一种3D掌纹识别技术的制作方法
本发明涉及一种人体特征识别技术,具体是一种3d掌纹识别技术。
背景技术:
在高度信息化的现代社会,随着交通、通讯、网络技术的高速发展,信息安全显示出前所未有的重要性。在日常生活中以及金融、司法、安检、电子商务等很多场合需要准确的身份识别以确保系统的安全,因此,人的身份识别技术的应用越来越重要。传统的身份鉴定手段大体上可以分为两类:基于特定持有物的,如身份证、信用卡、钥匙、工作证等;基于特定知识的,如口令、密码、暗语等。很多场合需要将这两种方法相结合,例如在atm机取款时,你不仅需要信用卡,还需要知道密码。传统方法的缺点首先在于特定持有物或知识可能遗忘、遗失或者被盗。使用特定知识存在记忆上的困难,人们很难记住复杂密码,而简单密码(如生日、电话号码等)又很容易被猜测或破译。其次,它与用户并不唯一绑定,一旦别人获得这些持有物或知识,他将拥有与失主同样的权利。生物特征识别技术的发展和提高,为身份的认证和识别提供了更好的手段。
所谓生物特征识别就是指利用人体所固有的生理特征或行为特征,来进行个人身份鉴定。生理特征是指对人体部分进行直接测量所获得的数据,一些代表型的生理特征包括指纹、人脸、虹膜、视网膜、掌形等;行为特征是对个人习惯性动作的度量,是对人体特征的间接性测量,一些代表性的行为特征包括声音波纹、击键习惯、签名等。生理特征和行为特征的区分是人工给定的,在很多场合,二者之间的界限可能不十分严格。最常用的生物特征识别技术包括指纹、人脸、声音波纹、虹膜、视网膜、掌形、签名、掌纹等。还有一些技术因为使用的不方便或不成熟而缺乏商业价值,这些技术包括dna、耳型、气味、步态、指型、手指甲纹理等。
尽管掌纹图像早已应用于刑侦领域,但自动掌纹识别作为一种生物识别技术则是近年来发展起来的。它的取样可以像指纹和手形那样方便,又可以保证稳定性和唯一性,同时,掌纹识别并不会让人联想到隐私权的侵害,其被测试者的可接受程度较高,而且识别系统的硬件标准化程度也比人脸识别、语音识别、视网膜识别的标准化程度高。识别率与识别速度均可以达到实用系统的要求。因此基于掌纹的身份识别技术是人体身份识别技术的重要内容。而且掌纹图像是低对比度、低分辨率的图像,在图像处理中提取这样图像上的特征很困难。因而对掌纹识别技术的研究有着重要的现实和理论意义。
掌纹识别是一项具有较强市场前景的新兴生物特征识别技术。掌纹中含有丰富的特征,如主线、皱褶、脊线和细节点等。在高分辨率掌纹图像中可以提取到上述的全部特征,而在低分辨率掌纹图像中,只能提取到主线和皱褶特征,高分辨率掌纹识别技术主要应用在刑事侦查等领域。由于高分辨率掌纹图像的获取比较困难且图像尺寸大等原因,相关研究并没有广泛开展。而低分辨率掌纹识别技术具有图像获取容易、处理速度快且识别精度高等优点,适合一般的民用和商用,是目前学术界研究的重点。
手掌是手指根部到手腕之间的区域,手掌的皮肤纹理叫掌纹。掌纹主要提取主线和皱褶特征。(1)主线:由于深筋膜和手掌皮肤表面相连,手掌在内握时表皮内折的折线是固定的,随着手掌抓握过程中的张合形成的。因为不同的人抓握的方式、手掌的大小、手掌厚度的不同,导致主线也有着明显的不同。掌纹识别中主线是最为明显的特征。(2)皱褶:褶皱是掌纹中很多不规则的较浅、较细曲线或者直线。一些褶皱是天生就有的,一些褶皱是后天形成的,由于某些部位自然运动,所导致的皮肤在不同方向上进行伸展或收缩而失去弹性形成的永久性褶皱。
掌纹识别作为生物特征识别技术的新兴技术,具有独特的线特征,在低分辨率图像中也可以提取出其相对稳定的特征,具有较强的抗噪能力。与其他常用的生物特征识别技术相比,掌纹识别具有很多独一无二的特性。
