函数进行0-1分类。把所有的标注数据输入到模型中训练数据,输出训练好的模型。3)对于未标注的数据,将其向量输入到训练好的模型中,输出标注结果,如果输出为1表示为钓鱼url,否则为正常url。由此,通过上述实例可知,本例中的方法不需要人工提取任何特征,只需要把url转换为词序列向量表示,通过深度神经网络(双向lstm模型)自动学习词序列中的上下文信息和特征,用来检测钓鱼url。其主要步骤包括:1)词序列向量表示,首先对url进行分词,此处的url包含已标注的和未知的。所有的url都要转换为向量,然后用标注的数据训练模型。然后利用填充序列的方法得到固定长度的向量表示;“定长“表示每个url得到的词序列向量长度是相同的。填充序列方法是用来处理不同长度的向量,转换为相同长度。2)模型训练,对上一步骤得到的向量,使用标注好的训练数据训练双向lstm模型。3)钓鱼url检测,对于未标注的url,把其向量表示输入到训练好的双向lstm模型中进行标注,标注为1的为钓鱼url。步骤1)首先通过词序列向量表示,得到url字符串的定长向量表示,该方法对url的向量表示进行训练和分析;步骤2)对预处理后的数据,使用标注好的数据训练基于词序列的双向lstm模型;步骤3)把未知url的向量表示输入到训练好的双向lstm模型中进行标注,检测其是否为钓鱼url;利用上述方法来检测钓鱼url;能够深度挖掘url的词序列包含的上下文信息和特征,相比于基于人工提取的词特征的机器学习模型和基于字符序列的深度学习模型都有较好的效果,在相同数据集上的检测效果如表1所示;并且,该方法是一种轻量级的钓鱼url检测方法,使用训练好的模型,在普通的服务器上,单线程预测速度达每秒钟不少于600个url。可在提高检测准确率的同时,满足实时检测的需求。表1四种不同检测模型的检测结果对比模型precisionrecallf1基于词特征的决策树模型0.88030.87000.8751基于词特征的随机森林模型0.89810.89650.8973基于字符序列的双向lstm模型0.95530.94740.9513基于词序列的双向lstm模型0.98080.97160.9762显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1