1)与人脸识别相比,掌纹特征不受饰物、表情及姿态等因素的影响,相对比较稳定,可以更好的保障掌纹识别系统的识别精度。
2)与指纹技术相比,掌纹的有效区域要远远大于指纹的,掌纹含有比指纹更丰富的信息。并且指纹只适用于指纹质量较好的人群,限制了指纹不清晰或者指纹受到严重磨损的人。另外,掌纹采集设备成本比采集指纹的低,因为指纹采集需要高精度的设备。
3)与虹膜、视网膜识别相比,虽然虹膜、视网膜识别率比较高,但是采集设备高昂,并且导致眼疾交叉传染,而掌纹采集设备成本较低,图像获取方式简单,可接受程度高。
由于在图像获取过程中投影变换的原因,造成很多特征信息的丢失,致使二维识别受光照和姿态的影响巨大。为了提高识别率,避免视角和光照的改变对识别率的影响,亦即为使生物特征识别进一步贴近人类自然感知,众多研究者开始致力于三维生物特征识别。3d数据真实反映了3d对象在空间中的形状。用3d数据无需考虑投影变换,由于二维的图像数据本质上是3d物体在二维空间上的投影,造成同一对象在投影平面上具有多变的二维表现,即同一个掌的掌纹图像随姿态而变化的多样性,这也是当前基于2d图像的掌纹识别方法面临的最大困难之一。
对于低分辨率的掌纹图像,主要是利用主线和皱褶信息实现掌纹识别。根据掌纹中特征的表示以及匹配方法,可大致将掌纹识别方法分为四个类别,分别是基于结构的方法、基于统计的方法、基于子空间的方法和基于编码的方法。此外,还列出了一些不属于这些类别的方法。
基于结构的方法
基于结构的方法主要是指利用掌纹中主线和皱褶的方向和位置信息实现掌纹识别的方法。这一类的方法主要由两部分组成:1)提取掌纹中的纹线特征;2)纹线特征的有效表示和匹配。线特征的有效表示主要是指便于匹配,并且占用尽可能少的存储空间。对于特征的提取,较多使用的是各种线检测算。子以及边缘检测算子;对于特征的表示,主要是采用直线段或特征点代替掌纹纹线;而特征的匹配大多采用特征点之间的欧氏距离等。
wu等提出了一种利用高斯函数的导数提取掌纹主线特征的方法。该方法采用四个不同的检测算子,分别检测四个不同方向的纹线,最后合并各个方向的检测结果。为了克服非线性形变及旋转带来的影响,文献[2]在匹配前对表示纹线的二值图像进行旋转和形态学膨胀,之后再与其他掌纹匹配。文献[3]中首先通过二值化获得掌纹的线特征,之后提取掌纹中最大内切圆内部的若干条跨度最长的纹线,匹配时采用的是类似hausdorff距离的双向匹配方法。
基于结构的方法是早期的用于掌纹识别的方法。总的来说,大部分基于结构的方法都是借鉴或移植自指纹识别中的方法,简单直观。但是这类方法用直线段或特征点近似地表示掌纹纹线,丢失了大量信息,因此识别率不高.此外,这类方法的识别性能在很大程度上依赖于边缘检测算子或宽线检测算子。掌纹中一些比较细小模糊的线包含大量的判别信息,但却无法被检测算子检测到。大量的直线段和特征点也使匹配过程非常耗时。
基于统计的方法
基于统计的方法是指利用掌纹图像的重心、均值、方差等统计量作为特征的识别方法,可进一步分为基于局部统计量和全局统计量的方法.其中基于局部统计量的方法需要将图像分成若干小块,之后统计每块的均值和方差等统计信息,最后连接为表示整个掌纹的特征向量;而基于全局统计量的方法则直接计算整个图像的矩和重心等统计信息作为掌纹的特征.匹配时,一般采用矢量比较时常用的相关系数、一阶范数或欧氏距离.
对于基于局部统计量的方法,在提取统计特征之前,通常需要对图像做变换,例如傅里叶变换、小波变换等.li等[4]首先用傅里叶变换提取掌纹图像的频域信息,之后分块并计算每块的幅值和相位的和作为特征.基于统计的方法比基于结构的方法有更高的准确率,统计的本质也使得该类方法对噪声不敏感.
基于子空间的方法
子空间方法将掌纹图像看作是高维向量或矩阵,通过投影或变换,将其转化为低维向量或矩阵,并在此低维空间下对掌纹表示和匹配。主要包括独立成分分析(independentcomponentanalysis,ica)、主成分分析(principalcomponentanalysis,pca)、线性判别分析(lineardiscriminantanalysis,lda)等。基于子空间的方法大都需要对每个类别的掌纹图像构造训练集,在该训练集上计算最优的投影向量或矩阵,并将投影后的向量或矩阵作为该类掌纹的特征。在识别阶段,首先对待测掌纹图像作相同投影或变换,之后采用最近邻分类器分类。基于子空间的方法已成功地应用于人脸识别,移植到掌纹识别后也取得了很好的效果。
lu等提出了利用pca进行降维的eigen-palm方法,该方法首先将掌纹图像连接为高维向量,并计算该向量的散度矩阵的特征值和特征向量,之后保留若干较大的特征值对应的特征向量构成投影矩阵。由于pca主要考虑的是掌纹的表示(representation),而不是掌纹的判别(discriminance),wu等又提出了在pca的基础上再进行lda降维的fisherpalm方法。lda方法同时考虑类内散度和类间散度,并通过最大化类间散度同时最小化类内散度计算最优的投影矩阵。
基于子空间的方法具有坚固的理论基础,并且已广泛地应用于人脸识别中。相对于基于结构的方法,具有识别率高、特征小等优点,较之基于统计的方法也有更高的识别率。
基于编码的方法
基于编码的方法是指先用滤波器对掌纹图像滤波,之后根据某些规则将滤波后的结果进行编码的方法。通常特征都按照比特码的形式存储,对得到的特征码多采用二进制的“与”或者“异或”计算相似度。该类方法主要包括三个核心部分:滤波器的选择(gabor,高斯,高斯的导数),编码规则(最大值,序数关系),以及匹配方式(点对点,点对区域)。
kong等提出了一种称为fusioncode的方法.在用两个方向的gabor滤波器对掌纹图像滤波之后,对每个采样点,编码幅值最大的方向的相位信息。相位信息被量化到四个区间,因此每个采样点同样被编码为2个比特。fusioncode方法同时利用了幅值和相位信息,因此获得了更好的识别性能。wu等提出利用高斯函数的导数作为滤波器,在水平和垂直方向对图像滤波,最后根据滤波结果的符号编码,称作dogcode.实验结果表明该方法优于fusioncode。kong等在文献中提出使用六个方向的实值gabor滤波器对掌纹图像滤波,并对幅值最小的方向编码,称为竞争编码(competitivecode)。在每个采样点被巧妙地编码为三个比特之后,可以通过二进制的“异或”操作高效地计算出采样点间的角度距离。为了克服预处理带来的平移对匹配产生的影响,在匹配阶段需要在[-2,+2]的范围内进行竖直和水平方向上平移,并取距离最小的匹配结果作为最终的距离.由于竞争编码考察了掌纹图像的方向信息,对光照强度不敏感,而且对不同时期采集的掌纹有很好的稳定性,因此获得了很高的识别精度。
基于编码的方法最初借鉴了虹膜识别的方法,之后研究人员根据掌纹的特点提出了一些改进方案。从利用幅值和相位信息,到提取掌纹的方向信息;从单个滤波器,到使用不同方向的一组滤波器(filterbank),实验结果表明这些改进是可行的和有效的。
基于稀疏表示的分类方法
这种分类方法由wright等首次在人脸识别中应用,获得极好效果,展现了其在分类识别问题上的优越性。高等人把核约束加入稀疏表示模型,提出了核稀疏表示人脸识别方法;yang等人把尺度空间理论和稀疏表示结合起来,提出了基于线性空间金字塔的稀疏表示识别方法。郭等人[14]应用稀疏表示分类方法进行二维掌纹的识别,但是使用的特征仅仅是二维掌纹亮度信息。
基于三维掌纹数据的方法
虽然目前3d对象的研究还比较少,但是一些科研组对3d人脸的研究已经取得了一定的成就,譬如:lu利用icp方法进行三维人脸识别。这种方法假设图库中的三维图像是一个更完整的人脸模型,搜索三维图像是一个正视图就像图库图像一样。2008年,d.zhang等发表了一篇使用3d掌纹识别的文章,这也是国际首篇介绍3d掌纹识别的文章。另外,最近发表的一篇,在文章中提到所使用的识别算法就是使用微分几何的基于曲率的算法,获得了不错的识别效果。yang利用形状指标表示去描述三维掌纹的局部区域的几何特性,提取gabor小波特征用于识别掌纹,获得较好效果。
掌纹由于自身的一些优势,在生物识别领域具有很大的潜力,但目前掌纹识别的主要问题在于:
(1)掌纹特征的提取存在不足:在限定光照和姿态的前提下,获得的二维特征会达到较好的识别效果,但是光照和姿态改变时,提取的二维特征会降低掌纹识别效果。
掌纹分类方法研究相对较少:目前高效掌纹分类算法比较缺乏。
技术实现要素:
本发明的目的在于提供一种3d掌纹识别技术,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
一种3d掌纹识别技术,包含以下步骤:
掌纹的提取及融合;
掌纹的识别。
作为本发明的进一步方案:所述步骤a采用多特征信息提取及融合技术,所述特征信息包括二维的gabor小波特征和三维的曲面曲率特征,将二维数据的特征和三维数据的特征通过特征融合得到多维特征,保证了信息的全面性和完整性。
作为本发明的进一步方案:所述掌纹的识别是基于稀疏的识别技术实现的。
作为本发明的进一步方案:所述gabor小波特征提取采用gabor滤波器。
与现有技术相比,本发明的有益效果是:1、针对图像及三维掌纹数据,提取多维特征,发挥不同的特征互补性。克服单一、单维特征的缺点,发挥多特征对信息描述的全面性和完整性。2、研究一种改进的稀疏表示分类技术——邻域稀疏表示分类(nsrc),利用nsrc完成掌纹的分类识别,既保证原有稀疏表示分类技术的识别效果,又可以减少一定的计算量。
附图说明
图1为掌纹自动识别流程图。
图2为微分几何中的曲率对比图。
具体实施方式
下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种3d掌纹识别技术,包含两部分:
(1)掌纹的多特征提取及融合技术
二维掌纹图像提取gabor小波特征,三维掌纹数据特征提取均值曲率特征。gabor滤波器是窄带带通滤波器,在空间域和频率域都有较好的分辨能力,可以在空域和频域达到联合最优,具有明显的方向选择性和频率选择性,被广泛应用于纹理分割和目标识别领域。gabor滤波器适用于提取纹理特征。
曲率是曲面一种固有的属性,它的值与曲面上的点的距离有关,与曲面在空间的位置无关。曲率刻画在某一点的弯曲程度,均值曲率可以确定曲面的形状,高斯曲率刻画凸曲面以及非凸曲面的凸区域的形状。我们采用计算曲率的方法是先采用7×7的模板和图像进行卷积,求得一阶偏微分和二阶偏微分,然后结合均值曲率和高斯曲率的定义获得曲率值。在得到曲率值后,将曲率值映射到灰度图像上得到均值曲率图像和高斯曲率图像。
按照待融合信息所处层次的不同,信息融合一般可以分为数据层融合、特征层融合和决策层融合。本项目主要采用特征层融合。将二维数据的特征和三维数据的特征通过特征融合得到多维特征,保证了信息的全面性和完整性。
(2)基于邻域稀疏表示分类的掌纹识别技术
稀疏表示是近年来信号处理领域的研究热点,它是一种对原始信号的分解过程,该分解过程借助一个事先得到的字典,将输入信号表示为字典的线性近似的过程。
尽管稀疏表示的优化模型是从信号重建的角度设计的,其表示结果在识别中有较好的表现。稀疏表示用于识别,即基于稀疏的识别(src),这种分类方法由wrightet等首次在人脸识别中应用,获得极好效果,展现了其在分类识别问题上的优越性。src方法是把很多不同类别的对象放入训练集,当需要对某个类别未知的对象进行分类时,用训练集中每个样本的线性组合来描述这个未知类别的对象。然后计算重构样本与测试样本之间的残差,当残差在某一类特别小,而其他类别特别大时,该未知类别的对象属于该类。但是当残差呈现比较均衡,且很大的情况,表明测试对象不属于训练集的类别。
本发明的工作原理是:
(1)掌纹的多特征提取及融合技术
对于复杂模式识别问题,如手写体汉字识别、掌纹识别,目前还没有一个简单的方法可以达到较高的识别率和可靠度,每一种方法都有各自的优点、缺陷和不同的适用范围,不同的特征和识别方法之间具有一定的互补性。因此将不同的方法有机的结合起来以发挥各自的优势,克服缺陷,构成信息融合型的识别系统,是模式识别研究的一个主要方向。
用于掌纹识别的特征中,二维特征准备采用gabor小波,三维特征拟采用均值曲率三维特征。gabor滤波器是窄带带通滤波器,在空间域和频率域都有较好的分辨能力,可以在空域和频域达到联合最优,具有明显的方向选择性和频率选择性,被广泛应用于纹理分割和目标识别领域。gabor滤波器适用于提取纹理特征。
二维gabor滤波器的余弦形式可被定义为高斯函数与余弦函数的乘积:
式中:
(x,y)——滤波器中心位置;
f——余弦信号的频率,即滤波器中心频率;
σx——高斯窗函数的有效宽度;
σy——高斯窗函数的有效长度。
通过改变参数(σx,σy,f,
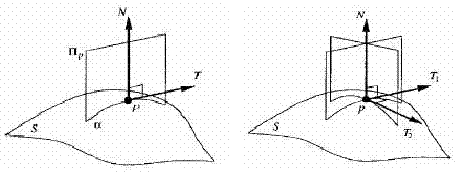
三维掌纹模型的特征提取采用曲面曲率。曲面曲率可以描述三维掌纹丰富的曲面皱褶信息。曲率是曲面一种固有的属性,它的值与曲面上的点的距离有关,与曲面在空间的位置无关。曲率刻画在某一点的弯曲程度,均值曲率可以确定曲面的形状,高斯曲率刻画凸曲面以及非凸曲面的凸区域的形状。定义曲线α上的弧长参量s,使得α(0)=p,α'(0)=t,t是点p沿着曲线α的单位切向量。由α”(0)=kp(t)·n定义曲面s在点p的法曲率kp(t),n为曲面s在点p的法方向。
当平面πp绕n旋转一周时,α,t随之改变,得到不同的法曲率kp(t)。相对于最大和最小的法曲率的方向{t1,t2}称为曲面s的主方向,相对应得到的曲率称为主曲率,
它们都是内在的几何不变量,很好的刻画曲面的弯曲程度。
(2)基于邻域稀疏表示分类的掌纹识别技术
稀疏表示是近年来信号处理领域的研究热点,它是一种对原始信号的分解过程,该分解过程借助一个事先得到的字典,将输入信号表示为字典的线性近似的过程。表示如下:
y=ax,其中y是待处理信号,a是字典,x为系数向量表示,||x||0为x的稀疏度,表示x中非0的个数。在给定一组字典a前提下,稀疏表述的目的是使x尽量稀疏,重构信号y:
min||x||0
s.t.y=ax
尽管稀疏表示的优化模型是从信号重建的角度设计的,其表示结果在识别中有较好的表现。稀疏表示用于识别,即基于稀疏的识别(sparserepresentationbasedclassification,src)。wright等人利用人脸图像的稀疏表示进行人脸识别,得到较好的效果。该方法假设一个给定的测试样本可以用全体训练样本的稀疏的线性组合来近似表示。在线性组合中,与测试样本同类的训练样本不为零的概率很大,且其他训练样本的系数一般为零或接近零。
在src中,求解稀疏的非零系数可以通过求解l0范数优化问题得到。但是,求解l0范数优化问题是一个np难题。根据稀疏表示理论,在某些情况下,找寻l0范数优化问题的最优解等价于找寻l1范数问题的最优解。所以在src中,可以用l1范数优化来代替l0范数优化。
src方法在做分类时,需要用全部的训练样本来表示测试样本,当训练样本很大时,该方法的计算量会很大。本课题研究改进的src方法,使得能够减少这种计算量。采用先通过某种方式得到与测试样本最相似的一部分训练样本,称作该测试样本的n邻域训练样本,然后用得到的n邻域训练样本进行对测试样本的稀疏表示,最后判断测试样本的类别。对于任意的一个测试样本y,改进的src算法先找到与测试样本y最相近的n邻域训练样本集合。假设在第i类训练样本中找到ni个训练样本,则第i类训练样本记为
x是y由a列向量的稀疏表示系数。根据这个系数,计算测试样本y的重构样本
基于稀疏表示分类算法步骤如下:
(1)确定字典a
(2)由字典a对待测y编码,使其系数l1范数最小,λ为正则参数
(3)计算残差:
对待测样本进行分类:identity(y)=argmin(ri)。
- 还没有人留言评论。精彩留言会获得点赞!